
基于多级融合的多模态谣言检测模型
2022-06-23 11:00王壮,隋杰
计算机工程与设计 2022年6期
王 壮,隋 杰
(中国科学院大学 工程科学学院,北京 100049)
0 引 言
网络谣言检测本质上是一个二分类问题,即实验者通过使用特定模型对一条或者一系列的帖子进行判别,将其分类为谣言或者非谣言。
近年来,随着神经网络技术不断在自然语言处理领域取得进展,越来越多的学者将其应用到谣言检测领域[1]。Ma等[2]将循环神经网络(recurrent neural network,RNN)运用到网络谣言检测中,相比于传统的机器学习方法,大大提高了谣言检测的效率。刘政等[3]提出了一种改进的卷积神经网络(convolutional neural networks,CNN)模型用于微博谣言检测,该模型结构简单,易于实现。Chen等[4]将注意力机制与RNN模型相结合用于谣言检测,在一定程度上解决了文本信息过度冗余、远程间信息联系薄弱的问题。然而,上述模型只关注于谣言的文本信息而忽略了其附带的图片和社会信息,限制了模型的检测效果。针对于此,Jin等[5]利用神经网络分别对待测事件中的图片、文本和社会特征等信息进行编码并使用注意力机制将其结合,提升了图片信息的利用价值。Dhruv等[6]通过自动编码器对融合后的多模态向量进行约束,从而更好地学习多模态之间的联合表示。刘金硕等[7]则通过提取图像中隐藏的文字来提高模型的检测效果。
目前,多模态谣言检测模型已成为谣言检测领域的一大发展趋势,但现有的该类模型仍存在着各模态间信息融合不足和模型泛化能力较差等问题,这也是本模型着重解决的。
1 相关工作
现有的谣言检测模型大多数只关注于谣言的传播途径或者文本内容,而忽略了事件相关的图片信息。有研究表明[8],带有图片内容的新闻转发次数是纯文本新闻的11倍以上,其具有更强的迷惑性和传播性。目前,仅有少数工作关注到了新闻中的图片信息,但这些多模态谣言检测模型普遍只是将图像信息与文本信息进行简单的特征级融合后进行分类,而实际上各模态间的语义信息在特征空间是异构的,这可能会导致以下两个问题:①多模态之间的信息融合不够充分;②模型过于依赖各模态间的信息完整度(可能有的事件只存在文本信息,而有的事件只存在图片信息)。
针对上述问题,本文提出了将特征级融合与改进后的决策级融合相结合的多模态谣言检测模型MFCD。本模型通过多级融合框架对视觉特征和文本内容之间的区别性特征和相关性进行学习,在保留各模态原始信息的基础上进一步提升了各模态间的信息融合程度。同时,根据不同模态信息的实际缺失情况采取不同的决策级融合策略,在一定程度上解决了现有的多模态谣言检测模型过于依赖各模态间信息完整度的问题。
2 MFCD模型
MFCD模型总体框架如图1所示,主要由纯文本模型Textual、纯图片模型Visual和深度特征级融合模型(feature-level fusion model,FFM)等3个部分组成。首先,分别利用文本-卷积神经网络(text convolutional neural network,TextCNN)和深度残差网络(residual neural network,Resnet)[9]对文本内容和图片内容进行编码,构建Textual模型和Visual模型;然后将两者的语义映射进行特征级的融合,得到深度特征级融合模型FFM,其可以挖掘不同模态信息间的非线性关系,在剔除多模态间冗余信息的同时学习互补信息;最后,将3个模型的各自决策输入改进后的决策级融合层得到最终的决策结果。

