
基于改进磷虾群算法的多目标文本聚类方法
2022-06-23 11:11菊花
计算机工程与设计 2022年6期
菊 花
(内蒙古师范大学 教育学院,内蒙古 呼和浩特 010020)
0 引 言
Web网页由于移动互联网的广泛流行已经成为文本信息的主要来源,其出现形式如新闻网站、社交媒体、数字图书馆等[1]。为了管理巨量文本信息,聚类是有效的非监督学习方法[2]。由于同聚类文档具有最大相关性和内在联系,这一技术可以简化用户的文本处理过程。文本聚类还可应用在图像识别、文本划分、信息检索、搜索引擎等[3]。此时的文档可表示为矢量空间模型VSM,用以度量文档矢量与聚类质心间的相似程度[4]。K均值聚类是求解文本聚类的一种快速、健壮的局部搜索算法[5],其结构简单、收敛速度快,该算法通过初始的聚类质心来寻找聚类成员,每个文档将根据自身与质心的相似性选择加入的聚类。但算法过于依赖初始质心选择,容易陷入局部最优,聚类结果不稳定。磷虾群算法KH是受磷虾的捕食行为的启发而提出的一种新型的元启发式算法[6]。该算法控制参数少,易于实现,极好的全局寻优能力使其常用于数据聚类领域。
相关研究中,文献[7]利用公平克隆机制提升蜂群算法的种群多样性和全局搜索能力,再结合K均值法进行聚类。文献[8]将差分进化和遗传算子嵌入K均值聚类,提升了聚类相似性。文献[9]以梯度搜索和混沌搜索设计蜂群算法,并以此选择聚类中心。文献[10]融合粒子群和布谷鸟算法的优势进行文本聚类。文献[11]提出混合粒子群算法的文本聚类算法HPSO。文献[12]和文献[13]分别提出混合遗传文本聚类算法HGA和混合和声搜索聚类算法HHS。
元启发式方法求解聚类时可能有早熟收敛问题,该问题与初始解有关。单纯依靠元启发方法不能保证有限时间内得到全局最优。若可以改进初始解的随机性,并利用优化后的全局搜索能力,则可以在聚类准确性、精确性取得均衡。K均值聚类易受初始质心影响,聚类不稳定,而传统磷虾群算法KH易陷入局部最优,全局搜索能力弱。为此,提出基于改进磷虾群算法的多目标文本聚类算法,通过磷虾个体的诱导运动、觅食运动和随机扩散,以及融入遗传交叉和变异的个体更新机制,增加种群多样性,更快得到文本文档聚类结果。
1 模型描述
1.1 文本文档聚类问题
文本文档集合D可划分为K个聚类,D可表示为如式(1)的文本矢量形式
D=d1,d2,…,di,…,dn
(1)
式中:di为文档i,n为文档总数。文档可表示为矢量d1=w11,w12,…,w1j,…,w1t, 其中,d1表示长度为t的文档1,wij表示文档i中词条j的权重,计算方法如下
wij=TFIDF(i,j)=tf(i,j)×logn/df(j)
(2)
式中:tf(i,j) 为词条j在文档i中的出现频率,df(j) 为含有j的文档数。
聚类即就是将D划分为K个聚类,Ck为聚类k的质心,可表示为一个词条权重矢量Ck=c1,c2,…,cj,…,ct,Ck表示第k个聚类质心,c1表示聚类质心k位置1上的权重值,t表示聚类质心的长度。
算法利用余弦相似度计算每个文档与聚类质心间的相似性分值,计算公式如下
