
一种改进复杂场景下小目标检测模型的方法
2022-06-09 11:58严凤龙刘振宇
计算机工程与应用 2022年11期
周 慧,严凤龙,褚 娜,刘振宇
1.大连东软信息学院 软件学院,辽宁 大连 116023
2.大连东软信息学院 计算机学院,辽宁 大连 116023
目标检测是将目标定位和目标分类结合起来,其中目标分类负责判断输入的图像中是否包含所需物体,目标定位则负责标识出目标物体的位置,并用外接矩形框定位。目标检测通常需要在卷积特征图上引入事先定义好的矩形框,即锚点框(anchor boxes),这些锚点框按照面积和宽高比均匀分布,便于检测出不同比例的目标。这类方法称为基于锚点框(anchor-based)的目标检测[1-2]。anchor-based检测方法通常分为two-stage[3-4]和one-stage[5-6]。两者都是先在图像上平铺大量预定义锚点框,然后预测锚点框类别,最后选择合适的锚点框作为输出结果并进行回归操作。常见的two-stage检测方法如faster R-CNN[3]、FPN(feature pyramid networks,FPN)[4]等。复杂场景下的舰船目标检测,是典型的小目标检测应用,上述模型都在舰船小目标检测中广泛应用。如Kang等人使用fast-RCNN方法获得初始舰船检测结果,然后应用恒虚警率评价检测结果[8]。Xiao等人提出了一种语义分割网络,以生成更精确的旋转锚点框,并将生成的锚点框用于船舶目标检测[9]。常见的one-stage方法如Yolo系列[5-6]、SSD(single shot multibox detector,SSD)[7]等。其中,Wang等人使用SDD模型检测SAR图像中复杂背景中的船只,并使用迁移学习来提高准确性[10]。Hu等人提出了一种基于改进YOLOv3的SAR舰船检测算法[11]。
然而,anchor-based检测方法会带来正负样本的不平衡问题。在目标检测的过程中,大量的锚点框分布在卷积特征图上,通过计算真实边界框与锚点框的交并比(intersection over union,IoU)来划分正负样本[12]。一般而言,高于IoU设置正样本阈值的标记为正样本,低于IoU设置负样本阈值的标记为负样本(或者称为背景),其他为可忽略样本。复杂场景下的小目标船舶,通过锚点框标注样本,带来的正负样本不均衡更为明显。还有部分模型如Yolo等,为进一步提高定位准确率,采用NMS(非极大值抑制)[13],将具有最高分类得分的锚点框定义为正样本,其余为负样本。这个过程造成了更为突出的正负样本不平衡问题。而正负样本不均衡是影响船舶检测准确率的重要因素。
与此同时,anchor-based检测方法提到的基于不同面积和宽高比的锚点框是一组预先定义的超参[14],锚点框设计最重要的因素是要保证覆盖目标的位置和密度。通常锚点框分为大中小三类尺寸,SAR图像中的船舶目标属于特定数据集,多数为小尺寸目标。通过固定锚点框得到候选框的方式明显限制了检测模型[15-16]。
