
基于关键点的眼睛定位和状态估计
2022-06-24 10:02孙哲南王财勇王云龙朱宇豪
计算机应用与软件 2022年4期
何 勇 孙哲南 王财勇 王云龙 朱宇豪
1(湖南工业大学计算机学院 湖南 株洲 412007) 2(中国科学院自动化研究所 北京 100190)
0 引 言
随着现代社会的高速发展,安全、可靠的身份验证变得更加重要,以人脸、虹膜、指纹等为代表的现代生物特征识别技术正逐步取代传统的身份识别技术,并广泛应用在安防、金融支付、刑侦、考勤门禁等领域。眼睛是人脸、虹膜、眼周识别等最重要的特征,因此准确可靠的眼睛定位对于提升身份识别的性能有重要意义。此外,眼睛也是表现人的情感和状态的重要窗口,因此眼睛状态估计在人机交互、睡眠研究和疲劳驾驶等领域都有广泛应用。
眼睛关键点可以准确地反映眼睛在人脸图像中的位置,而眼睛状态估计是为了估计眼睛的左右和开闭状态。眼睛作为一种特殊的生物特征,很容易受到光照条件、镜片遮挡、头部姿态改变的影响,导致眼睛的形态发生较大的变化,这就为定位眼睛位置、评估眼睛状态造成了很大困扰,大多数眼睛定位和状态估计方法都尝试着增加网络深度或者采用更复杂的网络结构来应对这些挑战。
针对生物识别场景下广泛存在的半人脸图像,本文提出直接利用单阶段的堆叠沙漏网络[1]定位眼睛关键点,从而确定眼睛的位置,并利用获取的关键点估计眼睛的左右和开闭状态。此外基于关键点信息也可以用于眼周图像的对齐,进一步地提高眼周识别的精度。针对现有的眼睛数据集存在姿态变化性较差、状态单一等缺点,收集并整理了一个新的有挑战性的数据集OCE-1000,并手动地为每只眼睛标记了四个关键点(左眼角、上眼皮最高点、右眼角、下眼皮最低点)和左右开闭状态,满足眼睛关键点定位和状态估计的需要。最终的实验结果表明提出的方法在复杂背景和严重遮挡的条件下可以达到很高的关键点定位和状态估计精度。
本文主要贡献为:1) 建立了一个较大的可见光和近红外眼睛数据集OCE-1000,补充了生物特征识别领域眼睛数据的空缺,并且该数据集可以公开获取;2) 提出了高效的单阶段网络框架可以在复杂场景下预测眼睛的关键点,定位出眼睛的位置,并基于这些关键点实现了准确的眼睛状态估计;3) 提出了基于关键点的眼周图像裁剪和对齐,提升了眼周识别的可用性和准确性。
1 相关知识
眼睛检测是一个热门的研究话题,很多优秀的方法陆续被提出。经典的Viola-Jones[2]检测器可以通过提取眼睛周围的haar特征并使用级联分类器来检测眼睛的位置。Young等[3]通过霍夫变换确定虹膜和瞳孔的位置来定位眼睛区域。Feng等[4]使用Variance Projection Function(VPF)[5]来定位眼睛的关键点,从而指导检测眼睛的位置和形状。El Kaddouhi等[6]采用Viola-Jones检测器来检测人脸的位置,然后基于人脸的位置和先验的知识来生成眼睛的检测框。总体来说,这些早期的眼睛检测方法大多依赖手工特征或者先验策略,因此容易受到外界噪声因素的干扰。此外,眼睛状态需要在检测的基础上进行估计。
随着深度学习的发展,各种先进的目标检测方法被提出,例如SSD[7]、YOLO[8]、Faster RCNN[9]。这些方法会在输入图像上生成大量的锚点框,并为每一个检测框打一个分数,然后选择其中得分较高的检测框作为预测框,这些方法为了更准确地定位目标的位置,往往需要生成大量候选检测框,这在一定程度上会限制目标检测的速度和准确性。
此外现实场景捕获的人脸或者眼部图像含有很严重的噪声,挑战着许多现有的方法,表现在:1) 局部极端光照(如:强光和阴影)和遮挡会给眼睛区域带来较大变化和干扰,导致某些区域像素值偏离正常值,甚至遗失;2) 变化的脸部姿态会干扰很多依赖先验知识的眼睛定位和状态估计方法;3) 现有数据集常常存在类别不均匀的问题,例如闭眼的图像是少数的,影响了很多方法的训练。图1展示了在不同的姿态和遮挡、光照下的眼睛图像。