(3)

欧氏距离可用于计算每个文档与聚类质心间的距离,该距离则可以度量两者间的非相似性,计算方式如下
(4)
可以看到,欧氏距离取值在(0,1)之间,这不同于余弦相似度的度量方式。若文档与质心距离接近0,则表明该文档与该质心具有较大相似性;若距离接近于1,则表明该文档与质心具有不相似性。式(4)为文档d4与C2的欧氏距离。
1.2 多目标文本聚类
根据式(3)和式(4)可知,余弦相似度衡量相似性,欧氏距离度量距离。本文算法联立两种度量方式作为目标函数进行聚类决策,即尽可能选择离质心近且相似度高的质心。因此,聚类目标函数为
multi-obj=cosine(d1,C2)×[1-dis(d1,C2)]
(5)
2 K均值聚类算法
K均值聚类算法目标是通过初选的聚类质心,将高维度文本集合D中的文档划分为K个固有聚类子集。算法通过所设定的目标函数将每个文档划分至相似性最大的质心中。该算法通过聚类数K、初始质心及余弦相似度进行聚类划分,并通过质心迭代更新,得到最优聚类解。算法以矩阵A(n×K)表示可能的聚类解集,n代表所有文档数量,K代表聚类数量,每个文档可表示为式(1)所示的词条矢量权重,t表示唯一文本特征(词条)数量。算法的目标就是寻找最优的n×K矩阵,具体过程如算法1所示。
算法1:K均值聚类算法
(1)input:Dis a set of text documents,Kis the number of clusters
(2)output: assignDtoK
(3) termination criteria
(4) randomly chooseKdocuments as clusters centroids
(5) initialize matrixA(n*K) as zero
(6)foralldinDdo
(7) letj=argmaxk∈(1,2,…,K)based onmulti-obj(di,Ck)
(8) allocatedito the cluster numberj,A[i][j]=1
(9)endfor
(10) update the clusters centroids
3 融合遗传算子的改进磷虾群算法
磷虾君算法KH是一种新型的元启发式算法,模拟了虾个体的捕食行为,可用于求解全局优化问题。寻优过程中,磷虾的位置更新通过3种运动构成:诱导运动、觅食运动和随机扩散。每个磷虾的位置代表目标函数的一个可行解,每只磷虾通过觅食过程中位置的不断更新来寻找最优解。
3.1 位置更新
磷虾个体i从迭代I至迭代I+ΔI发生的位置更新如下
xi(I+ΔI)=xi(I)+ΔIdxi/ds
(6)
式中:xi(I+ΔI) 表示磷虾个体i的下一更新位置,xi(I)表示迭代I时磷虾个体的位置,ΔI表示间隔常量。磷虾个体的位置决策利用拉格朗日模型进行表示,将其描述为
dxi/ds=Fi+Ni+Di
(7)
式中:Ni代表诱导运动分量,Fi代表觅食运动分量,Di代表随机扩散分量。
(1)诱导运动
每个磷虾个体的邻居诱导运动可计算为
Ni,new=Nmaxai+wnNi,old