为了追求最佳特征对象匹配,目前提出了很多锚点框优化的方法。如meta anchor[17]提供了一个子网,从预定义的任意框中学习合适特征对象尺寸的锚点框。Guided anchoring[18]利用语义特征建立一个单独模块,通过建立锚点框函数自动生成锚点框。Gaussian YOLO[19]在建模过程中建立为四个高斯分布,在预测过程中输出引入了预测框的不确定性,从而最终提升锚点框的定位精度。另外,rotated anchor boxes[9]是设计了一个成对的语义分割网络来生成具有旋转型的锚点框,然后生成的旋转锚点框用于分类和回归。
本文也提出了一种改进anchor-based小目标检测方法。首先采用自适应锚点框保证覆盖目标的位置和密度;然后基于自适应锚点框生成的自适应IoU阈值,并利用该阈值选择正负样本,保证样本均衡。分别对two-stage模型faster R-CNN[3]、FPN[4]和one-stage模型Yolo3[5]、pp-Yolo[6]优化锚点框,性能均得到提升,说明了该优化方法的有效性。
1 基于形状聚类的自适应锚点框模型
在船舶目标检测时,首先需要定义正样本和负样本,并对正样本的位置进行回归。传统的检测方法是预先定义一组基于不同面积和宽高比的锚点框。SAR图像的船舶目标多为小尺寸目标,通用锚点框的尺寸无法较好地反映目标的形状信息,会影响检测精度。因此,本文在定义正负样本的过程中,采用基于形状相似度的DBSACAN聚类方法,计算得出一组的锚点框,更适应SAR图像中的船舶目标尺寸。
DBSCAN算法是基于密度的聚类算法,以数据集在空间分布上的稠密程度为依据进行聚类[20]。假设给定数据集D={x1,x2,…,xm}定义如下概念:
定义1(ε-邻域)对xi∈D,ε-邻域包含了数据集D中与xj之间的距离小于等于ε的样本,即:Nε( xj)={xi∈D|d(xi,xj)≤ε}。
定义2(核心对象)如果xj的ε-邻域至少包含MinPts个样本,即Nε( )xj≥MinPts,则xj是一个核心对象。
定义3(密度直达)如果xi在xj的ε-邻域中,并且xj是核心对象,称xi由xj直接密度可达。
定义4(密度可达)对于xi和xj,如果存在一个对象链m1,m2,…,mn,其中m1=xi,mn=xj,mi∈D(1≤i≤n),并且mi+1由mi直接密度可达,称xj由xi关于ε和MinPts密度可达。
定义5(密度相连)对于xi和xj,如果存在一个对象xk,xk∈D( )1≤k≤n使xi和xj均由xk密度可达,则称xi和xj关于ε和MinPts密度相连。
定义6(簇)从数据集D中任取一个对象xi,从xi开始在D搜索所有密度相连对象,构成一个簇。
