
基于GitHub数据的安全性需求用户故事生成
2022-06-23 11:00张晓妘郑丽伟
计算机工程与设计 2022年6期
张晓妘,郑丽伟
(北京信息科技大学 计算机学院,北京 100101)
0 引 言
在开发大型软件项目的过程中,软件需求通常频繁变更并且该过程通常贯穿整个软件开发周期,开发者需要经过长时间的反复发现和认识才能逐步明确软件需求。因此,软件开发者也开始逐渐将一部分的注意力从软件开发编程阶段转移到了软件需求设计阶段以减少软件产品的迭代次数。软件需求按照软件功能性可以分为功能性需求和非功能性需求两类[1]。相较于功能性需求,软件的非功能性需求往往具有较大的隐含性和不确定性,难以准确获取。
近年来,针对软件需求的表示、抽取、挖掘等工作取得显著成果,但也存在用户需求数据较难获取,数据种类较单一,挖掘结果易受领域局限等问题。针对这些问题,我们认为通过机器学习方法从GitHub等软件开发类社交平台的海量数据中发现潜在的软件非功能需求是一种可行的思路。本文以软件非功能性需求中较为重要的安全性需求作为切入点,以GitHub中庞大的Issues讨论数据作为挖掘对象,利用自然语言处理中的实体识别技术对句子中的连接实体进行识别并在此背景下设计出了一种用户故事生成方法——CreUS用户故事生成方法,旨在将抽取到的用户安全需求以用户故事这种结构化的方法表示出来。所生成的用户故事集,不仅可用于支持Issues所在项目的开发迭代,还可以作为领域知识,在同领域类似项目的需求发现中起到重要的参考和辅助作用。
1 研究背景
1.1 需求工程
在计算机刚刚发展起来的阶段,人们对于软件项目的开发大多关注在如何更好进行代码编写上。随着编程技术发展的日趋成熟,人们开始将更多的焦点转移到了需求分析上。一开始,软件需求分析阶段仅仅只是作为软件开发生命周期中的第一阶段,随着软件项目规模不断扩大,其复杂性也相应增加,需要被满足的功能愈来愈多。伴随着诸多问题的产生,人们意识到如果只是把需求分析阶段作为一个开发过程中的阶段是不够的,也许在软件开发整个生命周期中都会伴随着需求的增加与改进。在80年代中期,需求工程(requirement engineering,RE)作为软件工程的一个子领域被提出,这也意味着软件需求工程开始作为一个独立的研究方向出现。
1.2 安全性需求探索
研究者对安全性需求的探索从未中断,甚至在需求工程和安全的交叉领域提出了安全需求工程的概念。安全需求工程旨在通过一系列框架方法来重新解决软件安全需求相关问题。例如Guarín等[2]对容易遭到攻击的财产去进行危险分析从而从风险角度来获取安全需求,把网络应用程序作为研究目标,通过提出一种在敏捷环境下的安全需求审查办法来帮助开发人员更好探测软件安全需求缺陷。上述工作在安全需求问题领域做出了不可否认的贡献,但是在需求发现方面仍然无法避免因系统复杂性和各类环境因素带来的需求频繁变更等问题。Mavin等[3]针对安全问题提出了一种框架用于处理安全需求工程问题,通过从安全需求的问题本体领域角度出发,提出了一种3层的认知方法,从而细化安全需求。Singh等[4]则是针对安全性需求,将其从根本类别上划分出来,认为其既不属于功能性需求,也不属于非功能性需求,为了将其更好地界定出来,利用公开的SecReq数据集,对22种监督机器学习分类算法和两种深度学习方法在分类安全需求方面的性能进行了实证,结果表明,在无监督算法中,长短期记忆(LSTM)网络的准确率最高(84%),在有监督算法中,增强集成(boost Ensemble)的准确率最高(80%)。Villamizar等[5]将网络应用程序作为研究目标,提出一种在敏捷开发环境下的安全需求审查办法,该方法将用户故事和安全规范相结合,对安全性需求进行审查,结果表明针对新手开发人员具有较好的效果。
1.3 软件需求挖掘与抽取
从海量的网络数据中挖掘出有价值的知识和信息是进行用户需求抽取的有效途径,目前已经有很多研究人员针对社交数据进行了需求挖掘,比如Martns等利用Twitter上的官方账号(如Netflix、Spotify)去收集用户反馈[6];Hassan等[7]通过对谷歌用户商店中开发者和用户的对话追踪产品信息,查找产品缺陷从而对用户提供支持;在需求抽取方面,Raharjana等[8]针对网络新闻提出了一种概念模型提取用户故事,但是该方法机制不灵活,存在一定的局限性,作者也提到对于未来可能会借助机器学习的方法对其进行完善,提高抽取效果;胡田媛等[9]针对应用商店中的APP评论进行挖掘与抽取,采用基于人工标注的少量初始评论种子持续构建候选评论模式库,通过使用循环挖掘的方式进行匹配,动态扩大挖掘体现不同使用反馈类型的 APP 软件用户评论的范围;Cui等[10]提出基于评论的需求挖掘方法RERM,通过使用本体和条件随机场模型对相关特征进行提取,对软件存在的相关问题进行分类,如改进意见和产品缺陷等;Panichella等[11]对用户评论使用一种自然语言解析器进行特征抽取,通过对句子的相关语法进行分析确定用户反馈或者产品问题。
通过以上的分析研究,我们发现还很少有人将用户故事作为需求的表达载体,同时大多数学者的研究思路都是针对句子的语法结构对内容进行抽取,在此基础上,我们针对句子中的连接词对用户需求进行抽取,并以用户故事模板作为需求表达形式。
2 整体框架
规范的用户需求不仅便于项目的迭代演进,还能在一定程度上便于领域内不同项目间的需求重用。本文主要工作包括以下内容:
(1)筛选安全性需求相关数据;所获取到的Issues原数据并不是所有的都可以进行需求提取,因此需要从中筛选出符合需要的数据;
(2)提出一种通过对句子中的连接实体进行实体识别进而对Issues语句中的需求进行抽取的方法,主要针对3类句内连接实体来完成安全需求的抽取;
(3)基于需求抽取给出一种用户故事生成方法——CreUS。该方法根据语句中的连接实体和连接实体的位置制定生成用户故事的策略和规则,进而生成用户故事;
(4)基于针对特定实际项目的案例分析,对所生成的用户故事实用价值进行评价。
系统整体研究框架如图1所示。