(8)
式中:Nmax表示最大诱导步长,wn表示惯性权重,取值(0,1)之间,Ni,old表示磷虾个体i的先前诱导运动,ai表示诱导方向,计算为
ai=ai,local+ai,target
(9)
式中:ai,local表示磷虾个体i受邻居的诱导方向,ai,target表示磷虾个体i受当前全局最优个体的诱导方向,且
(10)
其中
(11)
K′i,j=Ki-Kj/Kworst-Kbest
(12)
其中,Kworst和Kbest分别表示特定位置上磷虾个体的目标函数值最差值和最优值,Ki表示个体i的目标函数值,Kj表示其邻居j的目标函数值,x表示相关个体,ε为极小正值,xi表示当前个体位置,xj表示邻居j位置,NN表示磷虾个体总量,即代表总的文档数n
ai,target=CbestK′i,bestx′i,best
(13)
Cbest=2(rand+I/Imax)
(14)
其中,Cbest表示磷虾个体的相关系数,ai,target代表的系数有助于算法达到全局最优解,rand是(0,1)间的随机数,I代表KH算法的当前迭代,Imax为最大迭代。
(2)觅食运动
觅食运动分量Fi与当前估算的食物源位置和前一次觅食活动及位置相关,可表示为
Fi=Vfβi+wfFi,old
(15)
βi=βi,food+βi,best
(16)
式中:βi,food表示个体受食物源诱导的方向,βi,best表示个体受自身历史最优个体诱导的方向。
(3)随机扩散
随机扩散分量表示磷虾个体的随机搜索行为,可表示为
Di=Dmax(1-I/Imax)δ
(17)
式中:Dmax表示最大的随机扩散速度,I表示当前迭代数,Imax表示最大迭代数,δ表示随机扩散方向,取值范围为[-1,1]。
3.2 融入遗传算子的位置更新
由磷虾个体的位置更新方式可知,磷虾个体运动由其邻居、种群最优个体、食物源位置以及自身位置等多个因素共同决定,因此,传统KH算法的局部开发能力较优,但其全局搜索能力不足,在处理多峰优化问题过程中可能陷入局部最优解。此外,KH算法在每次迭代中均需要多个因素共同决策个体的运动,其搜索全局最优解的速度较慢,无法快速收敛。
为解决该问题,引入遗传算子增强传统KH算法的全局搜索能力。首先,通过交叉算子交换所选个体的相应位置信息,交叉算子由交叉概率pc控制,定义pc=0.2×Ki,best。 磷虾个体i的位置j发生交叉的更新方式为
(18)
变异算子可以通过所选个体的位置信息突变方式增加解的多样性,以便搜索全局最优解。变异算子由变异概率pm控制,将其定义为pm=0.05/Ki,best。 磷虾个体i的位置j发生变异的更新方式为
由此可见,智能加工技术研究的内容极其广泛,但要真正实现整体加工过程的优化控制,机床、刀具以及工件的状态监测是基础[13-14],需要通过监测为过程优化提供源信息。其中,机床的状态监测通常通过内置传感器来实现,而刀具和工件状态的监测,机器视觉技术可以发挥重要作用。
(19)
4 基于改进磷虾群算法的文本聚类模型
