
结合统计特征和图模型的半监督式中文关键短语抽取方法
2022-06-17 09:09谢海华陈雪飞都仪敏吕肖庆
中文信息学报 2022年4期
谢海华,陈雪飞,都仪敏,吕肖庆,2,汤 帜,2
(1. 北大方正信息产业集团有限公司 数字出版技术国家重点实验室,北京 100871;2. 北京大学 王选计算机研究所,北京 100871;3. 北京雁栖湖应用数学研究院,北京 101407)
0 引言
文档关键短语抽取的目标是从文档中抽取出能够代表文档主题和内容的短语集合[1]。短语是由一个或多个词语组成的词组,例如,深度神经网络(“深度”“神经网络”两个词的组合)、强迫高弹形变(“强迫”“高”“弹”“形变”四个词的组合)。一般地,关键短语由文档中出现过的词语组合而成。
由于短语的应用十分广泛,关键短语抽取是文档处理领域的一项重要任务。关键短语可以用于生成文档的索引以便于检索,用于查询词的扩展以获取更多查询结果,作为特征用于文档聚类和分类,作为文档的简短总结以让读者了解文档内容。另外,关键短语抽取在学术出版领域的很多任务中发挥关键作用,例如,给用户精准推荐新出版的文章和图书、发现文章中缺失的引用项、为论文发掘潜在的审稿人、分析学术研究趋势,发现领域新词或术语等[2]。
文档关键短语抽取可以采用无监督或有监督的方法实现。采用无监督方法进行关键短语抽取的基本思路是基于多项特征对候选关键短语进行评分,并设定阈值以选择关键短语。可选的特征包括统计特征[3]、位置特征[4]、语言学特征和图结构特征[5]等。有监督关键短语抽取可采用的方法包括基于多项特征构造分类器或者序列标注模型、采用RNN等深度学习方法构造序列标注模型或者端到端生成模型[6]。
目前关键短语抽取算法的结果还不尽如人意,例如,抽取出来的短语并不能代表文档主题,或者一些能代表文档主题的关键短语未被算法发现,主要原因是抽取算法还面临以下技术挑战: ①由于缺乏明确的短语定义,候选短语的选择不够准确(如有些非短语中文词组被误认为是短语); ②由于缺乏统一、完备和权威的数据标注,所抽取的短语是否关键的依据偏弱。此外,大部分关键短语算法是基于英文数据集进行设计和实验的,基于多个数据集的测试结果显示,英文关键短语抽取算法的F1值最高不到0.6[2]。由于语言差异以及中文语法的复杂性,这些算法在中文数据集上表现得更加不理想。
本文提出一种针对中文的关键短语抽取算法,结合多项统计特征得分、图模型排序、短语和文章的语义相似度等因素,对短语进行评分以获取关键短语。本文的主要贡献如下:
(1) 基于中文期刊论文数据,构建中文关键短语标注数据集,用于计算中文短语的统计特征,以及评估中文关键短语抽取算法的性能;
(2) 针对中文特点,提出基于词性及词性组合特征的候选关键短语获取方法;
(3) 为了更准确地提取关键短语,提出采用多种因素结合的方式来计算短语得分,包括短语和文章的语义相似度、图模型排序、统计特征得分。