图1 MFCD模型框架
2.1 文字特征提取器
相比于传统的RNN模型,TextCNN模型能够更好地扑捉到文本中的局部语义关系,已在短文本分类领域取得一定的成功[10]。其工作原理为利用各种形状的卷积核分别提取文本中不同粒度的特征并加以拼接,进而对文本进行分类。模型主体结构如图2所示,主要由预处理层、卷积层、池化层、融合层和输出层等5个部分组成。
(1)预处理层
使用预处理模型对分词后的中文文本进行编码,得到代表该文本的矩阵。其中,n代表该文本分词后的词语数量,d代表每个词语的向量表示维度。
(2)卷积层
卷积核c是一个形状为d*h的矩阵。其中,h为该卷积核的长度,d为该卷积核的宽度,该宽度与词语的向量维度保持一致。单位向量A中的第i个节点a(i)可表示为

(1)
(3)池化层
池化操作是从每个单位向量A中选取出最能代表该单位向量的某个节点。一般采用最大值池化方法,即选取其中值最大的节点代表该单位向量A。
(4)融合层
将各个池化层得到的特征进行拼接即得到对应的融合层。
(5)输出层
一般使用Softmax函数对融合层进行处理得到输出层,输出结果即为各个类别所对应的概率大小。

图2 TextCNN模型结构
2.2 图像特征提取器
现有的大多数多模态谣言检测模型[5-7]使用深度卷积神经网络模型VGG19(visual geometry group,VGG)对图片进行特征提取,在提升了图片信息利用率的同时也造成了模型参数过多、易过拟合等问题。针对这个问题,本文提出采用基于迁移学习的深度残差网络Resnet18模型代替VGG19。相比之下,Resnet18模型的参数量更小,训练速度更快,准确率更高。
Resnet模型最初由Kaiming He等提出,被广泛应用于图像处理和计算机视觉领域。其主要思想是采用了多级的残差模块进行连接,有效地缓解了传统深度卷积神经网络模型因层数过多而导致的反向传播梯度消失和模型性能退化等问题。
每个残差单元由一个残差学习分支和一个恒等映射分支组成,具体结构如图3所示。其中,x表示输入,F(x)表示残差学习分支的结果,relu表示激活函数,则残差单元的输出可表示为H(x)=F(x)+x。 当残差学习分支不工作时,H(x)=x。 残差分支中的两个1*1层作用分别为降维和升维,以保证F(x)的维度与x的维度保持一致,进而进行后续操作。

图3 Resnet单元结构
2.3 多级融合
根据目前已有的研究,多模态信息间的融合方式大致可分为数据级融合[11]、特征级融合[12,13]和决策级融合[14]。数据级融合是指直接将多个数据源集成到单个特征向量中再进行后续处理。该种融合方式的优点在于在一定程度上保持了数据的完整性,避免了数据的丢失和污染。但是其缺点也很明显,由于各种模态间的信息表现形式差异较大,此种融合方式很难利用各种模态信息间的互补性,甚至会造成很大的信息冗余。相比数据级融合,特征级融合和决策级融合的应用范围更加广泛,应用方式更加灵活。
近年来,将多种融合模式相结合使用的多模态模型已在多个领域取得进展[15,16],受此启发,本文提出了结合特征级融合与改进后的决策融合的多模态谣言检测模型,在保留了各模态信息独立性的同时使其充分互补,其融合原理如图4所示。
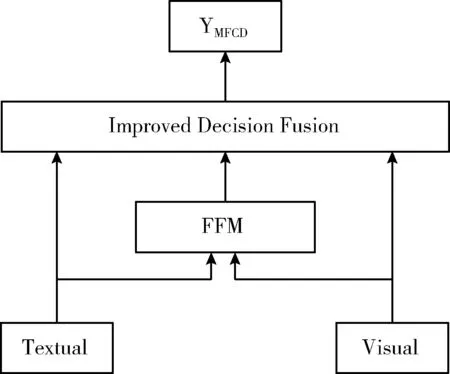
图4 多级融合框架
2.3.1 特征级融合
特征级融合又称中期融合,是指分别使用不同的特征提取器对各个模态信息提取后再进行拼接、按位加或者按位乘的操作过程。本模型采用直接拼接的特征级融合方案,具体过程如式(2)所示
Fi=Ti⊕Vi
(2)
式中:Ti表示第i个样本中文本信息的特征映射,Vi表示该样本中图片信息的特征映射,⨁表示连接操作,Fi则表示该样本的图文联合信息映射。
相比于数据级融合方式,特征级融合对不同模态信息采用不同的特征提取器,更加能挖掘各模态信息的潜在语义特征。但是单独的特征级融合方式对各模态的信息完整度要求很高,如果某个模态的信息缺失,只能使用对应模态数据的平均值或者其它数据进行填充,将会对模型的决策结果造成很大的不利影响。
2.3.2 改进后的决策级融合
决策级融合又称为后期融合,其首先分别提取各个模态的特征,然后输入对应的模型中并得到各自的分类结果,最后将各个模态的分类结果进行整合计算,以得到最终的分类结果。
决策级融合可以较好处理不同模态间的数据异步性问题,其融合规模也可以随着模态个数的增加而进行简单的扩展,对于融合不同性质特征的数据分类结果是十分有效的。但是当出现各个模态信息不完整的情况时,传统的决策级融合方案不能避免其带来的影响。针对本模型而言,当某一模态信息缺失时,不仅会影响到该模态对应模型的决策结果,还会对特征级融合模型FFM的结果产生影响,从而使总决策结果产生巨大偏差,导致分类错误。
针对于此,本模型采用一种改进后的后期融合方案,对于不同的模态信息缺失情况采用不同的决策级策略,从而避免了因某个模态信息缺失而影响到最终模型的分类结果。具体来说,当某一模态信息缺失时,则使用另一模态的分类结果作为最终分类结果;当各个模态信息完整时,使用三者与对应的自适用权重之积的和作为最终分类结果。具体见式(3)