图1 不同的姿态和遮挡、光照下的眼睛图像
为应对这些挑战,Huang等[10]使用级联的两阶段框架先预测人脸的68个关键点从而获取眼睛的位置,然后采用一个多任务的网络去估计眼睛区域的7个关键点和眼睛的开闭状态,这种方法造成重复的低层次特征提取,速度较慢。Gou等[11]提出了级联回归的方法,可以检测眼睛的位置并估计瞳孔被眼皮遮挡的概率,这个方法在光源复杂、镜框遮挡和目标模糊等情况下会导致定位和状态估计结果不准确。
抛却冗余的基于锚点框的检测方法以及级联的思路,直接预测人脸图像中的眼睛关键点,从而预测眼睛位置和状态估计的方法明显在抗干扰的性能上更为优越。这是因为检测框考虑的是目标中更具判别性的区域,而关键点选择的往往是最具有判别性的点,这些点与点之间往往存在着各种联系,这就保证了在某些区域或者某些关键点被遮挡或者不存在的情况下,依然可以有效地预测出目标的其他关键点,这些关键点不但反映了目标的位置,同时也可以反映目标当前的状态。基于此,选择使用性能卓越的堆叠沙漏网络,提取不同尺寸下的眼睛特征,保证了眼睛关键点定位的准确性,同时基于眼睛关键点的空间位置关联性和人的先验知识,使眼睛状态估计更为鲁棒。
2 方 法
2.1 基于关键点的眼睛定位和状态估计
提出一种基于眼睛关键点来定位并估计眼睛状态的方法。主要分为以下几个步骤:1) 利用堆叠沙漏网络强大的特征提取能力融合不同尺度下的特征,并输出一系列热点图,每一个热点图表征了关键点存在的概率。2) 基于这些关键点的空间位置关系生成一系列候选检测框,利用IOU选择眼睛最佳检测框。3) 利用人的先验知识,在这些关键点基础上建立眼睛状态估计策略,输出状态估计结果。图2是基于眼睛关键点定位眼睛位置和状态估计的框架示意图,图3是网络输出的眼睛关键点的热点图及其对应眼睛的位置。
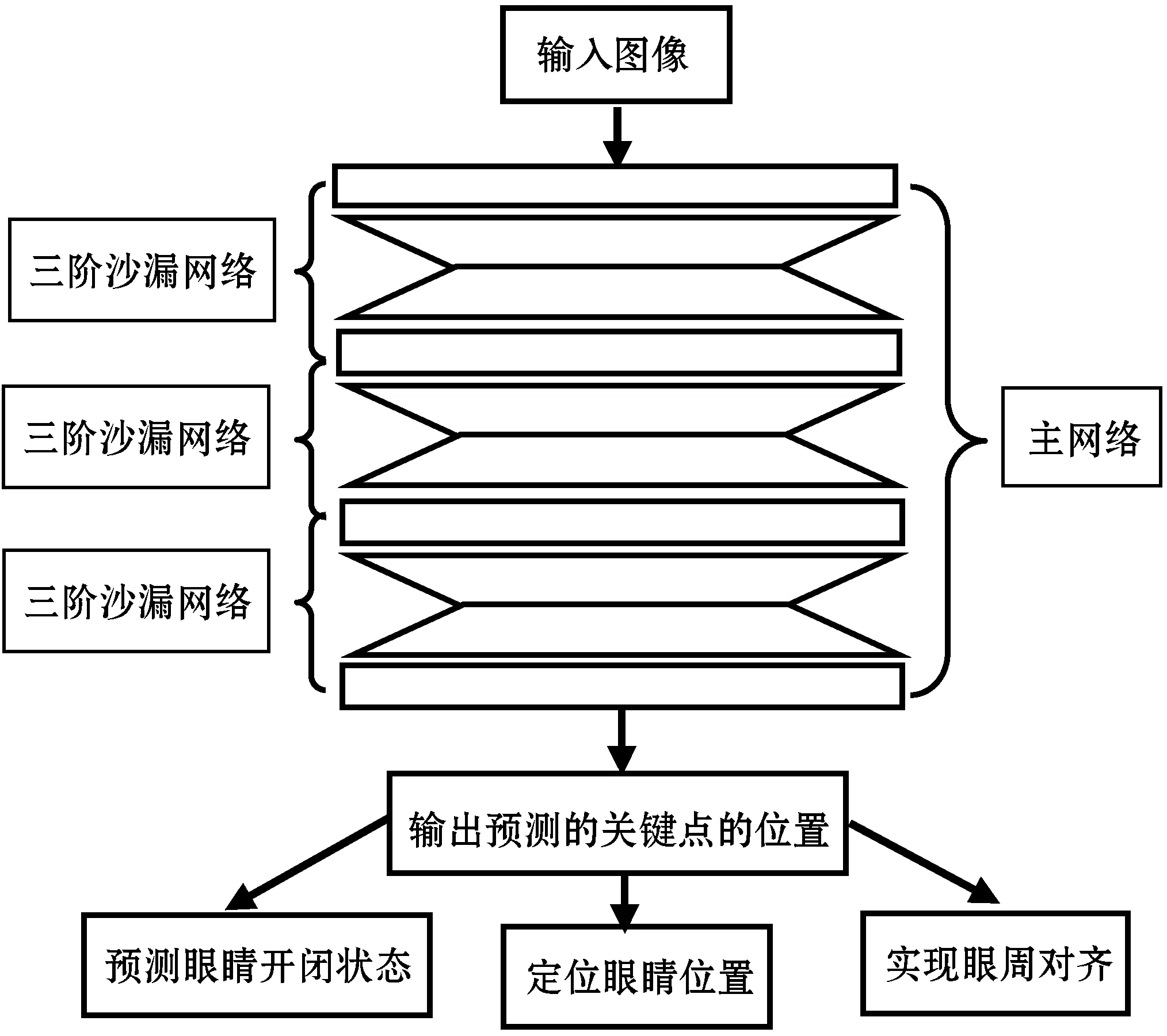
图2 整体网络框架结构图