本节描述基于改进磷虾群算法的文本文档聚类模型,目标是寻找最优文本聚类,提升聚类准确度,加快算法寻优。
4.1 磷虾个体位置表示
利用一个代表磷虾的解集S进行文本文档聚类,每个解可表示为一个长度为n的矢量,n代表所有文档数量,每个文档则代有KH算法中一个磷虾的行为。每个决策变量(即磷虾个体)属于一个聚类质心 [1,2,…,K], 每个解由K个质心集合构成,单个质心Ck=c1,c2,…,cj,…,ct,Ck表示第k个聚类质心。图1是解的一种表示方式,该解表明8个文档被划分为3个聚类,文档d1属于聚类c3,文档d5属于聚类c2,而聚类c3包含文档d1、d2和d7这3个文档。

图1 解的表示方法
4.2 磷虾群记忆库KHM
KHM通过区间 [1,…,K] 内搜索空间的随机值进行初始化。KHM的每个矢量代表一个可行解,对应聚类质心K中的一个序号。KHM大小S×n由可行解数量和文档数量决定。将KHM定义为
(20)
4.3 聚类质心更新
质心更新是文本聚类的主要步骤,决定了文档所属聚类。聚类质心Ck的计算方式为
(21)
式中:nk为聚类k的文档量,Ck为聚类k的质心。式(21)表明:聚类内所有文档的矢量权重和与文档数量之比为聚类质心。
4.4 适应度函数
定义平均相似文档质心ASDC为适应度函数,该函数可考虑为一个外部度量方式,其值则是根据内部度量(余弦相似度和欧氏距离)计算。结合式(5)定义的聚类目标函数,适应度函数利用目标函数在K个聚类上的均值结果进行定义
(22)
式中:ni表示聚类i中的所有文档数量,multi-obj(Ci,dij) 表示文档j与质心i间的相似度,dij表示聚类i中的文档j。
4.5 基于改进磷虾群算法的文本聚类算法MHKHA
图2是融合K均值的混合多目标改进磷虾群算法的文本聚类算法MHKHA的执行流程。算法以多目标K均值聚类结果作为改进磷虾群算法的初始种群,即初始聚类解,填充至磷虾群记忆库KHM中。同时多目标K均值聚类以式(5)融合余弦相似度和欧氏距离的目标进行度量。在对磷虾群相关参数配置后,进行迭代终止判断,若未满足终止条件,则进行磷虾个体运动计算,包括诱导运动、觅食运动和随机扩散,从而进行磷虾群位置更新。再引入遗传交叉和变异机制,提升种群多样性,再以最优个体替换最差个体,完成一次文本聚类迭代过程。算法2是MHKHA的完整伪代码。

图2 MHKHA算法的执行流程
算法2: MHKHA算法伪代码
(1) initialization ofK-mean parametersK,KImax//初始化K均值聚类参数
(2) initialization of KH parameters:Imax,S//初始化磷虾群参数
(3)forl=1 toSdo//在KHM上遍历
(4) randomly selectKdocuments as the initial cluster centroid//随机选择聚类质心
(5)forKI=1 toKImaxdo//K均值聚类迭代
(6) initialize matrixAas zero//初始聚类矩阵初始化
(7)forj=1 tondo//遍历文档集合
