
基于模糊隶属度函数的脑图像分割方法
2022-06-24 10:11刘晓芳
计算机应用与软件 2022年4期
杨 兵 刘晓芳
(中国计量大学计算机应用与技术研究所 浙江 杭州 310018) (浙江省电磁波信息技术与计量检测重点实验室 浙江 杭州 310018)
0 引 言
磁共振成像(Magnetic Resonance Imaging,MRI)具有软组织对比度高、无放射损伤等优点[1],广泛用于人体脑部成像。脑图像分析是了解人脑健康状况以及生理特征的重要渠道,其中脑图像分割是研究人脑解剖结构以及智能诊断脑部疾病的基础,近年来,机器学习技术因其具有良好的数据预测能力以及模型泛化性能,被广泛用于医疗数据智能诊断[2]中。脑组织分割和脑肿瘤智能检测是脑部图像分割的两个重要研究方向,本文的目的是应用机器学习技术对脑图像中脑灰质(Gray Matter,GM)、脑白质(White Matter,WM)、脑脊液(Cerebrospinal Fluid,CSF)三种主要脑组织进行自动分割。
由于成像设备等原因,磁共振图像存在各组织之间没有明显的边界、各组织之间灰度值重叠等现象[1],针对此问题,Vaishnavee等[3]将支持向量机用于脑影像智能分析中,证明支持向量机可以根据医学图像灰度不均匀以及组织边缘不清晰等特点做出准确的识别分析。支持向量机是一种基于类间最大距离的数据处理算法,其分类超平面的建立仅依赖于少数支持向量[4],具有较好的泛化性能和判别能力,在此基础上,模糊支持向量机将模糊理论和支持向量机相结合[5],提出根据空间距离判别规则对样本赋权,在解决样本数据不完全属于某一类的情况下表现出了较好的预测能力,广泛应用于医学图像分析中。
隶属度函数的设计是构建模糊支持向量机模型的关键[5]。目前,隶属度函数的设计大多基于同类样本之间的几何距离,没有考虑到不同类样本之间的模糊距离,无法有效解决灰度不均匀带来的像素值交叉重叠问题。基于此,本文提出一种基于类间样本模糊距离的隶属度确定方法,综合考虑同类样本中心以及不同类样本中心对待赋权样本的影响,训练模糊支持向量机模型对三种主要脑组织进行自动分割。
1 相关工作
1.1 图像分割
图像分割是指利用计算机辅助技术将图像划分为具有不同性质的图像块[6],传统算法如直方图方法[7]提取图像特征如梯度特征,颜色直方图、纹理特征将图像划分为不同图像块。然而,由于医学图像具有灰度不均匀、各组织之间边界不清晰等特点,传统算法不能较好适应此种情况。
研究人员将支持向量机应用于医学图像处理中,如Blumenthal等[8]将支持向量机应用于肿瘤图像分类,Khedher等[9]将支持向量机与主成分分析方法结合用于阿尔兹海默症的早期诊断,Emblem等[10]将支持向量机用于术前脑部胶质瘤生存预测。然而,上述方法没有充分考虑到医学图像的特点,没有将同类样本距离以及不同类样本距离引入支持向量机中,无法有效解决医学图像分割面临的边界不清晰和灰度不均匀等问题。由支持向量机改进的模糊支持向量机在处理样本不完全属于某一类的问题上表现出不错的应用前景,模糊支持向量机的构建主要分为三部分:1) 根据样本隶属度函数计算样本隶属度;2) 对样本进行赋权,训练模糊支持向量机模型;3) 对模型调整参数,使其具有较好的判别能力与泛化性能。
1.2 支持向量机
支持向量机是一种基于类间距离最大化的数据处理算法[11],其目标是在多维特征空间中确定最优分类超平面,使得分类确信度(confidence)最大。支持向量机能够很好地处理线性可分问题,对于线性不可分问题,支持向量机引入核函数将原始数据从低维空间映射到高维空间,从而解决原始数据在低维空间中线性不可分的问题。即考虑以下问题:
(1)
式中:φ为原始数据空间到高维特征空间的映射;w为数据权重项;b为数据偏置项。核函数就是将映射形式φ隐式地表示为原始数据内积的形式:
(2)
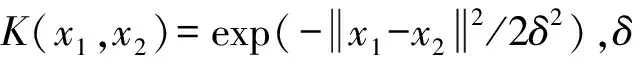
(3)