图3 网络热点图及对应眼睛位置
2.2 堆叠沙漏网络
Newell等[1]提出的沙漏网络最初被用来估计人体姿态关节点,它可以很好地挖掘人体各部分关节点之间的位置关联性,通过堆叠多个沙漏网络,制定合理的训练策略,即使在严重遮挡和复杂背景的条件下,也可以实现很好的关键点定位结果。当前一些目标检测任务通过堆叠沙漏网络输出特定的目标关键点实现目标检测。残差模块是沙漏网络的基本结构单元,如图4所示。

图4 沙漏网络的基本模块单元—残差模块
沙漏网络以残差模块为基本单元。残差模块[12]在保留原有尺寸特征的基础上,同时提取了较高层次的特征,并且不改变数据尺寸,只改变数据深度。沙漏网络与残差网络结构类似。单阶的沙漏网络拥有上下两个半路,上半路在原始输入尺度上经过若干个残差模块,逐步提取更深层次特征,下半路经历了先max pooling降采样,然后经过残差模块提取深度特征,再升采样(采用最近邻插值)的过程。多阶子模块提取深度的特征,同时保持特征尺度不变。多阶沙漏每次先分出上半路保留原始信息,然后开始降采样;每次升采样之后,和上一个尺度保留的上半路信息相加;在两次降采样之间,一般使用三个残差模块来提取特征;两次相加之间,还需要使用一个残差模块再次提取特征。三阶沙漏网络示意图如图5所示。

图5 三阶沙漏网络模型
进一步地,堆叠多个沙漏网络,前一个沙漏网络的输出作为下一个沙漏网络的输入,采用由粗到精的方法逐步细化关键点的定位精度。在本文中,采用MSE损失来训练眼睛关键点定位:
(1)