图1 CreUS系统整体框架
3 数据筛选
3.1 数据来源
从广义角度来看,需求工程是一个逐步明确目的的过程,通过确定利益相关者(stakeholders)的需求并将这些需求以一种便于分析、沟通和后续实现的形式记录下来。其中利益相关者包括很多角色并且范围较为广泛,主要包括付费客户、用户和开发人员[12]。GitHub作为一个面向开发者的技术社区,迄今为止已经为超过5000万的用户提供了一个可供分享,可以共同协作完成软件开发的平台。开发者在上面不仅可以托管开发项目,提交代码,进行代码评审,同时还可以交流相关开发经验,以便开发者们之间互相之间进行学习。在GitHub的开发项目的功能板块中有一个Issues版块,该板块的主要目的是为平台上的开发者提供一个交流平台,开发者们在这上面可以对相关代码功能提出改进建议或者对项目运行之后的结果给予相关反馈。Issues是GitHub为各类平台使用者提供的一种交流工具,通常被用来追踪各种用户想法、任务、bug、完善用户功能等。
另外,当用户发布Issues对软件功能进行反馈的时候,对于某些评论可能会带有身份标签;标签主要包含两种,分别是Author标签和Member标签,其中Author标签代表发布这条Issues的作者;Member标签代表参与构造这个软件项目的成员;此外,还有其它参与到此条Issues中的评论者,此时,他们的反馈没有身份标签显示;3种情况分别如图2~图4所示。