(3)
式中:YTextual、YVisual、YFFM和YMFCD分别为各自模型对应的决策结果;α、β和γ分别为各个模型的所占权重,且满足 {α,β,γ|α,β, γ∈[0,1], α+β+γ=1}。
3 实验结果及分析
为验证本模型的可行性及检测效果,在微博数据集上进行了实验。
3.1 实验数据集


表1 微博数据集
从表1中可以看出,样本中模态信息不完整的情况是切实存在的,这也从侧面反映出本模型所采用的改进后的决策级融合方案是具有一定现实意义的。
3.2 模型参数设置
本模型采用小批量随机梯度下降方法训练数据,每个批次的样本数量为32,初始学习率设置为0.001,共训练60次循环。采用交叉熵损失函数和Adam优化器进行反向传播优化。同时,为防止模型过拟合,使用Dropout和L2正则化对模型参数进行约束。
3.3 基线模型
为公平比较各模型性能,以下模型均在上述数据集进行实验,且训练集与测试集的划分比例相同。
(1)Textual模型
该模型仅利用样本中的文本信息进行实验。首先使用结巴分词将中文文本进行分词,然后使用Word2vec技术将分词后的文本进行编码,编码后的单词维度为32。对于文本长度不足或者文本缺失的样本,使用0元素进行填充。TextCNN模型共有高度分别为1、2、3、4等4种形状不同的卷积核,每种卷积核的个数为8,故输出向量维度为32。将输出向量输入分类器,即得到该样本的最终分类结果。
(2)Visual模型
该模型仅利用样本中的图片信息进行实验,对于图片信息缺失的样本用0进行像素级的填充,即利用一张纯黑图片代替该样本中的图片信息。将图片编码后输入Resnet18模型,后接一个维度为32全连接层,最后输入分类器得到样本分类结果。为增强模型泛化能力和减少训练时间,Resnet18网络采取迁移学习的方式,选用已在大型数据集Image1000上训练完毕的模型参数且不参与反向传播,仅对后接线性层进行微调。
(3)FFM模型
将Textual模型和Visual模型提取的特征向量进行特征级融合后输入分类器进行分类。
(4)DFM模型
将Textual模型和Visual模型分别得到的分类结果进行决策级的融合。
(5)att-RNN模型[5]
该模型利用注意力机制将文本、图片及社会特征等信息进行融合后输入分类器进行判断。为公平比较,本文采用其删除了社会特征后的模型,其余参数与文献[5]中所述一致。
(6)MVAE模型[6]
该模型利用VAE(variational autoencoder,VAE)模块对多模态特征融合后的向量进行约束,然后利用该特征向量进行分类。
(7)MRSD模型[7]
该模型首先将图片中的文本提取出来,然后将其与样本中的文本内容进行连接,最后将图片与连接后的文本进行特征级的融合并分类。
(8)MFCD-模型
使用一般的决策级融合代替改进后的决策级融合,其余部分与MFCD模型一致。
3.4 模型对比结果及分析
本文采用F1值、准确率(Accuracy,A)、精确率(Precision,P)和召回率(Recall,R)等4个常用指标对各模型进行评价。各模型结果见表2。