2.3 基于关键点的眼睛定位和状态估计
2.3.1眼睛定位方法
经过观察分析,结合眼睛关键点之间的位置关系,可以生成指定大小的眼睛检测框来表示眼睛位置,示意图如图6所示,具体步骤如下(以右眼为例):
步骤1利用眼睛右眼角关键点(xrr,yrr)、左眼角关键点(xrl,yrl)得到眼睛中心点坐标:
步骤2计算眼睛右眼角到中心点(xrc,yrc)的欧氏距离Lrrc和眼睛左眼角到中心点(xrc,yrc)的欧氏距离Lrlc:
(2)
(3)
步骤3经过线性变换得到检测框的左上角的点(xblt,yblt)和右下角的点(xbrb,ybrb):
(4)
(5)
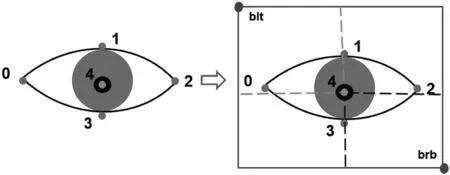
图6 眼睛定位示意图
调节参数α、β(α≥0.5,β≥0.5),可以直接生成不同大小的眼睛检测窗口,本文选择与标记框(经验上手动标记)有最大IOU的检测框,在训练集上进行实验比较,发现在NIR-1000数据集下,α=β=0.7的时候,可以保障与标记框有最大IOU,同样在VIS-1000数据集上,α=β=0.85的时候获得最佳检测框。
2.3.2眼睛状态估计
眼睛关键点标注示意图如图7所示。

(a) 眼睛睁开 (b) 眼睛闭合图7 眼睛关键点标注示意图
从眼睛在开闭状态下建立的先验知识中获得启发,提出基于眼睛关键点的眼睛状态估计方法。鉴于已经得到了上眼皮最高点(xrt,yrt)和下眼皮最低点(xrb,yrb),右眼角关键点(xrr,yrr)和左眼角关键点(xrl,yrl),利用上下眼角之间的高度差hrtb=|yrt-yrb|作为衡量眼睛开闭状态的指标,考虑到不同场景下,这个高度差没有一个统一的衡量指标来认定眼睛的状态,所以利用左右眼角之间的水平差值wrrl=|xrr-xrl|来归一化这个指标,映射为t=hrtb/wrrl,因此t可以作为反映当前眼睛状态的指标。经过实验验证,得到眼睛开闭状态实验结果分布图如图8所示。
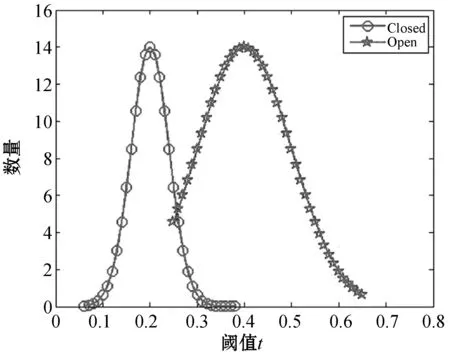
图8 开闭眼状态统计直方分布图
由图8发现:当t<0.3的时候,眼睛大概率可判定为闭眼状态,当t>0.3的时候,大概率可判定眼睛为睁眼状态。t值可能会随着人种不同、民族不同而略有改变,但在已经获得眼睛关键点的基础上,t值的选取可以根据不同任务需求来选定。
2.4 评判标准

(6)
(7)

3 实验结果及分析
3.1 OCE-1000数据集
目前针对眼睛的数据特别稀少,现有的文章中提到的数据集多是从网上爬取,或者挑选部分人脸数据集来做关于眼睛定位的任务,这些数据集往往会存在检测目标状态单一、图像质量较差、标注不完善等问题。为此,在可见光和近红外光源条件下建立了一个较为完善的眼睛数据集OCE-1000。OCE-1000数据集包含2 000幅图像,包含遮挡、面部表情和头部姿态等多种变化,其中有1 000幅可见光下采集的图像组成VIS-1000数据集,分辨率为4 160×2 336。除此之外,还包含了1 000幅分辨率为1 080×1 920的近红外图像组成了NIR-1000数据集,图9中是OCE-1000部分数据集图像。这个数据集用来做眼睛定位和状态估计任务是有挑战性的,但也可以真实反映网络模型的鲁棒性。在这个数据集上,同时标注包含了眼角和眼皮四个关键点的坐标,还包括眼睛区域的标定框和眼睛的状态。