基于我们构建的中文关键短语标注数据集的实验显示,本文方法在准确率和召回率等指标上,明显优于目前前沿的关键短语抽取方法。
本文组织结构如下: 第1节简述文章关键短语抽取算法的主要方法和前沿进展;第2节介绍本文方法的基本架构和流程;第3节介绍本文构建的中文关键短语标注数据集,以及在该数据集上各种方法的测试效果,最后一节阐述本文方法的局限性以及未来的研究方向。
1 背景及相关工作
根据不同的数据特点和应用场景,文章关键短语抽取可以选择无监督或有监督方法实现。基于无监督方法进行关键短语抽取的基本流程如下:
(1) 获取候选关键短语集。从文档中选择一些词语及词组作为候选关键短语,可采用的方法包括词性筛选、命名实体识别等;
(2) 对候选关键短语进行评分和排序;
(3) 基于评分选择关键短语。选择排名较高的词语或词组,或者含有排名高的词语的短语作为关键短语。
其中,“对候选关键短语进行评分和排序”是无监督关键短语抽取的核心步骤。基于无监督方法的关键短语抽取可分为基于统计的方法、基于图模型的方法和基于语义信息的方法。基于统计法的基本思想是采用词语统计特征,例如,TFIDF值[3]、词语共现统计、词语位置[4]等信息,计算候选短语的得分,并设定阈值来选择关键短语。基于图模型的方法的基本思想是: 基于文档内容分析创建短语关系图,该图的节点是候选关键短语,边连接语义相关的短语。然后采用图排序的方法,例如,TextRank[7]和SGRank[8]等,利用统计、位置和词共现等信息对节点进行评分和排序。基于语义信息的方法则是将词语的深度语义信息用于关键短语的判断。例如,通过实体链接技术将文档中的名词和命名实体链接到DBpedia以获取其语义信息[9],将名词短语链接到相关的维基页面以获取它们的语义信息[10]。在词语的分布式表示方法成熟之后,很多研究者运用Word2Vec等模型对词语进行编码以获取它们的语义信息[11]。
基于有监督的关键短语抽取方法可分为基于传统机器学习和基于深度学习两种。基于传统机器学习的关键短语抽取方法包括: 采用朴素贝叶斯、随机森林等分类器,基于词语的TF-IDF值,首次出现位置[12]、是否维基/IEEE词条等信息[13],对候选短语进行分类;采用CRF等序列标注方法,基于词语的语言学信息、结构信息以及专家知识和领域知识,对语句中的词语进行标注以识别关键短语[14]。
在训练数据充足的情况下,采用深度学习方法进行关键短语抽取能够取得更好的性能。例如,采用循环神经网络获取词语语义信息,并结合序列标注以提取关键短语[6];采用端到端的生成式方法,基于Encoder-Decoder架构,直接生成关键短语[15]。为了解决短语抽取结果存在重复或者缺失的问题,Chen等[16]提出CorrRNN以反映关键短语之间的相关性。为了提高性能,Rush[17]采取联合学习思想,把短语生成和标题生成任务进行联合训练。Wang等[18]采取迁移学习思想,将其他任务的标注数据用到短语抽取任务中。