s.t.αi≥0,i=1,2,…,n
对于离群点,支持向量机通过引入松弛变量ξ来更好地容忍少数离群点对于分类超平面地影响,目标是解决以下原始问题:
(4)
s.t.yl(wTxl+b)≥1-ξl,i=1,2,…,n
ξl≥0,l=1,2,…,n
式中:w为权重因子;C用于控制最大分离超平面与数据偏差的权重;x为样本数据点;ξ为松弛变量;y为样本数据的标签。通过拉格朗日法求解得到以下对偶问题:
(5)
0≤αi≤C,i=1,2,…,n
通过对拉格朗日乘子α的求解,将原始问题转化为对偶问题。
1.3 模糊支持向量机
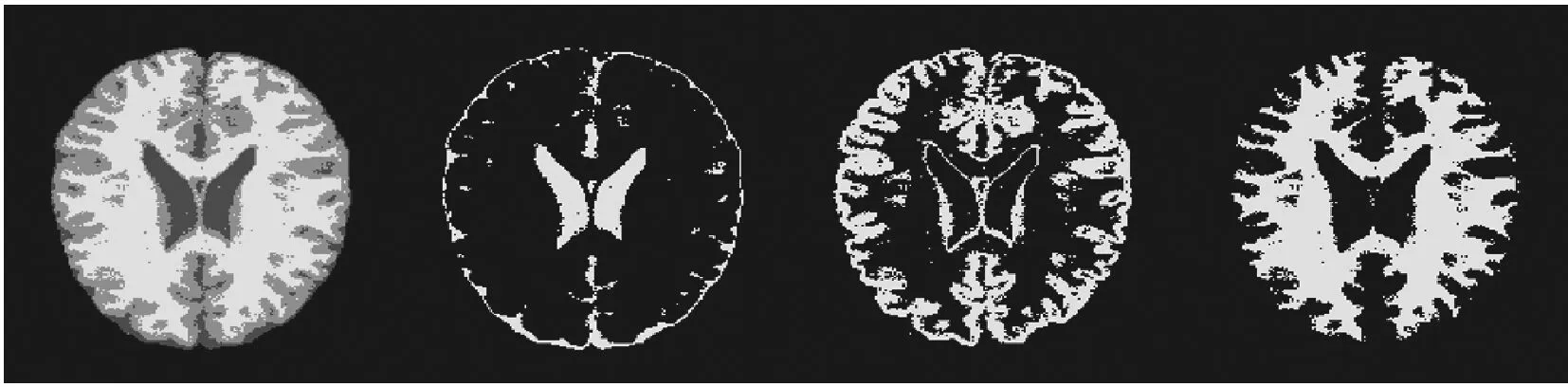
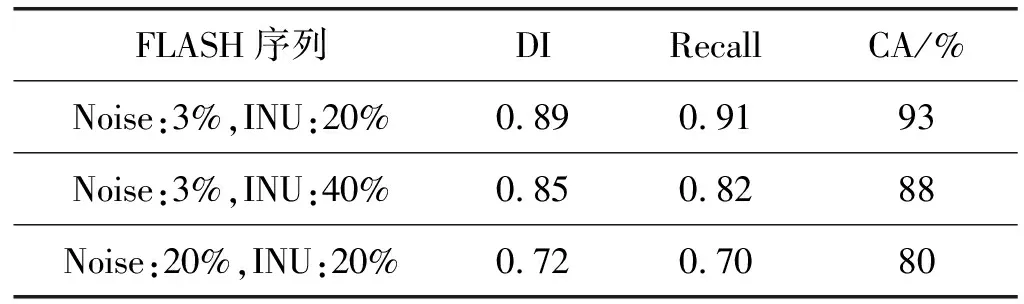
传统支持向量机中,每个样本点完全属于某一类,不能处理样本同时属于多类的情况。Khodagholi等[12]将模糊理论引入支持向量机中,赋予每个样本点不同的隶属度ml(0 s.t.yl(w·xl+b)≥1-ξl ξl≥0,l=1,2,…,n (6) 由拉格朗日乘子法得到原始问题的对偶问题: 0≤αj≤mjC,j=1,2,…,n (7) 样本隶属度的确定是构建模糊支持向量机的关键。Lin等[13]提出一种基于样本到样本中心距离的隶属度确定方法,假设有样本集{(x1,y1),(x2,y2),…,(xn,yn)},y∈{-1,+1},x+表示正类样本的均值,x-表示负类样本的均值,r+=max|xi-x+|,r-=max|xi-x-|,则样本隶属度mi定义为: (8) 上述方法没有考虑到各类别样本之间的内在联系,将各类别的样本孤立看待。张翔等[14]考虑了样本与样本中心的关系以及样本之间的紧密度,提出了一种基于样本紧密度的隶属度计算方法,但无法有效解决孤立样本隶属度赋权问题。 由于成像技术等原因,医学图像中的每个像素的灰度值通常是多种组织灰度值的平均,这也导致医学图像中组织与组织之间边界不清晰。针对此问题,本文设计了一种基于不同类别样本之间模糊距离的隶属度计算方法。 图1中,超球体分别表示三种不同的脑组织。AB、AC、BC表示各脑组织样本间最远距离。a、b、c分别表示各脑组织样本中心,设样本点x1到三种脑组织的距离分别为L2、L1、L3。 图1 样本隶属度 (9) 样本点x2到超球体中心b、a、c的距离分别为M1、M2、M3。 (10) 样本点x3到超球体中心b、a、c的距离分别为N1、N2、N3。 (11) 则样本点x1的隶属度m1为: (12) 样本点x2的隶属度m2为: (13) 由于样本点x3位于三角形ABC之外,故样本点x3的隶属度m3为: (14) 式中:λ、μ为模糊距离系数。若L1=M1,即样本点x1和样本点x2在超球体内处于同一球面上,但由于L2+L3 综上,对于位于三角形ABC之内的样本隶属度计算公式为: (15) (16) 式中:μ为模糊距离系数,使位于三角形ABC之外的样本隶属度mi<0.5。 本文提出的算法整体流程如图2所示。 根据图2,模糊隶属度函数算法主要步骤如下: 1) 根据具体应用实例,提取数据特征,如图像的梯度特征,纹理特征等。 2) 结合样本标签,计算每个数据样本的模糊隶属度。应用于图像数据时,不计算背景样本的模糊隶属度。 3) 根据输入数据特征,并划分数据集为训练集、验证集以及测试集,将步骤2)计算的样本模糊隶属度作为样本数据权重,建立模糊支持向量机模型。 4) 使用交叉验证策略,根据验证集的分类精度调整模型参数(惩罚系数C、核函数系数、模糊距离系数μ和λ等)。 5) 使用步骤4)得到的分类模型,验证模型在测试集上的精度。 此外,本文还给出了具体的算法执行流程,其中图像的问题特征提取和样本的模糊隶属度计算以伪代码方式展现。 Step1设定模型初始参数,包括惩罚系数C,迭代次数MaxG,核函数系数σ,模糊距离系数λ、μ等。 Step2数据样本预处理,包括归一化,去除异常值等。 (17) Step3设定数据划分比例:a、b、c。