
基于MySQL不同存储引擎下数据存储效率研究
2022-05-30 10:48杨卓凡
电脑知识与技术 2022年21期
杨卓凡

摘要:随着社会信息数据量高速发展,庞大数据量信息需要高效存储在数据库系统中。MySQL数据库是一款较为普遍使用的开源关系型数据库系统,其数据的存储过程是依靠存储引擎进行的。文章基于几种主流存储引擎下分别进行了数据存储效率的实验研究与对比,从而给用户进行存储数据时可根据不同需求和应用环境选择适合的存储引擎提供了一些建议,进而能使数据库性能得到提升优化。
关键词: MySQL数据库;存储引擎;研究对比;性能优化
中图分类号:TP311.13 文献标识码:A
文章编号:1009-3044(2022)21-0018-03
开放科学(资源服务)标识码(OSID):
1 序言
随着Web2.0时代的来临,人类社会信息数据量呈现爆发式增长,在很多项目中存储百万级甚至上千万级的数据很是普遍。MySQL数据库则是一款应用在企业级存储数据较为流行的数据库,如何高效率高质量地将外部大量数据存储或更新到MySQL数据库中是许多项目需考虑的问题,而MySQL是依靠其存储引擎来进行存储数据的[1]。因此,本文就其主流的几种存储引擎的特点进行了相关介绍及数据存储实验的研究。
2 存储引擎及其介绍
2.1 存储引擎定义及原理
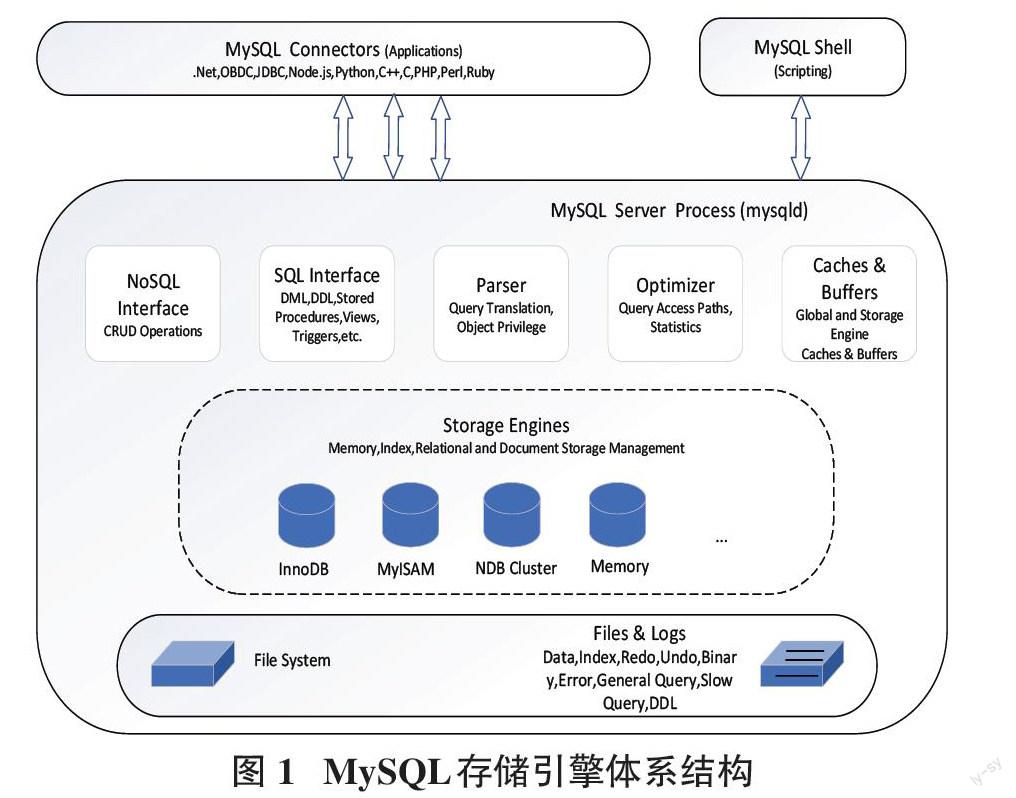
存储引擎是一种关于如何存储数据,如何为存储的数据建立索引以及如何更新,查询数据等技术的实现方法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)。MySQL数据库存储引擎体系结构如图1所示[2]。
如图1所示,从上到下依次是连接层、服务层、存储引擎层和数据存储层[3]。连接层主要提供客户端接口和连接服务以及进行授权认证等操作,服务层包括SQL接口、Parser解析器、Optimizer查询优化器和Cache & Buffer查询缓存,存储引擎层实际进行MySQL中数据的存储和提取操作,MySQL服务器通过API与存储引擎进行通信,数据存储层主要将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互[4]。
2.2 存储引擎主要类别
MySQL数据库存在多种存储引擎,其名称与基本描述如表1所示。
如表1所示,不同存储引擎依据其自身的特点适用于不同的场景下,其中使用最为广泛的是MyISAM和InnoDB两种存储引擎。自MySQL5.5版本之后,MySQL的默認内置存储引擎已经是InnoDB了,其最大的优势在于提供事务支持,灾难恢复性较好。而MyISAM数据引擎虽插入速度快,但不支持事务处理,使用MyISAM创建表时,每张表的结构及数据是依赖三个文件存储在数据库中的。三个文件的文件名与表名相同,文件后缀名分别是SDI、MYD和MYI。其中.SDI文件用于存储表的元数据信息,.MYD存储的是数据信息,而.MYI则是索引信息存储的文件。下面主要进行这两种存储引擎的数据存储实验及其对实验结果的对比分析。
3 存储实验的环境搭建及准备工作
以下是基于MyISAM存储引擎下的搭建及准备工作。
(1) 软件环境的搭建:
Windows10专业版,MySQL-8.0.23-winx64,
Navicat for MySQL,IIS6。
(2) MySQL表结构的设计与存储过程的定义。
表定义如下:
CREATE TABLE t_tag(
tag_name varchar(100) DEFAULT NULL,
tag_desc varchar(100) DEFAULT NULL,
tag_id bigint(100) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (tag_id)
