
基于ZYNQ的卷积神经网络加速器设计
2022-06-23 11:11顾明剑曾长紊邵春沅范余茂
计算机工程与设计 2022年6期
吴 健,顾明剑,曾长紊,邵春沅,范余茂
(1.中国科学院 上海技术物理研究所,上海 200083;2.中国科学院 上海技术物理研究所 红外成像与探测重点实验室,上海 200083;3.中国科学院 上海技术物理研究所 苏州研究院,江苏 苏州 215000;4.中国科学院大学,北京 100049)
0 引 言
随着深度学习在人工智能领域的发展,已经展示出了它在解决复杂学习问题上的能力和有效性。然而卷积神经网络(CNN)要求强大的CPU计算能力和内存带宽,使得普通的嵌入式CPU无法满足实际的需求。因此,专用集成电路(ASIC)、现场可编程门阵列(FPGA)和图形处理单元(GPU)的硬件加速器被用来提高卷积神经网络计算的吞吐量[1]。但GPU和ASIC分别有着功耗大和不灵活的缺点[2-4],而FPGA却能以较低功耗实现中等的性能[5],以合理的成本提供高吞吐量、低功耗和可重构性[6]。另外Xilinx提供的高层次综合工具(HLS)进一步降低了设计的难度,缩短了基于FPGA硬件加速器的开发时间[7]。
本文使用HLS工具对加速器进行设计,将浮点型参数转换成16 bit动态定点型参数,利用FPGA中BRAM资源对特征及权重进行双缓存,使用乒乓操作及流水线的形式对数据进行搬运,显著减少了频繁访问片外内存所带来的时间开销。为了更好利用AXI总线的带宽,采用多位宽并行传输和突发传输的方法,有效提高了总线传输效率。在卷积计算中对不同层多路特征并行计算,充分运用FPGA中DSP资源,提高运算效率。最终将CNN加速器部署到PYNQ-Z2上,并与之前的工作进行了比较,结果显示该架构加速性能优于其它设计。
主要创新工作如下:①将相邻特征层数据在内存中进行合并,增加数据传输并行度的同时节省了通道的使用;②改进输入输出模块,采用多通道、相邻层参数合并、参数重排序结合的方法提高了传输速率,提高总线带宽利用率。
1 卷积神经网络基本概念

(1)
式中:bi为偏置,N为输入特征层个数,M为输出特征层个数。卷积计算可用伪代码表示如下:
I[N][(R-1)*S+Ky][(C-1)*S+Kx]//input features
O[M][R][C]//output features
W[M][N][Kx][Ky]//weights
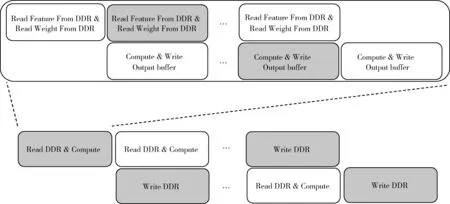
for(m=0;m for(n=0;n for(r=0;r for(c=0;c for(i=0;i for(j=0;j wx=W[m][n][i][j]; ix=I[n][S*r+i][S*c+j]; O[m][r][c]+=wx*ix;}}}}}} 伪代码中I、O、W分别代表存放在外部存储器中的输入特征图、输出特征图和卷积核参数。其中R、C、S、Kx、Ky代表输入特征图高度、输入特征图宽度、步长、卷积核宽度、卷积核高度。 池化层一般使用最大值池化对输入特征进行降采样,减少数据量同时增加鲁棒性。伪代码表示如下所示: for(r=0;r for(c=0;c for(m=0;m O[m][r][c]=max(I[n][r*S+Ky][c*S+Kx]);}}} 全连接层对输入进行特征空间的线性转换,对输入特征进行加权从而得到输出,全连接层可由卷积操作实现 (2) 由于训练后的神经网络参数对噪声具有一定的鲁棒性,因此将训练后的特征及权重参数量化处理后,卷积神经网络的前向推理仍然能够得出一个准确的结果。