分别将数据分别划分为训练集、验证集、测试集。 Step4提取数据特征,如图像的梯度特征、纹理特征(对比度CON、ASM能量、熵)等。 Gx(x,y)=H(x+1,y)-H(x-1,y) Gy(x,y)=H(x,y+1)-H(x,y-1) (18) 以图像的纹理特征提取为例,imgLength、imgwidth分别表示图像的长和宽,GLCM_GrayLevel表示灰度共生矩阵的灰度级数,greycomatrix_diatance表示灰度共生矩阵距离,greycomatrix_angles表示灰度共生矩阵的角度,texture_property表示需要提取的纹理特征,glcm表示灰度共生矩阵。 For i=1 to imgLength: For j=1 to imgWidth: If i<3 or j<3: continue # 使用7×7的窗口大小计算灰度共生矩阵 GLCM_window=img[i-3:i+4,i-3,j+4] # 计算灰度共生矩阵 glcm= greycomatrix(glcm_window, greycomatrix_diatance,greycomatrix_angles,GLCM_GrayLevel) # 计算纹理特征1 texture_property_1= greycoprops(glcm,texture_property[0]) texture_1[i,j]=texture_property_1[0][0] # 计算纹理特征2 texture_property_2= greycoprops(glcm,texture_property[1]) texture_2[i,j] = texture_property_2[0][0] # 计算纹理特征3 texture_property_3= greycoprops(glcm, texture_property[2]) texture_3[i,j]=texture_property_3[0][0] Step5计算并保存每个数据样本的模糊隶属度: (19) 其中,两类样本之间的最远距离用动态规划法求解,N表示负类样本数,M表示正类样本数,Dn(i,j)表示负样本i到正样本j的距离,Dp(i,j)表示正样本i到负样本j的距离,伪代码如下: For i=1 to N: FarthestDistance[i]=0 For j=1 to M: FarthestDistance[j]=0 For i=1 to N: For j=1 to M: If Dn(i,j)+Dp(i,j)>FarthestDistance[i][j]: FarthestDistance[i][j]=Dn(i,j)+Dp(i,j) If Dn(i,j)+Dp(j,i)>FarthestDistance[i][j]: FarthestDistance[i][j]=Dn(i,j)+Dp(j,i) Step6选择并初始化核函数、惩罚系数C、模糊距离系数λ和μ等。 Step7根据Step 1-Step 6建立模糊支持向量机模型。 (20) 0≤αj≤mjC,j=1,2,…,n Step8选择评价指标对验证集定律评价。 Step9若Step 8的评价结果不满足精度要求或算法迭代数小于迭代次数MaxG,则返回Step 6,否则执行Step 10。 Step10保存算法模型,输入测试集并输出预测结果,算法结束。 实验采用的硬件设备是Intel Core 4.2 GHz i7- 7700k CPU以及NVIDIA Geforce GTX 1080Ti GPU,软件环境采用Python 3.5,所用图像处理软件包括scikit-image,SimpleITK、以及神经影响处理工具NiBabel。此外,还用到机器学习处理软件包scikit-learn(sklearn)。 本文所用实验数据来自brainweb[15],其包含了多个数据的人工分割结果。