)ENGINE=MyISAM AUTO_INCREMENT=1099999 DEFAULT CHARSET=latin1
存储过程定义如下:
create procedure myproc()
begin
declare index bigint;
declare number bigint;
set index=1;
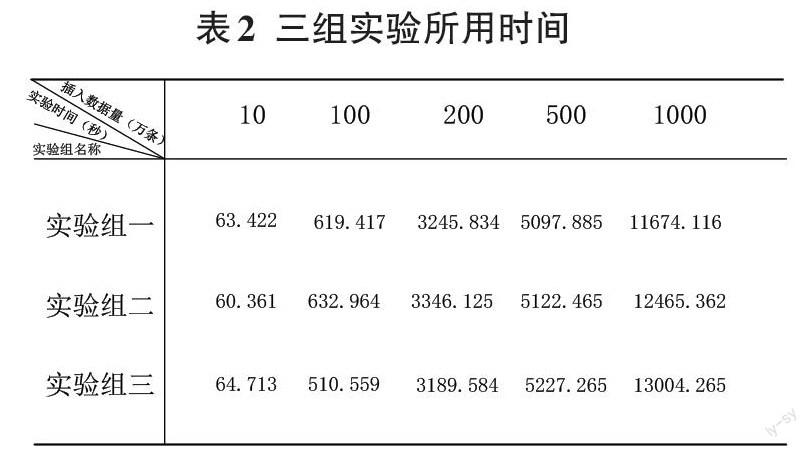
while index insert into t_tag(tag_name,tag_desc)values(concat(“tag”,index),concat(“tag”,index));set index=index+1; end while; end 4 基于MyISAM引擎下数据存储实验 4.1数据存储实验过程 调用存储过程语句为 call myproc(),通过向myproc()存储过程中定义的number变量分别多次传入不同的值,来表示向t_tag表中分别插入不同数据量数据(每次的存储过程是向空表中重新插入数据),为了保证实验数据的有效性、准确性及可靠性,对每次的存储数据过程在Navicat for MySQL客户端进行了三组实验,最终各项存储时间取三组实验的平均值作为最终的实验结果。三组实验原始时间数据记录如表2所示,且将时间数据绘制成如下曲线图2所示(三组实验均成功将数据存储到库表中)。 4.2实验数据结果分析 由图2可以看出,在MyISAM引擎下进行存储数据时,当数据量在500万以内时,数据存储到表中所需时间增长较为缓慢,而当数据量大于500万时,从图中可看出数据存储到表中所需时间增长速率较快(图中曲线上各点的切线平均斜率较大)。例如从实验组一可以得出,数据量为1000万时所用时间为11674.116s是数据量为100万所用时间619.417s的18.85倍,大于数据量增长的10倍。是由于MyISAM引擎不提供事务支持,也不支持行级锁和外键,当对表执行大量的写操作的时候需要锁定该表,所以会造成写操作效率降低。 5 基于InnoDB引擎下数据存储实验 基于InnoDB存储引擎下的搭建及准备工作,在数据库中建立一张新的数据表t_tag1,建立新的字段名为tag1_name,tag1_desc及tag1_id,存储引擎设置为InnoDB,建立新的存储过程为myproc1。 5.1影响存储效率相关参数不同值的设定 InnoDB引擎下影响数据存储效率主要有两个参数autocommit(自动提交事务参数)和innodb_flush_log_at_trx_commit(事务日志刷写参数),两者在默认情况下值均为1,两者参数均可以在MySQL安装文件位置的源文件中的my.ini配置文件中进行添加设置,其中autocommit取值可为0,1,innodb _flush_log_at_trx_commit可取值0,1,2[4]。 由于InnoDB引擎是支持事务处理,调用存储过程语句为 call myproc1(),通过向myproc1()存储过程中定义的number变量分别多次传入不同的值,来表示向t_tag1表中分别插入不同数据量数据(每次的存储过程是向空表中重新插入数据)[5]。为了保证实验数据的有效性、准确性及可靠性,对存储数据过程在Navicat for MySQL客户端进行了六组实验,前三组实验(实验组一,实验组二及实验组三)是在autocommit设置为1下所进行的,后三组实验(实验组四、实验组五及实验组六)是在autocommit设置为0下进行的[6]。当数据成功存储到数据表中时,依照记录的时间数据绘制成曲线图,前三组实验组时间数据对应为主坐标轴,后三组实验组时间数据对应为次坐标轴。 