由于缺乏大规模标注数据集,实际应用系统大多采用无监督方法进行关键短语抽取。其中,对于短文档,基于图模型的方法效果较好,而对于长文档,基于统计的方法效果较好。如果训练数据充足,采用深度学习方法进行关键短语抽取的效果最好。基于有监督方法的关键短语抽取的性能瓶颈在于训练数据,因为关键短语的标注十分依赖主观判断,而且关键短语和非关键短语的数据不平衡问题非常严重。
大部分关键短语抽取的评测数据集是英文的,例如,DUC-2001[19]和KP20k[15],因此关键短语抽取算法也主要针对英文进行设计和实验。无论采用无监督方法还是有监督方法,目前关键短语抽取结果在很多情况下依然无法达到理想的结果。基于公开数据集的评测结果显示,最好的英文关键短语抽取结果的F1值不超过0.6。近几年来,基于大规模语料预训练的文本表征模型,例如,BERT[20],在众多自然语言处理任务中表现出卓越的性能,因此采用这些模型来改进关键短语抽取效果是一个十分值得研究的方向。
2 基于统计特征和图模型的半监督式中文关键短语抽取算法
本文提出的中文关键短语抽取算法,命名为CnKPRank(Chinese Keyphrases),其主要步骤(图1)的介绍如下。
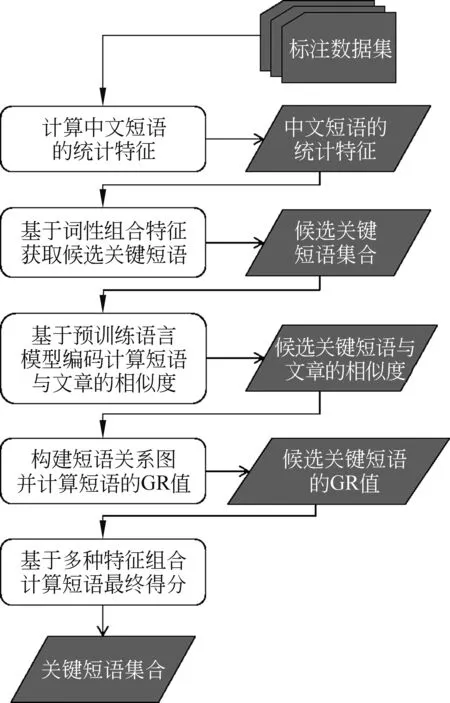
图1 CnKPRank的中文关键短语抽取基本流程
2.1 计算中文关键短语的统计特征
CnKPRank属于半监督的方法。首先需要少量带标注的数据,即含有关键短语标签的文本,用于分析关键短语的统计特征,包括词性组合、位置、长度等信息。词性组合特征是指构成短语的词语的词性,例如,短语“机器学习”的词性组合为“n+vn”,即由名词和动名词组成;位置特征是短语在文章中的相对位置;长度特征是指短语含有的字符的数量。
文章的关键短语会呈现一定的统计规律性,例如,关键短语经常由名词组成,出现在文章的前半部分,并以4个字符组成。因此,短语的统计特征可以用于选择候选关键短语(2.2节),以及辅助判断关键短语(2.5节)。在短语的统计特征的基础上,CnKPRank的关键短语抽取流程采用第2节“背景及相关工作”所述的无监督式流程进行设计,即首先获取候选关键短语,然后计算每个候选关键短语的得分,并基于得分选择最终的关键短语。
2.2 基于词性组合特征获取候选关键短语
候选关键短语的获取以分词之后的语句为基础,基于词性组合的规则匹配,从语句中筛选出候选短语。基于统计得到的中文关键短语的常见词性组合,我们设计相应的词性组合规则。例如,基于论文的keywords(即由作者给出的关键短语)的统计,关键短语的常见词性组合如下:
(1) n,即一个名词;
(2) n+n,两个名词的组合;
(3) gb/gc/gg/gm/gp,生物/化学/地理/数学/物理等学科的相关词汇;
(4) vn+n,动名词和名词的组合;
(5) n+v,名词和动词的组合。