将神经网络中32位浮点数类型的参数量化成更少位宽的浮点数能够减少前向推理的计算量,减少权重所占用的存储空间,提高运算速度,能够更方便部署在移动端内存有限的嵌入式设备中。 在对精度较高的数据转化成低精度数据时,如果使用固定精度进行定点量化,随着量化后的数据精度的降低,结果的准确性也会降低。然而在相同位宽数据情况下,使用动态定点数量化的方法,数据的准确性更高。本设计希望能够实现高性能的同时得到较好的数据精度,因此将32位特征数据和权重参数量化为16动态定点数,根据不同特征层数据的动态范围对其进行量化。 定点数可以表达为 (3) 式中:xfixed为补码形式,最高位为符号位,bw代表定点数位宽长度,exp代表阶码。动态定点数量化就是希望找到最优的阶码expb使得原始数据xfloat与定点化后数据绝对误差和最小,即 (4) 式中:x(bw,expb) 表示在给定阶码和定点数位宽下由定点数转换回浮点数的值。根据上式对每一层输入输出特征,权重参数和偏置参数找到对应的最优阶码,量化成16位定点数后卷积的浮点数乘累加运算可使用定点数乘法加法和移位操作来实现,显著减少浮点数运算带来的DSP资源的消耗。 ZYNQ系列FPGA的PS端包含4个AXI_HP接口,主要用于PL访问PS上的外部存储器。每个HP接口拥有独立的读写通道,主从设备之间能够同时进行双向传输,AXI4协议数据传输最大突发长度为256。 卷积计算中特征数据、权重数据、偏置数据相互独立,数据的获取可以同时进行。因此可以在加速器内部分别设置输入模块与HP接口读通道相连接,能够提高数据并行度。 由于只需要将输出特征写入外部存储器,因此HP接口的写通道专门用于传输输出特征数据。可将输出特征层按M维度进行划分,采用多个写通道并行输出的方法将输出特征写入外部存储器。 因为FPGA内部资源的限制,输入特征值、权重数据以及中间结果都需要保存至外部存储器中。与片上内存访问相比较,访问外部DRAM的代价是更高的延迟和功耗。因此减少外部存储器访问的次数,对于提高整体计算性能和能量效率是很重要的。 通过量化操作后,卷积计算所需要的特征数据和权重数据变为16位定点数。加速器通过AXI_HP接口访问外部存储器通过突发传输的方式获取数据,默认的数据位宽为64位。若只用来传输16位的数据并没有完全利用AXI总线传输带宽,因此对特征和权重数据进行处理,将相邻TN层特征数据、权重数据合并为16×TNbit数据,储存在外部存储器中,如图1所示。相较于用多通道同时传输不同特征层的方法,采用数据合并的方式在节省传输通道的同时增加了实际带宽利用率。 图1 相邻特征层数据合并 从外部存储器读取数据的带宽还与数据的突发长度有关。对于获取同样大小的数据,突发长度越长,传输的时间越小。为了能够使得数据以较大的突发长度进行传输,对权重数据在内存中进行了重新排布。 权重参数是一个4维的数据,分别为卷积核个数M,卷积核层数N以及卷积核大小Kx,Ky。假设一次传输需要将TM个卷积核的TN层权重参数搬运至片上缓存中 (TM≤M,TN≤N)。 此时存在着两种传输方案:①以Kx,Ky,N,M的优先顺序进行传输,突发次数为TM次,每次突发长度为TN×Kx×Ky。②以N,M,Kx,Ky的优先顺序进行传输,突发次数为Kx×Ky次,每次突发长度为TM×TN。 一般情况下TM大于Kx×Ky,因此第二种方案可以以较少的突发次数,较大的突发长度传输权重数据。 本章主要介绍硬件加速器的基础架构,它由特征输入模块、权重输入模块、运算模块、特征输出模块组成。