图2 Issues的提出者-Author标签

图3 项目中的程序开发成员-Member标签

图4 其余参与到Issues中的评论人员-无标签
明确此类标签之后,在数据爬取阶段可以根据身份标签筛选相关数据。
3.2 数据获取及筛选
利用GitHub 官方API工具,从217个项目中一共爬取了25 490条Issues。考虑到主要目的在于挖掘用户的潜在需求,因此根据上面提到的GitHub Issues概念中的身份标签,本次数据爬取过程中过滤掉了带有
将获取到的Issues数据进行分类从而得到符合研究要求的数据。本次实验数据需要满足“需求”和“安全”两个方面,基于这两点考虑,决定将这里的工作内容分成两部分:①找出Issues语句中和需求相关的语句;②建立安全性需求初始特征词表,从①得到的数据结果中按照安全性特征词表进行筛选,可以大概率认为该条语句描述和安全性需求有关;通过以上两个步骤最后得到的数据可以认为基本满足所期望的数据要求,数据分类具体工作内容如下:
(1)筛选出Issues中的需求描述语句
参考文献[13]中作者提出的一种界定需求(dema-rcating requirements)问题的新方法,基于该方法,本文对对筛选出的Issues语句中包含的需求描述加以识别。数据特征化完成后,本文分别选用逻辑回归(logistic regression,LR)方法、支持向量机方法(support vector machine,SVM)、和决策树(decision tree,DT)方法进行训练分类模型并进行效果比较。3种方法的评估采用准确率A(Accuracy)、精确率P(Precision)和召回率R(Recall)。选用五折交叉验证的方式对实验结果取平均值,得到的结果见表1,SVM的方法要优于其余两种方法,因为在本问题上传统机器学习方法均表现较好,所以未对深度学习等新兴方法进行比较。

表1 3种模型分类结果比较
(2)进行安全性需求筛选
在步骤(1)筛选出需求相关数据见表2,然后通过建立安全性关键词属性筛选出安全相关需求,经过这两个步骤之后,可以认为最后得到的数据为基本满足需要的目标数据,即与安全需求相关的Issues语句,其结果见表3。