基于词性组合的统计结果,可采用下述正则表达式获取候选关键短语:
?
为了避免将一些无意义的词语误判为候选关键短语,如“这个”“它”“我们”等,在运用上述正则表达式筛选候选短语之前,需要把将语句中的停用词的词性修改为“NA”(即not available,不可用)。
筛选出来的候选关键短语的信息包括: 位置信息和词性组合信息。位置信息的表达方式为: (句子编号,短语在句子中的起始位置,短语在句子中的结束位置),例如,“(1,3,5)”表示候选关键短语在文章的第一句话,并且由该句中的第3~5个词组成。词性组合信息即该短语中每个词的词性,例如,“(n,vn)”表示该短语由词性为n(名词)和vn(动名词)的词语组成。
2.3 基于预训练语言模型编码计算短语与文章的相似度
运用预训练语言模型(如BERT),对词语进行编码,生成词语的向量表示。需要说明的是,同一词语在不同句子中的向量表示可能不同。基于词语的向量表示,采用下述方法生成文章的主题向量表示:
(1) 构建主题词性集。基于2.1节介绍的中文短语统计结果,将关键短语中经常出现的词性合并整理为主题词性集。例如,主题词性集为: {n,vn,v,nz,a,ng,b,vi,q,ns,gi,gm}。一般地,主题词性集里的词性包含在前一步骤所述的正则表达式内。特别地,gi和gm是由g.*产生的;
(2) 从文章中筛选出词性为主题词性的词语,称为主题词;
(3) 将所有主题词的向量表示进行累加并求平均,得到文章的主题向量表示。
同理,候选关键短语的向量表示的计算方法为: 将短语中的词语的向量进行累加并求平均,得到短语的向量表示。由于不同位置的词语的向量表示可能不同,因此不同位置的短语的向量表示也可能不同。
本文采用余弦相似度,计算短语与文章的相似度,如式(1)所示。
(1)
其中,Ep= {ep1,ep2,…,epn}表示短语p的向量表示,Ed= {ed1,ed2,…,edn}表示文章d的主题向量表示。如果某个候选关键短语在多个句子中出现并存在多种向量表示,那么需要计算该短语的每个向量表示与文章主题向量的相似度,并将其中值最大者作为最终的相似度。
在计算出每个候选关键短语与文章主题向量的余弦相似度之后,将这些相似度值进行归一化。以sim(p,d)表示短语p与文章d的相似度,即余弦相似度的归一化值。
2.4 构建短语关系图并计算短语的GR值
用图G= {V,E}表示短语关系,其中,V是该图的节点集,每个节点对应一个候选关键短语。E是图G的连线集。如果两个候选关键短语出现在同一个句子中,而且在同一窗口内(窗口尺寸设置为5个词语),那么这两个关键短语对应的节点会有连线。连线的权重为节点对应的短语出现在同一窗口内的次数。
候选关键短语的图序特征值,即GR值(graph-based ranking)值由式(2)进行计算。
(2)
各个变量的说明如下:
●pi和pj表示候选关键短语。gr(pi)和gr(pj)分别表示pi和pj的GR值。各个候选关键短语的GR值的初始值设置为1/k,其中,k为候选关键短语的数量。
●Mi表示与pi有关联(即有连线连接)的节点的集合。o(pj)表示与pj有关联的节点的数量。
●wij表示pi和pj的连线的权重,即pi和pj同在一个窗口的次数。
● sim(pi,d)表示pi与文章d的相似度。
●z表示候选关键短语与文档的相似度在短语选择方面的权重,取值在0~1之间。
基于式(2),依次计算每个候选关键短语的GR值。上述过程需要迭代多个轮次,直到短语的GR值的变化小于一定阈值。
2.5 基于多种统计特征组合计算短语复合重要度
由于短语的词性组合、长度、位置等特征对判断它是否为关键短语都十分重要,因此候选短语的最终得分的计算需要综合考虑上述特征。我们设计式(3)来计算候选关键短语的复合重要度。
s(pi)=gr(pi)+pos(pi)+pst(pi)+len(pi)
(3)
其中,pi是候选关键短语。s(pi)表示pi的复合重要度,gr(pi)是pi的GR值,pos(pi)是pi的词性组合特征值,pst(pi)是pi的位置特征值,len(pi)是pi的长度特征值。
如2.1节所述,需要少量的带标注数据来计算短语的统计特征。短语的词性组合特征值(即pos)是该短语的词性组合出现在标注数据集的概率值。例如,词性组合“n+n”在标注数据集的所有短语中出现了100次,而所有短语的数量为1 000,那么词性组合“n+n”的特征值为0.1。同样地,短语的位置特征值(即pst)和长度特征值(即len)是它们的位置和长度出现在标注数据集的概率值。pos、pst、len的具体计算方法可参见3.2节。
基于式(3)计算出每个短语的最终复合重要度,重要度排名靠前的候选短语被认为是关键短语。按照具体的要求,可以选取前K个候选短语作为最终的关键短语,也可以将得分大于(预先设定的)阈值的候选短语选为关键短语。
3 中文关键短语抽取实验
3.1 数据获取及预处理
中文期刊论文大多含有关键词标签,而且关键词由作者给出,一般能够准确地反映论文的主题和内容。我们以论文的标题和摘要作为待分析的文本对象,并以关键词作为相应的关键短语标签。我们从一些中文期刊网站上获取化学、物理、地理、计算机等领域的中文期刊论文的元信息,包括标题、摘要和关键词。这些论文数据作为分析关键短语的统计特征的基础数据,并用于测试算法的性能。
为保证数据质量,本文采用以下措施进行语料筛选: ①文本乱码比例小于3%; ②关键词的数量超过3个; ③关键词全部出现在摘要或标题当中。满足以上三个条件的论文共计5 939篇,这些论文的集合记为P。去除文本中的乱码等噪声后,我们使用HanLP[21]对论文的摘要和标题进行分词。
3.2 数据统计分析
论文集合P共有68 139个关键短语标签(即论文的关键词),包含26 868个非重复的关键短语。基于这些数据的统计特征分析结果如下。