加速器通过AXI lite接口与PS端GP接口连接负责配置控制寄存器、状态寄存器、读写地址等。输入输出模块提供的AXI master接口与PS端DDR的HP接口连接进行特征、权重及偏置数据的传输。每个输入模块拥有一个独立的AXI master读通道,将外部存储器中的数据读入输入内部缓存区中。特征输出模块同时使用3个AXI master写通道将输出缓存区的数据并行搬运至外部存储器。 卷积池化计算模块从输入内部缓存区中同时取出多通道数据,并行计算后将输出特征写入输出内部缓存。如图2所示为硬件加速器的内部架构。 图2 硬件加速器内部架构 部分内部存储区包含两个大小相同的存储块,目的是为了对外部存储器取出的数据进行乒乓缓存。由于偏置参数数据量较小,因此偏置参数缓存区只设置一个缓存块,在每次计算前将所有的偏置参数搬运至偏置缓存区中。 加速器的工作时序如图3所示。将读外部存储器、运算和写外部存储器作为一个周期,以流水线的形式进行,Read DDR & Compute操作所消耗的时间与Write DDR操作所消耗的时间重叠,减少操作延时。进一步的将Read DDR & Compute操作展开为两部分操作,第一部分是读取外部数据至输入片上缓存区,第二部分是运算并将运算结果写入输出片上缓存,这两部分同样以流水线的形式进行操作。 图3 加速器工作时序 以卷积计算为例,设计的卷积加速器对应伪代码如下所示: I[N][(R-1)*S+Ky][(C-1)*S+Kx];//input features O[M][R][C];//output features W[M][N][Kx][Ky];//weights Ibuffer[TN][(Tr-1)*S+Ky][(Tc-1)*S+Kx];//input buffer Obuffer[TM][Tr][Tc];//output buffer Wbuffer[TM][TN][Kx][Ky];//weight buffer for(r=0;r for(c=0;c for(m=0;m /*************** Block compute **************/ for(n=0;n //---------------------- Inner compute ---------------------- for(ky=0;ky for(kx=0;kx for(tr=0;tr+r for(tc=0;tc+c for(tm=0;tm for(tn=0;tn //--------------- /******************************************/ Ibuffer、Obuffer、Wbuffer、Bias分别表示加速器内部输入片上缓存、输出片上缓存、输入权重缓存和输入偏置缓存。 输入特征子块的宽度Tcol和高度Trow由输出特征子块的宽度Tc、高度Tr、卷积核大小Kx、Ky和步长S决定 Tcol=(Tc-1)×S+Kx (5) Trow=(Tr-1)×S+Ky (6) 将代码中Block compute展开如图4所示。每次读取TN张输入特征层的Trow×Tcol小的像素块,循环N/TN次遍历完输入特征所有通道。每次读取TM个TN×Ky×Kx大小的权重参数,循环N/TN次遍历完对应输入特征所有通道的权重参数。输入特征存储子块乒乓读取特征输入数据,输入权重存储子块乒乓读取卷积核权重数据,每次计算完的结果累加到输出特征存储子块中。