图9 随机选取部分OCE-1000数据集图像
3.2 模型结构和训练细节
堆叠沙漏网络可以准确预测眼睛关键点。图像输入沙漏网络之前,首先经过一个核大小7×7、Stride为2的卷积层和一个2×2的max pooling层。接下来输入到3个形似编码解码网络结构的沙漏网络,受残差网络的启发,沙漏网络采用残差模块结构设计来使整个网络更深并且更容易优化,设置整个沙漏网络的通道层为256,并且在最后256个优化的特征层使用8个核大小为1×1的卷积层使输出为8个眼睛关键点的热点图。训练期间,在输入图像的分辨率为512×256,最终的输出分辨率为128×64。整个网络采用标准的Adam算法优化整个网络,初始学习率设置为2e-5并且选择batch size为8,我们设置了最大训练迭代次数为750,学习率随着验证集的损失而调整,如果在若干个迭代次数中验证集的损失不再下降,则学习率降低为原来的0.5倍,直到网络收敛。保存所有训练迭代中Loss最低的5次。训练过程中,将训练集分成两部分,分别用于训练和验证,比例为3 ∶1。
3.3 眼睛关键点定位与眼睛状态估计结果
3.3.1眼睛关键点定位的结果
在不同的眼睛数据集上,眼睛图像的尺寸大小不一,需要一个合理的眼睛关键点评价标准,利用2.4节所示评判规则可以很好地解决这个挑战。在VIS-1000数据集和NIR-1000数据集中,都选择预测的眼睛关键点偏差率大于0.2视为预测失败,实验结果如表1所示。

表1 OCE-1000数据集关键点定位结果
从表1可以看出,在NIR-1000数据集中关键点偏差率比VIS-1000数据集中的偏差率小,这是因为图像中背景信息所造成的影响,NIR-1000数据集中的图像内容较为单一,目标很明显,而在VIS-1000数据集中图像背景复杂,目标状态、尺寸大小差异性较大,很容易受到背景信息的干扰。尽管存在数据上的差异,但是提出的方法在两个数据集上都达到了98%以上的关键点定位准确率。表2是在公共数据集Gi4e和BioID上预测的关键点的定位结果,表明模型的泛化性良好。

表2 在Gi4e和BioID数据集关键点定位结果
3.3.2眼睛关键点检测的结果
为了更好地展示眼睛定位的效果,我们选择使用关键点来生成眼睛检测框,这些点不仅包含着眼睛的位置信息,同时也包含着眼睛的类别信息(左眼和右眼),所以基于这些点可以很好地生成眼睛检测框。我们统计了训练集中标记的眼睛检测框,根据2.3.1节所示的生成规则发现,在NIR-1000训练数据集中令α=β=0.7,可以实现与标记的眼睛检测框有最大重叠,即生成眼睛检测框的左上角和右下角的坐标可表示为:
(8)
在VIS-1000训练数据集中令α=β=0.85,可以保证与标记的眼睛检测框有最大的重叠,即生成眼睛检测框的左上角和右下角的坐标可表示为:
(9)
在上述生成规则下,在测试集上可以保持生成的预测眼睛检测框与标记的眼睛检测框达到IOU=0.8,准确率达到了97%以上,对比传统的目标检测方法,结果如表3所示。

表3 在OCE-1000数据集眼睛检测结果
3.3.3眼睛状态估计的结果
采用2.3.2节所示方法,融合人们对于眼睛开闭状态先验知识的理解,利用预测的上眼皮关键点和下眼皮关键点的距离在眼睛开闭状态下的变化表示眼睛开闭状态。设定判别眼睛开闭状态的阈值为0.3,发现:当t<0.3的时候,眼睛可判定为闭眼状态,当t>0.3的时候,可判定眼睛为睁眼状态。表4是在公共数据集Gi4e和BioID上与其他眼睛状态估计方法的比较,发现本文提出的算法均可以达到最优的实验结果。表5是在标注的数据集OCE-1000上与其他眼睛状态估计方法的比较,发现本文提出的算法同样可以达到最优的实验结果。

表4 在公共数据集Gi4e和BioID上的对比实验结果(%)