磁共振图像中纵向弛豫时间T1是指成像扫描仪射频脉冲发射后,核自旋磁化强度受到激发时,从高能状态恢复到原始稳定状态的快慢程度[16]。T1值也是磁共振成像中软组织对比的重要来源,针对不同组织的成像,T1映射图可以作为反映组织生理健康程度的参考,故计算T1映射图对于临床诊断、疾病治疗都至关重要。 本文根据T1值生成图像标签。在成像序列中,重复时间TR、回波时间TE、反转时间(Inversion Time,TI)以及发射角(Flip Angle,FA)影响图像对比度。根据成像对比度质量和实际操作经验设置SE序列以及FLASH序列的成像参数。此外,层面厚度ST由梯度强度和脉冲带宽决定,在2D图像中,ST越小则空间分辨率越高,但图像信噪比也随之下降,本文结合磁共振相关原理和常用层面厚度来设置层面厚度ST。磁共振图像序列采用自旋回波-反转恢复(Spin-Echo Inversion Recovery,SE-IR)序列,序列翻转时间(Inversion Time,TI)分别为800、1 200、1 600、2 200采集得到,如图3所示。图3成像参数为:重复时间(Repetition Time,TR)/回波时间(Echo Time,TE)为2 500/14,层面厚度(Slice Thickness,ST)为3 mm。 (a) TI=800(b) TI=1 200 (c) TI=1 600 (d) TI=2 200图3 不同TI的T1加权图像序列 待分割脑图像如图4所示,实验中采用了两个脉冲序列:SE序列和小角度快速激发梯度回波(Fast Imaging using Low Angle Shot,FLASH)序列。图像的噪声水平为3%和20%,灰度不均匀性(Intensity Non-uniformity,INU)为20%和40%。其中SE成像参数:TR/TE为1 500/13,ST为3 mm。FLASH成像参数:TR/TE为25/13,发射角(Flip Angle)为15°。 (a) SE图像,从左至右噪声比例和灰度不均匀程度 依次为:3%、20%,3%、40%,20%,20% (a) FLASH图像,从左至右噪声比例和灰度不均匀程度 依次为:3%、20%,3%、40%,20%,20%图4 部分实验图像 本文将T1映射图作为磁共振图像数据的参考标签。首先计算MR扫描部位的T1值,通过设置脉冲序列中特定的成像参数,扫描得到不同参数MR图像序列,再根据Bloch方程设计T1的计算方法[17]。最后,通过非线性最小二乘法,拟合得到每个像素点的T1值。本文中,采用经典的自旋回波反转恢复序列,通过采集不同反转时间的T1加权图像,然后运用计算T1值: (21) 式中:a、b是待定复数形式参数,通过拟合得到;TI是反转时间(Inversion Time),是采用自旋回波反转恢复序列进行扫描时需要设置的参数;n=1,2,…是序列图像的序号;S表示采集的MR图像上的某个像素值。 为了从T1映射图上得到训练分割模型所需要的标签信息,需要对T1映射图做一些预处理。图5为原始T1映射图的直方图,可以看出,每种脑组织像素值在直方图上表现为一个数值范围(其中0表示背景),对其取三个阈值再经过形态学滤波去除图像空洞及毛刺得到模糊标签。由于模糊标签中存在一些噪声标签,影响后续脑组织分割,在本文中,采用Northcutt等[18]提出的标签去噪方法去除噪声标签,最终得到的模糊标签为分割脑组织的图像标签。 图5 原始T1映射图的灰度直方图 图6 原始T1 映射图 图7 经过预处理后的T1映射图 采用的分割评价指标包括分类准确率(Classification Accuracy,CA)、召回率(Recall)、Dice系数(Dice Index,DI)。三者计算公式如下: (22) (23) (24) 式中:a表示正确分类样本数;b为错误分类样本数;TP表示分类器将正类划分为正类的样本数;FP表示分类器将负类划分为正类的样本数;FN表示分类器将正类划分为负类的样本数。 