3.2.1 关键短语词性统计分析
(1) 词性组合统计
论文集P的关键短语共计3 016种词性组合,排名前10的词性组合见表1。
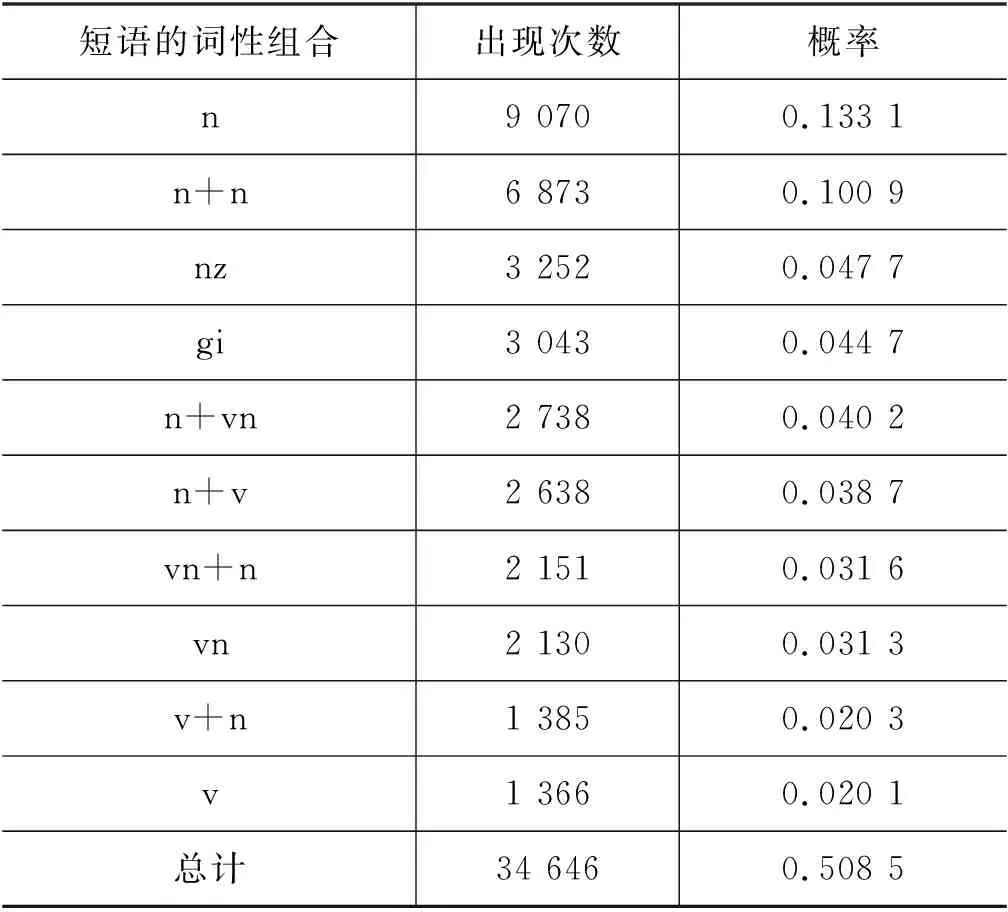
表1 关键短语词性组合的统计结果
Top10的词性组合的概率总计只有50.85%(1)概率计算的基数为68 139,即P中关键短语的总数。,可见中文短语词性组合的多样性。我们统计了词性组合排名前N的概率情况,如表2所示。
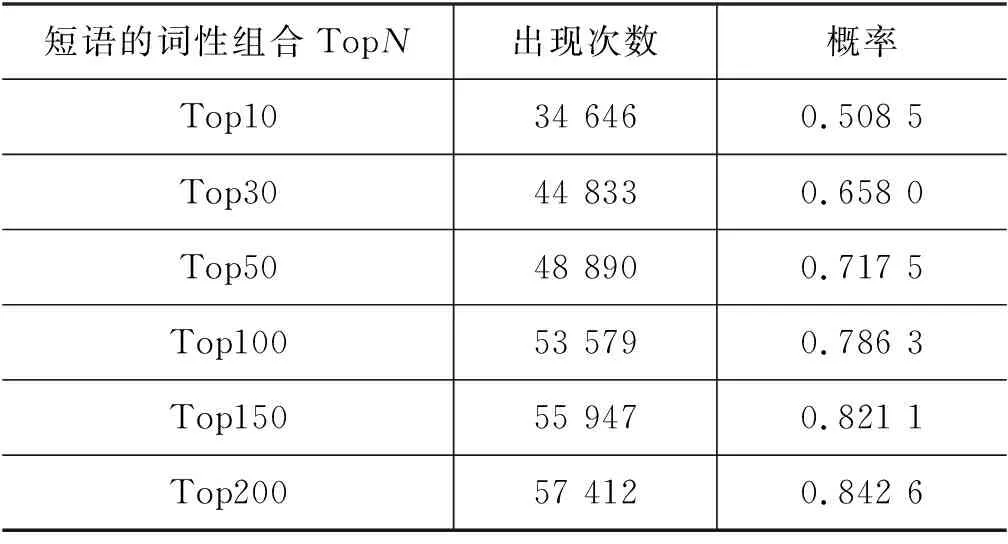
表2 关键短语词性TopN的统计结果
基于词性组合的统计结果,选用合适的筛选方法以获取大部分候选短语。例如,2.2节介绍的词性组合筛选正则表达式,是按照前35名的词性组合(出现了至少250次)以及专业词汇词性(以'g'开头)进行设计的。该词性组合规则最终获取了超过90个词性组合,因为有些专业词汇词性(如: 'gg')不在前35名当中。最终,该词性组合可以获取论文集P内的73%的关键短语。
式(3)中,短语的词性组合得分pos(pi)即为表1所示的概率。
(2) 词性统计
将关键短语中的词语进行统计和词性分析,共有131 484个词语,76种词性。排名前10的词性见表3。
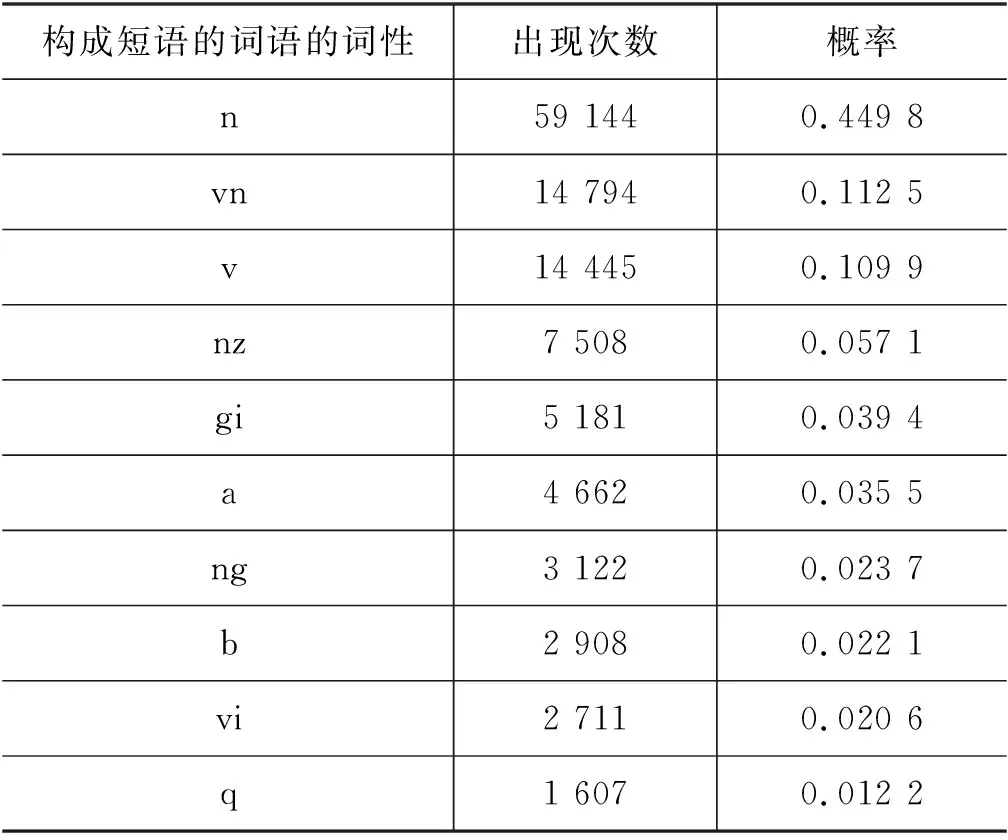
表3 关键短语词性的统计结果
2.3节的主题词性集可以由出现次数较多的词性和学科相关的词性组成。例如,以排名前10的词性及专业词汇的词性组成的主题词性集为: {n,vn,v,gi,nz,a,ng,b,vi,q,ns,gm,gp,gb}。
3.2.2 关键短语的长度统计
关键短语的长度即它含有的字符数量。基于论文集P的统计结果,关键短语长度排名前10的情况见表4。
式(3)中,关键短语的长度得分len(pi),就是表4所示的概率。此时概率计算的基数是26 868,即非重复的关键短语的数量。由于短语的长度是固定的,采用非重复的关键短语为基数进行概率计算能更好地显示不同短语的分布情况。而在词性组合统计中,由于词语在不同文本中的词性可能不一样,所以只能以词性总数(或词性组合总数)作为概率计算的基数。同样地,在短语位置统计中(3.2.3节),由于短语不同文本中出现的位置可能不一样,也只能采用关键短语标签的总数作为概率计算的基数。
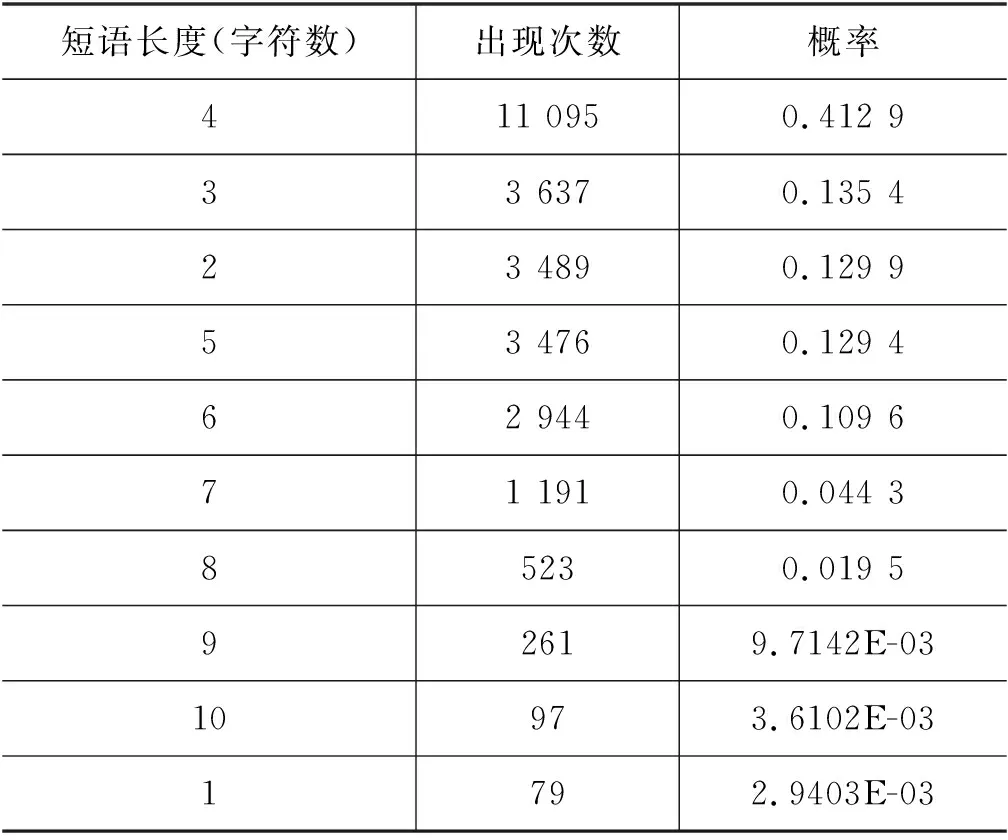
表4 关键短语长度的统计结果
3.2.3 关键短语的位置统计
关键短语在文章中出现的位置也有一定的规律,一般地,出现位置越靠前概率越高。关键短语出现位置的统计结果如表5所示。

表5 关键短语出现位置的统计结果
表5中,位置“0~10%”表示,短语的首字符出现在文章的前10%文本内。式(3)中,短语的位置得分,pst(pi)即为表5所示的概率值。
3.3 实验结果以及分析