本文采用DBSCAN算法聚类生成锚点框,替代传统的预先指定锚点框的方式。在计算真实边界框之间是否可聚类时,利用形状相似距离替代欧式距离,即根据形状相似性进行密度聚类。具体步骤如下:
步骤1初始化核心对象集合Ω=∅,初始化聚类簇数k=0,初始化未访问目标框集合Γ=D,簇划分C=∅。
步骤2计算目标框g i的ε-邻域包括的样本集Nε(g i),根据Nε(g i)判断g i是否为核心对象,如果是,将g i加入核心对象集合中:Ω=Ω∪{g i}。
本文计算目标框间ε-邻域距离采用的是形状相似度距离,通过计算形状距离dSSD来度量目标框之间的相似性,dSSD如公式(1)~(4)所示:

步骤4重复步骤3,直到Ω为∅,则聚类簇生成完毕。取当前簇C k中所有样本的长和宽,分别求出均值,即为一个新的锚点框尺寸。簇的个数即为锚点框的数量。采用基于形状相似距离的DBSCAN算法聚类目标真实框,结果如图1所示。
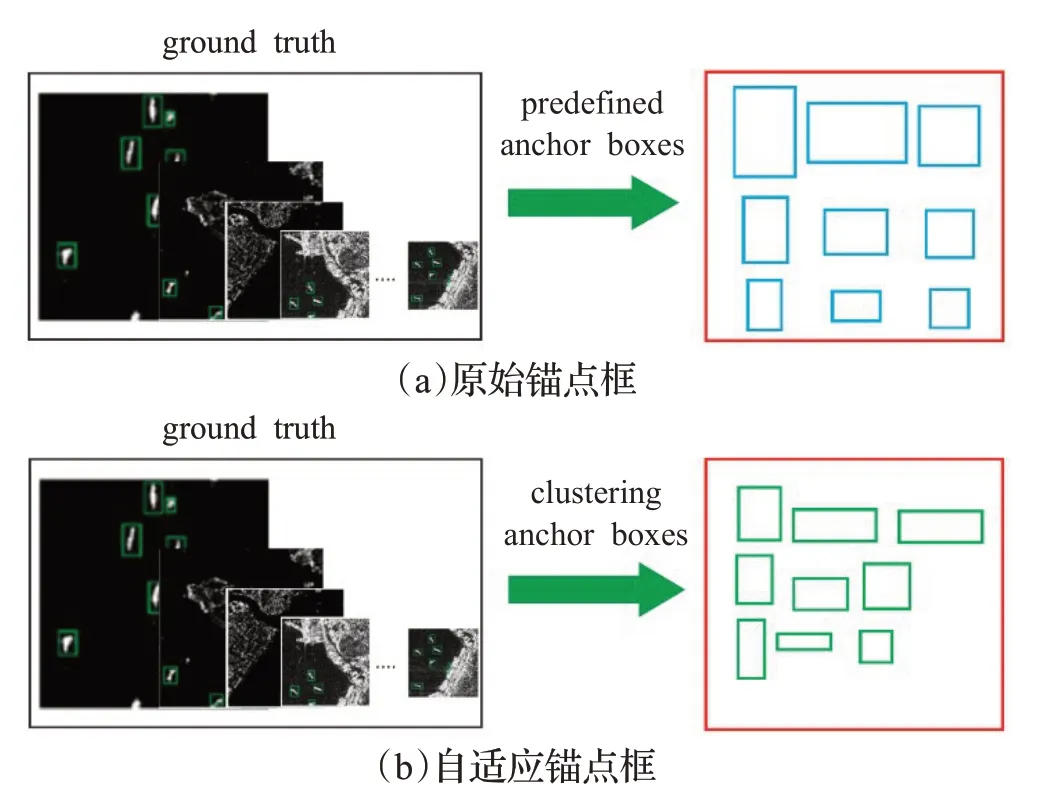
图1 原始锚点框与自适应锚点框对比Fig.1 Comparison of original anchor boxes and adaptive anchor boxes
2 自适应正负样本阈值
目标检测器通过计算真实边界框与锚点框的IoU来划分正负样本时,一般而言,高于IoU正样本阈值的标记为正样本,低于阈值的标记为负样本(或者称为背景)。因此基于锚点框的IoU阈值作为超参,不同的设置会有产生不同的正负样本划分结果。复杂场景下的小目标船舶,通过锚点框标注样本,会带来明显的正负样本不均衡问题。本文采用了一种自动的计算IoU阈值的方法,利用上述自适应的锚点框,根据统计量划分正样本和负样本,尽量避免影响结果的超参数的使用。具体过程如下:

步骤4在候选样本集中,再次选择候选框与目标框的IoU大于TIoU的为正样本,则候选集中剩下的为负样本。
锚点框的中心越靠近目标框中心,IoU的值越大,故根据中心距离选择候选框,能够提高样本的候选质量。
3 实验结果与分析
3.1 自适应锚点框实验
实验数据集使用中国科学院发布的SAR船用数据集,共计43 819艘船图片,其包括59 535艘船的图像切片。在利用目标检测模型检测前,先采用自适应锚点框的算法得到一组锚点框,再根据该组锚点框计算自适应IoU阈值,并利用该阈值选择正负样本,将改进的锚点框和IoU阈值用于不同的检测模型中,整体流程如图2所示。
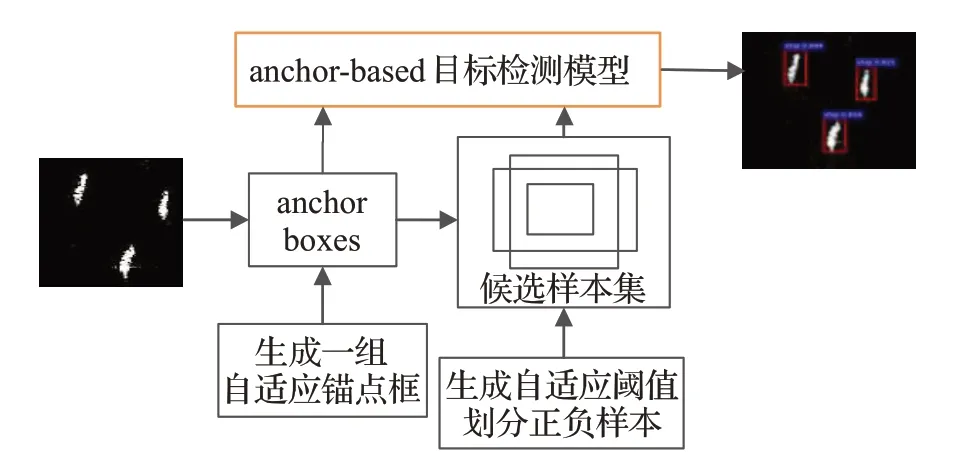
图2 实验流程图Fig.2 Experimental flowchart