表2 需求数据分类结果

表3 安全需求数据分类结果
所建立的关键词表用来表示安全性需求分类的初始特征词,表中描述词汇主要整理、提取来自相关文献[1],其结果见表4。

表4 安全性需求相关词汇描述
3.3 数据预处理
对于上述步骤操作得到的数据需要对数据内容进行预处理操作,使用正则表达式去除句子中无用的链接和代码。考虑到Issues的语言表达形式为英文形式,其中可能包含一些词形变换,因此需要对一些词语进行词形还原,这样才能保证不会影响后续操作。例如,短语词组“would like to”在有些句子中用户可能会将其口语化表达为“I’d like to”,这种情况不利于研究后续对数据进行标注,因此需要将其还原为“I would like to”。
4 句内连接实体识别
在敏捷环境下,用户故事作为表达用户需求的重要方法,对于软件项目的开发有着巨大的影响。用户故事作为敏捷开发中一种有效的需求表示形式在实际开发中广泛应用。生成的用户故事集,不仅可用于支持Issues所在项目的开发迭代,还可以作为领域知识,在同领域类似项目的需求发现中起到重要的参考和辅助作用。Issues数据往往较为杂乱,如果能够将其规范化,将会大大提高它的可用性。因此,需要按照用户故事模板对用户故事进行提取。提取格式按照用户故事英文模板格式: As a
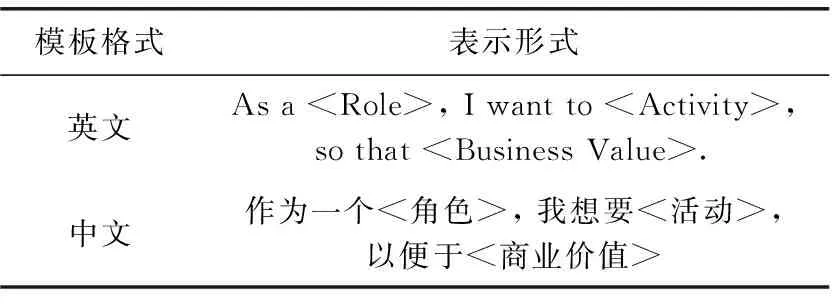
表5 用户故事模板
用户发表的Issues通常具有不同的表达形式,为了保证抽取工作的准确性,需要根据不用的句子特征对用户故事进行提取。提取用户故事只需要关注3个方面,分别是角色、行为和收益(原因),鉴于在爬取过程中已经对角色标签进行了筛选,所以用户故事角色可全部统一为“User”,接下来的任务就是如何对用户行为和行为原因进行抽取。
想要准确的分离一句话中的用户行为和行为原因,必须抓住其中起关键作用的句内连接实体然后对其进行分割。考虑到之前已经在此方向上对软件需求实体方面进行研究,并且取得了较好的效果,为了提高对于句内连接实体的识别效率,考虑使用了自然语言处理领域中对于实体识别的研究方法,在之前的基础上将其迁移到本次句内连接实体识别。
在本课题组前期相关工作中,使用Bi-LSTM+CRF实体识别方法对面向软件开发社交网络的软件功能需求实体进行识别。本文实验中直接采用上述方法对句内连接实体进行识别,该方法的性能比较以及实验数据分析参见文献[14]。
为了方便,在这里定义了一个新的概念——句内连接实体。句内连接实体是指通常句子内部会存在一些典型的连接词或短语。该类词语或者短语的上下文前后会对用户行为和行为原因进行描述,并将这些连接词或短语称作句内连接实体。值得注意的是,本文提到的句内连接实体的概念不同于英语语法中的连词的概念,连接实体还会包括一些连接短语表达。例如在下面的Issues语句中:
Itwould be nice tohave a short security summary in each crate documentation which would include known insecurities,applicability,etc.
其中,“would be nice to”不属于英语语法中的连词范畴,但是通过对“would be nice to”这类短语的识别可以切分该短语后面的句子作为用户行为,完成用户故事提取。因此该短语是句内连接实体;
句内连接实体包含的短语或者连接词的种类众多,在此,针对软件需求领域,定义句内连接实体的范围主要包括以下3种:表因果关系的连接实体;表意愿关系的连接实体;表建议关系的连接实体。主要集中在这3类连接实体的原因在于,根据用户故事模板,可以推测出这3类连接实体的句子中包含其三要素中的一个或几个,因此可以作为出发点来进行用户故事生成。
5 CreUS用户故事生成方法
用户故事是在软件开发过程中的一种需求描述形式,多用于在敏捷开发环境下。用户故事的详细定义请参见文献[15]。
用户故事通常按表5所示模板描述。例如:“作为一名[学生],我想要[轻松地完成密码修改任务],以便于[我可以及时保证我的个人隐私]。”
本文针对不同Issues安全性需求语句特点制定相应的用户故事元素提取规则;同时在用户故事表示中使用“下划线”来表示用户行为,例如用户行为;使用双下划线来表示行为收益,例如行为收益。
针对用户故事的抽取本文提出了CreUS算法,该算法主要是面向蕴含潜在的用户需求的Issues语句,通过上一小节的步骤对语句中的连接实体进行识别之后,还要根据不同语句类别和实体类型制定相应的规则进行抽取。该算法主要是从两个方面进行考虑,分别是句子类型和连接实体两个层面,基于这两个角度,制定了如下规则:
(1)如果句子中含有句内连接实体,则:
规则1:对表因果关系的句内连接实体,将连接实体的前缀作为用户行为,后缀作为行为原因,例如so that,because,in order that等;
规则2:对表意愿关系的句内连接实体,将句内连接实体的前缀作为行为原因,后缀作为用户行为,例如would like to,want to,hope to等。
规则3:对表建议关系的句内连接实体,将句内连接实体前缀作为行为原因,后缀作为用户行为,例如would be great to,be nice to,suggest that等。
(2)经过了上一步对于句内连接实体的判断,还要针对Issues需求语句不同的表达形式,将二者结合起来并给出如下规则:
规则1:句中无标点符号,单独短语成句,带有祈使的语气,在这种情况下,可将全部文本内容作为用户行为原因,并且在用户行为上使用“Action”进行补全,举例如下:
原Issues语句:

insecure firebase architecture.
提取用户故事:

As a user,I want Action, so that insecure firebase architecture.
规则2:对于含有句内连接实体的简单句,首先识别句子中的连接实体并确定其所属种类,然后按照(1)中对应的规则进行抽取,举例如下:
原Issues语句:

finish session and login work so that the session is in the db and that the login is secure.
提取用户故事:

As a user,I want to finish session and login work, so that the session is in the db and that the login is secure.
规则3:往往用户的反馈不仅仅是一句,而是由多个语句构成的集合。对于含有多个语句的段落,如果其中只有一个句内连接实体的话根据该句内连接实体所处的位置和所在的句子进行分割,同样在对句子进行分割的时候遵循(1)中的规则。例如:
原Issues语句:

the current 20 character limit on passwords is too short for secure passphrases. would be great to support lon-ger passwords eg: 128+ characters especially considering unicode chars take up more than one character in the pass-word manager.
对于该句,其中只包含一个句内连接实体。找到句内连接实体would be great to所在的位置,对前后文进行划分;按照句内连接实体属性规则,生成的用户故事如下:
提取用户故事:

As a user, I want to support longer passwords eg: 128+ characters especially considering unicode chars take up more than one character in the password manager so that the current 20 character limit on passwords is too short for se-cure passphrases.
规则4:在同一段落文本中,句内连接实体可能不止出现了一次,一段文本中可能含有两个或者两个以上句内连接实体,对于这种情况,按照句内连接实体的位置将句子分割,之后重复规则3。对于一段文本中含有多个句内连接实体的句子就表明用户可能有多个需求,因此这样的话就需要找出句中所有句内连接实体并对潜在的用户需求进行拆解,从而保证需求提取的完整性,示例如下:
原Issues语句:

句子1:hashed key is the password hash from user specified plaintext password using crypto_pwhash. it is a hash value but used as a key, so it must be protected by safebox as same as other keys.(第一个连词结尾处对段落进行分割)句子2:although the current password hash has drop to clear it, but it is allocated on stack which is weaker than the secured heap and potential to be persistent. so it should be u-sing same safebox as a normal key to enhance security.
重复步骤规则3,对已获得到的句子进行用户故事提取,如下:
提取用户故事:

As a user, I want protected by safebox as same as other keys, so that hashed key is the password hash from us-er specified plaintext password using crypto_pwhash. it is a hash value but used as a key.

As a user,I want to use same safebox as a normal key to enhance security, so that although the current pass-word hash has drop to clear it, but it is allocated on stack which is weaker than the secured heap and potential to be persistent.
基于Issues安全性需求描述文本的用户故事生成算法如下:
算法1:CreUS用户故事生成算法
Input: 处理后的Issues语句
Output: Issues语句对应的用户故事
Variable: SenEntityNum /*Issues语句中所含连接实体的数目*/
JustSinglePhrase /*句中无标点符号,单独短语成句*/
SenNum /*输入Issues语句中完整句子数目*/
SenIsSimple /*输入Issues语句为简单句*/
BeforeJoinEntity /*连接实体前文内容*/
AfterJoinEntity /*连接实体后文内容*/
RolePart /*用户故事模板中用户角色,统一为:User*/
ActionPart /*用户故事模板中用户行为部分*/
ReasonPart /*用户故事模板中行为原因部分*/
Function:/*所用到的函数*/
Check() /*如果连接实体前后文为空则进行关键词补全处理*/
(1) If(BeforeJoinEntity.content == null)
(2) Then “Action”→UserStory.ActionPart
(3) Return
(4) If(AfterJoinEntity.content == null)
(5) Then “Reason”→UserStory.reasonPart
(6) Return
MakeUserStory()/*创建用户故事函数*/
JudgeEntityType(): /*判断连接实体类型*/
(1)If(JudgeEntityType==1)/*如果是表示因果关系的实体*/
(2)ThenIssues. BeforeJoinEntity → UserStory.Action-Part;
(3) Issues. AfterJoinEntity →UserStory.Reason-Part
(4)MakeUserStory(RolePart+ActionPart+ReasonPart)
(5)ElseIf(JudgeEntityType==2‖JudgeEntityType==3)
/*如果实体是表示意愿关系或者表示建议关系的连接实体*/
(6)ThenIssues. AfterJoinEntity → UserStory.Action-Part;
(7) Issues. BeforeJoinEntity →UserStory.Reason-Part
(8)MakeUserStory(RolePart+ActionPart+ReasonPart)
CutSenByEntity() /*根据连接实体位置分割句子*/
Main()/*主函数*/
Begin:
(1)If(Issues.JustSinglePhrase == True)
(2)ThenIssues.WholeContent →UserStory.Reason-Part
(3) “Action”→UserStory.ActionPart
(4)MakeUserStory(RolePart+ActionPart+ReasonPart)
(5)ElseIf(Issues.SenEntityNum == 1 && SenNum ==1)
(6)Check();
(7)JudgeEntityType(Issues.entity)
(8)ElseIf(Issues.SenEntityNum == 1 && SenNum >1)
(9)Check()
(10)JudgeEntityType(Issues.entity)
(11)ElseIf(Issues.SenEntityNum >1 && SenNum >1)
(12)CutSenByEntity()/*通过实体对段落句子进行分割*/
(13)Repeat(Step(5)~Step(10))
(14)ElseCatchException()
(15)Return
End
本算法时间复杂度为O(n)。复杂度较低的原因主要是前期数据筛选和实体识别承担了较大工作量。
6 案例分析
本文从GitHub抓取的Issues数据中筛选出425条安全相关Issues,通过上文提供的算法,从这些Issues语句中抽取到157条用户故事。其中,不含语义错误的用户故事共有52条。在GitHub中选取若干真实项目案例,通过计算用户故事覆盖率分析抽取到的用户故事在实际项目中的实用性。
为了进行用户故事实用价值判定,使用人工的方式对52条用户故事进行分类,所采用的分类标准是文献[16]里面Donald Firesmith所提出的12种安全性需求,即:①鉴别需求;②验证需求;③授权需求;④免疫性需求;⑤完整性需求;⑥入侵检测需求;⑦不可否认需求;⑧秘密需求;⑨安全审计需求;⑩可存活性需求;物理保护需求;系统维修安全性需求。按照这12类标签对用户故事进行分类,分类情况见表6。