表5 在标注数据集与其他眼睛状态估计方法的比较(%)
表面上看,眼睛状态估计依赖于眼睛关键点预测的准确性,其实在加入眼睛各个关键点之间的位置关联性后,可以保证即使在关键点预测一般的情况下,也可以实现较好的眼睛状态估计。
3.4 基于眼睛关键点获取眼周数据集
深度学习的发展很大程度上是数据量的爆发式增长,很多数据集数据量达到十几万,甚至数百万,但在虹膜识别、巩膜识别还有眼周识别领域,目前比较缺乏较大规模的数据集。目前存在的较大的人脸图像有数百万,可以考虑从这些人脸图像中获取眼周、虹膜和巩膜图像,而不需要特意取采集,这是本文算法的一个优势。
在一幅包含眼睛的人脸图像上,通过直接预测眼睛的关键点,输出眼睛的状态,根据在2.3.1节中所提出的方法,当α和β相同时,提取的眼睛区域是一个正方形,当α和β不同时,提取的眼睛区域是一个长方形,调节α和β可以提取出最佳的眼睛图像,这里取α=β,使提取的眼睛区域为正方形。对于提取虹膜、巩膜图像,往往取0.7附近比较好,而对于眼周识别来说,需要更多的眼睛区域的特征,就需要取1.5。表6和表7是在OCE-1000数据集上采用不同超参数裁剪眼睛区域与手动标注的groundtruth交并比的结果,可以看出在合适的α和β参数下能得到最佳的眼睛区域。

表6 在NIR-1000数据集上不同的超参数的比较

表7 在VIS-1000数据集上不同超参数的比较
3.5 眼睛关键点在眼周识别上的应用
在人脸识别和虹膜识别受约束的环境下,眼周识别是一种有效的生物识别方法。眼周识别指的是利用眼睛区域的纹理、皮肤、眉毛等特征来识别,但眼睛的位置和状态容易受到头部姿态变化的影响,这对利用眼周来进行识别是很不利的。基于提出的眼睛关键点定位方法得到准确的眼睛关键点信息,根据在2.3.1节方法,选取合适大小的α、β两个超参数,可以裁剪合适大小的眼睛区域进行眼周识别;通过关键点信息对不同状态下的眼睛做仿射变换,实现人眼的对齐,避免由于眼睛形状各异导致识别不到或者识别错误,大大提高眼周识别的准确率。眼睛关键点也是很好的语义信息,可以提升眼周识别的鲁棒性,增强识别效果。
根据在OCE-1000数据集上得到的眼睛关键点信息,调节α和β两个超参数,得到如下大小的眼周数据集,同时利用眼睛的左右关键点进行仿射变换,将眼睛对齐到图像中的固定位置,选取图像像素平均值补全对齐后缺失的像素值,对齐结果如图10所示。

图10 眼睛对齐前后对比结果
利用眼睛关键点进行眼周对齐操作之后,将眼睛区域变换到图像中的固定区域,对于实现特征提取,特征匹配和识别有重要意义。
4 结 语
相比于之前的眼睛定位和状态估计需要先执行眼睛检测,再设置一个合理的分类器来估计眼睛状态,现在更多地考虑两个任务之间存在的关联性,通过单阶段网络大大削弱网络的复杂度,同时依赖于眼睛的先验知识,基于数据驱动的方式,极大地提升网络预测的准确性。区别于传统的基于目标检测框的方法,首先采用性能优越的堆叠沙漏网络预测出眼睛边缘的四个极值点(左眼角、上眼皮最高点、右眼角、下眼皮最低点)。然后将这些关键点作为线索,融合关键点之间的空间位置关系,依赖于人在眼睛开闭状态下的先验知识,设定合适的阈值,可以实现高效地估计眼睛当前的状态。该方法首次在单阶段网络框架下同时实现眼睛定位和状态估计,通过在新建立的眼睛数据集OCE-1000进行验证分析,证明了该方法的可行性和有效性,为实现眼睛检测和状态估计提出了新的思路和方法。
眼睛的关键点提供了精准的目标定位信息,可以合理地把眼睛区域提取出来,这就为创建一个大型眼周数据集提供了可能。利用预测的眼睛关键点进行眼部预处理,实现眼周对齐,可以提升眼周识别的准确性。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
建材发展导向(2022年2期)2022-03-08
参花(下)(2022年1期)2022-01-15
海峡姐妹(2018年2期)2018-04-12
数学大王·低年级(2018年3期)2018-03-27
人大建设(2018年12期)2018-03-21
杂文选刊(2018年1期)2018-01-09
广东教育·高中(2017年10期)2017-11-07
儿童故事画报·自然探秘(2017年2期)2017-09-26
儿童故事画报·自然探秘(2017年1期)2017-06-12