每次计算都会得到TM张Tr×Tc大小的特征存入输出特征缓存中,下一次的结果与这一次的累加,累加N/TN次后得到最终累加结果。这便完成图3中一次Read DDR & Compute操作,输出特征缓存中累加的数据在下一个时钟的Write DDR操作写入外部存储。 图4 特征子块运算 下面分别对各个模块的设计进行介绍。 特征输入模块负责将DDR中的特征数据读入片上缓存,采取相邻特征层多位宽合并的传输策略,将TN个相邻层的16 bit定点数特征值进行合并,如图5(a)所示将特征在内存中重新排列后,数据长度变为16×TNbit,这样一次读操作可以从DDR中同时读取TN个特征值,减少访存次数,充分利用AXI总线带宽。但由于片上存储空间的限制无法将输入特征数据一次性全部读入片上缓存中,只能对输入特征分块的方式进行读取,即每次读取TN张Tcol×Trow大小的特征子块到片上缓存。 为进一步减少数据读写所消耗的时间,使用两个行缓存进行乒乓操作。将特征输入过程分为两个过程,第一步先计算出外部存储起始地址、片上缓存地址,并将特征拷贝到行缓存中。第二步将行缓存中的特征数据拷贝到相应的片上内部缓存。如图5(b)所示,双缓存设计使得这两部分操作延时相互重叠,减少数据的传输时延。 因为行缓存占用的存储空间较小,因此使用LUT RAM作为输入特征数据行缓存。输入行缓存使用LUT构成片上RAM,所消耗的片上存储资源如下 (7) 其中行缓存大小需要满足SizeIn≥Tcol,Bitwidth为单个数据宽度为16 bit。LUT支持一次性1 bit或2 bit读写,因此存储一个16 bit数据需要消耗8个LUT,32为LUT深度。 输入特征缓存区所消耗的BRAM资源计算公式为 (8) COneBRAM表示单个片上BRAM的存储容量18 Kb。 图5 特征在内存中排布和读取时序 与特征输入模块设计相同,权重输入模块的工作是将DDR中的权重数据搬运到片上缓存。如图6(a)所示权重数据也按照相邻层位宽合并原则将相邻层合并成为一个权重子块,N为输入特征通道数,M为卷积核个数,TM为片上缓存能储存的最大卷积核个数。为了与输入特征子块对应需要先将0~TM-1卷积核的第一层特征子块传入片上缓存然后进行计算,再将0~TM-1卷积核的第二层特征子块传入片上缓存进行计算,直到0~TM-1卷积核所有层计算完成后再将TM~2×TM-1的卷积核读入片上缓存,以此类推。 图6 权重在内存中的排布和读取时序 为了进一步增加AXI总线数据传输时的突发长度,减少突发次数,需要对权重在内存中进行重新排布,将Kx,Ky,N,M的优先顺序排布方式改为以N,M,Kx,Ky的优先顺序排布。以这样的方式完成一次内部缓存数据的写入总共需要Kx×Ky次突发传输,每次突发长度为TM。而排布前需要TM次突发传输,每次突发长度为Kx×Ky。以TM=24,Kx=Ky=3为例,排布后需要读取9次长度为24的数据。而排布前需要读取24次长度为9的数据。 在权重输入模块中同样也使用了乒乓操作,使用两个行缓存交替的读取DDR中数据,并交替的将行缓存中的数据存入片上权重缓存,使得从DDR中读取数据写入行缓存的时延与从行缓存中读取数据写入片上权重缓存的时延相重叠,如图6(b)所示。 权重输入行缓存所消耗的片上LUT资源计算公式如下 (9) 其中行缓存大小需要满足SizeWeight≥TM。 输入权重参数缓存区消耗的BRAM资源的计算公式为 (10) 由于偏置参数所占用内存较少,因此通过AXI接口将偏置参数一次性导入内部缓存中,不需要消耗行缓存资源。 