针对该数据集,采用形状相似度的DBSCAN聚类方法计算得出一组的自适应锚点框,不同的(ε,Minpts)可计算确定锚点框个数的超参数k,通过实验验证超参k的鲁棒性。通常,faster R-CNN设置初始锚点框个数为9个[3],FPN模型设置个数为5个,并提供3个不同的宽高比[4],Yolo3模型初始锚点框一般设定为9个[5],pp-Yolo初始锚点框与Yolo3一致,因此选择DBSCAN聚类结果k值为[6,9,12,15]的几组结果,并对比基于欧式距离(Euclidean distance)聚类和基于形状相似度距离(shape similar distance)聚类生成的锚点框效果,如表1所示。当锚点框数据量为9时,准确率最高,继续增加锚点框数据量,准确率略有下降。同时,基于形状相似度的聚类,在欧式距离的基础上进一步考虑了形状距离,从实验对比结果来看,基于形状相似度聚类的锚点框在检测中能取得更好的准确率。
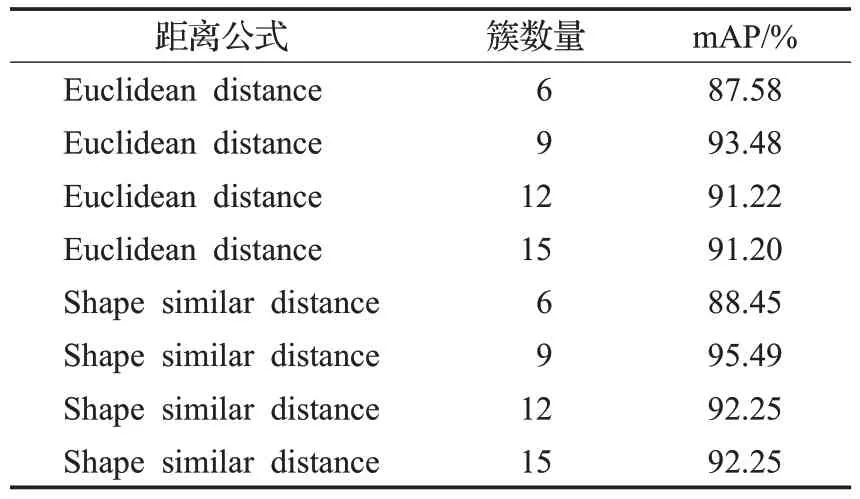
表1 基于欧式距离和基于形状距离聚类结果对比Table 1 Results with different clustering methods based on Euclidean distance and shape distance
同时与Kmeans的聚类结果进行对比,Kmeans的超参k值取9,分别按照欧氏距离和形状相似度距离聚类得到两组锚点框,与DBSCAN生成同样数量的锚点框,在faster R-CNN模型上进行对比实验,如表2所示,基于密度聚类的DBSCAN在锚点框聚类中能取得更好的结果。

表2 不同聚类算法结果对比Table 2 Results with different Clustering methods
3.2 自适应正负样本阈值实验
针对自适应正负样本阈值的实验,同样使用中国科学院发布的SAR船用数据集,并且采用自适应锚点框的结果集合。将自动的计算IoU阈值与预定义的IoU阈值进行比较,结果如表3所示。

表3 在SAR数据集上不同阈值结果对比Table 3 Experiment results of various IoU on SAR dataset
3.3 实验分析
传统的two-stage object检测器如faster R-CNN、FPN,one-stage object检测器如Yolo3和pp-Yolo,在一般的船舶检测任务中也能达到较好的检测结果。模型在Tesla V100中,均采用相同的训练策略对SAR船用数据集进行训练,迭代次数为105,batch_size设置为96,同时初始学习率设为0.000 1,每轮迭代后调整学习率,最终mAP分别为89.6%、93.3%、86.7%、88.0%。但是上述模型在背景中包含干扰对象的复杂场景下检测准确率下降明显,虚警概率和漏检率高,从上述SAR船用数据集中选择已标注的15 000张复杂背景图像(如图3)进行测试,faster R-CNN、FPN、Yolo3和pp-Yolo准确率分别下降到79.4%、85.7%、71.3%、78.2%。
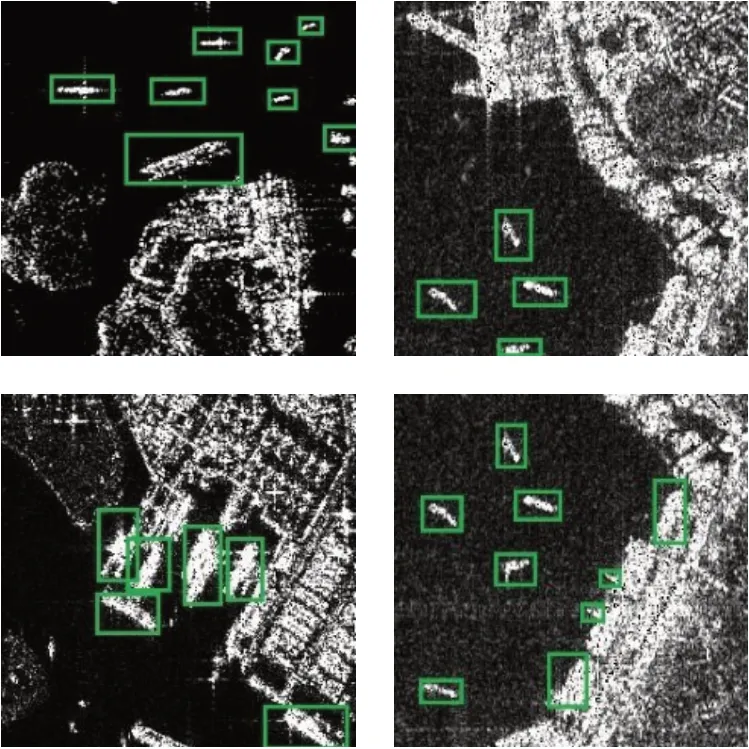