本文评估了不同组合的图像特征以及模型参数(模糊支持向量机惩罚系数C、高斯核函数宽度、模糊距离系数μ和λ)对SE图像中三种脑组织分割结果的影响,采用的图像为3%noise、20% INU。模糊距离参数λ和μ对分类精度的影响见表1,惩罚系数C和核函数宽度σ对分类精度的影响见表2,不同特征组合对分类精度的影响见表3。 表1 模糊距离参数λ和μ对分类精度的影响 表2 惩罚系数C和核函数宽度σ对分类精度的影响 续表2 表3 不同特征组合对分类精度的影响 特征组合1:灰度共生矩阵窗口大小为5×5,像素距离1 mm,像素角度45度,梯度,对比度(contrast),相关性(correlation),ASM能量(Angular Second Moment,ASM),逆差矩(Inverse Different Moment,IDM)。 特征组合2:灰度共生矩阵窗口大小为5×5,像素距离3 mm,像素角度90度,梯度,相关性(correlation),ASM能量(Angular Second Moment,ASM)。 特征组合3:灰度共生矩阵窗口大小为5×5,像素距离3 mm,像素角度45度,梯度,逆差矩(Inverse Different Moment,IDM),ASM能量(Angular Second Moment,ASM)。 特征组合4:灰度共生矩阵窗口大小为7×7,像素距离3 mm,像素角度90度,梯度,对比度(contrast),相关性(correlation),ASM能量(Angular Second Moment,ASM)。 特征组合5:灰度共生矩阵窗口大小为7×7,像素距离3 mm,像素角度90度,像素角度45度,梯度,对比度(contrast),相关性(correlation),ASM能量(Angular Second Moment,ASM),逆差矩(Inverse Different Moment,IDM)。 特征组合6:灰度共生矩阵窗口大小为7×7,像素距离3 mm,像素角度90度,像素角度45度,对比度(contrast),相关性(correlation),ASM能量(Angular Second Moment,ASM),逆差矩(Inverse Different Moment,IDM)。 本文基于灰度共生矩阵(Gray Level Co-occurrence Matrix,GLCM)提取脑组织特征。GLCM是一种在特定空间和方向提取像素间相关性的纹理描述方法,由于图像像素值分布导致图像空间像素出现一定的排列规律,故图像中间隔一定距离的像素之间存在可提取的纹理特征。基于表1-表3给出的不同模型参数对分类精度的影响,并结合脑部图像呈现细小的纹理性质,本文基于GLCM,用7×7的滑动窗口,像素距离1 mm和3 mm,像素角度45度和90度提取了脑图像的纹理特征,其统计量分别为:对比度(contrast),相关性(correlation),逆差矩(Inverse Different Moment,IDM),ASM能量(Angular Second Moment,ASM),共提取纹理特征总计16个,此外,还提取了梯度值等特征10个。 本文所用脑图像均重采样为60×180×180大小,为了增加图像数量,还使用了旋转、中心裁剪等数据增强技术,得到扩充后图像8 000幅,其中,5 000幅用于模型训练,1 000幅用于模型验证,2 000幅用于模型测试。模糊支持向量机中,惩罚系数C=1 000,高斯核函数宽度σ=1,模糊距离系数λ、μ分别取0.6、0.4。本文分别在SE图像和FLASH图像,不同噪声比例和灰度不均匀程度上进行了实验,分割结果如图8所示。 (a) 标准图像(Ground Truth)及其标准分割结果 (b) SE图像及脑组织分割结果(脑脊液,脑灰质,脑白质) (c) FLASH图像及脑组织分割结果(脑脊液,脑灰质,脑白质)图8 各脑组织分割结果 可以看出,在SE图像上,噪声3%,灰度不均匀40%的图像的脑白质分割效果最好,也最接近标准图像的分割结果。