运算模块包含卷积计算和池化计算,卷积计算使用的乘累加运算需要消耗大量的DSP和LUT资源[8]。池化计算使用的比较器、多路选择器等主要消耗的是LUT资源,且资源消耗较少。 图7 卷积运算 本文设计中卷积计算中乘法器主要使用DSP资源实现,加法器使用LUT资源来实现。在输入特征通道数为TN,输出特征通道数为TM,16bit数据精度情况下,实现卷积计算中加法器和乘法器所消耗的DSP、LUT资源计算公式如下 NDSP=TM×TN×NMulDSP (11) NLUT=TM×TN×(NMulLUT+NAddLUT)+TM×NSelectLUT (12) 其中,16 bit精度下单个乘法器消耗的资源NMulDSP=1、NMulLUT=101,单个加法器消耗的资源NAddLUT=47,2选1选择器消耗的资源NSelectLUT=8。 最大池化模块功能是对每个输入特征层以Kx×Ky大小的窗口进行滑动,取窗口中的最大值作为输出特征层对应位置的特征值。图8最大池化模块采取TN个并行比较器,对输入特征缓存中TN个输入特征通道同时进行比较运算。每个时钟周期输入TN个特征值,分别与各自当前最大值进行比较,比较Kx×Ky次后得到的最大值作为输出特征值写到特征输出缓存中。 池化运算所使用的16 bit比较器需要消耗LUT资源NComLUT=16,寄存器需要消耗LUT资源NRegLUT=1。因此池化运算消耗的资源为 NLUT=TN×(NComLUT+NRegLUT+NSelectLUT) (13) 特征输出模块负责将片上缓存中的计算结果写入外部存储器DDR。与输入模块相同,对计算后的结果进行多位宽合并。且考虑到AXI接口的读写通道相互独立,读写操作能够同时进行,为充分利用写通道,采用多通道并行传输的策略。将特征输出片上缓存按照特征通道方向TM维度划分为3个部分,分别通过3个AXI接口写通道并行传输。 图8 池化运算 如图9所示,对每个AXI写通道都配备2个行缓存进行乒乓操作,使得偏移地址的计算、特征读入行缓存的时延与行缓存写入外部DDR的时延相重叠。 图9 特征输出时序 输出行缓存所消耗的片上LUT资源计算公式如下 (14) 其中行缓存大小需要满足SizeOut≥Tc。 输出特征缓存区消耗的BRAM资源计算公式为 (15) 输出特征缓存区需要保存卷积运算16 bit乘累加操作后的中间结果,因此输出特征缓存区的位宽设置为40 bit,避免数据溢出,BitwidthInter表示40 bit。需要由两块36 bit位宽BRAM组成,因此公式中乘以2。 实验中使用的平台为Xilinx PYNQ-Z2,内部资源包含650 MHz双核Cortex-A9处理器和Artix-7系列可编程逻辑器件。片上拥有4个高性能AXI从端口DDR3内存控制器,630 KB的快速Block RAM,220个DSP资源,53 200个LUT单元。 使用Vivado HLS 2018.3工具进行卷积神经网络加速器的设计,完成软硬件协同仿真后生成IP核,使用Vivado 2018.3添加约束进行综合以及布局布线,得到资源使用情况和时序分析报告。 所部署的CNN模型为YOLOv2和YOLO-Tiny(416*416)。在GPU平台上进行训练得到模型的权重参数。加速器中使用的具体参数如下:卷积层的输出并行度TM=24,输入并行度TN=8,输出特征缓存的宽高Tr=Tc=13,S=2,Kx=Ky=3。 根据具体参数和资源消耗计算公式,对资源消耗量进行估计。乘法器主要用于卷积模块的运算,按照式(9)计算得到消耗192个DSP,与表1中实际消耗量对比,实际中还有部分DSP用于计算地址的偏移等运算。