(8)j=argmaxk∈(1,2,…,K)on basis ofmulti-obj(dj,Ck)//根据目标函数寻找聚类质心
(9) assigndito clusterj,i.e.A[i][j]=1//分配文档至聚类, 更新矩阵元素
(10) update the clusters centroids//更新聚类质心
(11)endfor
(12)endfor
(13) convert matrixAas a matrix of solutions KHM//将K均值聚类解A转换为KHM
(14)S(l)=A, note that eachK-means generation is one solution for KH memory//K均值每一次迭代的聚类解作为KHM的一种可行解
(15)endfor
(16) initialization of KHM usingS,which is theK-means results//初始化KHM
(17)fori=1 toSdo//遍历所有可行解
(18)forj=1 tondo//遍历所有文档
(19) computing the clusters centroids//计算聚类质心
(20) compute fitness function of each krill by usingASDC//根据ASDC计算磷虾个体适应度
(21)endfor
(22)endfor
(23) sort the krills and findxbest,where best from [1,2,…,S]//对所有可行解进行排序, 寻找最优解
(24)whileI=Imaxdo//改进磷虾群算法迭代
(25)fori=1 toSdo
(26) perform the three motion calculations//磷虾3种运动模式
(27)xi(I+dI)=xi(I)+ΔI(dxi/ds)//个体位置更新
(28) compute the clusters centroids//计算聚类质心
(29) evaluate each krill usingASDC//根据ASDC评估磷虾个体
(30)endfor
(31)fori=1 toSdo
(32) apply KH operators to KHM//更新KHM
(33) genetic crossover//遗传交叉
(34) genetic mutation//遗传变异
(35)endfor
(36) replace the worst krill with the best krill//个体替换
(37) sort the krills and findxbest//重新排序磷虾群, 寻找最优个体
(38)I=I+1//迭代更新
(39)endwhile
(40)returnxbest//迭代完成后, 返回最优解
5 实验分析
5.1 评估指标
本节对所提出的算法进行仿真对比分析,实验利用Matlab进行。文本聚类领域内聚类质量的评估指标主要有准确率、精确度、召回率和F度量值,以上指标可用于评估文档聚类和度量每个聚类中实际分割与文档分类标签的一致性。