本文方法能较好地判别孤立像素点,分割结果空洞情况较少,能对不同序列图像做出准确分割。 从表4中可以看出,对于SE图像,以CA为评价指标时,本文方法对噪声3%的图像实现了精确分割。结合表4和表5,SE图像的分割结果稍好于FLASH图像,在噪声20%、灰度不均匀20%图像上,两者相差较多。在SE图像上,本文方法平均CA为87%,平均召回率为0.81,平均DI系数为0.82。 表4 SE图像分割评价 表5 FLASH图像分割评价 上述实验结果表明,本文方法对于不同序列的脑图像具有较好的分割准确率和泛化性能。此外,本文还给出了三种脑组织在三种评价指标下的分割精度,如表6-表8所示。 表6 脑脊液分割评价 表7 脑白质分割评价 表8 脑灰质分割评价 可以看出,脑白质的分割精度最高,对脑白质的分割误判也最少,其次是脑脊液,最后是脑灰质。三组图像中脑白质的平均分割准确率达到90.33%,脑脊液平均分割准确率为83%,脑灰质平均分割准确率为83%。在实验样本图像中,脑白质的组织边缘较清晰,基于灰度共生矩阵提取脑组织的纹理特性时,脑白质的纹理可以较好地提取出来。 此外,为了说明本文分割方法在脑组织分割上的有效性与准确性,本文方法与目前主流的脑组织分割方法随机森林(Random Forest)方法、模糊C均值方法(Fuzzy C means)、Snake形变模型进行分析比较,结果如表9和图9所示。 表9 本文方法与其他三种方法分割性能比较 表9中,对于噪声3%、灰度不均匀20%的图像,本文方法DI系数为0.90,高于其他三种方法中最高的Snake形变模型0.89的DI系数,相对于随机森林分割算法0.85的DI系数高出5.9%。对于低噪声比例和低灰度不均匀程度的图像来说,本文方法和模糊C均值所取得的分割精度接近。对于灰度不均匀为40%的图像,本文方法DI系数为0.87,而随机森林算法所取得的DI系数为0.83。对于噪声20%的图像,相比于其他算法,本文方法的DI系数明显提升,和随机森林比较,本文方法DI提升10.4%,相对于Snake形变模型和模糊C均值分别提升4.2%、7.2%。图9表明,本文方法相对于其他三种方法在两种不同的Noise比例和INU的图像上的分割精度均有所提升。 针对医学图像组织边缘不清晰以及灰度不均匀问题,本文提出了一种基于类间模糊距离的隶属度函数计算方法,样本隶属度的确定不仅取决于同类样本之间的空间距离,还取决于不同类样本之间的空间距离,以解决样本标签交叉重叠的问题。此外,针对医学图像人工标注的困难,本文提出了基于T1映射图的模糊标签获取方法,减少人工标注图像的困难。三种主要脑组织分割实验表明,本文方法可准确有效地分割脑部图像,在处理医学图像具有很好应用前景。此外,本文提出的模糊隶属度函数在模糊支持向量机的基础上,可用于分类噪声较多的数据样本。一方面,模糊支持向量机对通过样本重新调整权重的方式增加了对噪声样本的鲁棒性;另一方面,基于本文提出的模糊隶属度函数在综合考虑类内距离和类间距离的基础上,重新计算样本的模糊隶属度,进一步提升了算法模型对噪声样本的鲁棒性。2 模糊隶属度函数设计




3 整体算法流程

4 实 验
4.1 实验数据



4.2 标签图像获取
4.3 标签图像处理

4.4 模型评价指标
4.5 脑图像分割实验











5 结 语
猜你喜欢
中国中医药信息杂志(2022年6期)2022-06-27
包装工程(2022年9期)2022-05-13
新高考·高一数学(2022年3期)2022-04-28
集装箱化(2021年1期)2021-04-12
中国信息技术教育(2020年2期)2020-02-02
中国医药导报(2017年11期)2017-06-01
高中生学习·高三版(2016年9期)2016-05-14
中国民族民间医药·下半月(2015年12期)2016-02-25
新高考·高二数学(2015年11期)2015-12-23
江苏农业科学(2014年8期)2014-10-23