3.3.1 实验对比模型
我们从论文集P中随机抽取1 000篇论文作为算法的测试集(记为C),并与多种现有方法进行了对比,包括TFIDF、TextRank[22]、TopicRank[23]、PositionRank[5]和SIFRank[24]。其中SIFRank在英文数据集上取得了关键短语抽取的SOTA结果。同时,我们对CnKPRank算法进行了消融实验,具体对比了以下几个方面。
(1)POS-removed: 在候选关键短语的选择方面,不使用我们统计出来的关键短语的词性组合特征,而采用较为普通的词性组合,以扩大候选关键短语的选择范围。
(2)SameSim: 在短语与文章的相似度方面,不采用式(1)来计算相似度,而是将所有短语向量与文章主题向量的相似度的值设置为相同的值,并进行了归一化。
(3)Sim-based: 将短语向量与文章主题向量的相似度作为候选短语的最终得分,省去GR值的计算,以及短语的词性组合得分、位置得分和长度得分的计算。
(4)GR-based: 将短语的GR值作为它的最终得分,而不考虑其词性组合得分、位置得分和长度得分。
3.3.2 实验结果的评价方法
我们采用以下三个方法选择关键短语,并分别计算算法的性能: 抽取5个关键短语,抽取10个关键短语,基于阈值抽取关键短语。“抽取5个关键短语”指的是: 算法取得分排名前5的短语作为关键短语,然后与测试集的结果进行对比。“抽取10个关键短语”则是指算法取得分排名前10的短语作为关键短语。“基于阈值抽取关键短语”的方法需要设置得分阈值t、关键短语最小长度min和最大长度max。在计算每个候选关键短语的得分之后,采用下述方法选择关键短语(假设得分大于或等于t的候选关键短语的数量为num)。
(1) 如果num介于min和max之间,则输出得分大于或等于t的候选关键短语作为最终的关键短语;
(2) 如果num小于min,则输出得分排名前min的候选关键短语作为最终的关键短语;
(3) 如果num大于max,则输出得分排名前max的候选关键短语作为最终的关键短语。
实验结果以部分匹配原则进行衡量,指标有精确率(P)、召回率(R)和F1值,分别介绍如下:
(1) 精确率(P): 如果算法输出的某个短语属于论文给出的关键词标签,则它是正确短语。精确率是正确短语数与算法输出短语总数的比值;
(2) 召回率(R): 正确短语数与论文的关键词标签总数的比值;
(3)F1值:F1=2PR/(P+R)。
例如,假设数据集C中某篇论文的关键词为7个,算法输出5个关键短语,其中两个属于论文给出的关键词。那么精确率P=2/5=40%,召回率为R=2/7=28.57%。
我们采用部分匹配法,而非精确匹配法(即算法输出的关键短语与文章的关键词标签在数量和内容上完全一致,抽取结果才算是正确的),因为精确匹配法的结果判断十分苛刻,导致各种方法的准确率和召回率都非常低,因此它们的实验结果没有显著区别。而基于部分匹配法来衡量中文关键短语抽取效果,不同方法的实验结果的区别比较显著(表6)。