分别设置参数innodb_flush_log_at_trx_commit值为0,1,2。各参数下实验原始所用时间如表3所示。 将以上三张表绘制成如下曲线图所示,每张表将前三组实验组及后三组实验组分割为两大类,并计算各自类中每一组插入数据量所用时间的平均值作为曲线图中的描绘点。例如表3中,当插入数据量为10万条时,实验组一,实验组二及实验组三分别所用时间为63.125s,60.954s,61.876s。其三组数据的平均值为61.985s。此时autocommit设置为1,innodb_flush_log_at_trx_commit設置为0。如图3中各曲线名称用二维数组形式表示,例如autocommit=1,innodb_flush_log_at_trx_commit=0时表示为曲线[1,0]。其中曲线[1,0],[1,1],[1,2]数值对应主坐标轴数据,曲线[0,0],[0,1],[0,2]数值对应次坐标轴数据。 5.2实验数据结果分析 由上述实验过程及相应的图表结果可以得出,当innodb_flush_log_at_trx_commit设置为0或2时(此时在autocommit值为1的默认状态下),数据存储到表的存储效率和基于MyISAM引擎下的存储效率基本接近,但当其值设置为1时,完成数据存储所耗时间大幅度增加,致使性能急剧下降,这是由于每次存储数据时都会自动提交并且刷新日志,因此存储效率会降低[7],若设置autocommit的值为0时,无论innodb_flush_log_at_trx_commit的值为何值,从图表中可以得出,当插入数据量为同一数量级时,后三组实验组对应次坐标轴时间数据远远低于前三组实验组对应的主坐标轴时间数据,因此当autocommit设置为0值时能大幅度提高数据存储效率,这是因为当autocommit值为0时,即为关闭自动提交事务功能,无需每次刷新到日志文件,因此数据读写性能会提升。 6结论 通过上述实验测试结果分析,可以得出在当前软件环境中,采用MyISAM引擎和在innodb_flush_log_at_trx_commit值为0或2时的状态下的InnoDB存储引擎进行数据存储效率差别不是很大,若innodb_flush_log_at_trx_commit的值为1时,在默认状态下的autocommit值为1时,InnoDB数据存储引擎效率较低,且当autocommit值为0时,InnoDB由于关闭了自动提交事务和无需写入日志文件到磁盘,因此具有高效的存储效率。本文分析了两种存储引擎各自的特点,在实际中针对不同业务项目来讲,各自有着不同的需求,进而需要采用恰当的存储引擎建立合适的存储表类型,从而可以最大程度地发挥MySQL数据库性能优势[8]。 参考文献: [1] 王威.MySQL数据库源代码分析及存储引擎的设计[D].南京:南京邮电大学,2012. [2] 徐昂,成科扬.基于关系型数据库的SQL检索优化研究[J].电子设计工程,2019,27(11):51-55. [3] 陈小辉,文佳,邓杰英.MySQL的体系结构及InnoDB表引擎的配置[J].福建电脑,2009,25(7):162,148. [4] 周渊,王力生.MySQL中InnoDB存储引擎在NUMA系统上的优化[J].科技传播,2011,3(1):155-156. [5] 胡雯,李燕.MySQL数据库存储引擎探析[J].软件导刊,2012,11(12):129-131. [6] 黑马程序员.MySQL数据库原理、设计与应用[M].北京:清华大学出版社,2019. [7] 刘阳娜.大数据下的MySQL数据库的效率优化[J].信息通信,2017,30(12):111-112. [8] 张工厂.MySQL技术精粹架构、高级特性、性能优化与集群实战[M].北京:清华大学出版社,2015. 【通联编辑:王力】