表6 用户故事按照安全需求标准进行分类
在GitHub上选取15个实际开发项目,其项目列表见表7;所选取的项目均为比较完整且权威的项目,每个项目都有比较完善的功能说明,根据这些功能说明可以列出原项目安全需求列表,形成具体功能点;依据功能点在所生成的用户故事集中筛选出可能相关的用户故事。进一步与原项目的安全需求进行比对,如果某个用户故事覆盖了项目中的有效功能点,则说明该用户故事有效。通过人工统计的方法,计算用户故事覆盖率p,如式(1)所示;其中n(s)表示覆盖实际项目用户故事的条数,n(c)表示原项目中实际的安全需求用户故事条数,在这里选用实际项目的目的是希望通过实际项目的角度出发来测试用户故事的价值,这样也会更加有说服力

(1)
生成用户故事的主要目的主要有两个,一个是以规范的形式帮助利益相关者完善某些需求,即覆盖已有功能;另一个是帮助利益相关者发现新的需求并对其形成辅助作用,即增加新的功能。
上述步骤以表8中的项目paascloud-master为例简要说明如下:
(1)根据项目介绍预测用户故事
根据主页信息中的简短介绍从用户故事列表中推荐相关的用户故事,最终人工推荐用户故事32条,并且按照Donald Firesmith在文献[16]中所提到的分类办法进行分类,具体序号见表8;考虑到抽取到的安全需求用户故事条数较多,因此在本文里不详细列出,作者已将用户故事进行整理并且上传到GitHub[17]。
(2)收集实际项目安全需求用户故事并分类
人工方法进行安全需求用户故事收集,具体需求见表8,在实际项目中,一共生成13条用户故事,并对其进行分类,这样便于更好推荐用户故事。

表8 项目列表
(3)进行用户故事价值比对并计算覆盖率
最后得到实际用户故事覆盖条数为11条,用户故事覆盖率84.6%。
类似的对15个项目的用户故事实用价值进行分析,结果详见表8;可以看出,采用该方法所得到的平均用户故事覆盖率为85.71%,说明本次生成的用户故事具有一定的实用价值,对实际项目开发能够起到一定的辅助作用。
7 结束语
在敏捷开发环境下,相对于被集中撰写的功能性需求,软件的非功能需求描述通常较为分散和隐含。我们认为开发类社交媒体上针对特定软件项目的讨论中往往蕴含着许多潜在的系统功能需求和非功能需求。因此本文针对GitHub中的Issues模块数据尝试进行安全性需求挖掘,从而获得有价值的信息为开发人员提供辅助工作。本文主要贡献包括:①给出一种以3类连接实体识别为基础从句子中抽取出用户行为和行为原因的方法;②给出一种CreUS用户故事生成算法,针对不同类型的Issues语句和句内连接实体类型设计规则进行用户故事生成。生成的用户故事集不仅可用于辅助Issues所在项目的开发迭代,还可以作为领域知识,在同领域类似项目的需求发现中起到重要的参考和辅助作用。
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
小学生·多元智能大王(2014年6期)2014-07-09