图3 复杂场景下的舰船目标数据集Fig.3 Ship target dataset in complex scenes
采用自适应锚点框方法(adaptive anchor boxes,AAB)和自适应阈值选择方法(adaptive threshold selection,ATS)与的目标检测模型对15 000张复杂场景图像检测,部分结果如图4所示,在复杂场景下,改进后的目标检测模型用于小目标检测均取得了较好的效果。四种模型均能提升mAP,如表4所示。针对不同的模型,首先采用AAB方法,mAP平均提升5.50个百分点;然后在同样的原始模型中,均加入ATS方法改进,各个模型mAP平均提升2.23个百分点。

表4 不同模型的检测结果对比Table 4 Comparison of detection results on ship dataset
two-stage object检测器faster R-CNN融合AAB+ATS,检测精确率上升了接近9.6个百分点;FPN融合AAB+ATS,检测精确率上升了接近2.6个百分点;Yolo3融合AAB+ATS,检测精确率上升了接近9.8个百分点;pp-Yolo融合AAB+ATS,检测精确率上升了接近9.9个百分点。说明通过自适应阈值,优化锚点框与目标框的IoU值解决正负样本不均衡问题,以及通过自适应锚点框,生成初始锚点框代替原始超参,解决目标覆盖问题,均能达到提升准确率的作用。两者结合,更有利于检测复杂场景下的船舶目标。复杂场景的检测结果如图4所示。
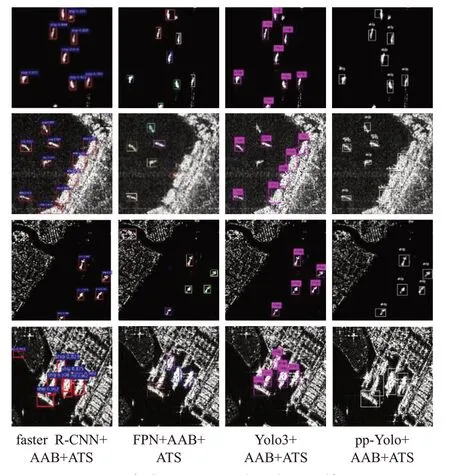
图4 复杂场景下的舰船目标检测结果Fig.4 Ship object detection results in complex scenes
4 结论
在复杂场景下小目标检测问题的研究中,正负样本均衡和锚点框的覆盖密度均影响检测结果,故本文提出了一种改进小目标检测模型的方法,采用基于形状相似距离评估的密度聚类方法,生成自适应锚点框;采用自适应阈值方法,利用训练样本选择合适的阈值,再划分正负样本。将该提升方法用于two-stage模型faster RCNN、FPN,one-stage模型Yolo3、pp-Yolo,针对复杂场景的小目标检测均不同程度地提高了检测准确,说明本文提出的方法是一种可行的、有效的改进小目标检测模型的方法。
猜你喜欢
建材发展导向(2021年19期)2021-12-06
通信电源技术(2021年2期)2021-05-21
电子技术与软件工程(2020年22期)2021-01-30
数字技术与应用(2020年12期)2021-01-22
临床骨科杂志(2020年1期)2020-12-12
移动通信(2020年5期)2020-06-08
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