表2 实验结果
由表2可以看出,MFCD模型在最重要的性能指标F1值和准确率上分别达到了0.830和0.829,均高于目前主流的多模态谣言检测模型,充分验证了本模型的先进性能。精确率与召回率在一般情况下是相互矛盾的,难以做到双高。MSRD模型在精确率指标上最高,达到了0.854,但其召回率却只有0.716,这可能是由于该模型对正负样本的判别能力相差较大而导致的。
(1)单模态与多模态的性能对比
多模态模型FFM和DFM在F1值上分别达到了0.808和0.811,均高于纯文本模型Textual的F1值0.775和纯图片模型Visual的F1值0.714,说明特征级融合和决策级融合都能够有效地提高谣言检测效果。
(2)单级融合与多级融合的性能对比
多级融合模型MFCD-的F1值达到了0.824,分别比FFM和DFM高出了1.6%和1.3%,且高于目前主流的多模态谣言检测模型,说明通过构建多级融合框架进一步提高了多模态间的信息互补能力,剔除了冗余信息。
(3)决策级融合改进前后的性能对比
MFCD模型在F1和准确率指标上均高于MFCD-模型,验证本文提出的改进后的决策级融合方案对于缓解样本中模态信息缺失情况是切实有效的。针对模态信息不全的样本单独进行统计,MFCD模型在其上的准确率为0.831,而MFCD-模型的准确率仅为0.812,进一步验证了改进后决策级融合方案的效果。
MFCD模型效果优于MFCD-模型的原因主要可以归纳为以下两点:
一方面在于MFCD-模型对于样本中缺失的模态信息需要使用0元素进行填充。如在谣言事件“今天下午位于深圳东门发生特大暴力恐怖事件,前往东门的朋友要注意安全!请互相转告!怕二次事件再次发生!!”中,因为该事件缺少图片信息,MFCD-模型使用了大量的无意义的0元素填充出缺失的图片信息,增加了无用的干扰信息,从而导致了最终的分类结果错误。而MFCD模型直接利用纯文本进行判断,避免了图片信息缺失带来的负面影响,更容易得到正确的分类结果。
另一方面得益于MFCD模型对不同的子模型给予了不同的权重,更好地发挥了各自的性能。通过对超参数进行迭代,发现当α=0.11、β=0.39、γ=0.5时MFCD模型取得最佳分类效果。
4 结束语
本文针对目前多模态谣言检测领域存在的模态间信息融合不充分、过于依赖各模态信息完整度等问题提出了MFCD模型,该模型将特征级融合与决策级融合相结合并对决策级融合进行了改进,在一定程度上解决了上述的两个问题。实验结果表明,本模型性能在F1值和准确率指标上均优于相关基线模型。下一步将重点研究如何构建更加高效合理的特征级融合方案,进一步剔除冗余信息,提高各模态间的信息互补能力。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
环球时报(2022-04-13)2022-04-13
纺织科学研究(2021年9期)2021-10-14
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
科学大众(2020年12期)2020-08-13
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
小天使·四年级语数英综合(2018年1期)2018-07-04
民生周刊(2017年22期)2017-12-12
新高考·高一数学(2016年10期)2017-07-06