精确度:精确度表示所有实际相关文档与所有聚类中文档总量的比值,该比值可以根据实际给定的分类标签针对每个聚类进行计算,计算方式为
P(i,j)=nij/nj
(23)
式中:P(i,j) 表示聚类j中分类i的精确度,nij表示聚类j中分类i的实际成员数量,nj为聚类j中的所有成员数量。
召回率:召回率表示实际相关文档与所有聚类文档的比值,计算方式为
R(i,j)=nij/ni
(24)
式中:R(i,j) 为聚类j中分类i的召回率,ni为分类i的实际成员量。
F度量:F度量根据聚类精确度和召回率计算,期望最佳的文本聚类结果,其F度量值将越接近于1,聚类j中分类i的F度量计算方式为
(25)
所有聚类的F度量计算方式为
(26)
式中:n表示集合D中的文档总量。
准确率:聚类准确率用于计算实际划分至每个聚类中的文本文档的比例,计算方式为
(27)
式中:K表示文本总聚类数。
5.2 测试数据集
利用9个拥有不同特征的文本数据集测试聚类算法的可行性,这些文本聚类基准数据集可从网站http://sites.labic.icmc.usp.br/text_collections/下载,并通过词条提取表征为数值形式进行实验。表1给出了数据集的详细属性。数据集DS1来源于CSTR,包括4个分类的关于技术报告的299个文档。数据集DS2来源于SyskrillWebert,包括4个分类的关于Web网页的333个文档。数据集DS3来源于Trace,包括6个分类的关于tr32的204个文档。数据集DS4来源于Trace,包括9个分类的关于tr32的313个文档。数据集DS5 Trace,包括9个分类的关于tr11的414个文档。数据集DS6来源于Trace,包括10个分类的关于tr41的878个文档。数据集DS7来源于OHSUMED,包括10个分类的关于MIDLINE的913个文档。数据集DS8来源于classic4,包括4个分类的关于MIDLINE的2000个文档,4个分类分别为CACM、CRAN、CISI、MED,每个分类500个文档。数据集DS9来源于20 NEWSGRUP,包括20个分类的关于新闻的18 828个文档。

表1 数据集
与本文设计的相关KH算法一共有6种,表2是不同KH算法版本的详细说明。KHA1和KHA2是利用基本KH算法进行文本聚类,不使用K均值结果作为初始解,区别在于是否融入遗传交叉和变异。HKHA1、HKHA2和HKHA3均是融入K均值的混合KH算法,但仅仅是以余弦相似度单目标进行聚类衡量,同时区别在于是融入遗传交叉和变异。MHKHA则是融入K均值的混合多目标算法,以K均值聚类作为初始解,以余弦相似度和欧氏距离进行多目标聚类优化,再融入遗传交叉和变异。不同版本的KH算法还将与3种混合文本聚类算法进行比较,分别选取混合和声搜索文本聚类算法HHS[13]、混合遗传文本聚类算法HGA[12]和混合粒子群优化文本聚类算法HPSO[11]进行性能对比。实验结果均是20次实验结果的均值,聚类过程中设置1000次最大迭代,可以使算法进行充分的全局最优搜索,K均值聚类过程设置100次最大迭代,可以使其收敛在局部搜索最优解上。