根据式(10)和式(11)可计算出运算模块消耗LUT资源为28 808,根据式(7)、式(9)、式(14)可计算出行缓存消耗的LUT资源为640。其余LUT用于其它模块的计算。BRAM资源主要用于的片上缓存以及AXI接口缓存的实现。根据式(8)、式(10)、式(15)计算可得输入特征缓存消耗为(1×8×2),输出特征缓存消耗为(2×24×2),输入权重缓存为(1×24×2),偏置缓存为1,AXI接口缓存3×2。因此计算得共消耗177个BRAM_18K,即83.5个BRAM_36K接近实际消耗个数。 表1 FPGA资源消耗 加速器的资源消耗情况见表1,在使用相同Zynq7020平台的条件下,相比于文献[9],本文的方法更加充分的使用了片上的DSP资源,使用率达到94%,并且节省了HP接口的使用。 本文使用的方法与之前的工作相比也取得了更好的性能。见表2,文献[9]使用多个通道进行数据传输,但每个通道只传输16 bit数据,数据的传输受到通道数量的限制。文献[10]中的时钟频率很高,但是运算模块中卷积和全连接计算采用不同设计,资源利用率较低。由于本文采用了多位宽合并的方法,减少通道数的同时,增加了计算单元的并行度,因此提高了运算性能。 表2 与其它FPGA平台比较 同时,对比YOLOv2在Xeon CPU上的计算性能4.11 GOP/s,和双核ARM-A9上的性能0.27 GOP/s,本文的设计性能有很大的提升。与intel i5-2400 CPU性能相比是其3.4倍,是ARM-Cortex A9 CPU的147.5倍,且在计算功耗上占有很大的优势,能够实现在低功耗场景下的高性能计算,具体性能参数见表3。 表3 与其它CPU平台比较 使用测试集中的图片进行检测,得到的检测效果如图10所示。 图10 检测效果 本文设计并实现了一种CNN硬件加速器,利用乒乓缓存、参数重排、相邻层数据合并及多通道传输等策略减少数据传输时延。对卷积计算进行分解,利用并行计算、参数复用等策略减少计算时延。并对加速器的资源消耗进行分析和估计。在PYNQ-Z2平台上进行部署,实现了94%的DSP资源利用率、计算性能达到39.39 GOP/s。通过与CPU平台及相同FPGA平台上的比较,本文的设计有着更低的功耗、更高的计算性能和FPGA资源利用率。2 加速器优化策略
2.1 动态16位定点数量化
2.2 多通道并行传输
2.3 相邻层多位宽合并
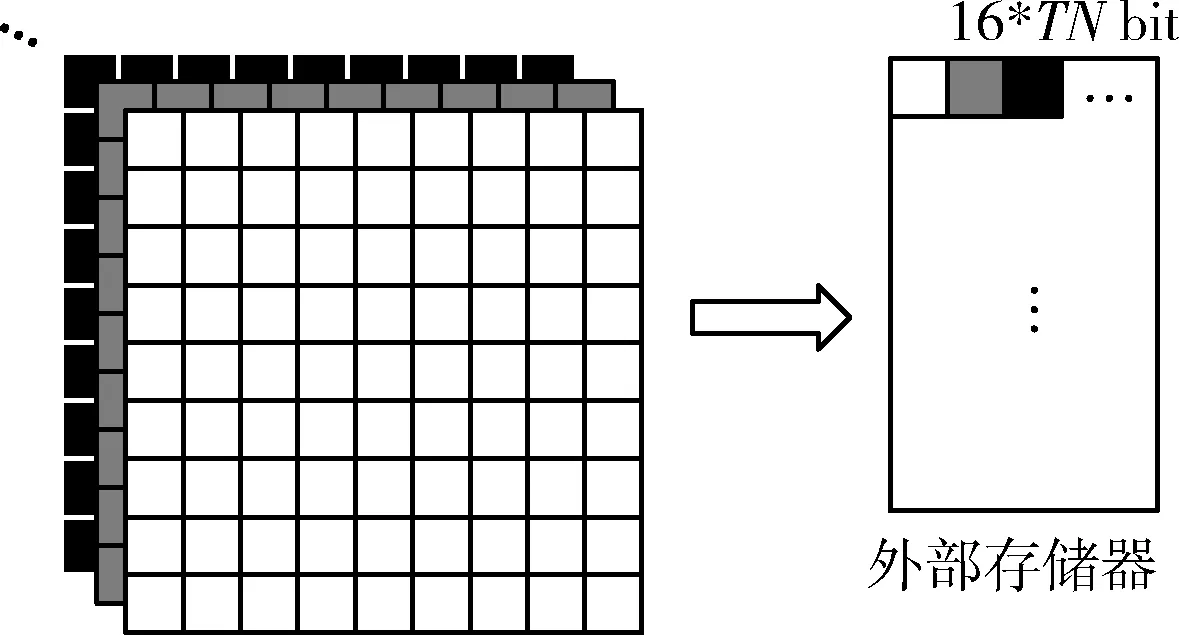
2.4 权重数据重排列
3 加速器架构设计




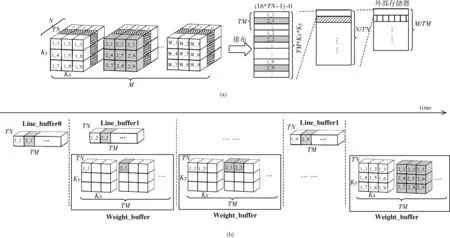
3.1 特征输入模块


3.2 权重输入模块
3.3 运算模块

3.4 特征输出模块


4 实验结果分析
4.1 实验环境
4.2 实验结果与分析




5 结束语
猜你喜欢
昆钢科技(2022年4期)2022-12-30现代装饰(2022年5期)2022-10-13小哥白尼(趣味科学)(2022年5期)2022-08-15心理学报(2022年5期)2022-05-16昆钢科技(2022年1期)2022-04-19少先队活动(2021年6期)2021-07-22昆钢科技(2021年6期)2021-03-09当代陕西(2020年17期)2020-10-28小学科学(学生版)(2019年4期)2019-05-11人大建设(2018年5期)2018-08-16