表6 中文关键短语抽取对比实验结果
3.3.3 实验结果分析
从表6可以看出,本文方法相比TextRank,SIFRank等方法,在准确率和召回率方面都有大幅度提升。具体分析如下:
(1) 在消融实验采取的几个方法当中,POS-removed的效果最差,说明候选关键短语的选择对于关键短语抽取效果的影响是最大的;
(2) SameSim,Sim-based和GR-based的效果相比SIFRank等传统方法有很大提升,说明本文选择候选关键短语的方法性能十分有效;
(3) GR-based的效果稍微优于Sim-based,说明基于短语关系图的排序有助于提升关键短语抽取的性能;
(4) SameSim的性能比CnKPRank有所下降,说明短语与文章的相似度的计算,只能在有限的程度上反映短语的关键性;
(5) CnKPRank比Sim-based和GR-based的性能有较大提升,说明短语的统计特征(词性组合、位置和长度)得分,对判断关键短语十分有用,也说明了半监督式方法在处理该问题上具有优势。
4 结论
中文关键短语抽取目前缺乏针对性的研究,也缺乏标准的评测数据集。针对该问题,本文首先收集了一些中文论文及其关键词标签,构建出中文关键短语抽取的评测集。在算法方面,我们采用半监督式方法,运用词性组合特征获取候选关键短语,并采用基于预训练语言模型编码的相似度评估、基于图的排序、基于统计特征得分等方式,计算短语得分并依此来选择关键短语。相比SIFRank等在英文数据集上表现很好的方法,我们的方法在中文关键短语抽取的准确率和召回率方面都有明显提升。
从实验结果可以看出,中文关键短语抽取的准确率只有30%左右,相比英文的关键短语抽取的效果相差较多。其部分原因是中文的复杂性比英文更高,且规范性更差。在中文关键短语抽取领域,我们认为以下问题值得进一步研究:
(1)优化候选关键短语的选择。候选关键短语的选择是关键短语抽取任务的重点和难点,具有较大的提升空间和研究价值。从短语的词语构成、词性构成、语法结构等方面进行深入研究,有助于提升关键短语选择的效果。
(2)抽取未在文本中出现的关键短语。目前方法抽取出的关键短语都曾出现在文本中,而测试集中的有些关键短语并没有直接在文本中出现。抽取出不曾出现在文本中的关键短语也是一个有价值的研究方向。
猜你喜欢
中老年保健(2022年1期)2022-08-17
客联(2022年3期)2022-05-31
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2017年7期)2017-05-06
海峡姐妹(2016年2期)2016-02-27
传记文学(2014年8期)2014-03-11
中国商人(2013年1期)2013-12-04
中国商人(2013年1期)2013-12-04