表2 不同版本的KH算法
5.3 改进磷虾群算法的参数确定
该部分实验用于确定MHKHA算法中相关参数最优值。表3是20个收敛实验场景的详细参数配置。实验主要研究4个参数的取值问题,包括KHM大小S、最大觅食速度Vf、最大随机扩散速度Dmax和最大诱导步长Nmax。所有实验场景最大迭代数Imax=1000,在所有9个数据集上对每个收敛实验场景进行实验分析,以确定4个参数最优值。表3将收敛场景划分为4组,每一组确定3个参数不同,改变一个参数来确定最优值。如:对于场景6~场景10,S、Dmax和Nmax是固定相同取值,Vf改变取值。第一组场景以5个不同取值S=1020304050检测磷虾群记忆库KHM大小(存储初始解)的最优值,第二组场景以5个不同最大觅食速度Vf=0.005/0.010/0.030/0.040/0.070检测Vf最优值。剩余3组场景依此类推。最后一列数据是在相应场景下得到的最优值组数,最后一行则是相应参数最优取值。4个参数的组合取值是参考有关磷虾群算法研究文献所作的取值。
场景1~场景5用于决定KHM大小的最优值,第2组场景在所有数据集中的36个评估指标中得到了24个最优值,因此,选定S=20,后续实验也以该值进行实验分析。场景6~场景10用于决定最大觅食速度Vf的最优值,第8组场景在所有数据集的36个评估指标中得到了19个最优
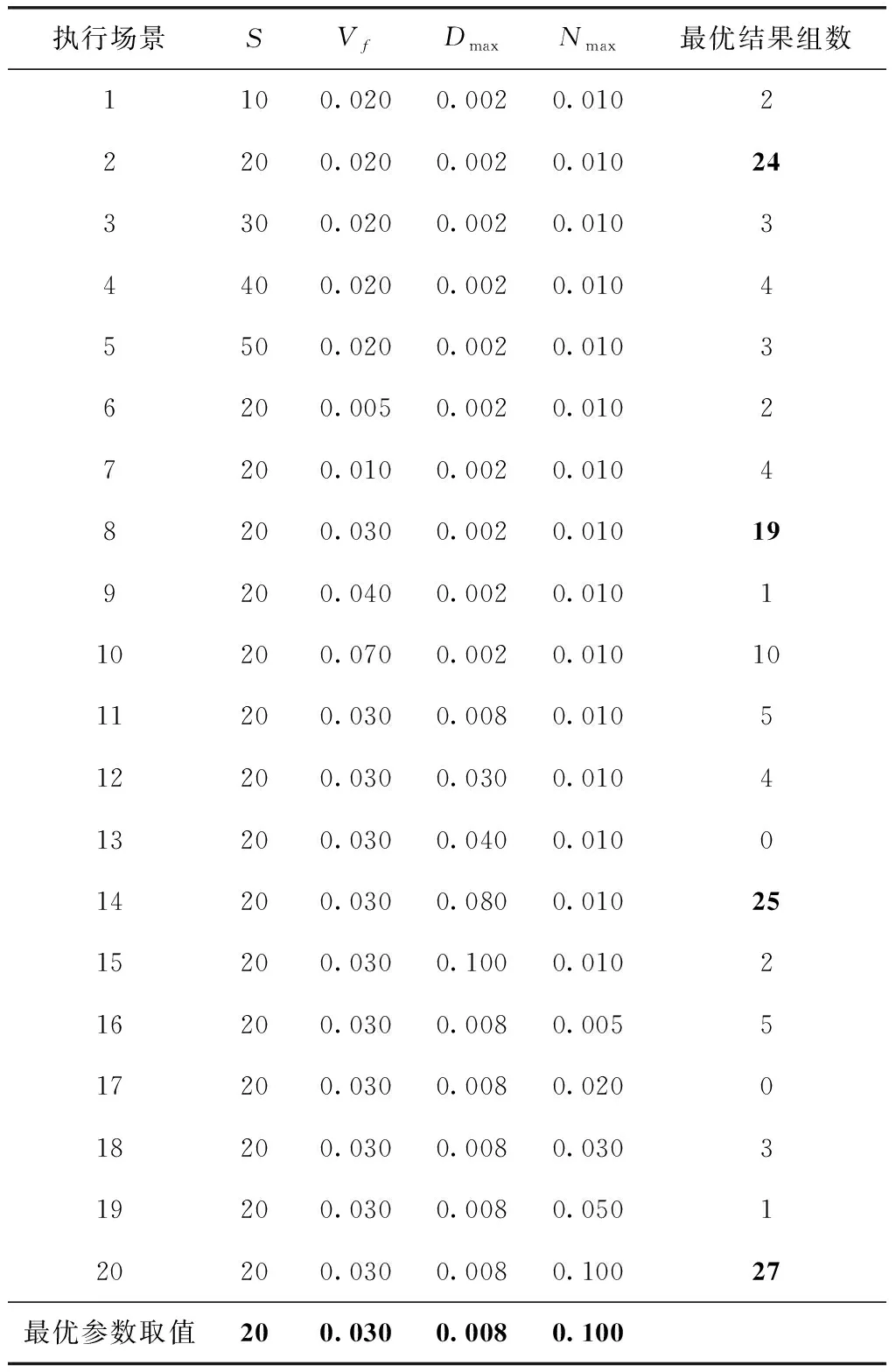
表3 磷虾群算法的执行场景和最佳参数取值
值,因此,选定Vf=0.030,后续实验也以该值进行实验分析。场景11~场景15用于决定最大随机扩散速度Dmax的最优值,第14组场景在所有数据集的36个评估指标中得到了25个最优值,因此,选定Dmax=0.008,后续实验也以该值进行实验分析。场景16~场景20用于决定最大诱导步长Nmax的最优值,第20组场景在所有数据集的36个评估指标中得到了27个最优值,因此,选定Nmax=0.100,后续实验也以该值进行实验分析。
5.4 算法对比结果分析
表4给出在9个基准数据集上测试的4个评估指标结果,共测试10种算法。最优结果以粗体表示。准确率方面,MHKHA在9个数据集中的7个数据集得到了最优结果;精确度方面,MHKHA在9个数据集测试中的8个数据集得到了最优结果;在召回率和F度量指标上,MHKHA在所有数据集上均得到了最优结果。综合所有指标可知,MHKHA获得了最多的最优值,可见,融入遗传算子的混合多目标磷虾群算法MHKHA可以有效提升文本聚类效果。
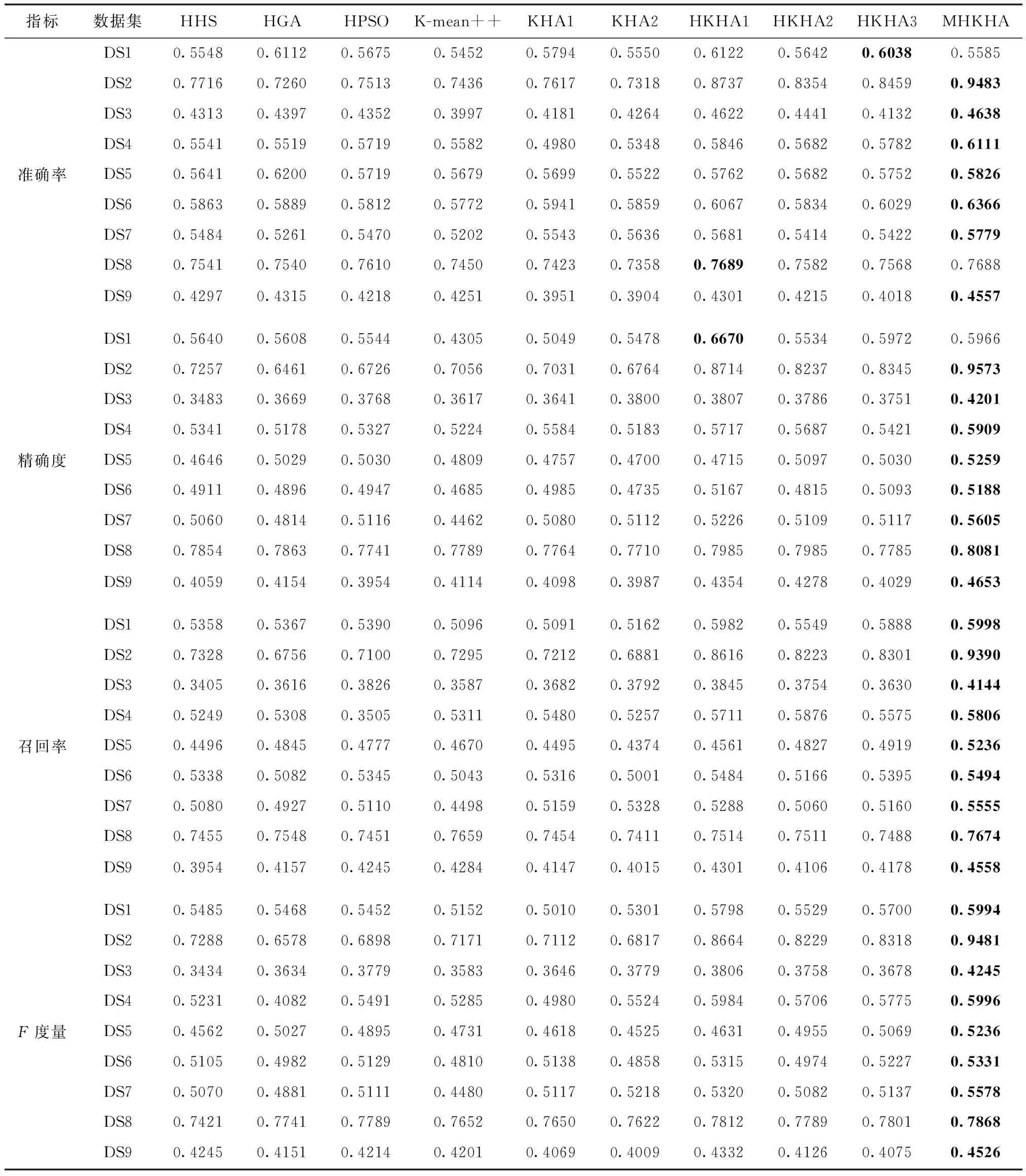
表4 聚类性能对比结果
5.5 统计分析
本节根据F度量值执行弗里德曼氏测试评估算法性能,结果见表5,给出的是算法在不同数据集中的测试排序。本文的MHKHA算法在所有数据集中改进文本文档聚类的排序最高,紧接着是HKHA1、HKHA3、HKHA2、HPSO、HHS、HGA、KHA2、HKA1和K-mean++算法。MHKHA算法利用多目标优化的K均值聚类结果作为算法的初始解,可以有效增强KH算法的局部开发能力;而融入遗传算法后的KH算法又可以提升算法的全局搜索能力,最终得到最佳的聚类效果。
进一步对算法进行t测试,测试结果见表6、表7,利用α<0.05的t测试评估性能。表6总结了KHA1和HKHA1

表5 基于F度量的弗里德曼氏测试分析

表6 KHA1和HKHA1在α<0.05时的t测试结果

表7 HKHA1和MHKHA在α<0.05时的t测试结果
的t测试结果,可以看到,9个数据集中有7个改进较多,结果很可观。同时,HKHA1的t测试结果要优于HKA1,可见,改善磷虾群的初始种群结构是行之有效的。表7总结了HKHA1和MHKHA的t测试结果,可以看到,9个数据集中有6个改进较多,同时,MHKHA的t测试结果要优于HKHA1,可见,融入多目标和遗传算子在磷虾群算法中可以有效增强个体寻优能力,在避免局部最优的同时,快速收敛至全局最优解处。
5.6 收敛分析
本节观察几种文本聚类算法的收敛行为,收敛速度可以反映算法寻找最优解(准确聚类)的速度。图3是算法的收敛行为表现。可以看到,MHKHA算法随着迭代的进行,基本上到后期在所有数据集测试下均可以得到最大的适应度均值,说明算法可以有效避免陷入局部最优,获得全局最优解,这与其它几种混合KH算法(HKHA1、HKHA2、HKHA3)不同,说明MHKHA算法所采用的混合多目标机制和遗传算子对于有效提升聚类效率,以及个体寻优方面是有效可行的。此外,HKHA2和HKHA3的收敛性优于HKHA1、HGA、HHS和HPSO,说明在融入K均值作为种群初始结构后,对磷虾群个体更新融入遗传算子的思路是有效可行的,可以有效增加种群多样性,增加获得全局最优的概率。

图3 算法收敛状况
6 结束语
为了提高文本聚类的准确率,提升聚类效率,提出一种融合改进磷虾群算法与K均值的文本聚类算法。算法结合K均值聚类的局部快速寻优能力和改进磷虾群算法的全局搜索能力,以K均值聚类解作为磷虾群算法的初始种群,引入遗传交叉和变异算子改善磷虾个体多样性,提升全局搜索能力;通过磷虾种群的诱导运动、觅食运动和随机扩散机制作个体位置更新,引入余弦相似度和欧氏距离的多目标结构适应度函数评估磷虾位置优劣,搜索全局最优解。结果表明,该算法在聚类指标上表现更优。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年14期)2022-07-30
小哥白尼(野生动物)(2022年4期)2022-07-16
北京航空航天大学学报(2021年4期)2021-11-24
湖南饲料(2021年4期)2021-10-13
意林(2021年2期)2021-02-08
中国惯性技术学报(2019年6期)2019-03-04
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2016年9期)2016-11-16
