
基于自适应稀疏监督典型相关分析的特征选择
2022-06-24 10:02王凯明鲁伊莎肖玉柱宋学力
计算机应用与软件 2022年4期
王凯明 鲁伊莎 肖玉柱 宋学力
(长安大学理学院 陕西 西安 710064)
0 引 言
随着智能传感器技术和数据存储技术的不断进步,高维数据的生成数量和速度呈指数爆发式的增长。在数据驱动建模问题中,这些高维数据不仅会消耗更多的计算时间,占用更多的存储资源,甚至会降低模型学习的性能,而且还会引发后续建模任务的过拟合现象甚至“维数灾难”[1]。为了解决这些问题,同时提升数据的可解释性,需要从高维数据中按照某种数据挖掘方法或者统计规则选择使特定模型目标达到最优且维度较低的特征子集,这就是特征选择问题[2-5]。
稀疏典型相关分析[6-7](Sparse Canonical Correlation Analysis, SCCA)是一种多元统计方法,其目标是求得一对稀疏的基向量,使得两模态数据集在这对基向量上的投影之间相关性最大。然而在一些实际应用领域中,随着信息采集技术的发展,在得到某些样本数据集的同时,也易获得样本的某种监督数据或可以看作监督数据的数据。但传统的SCCA模型是无监督的,不能充分利用这些数据的监督信息,造成信息损失。现有的大多数有监督特征选择方法一般应用类标签作为监督数据,如Witten等[6]通过引入类标签提出了一种基于类标签的稀疏监督的典型相关分析模型。事实上,除了类标签,还有其他类型的监督数据,如样本的某种量化结果数据(即样本某个指标的定量结果),它也可作为样本的监督数据。与类标签监督数据相比,样本的某种量化结果数据的引入有利于模型选择出与量化结果相关的特征子集。基于此,Witten等[6]通过引入样本某量化结果的数据作为监督数据提出了稀疏监督的典型相关分析(Sparse supervised Canonical Correlation Analysis, Sparse sCCA)模型。该模型利用了样本量化结果的数据,但是在求解优化问题的过程中为了提高计算效率,克服高维矩阵可能不可逆等缺陷,用对角矩阵甚至是单位矩阵替代目标函数中典型变量方差的约束条件,使模型的目标从相关系数组合简化为协方差组合,然而两两典型变量的相关系数由于方差的差异可能导致目标协方差在尺度上相差很大。当某对典型变量的协方差较大时,其相关性可能会被过度加权。同时,值得注意的是,这样的Sparse sCCA模型是通过求解一个约束优化问题实现的。众所周知,待定参数问题是约束优化问题中的公开难题,而k折交叉验证方法是确定待定参数现有的常用方法。如果Sparse sCCA模型的最优参数是通过k折交叉验证方法确定的,这种过度加权将表现得更明显。因为k折交叉验证倾向于分配更大的权重给协方差较大的典型相关变量对,所以当典型变量两两高度相关而协方差较小时,数据的特征选择结果将产生较大的偏差。究其本质原因,这种协方差尺度的差异是由多模态数据的异质性构成的,而且数据集的异质性越大,利用Sparse sCCA模型进行特征选择时所得结果的偏差越严重。因此,如何减少甚至是消除这种偏差,以较大相关性实现更优的特征选择具有重要的现实意义。为实现这种更优意义下的特征选择,如何解决优化问题的求解难度和待定参数的不平衡性,是改进Sparse sCCA模型需要解决的关键问题。文献[8]采用动态权重方法来提高最小二乘算法的性能,文献[9]提出了三模态数据的自适应稀疏典型相关分析模型,受此启发,本文在Sparse sCCA模型的基础上,采用自适应动态加权优化,建立自适应稀疏监督典型相关分析模型,以实现特征选择。
本文主要的研究思路包括有:① 引入一组新的自适应动态权重系数,提出基于自适应稀疏监督典型相关分析的特征选择模型;② 从应用的角度而言,本文模型能在最大相关性目标下更准确地选择出与样本某种指标相关的特征子集,所以适用于具有量化结果指标的样本数据集,同时对特征查准要求较高的实际问题,如某些肿瘤疾病的特征选择问题。
1 方 法
1.1 稀疏监督的典型相关分析
设X∈Rn×p、Y∈Rn×q为同一样本的两模态标准化数据集,z∈Rn×1为样本某种量化结果,可作为监督数据,n为样本容量,p、q为样本的特征维数。稀疏监督典型相关分析模型如下:
(1)
s.t.uTXTXu≤1,vTYTYv≤1,P1(u)≤c1,P2(v)≤c2
式中:P1(u)和P2(v)是凸的惩罚函数(如l1惩罚);c1和c2是控制典型向量u=(u1,u2,…,up)T∈Rp和v=(v1,v2,…,vq)T∈Rq稀疏程度的可调参数。该模型旨在寻找稀疏的典型向量对(u,v),使数据的典型相关变量(Xu,Yv)具有最大的相关性。
在求解式(1)时,一般需要求解矩阵XTX,YTY的逆,然而在高维数据集中,XTX,YTY常常是奇异的。为了避免这一问题,一般把约束条件uTXTXu≤1、vTYTYv≤1简化为uTu≤1、vTv≤1[10],这时目标函数由最大相关系数组合牺牲为最大的协方差组合。对于两模态的数据集,这样处理也能产生一个相对较好的结果,并且减少了计算量,通常认为这种牺牲是可以被接受的。但是稀疏监督典型相关分析模型中引进了样本某种量化结果的监督数据,原有的协方差改进为两模态数据与监督数据的两两协方差组合,这样的处理将造成特征选择的严重偏差。
为了说明典型向量对典型变量的相关系数与协方差比值的影响程度,我们以一组经过标准化的样本数据集X∈Rn×p、Y∈Rn×q和样本的某种量化结果的监督数据z∈Rn×1(标准化处理)为例,比较它们的相关系数与协方差比值。为体现一般性,任意给出10组不同的单位典型向量(u,v),以此得到变量对(Xu,Yv)、(Xu,z)、(Yv,z)在10组(u,v)下的相关系数与协方差比值情况(如图1所示)。

图1 相关系数与协方差比值对比图
图1中,三对典型变量(Xu,Yv)、(Xu,z)、(Yv,z)的相关系数与协方差比值在每组典型向量对(u,v)下差异很大。其中(Xu,Yv)的比值接近1,表明对于两模态数据集,SCCA模型中以协方差代替相关系数作为优化目标具有一定的合理性。然而(Xu,z)、(Yv,z)比值与(Xu,Yv)的比值差异较大,这种差异的大小说明了用最大协方差代替最大相关系数时,协方差对的固定权重会导致相关性占比的分配不公平现象,且这种不公平的严重程度依赖于典型变量的相关系数与协方差比值。另一方面,值得注意的是,典型向量对典型变量的相关系数与协方差的比值影响是随机的,不可预测的。在实际应用中,噪声的大小,数据服从的分布以及数据采集设备的精确度等都有可能影响典型变量相关系数与协方差的比值。因此,固定权重的Sparse sCCA模型不能解决该不平衡性问题,需要在传统的Sparse sCCA模型中引入可以减弱这种偏差带来的不平衡性的自适应权重,动态调节各对典型变量协方差使其达到最优占比。
1.2 ASSCCA模型
本节在Sparse sCCA模型中引入一组自适应权重系数,使其动态调整每对典型变量的“最大协方差”,直至目标函数无限逼近最大的相关系数,建立新特征选择模型如下:
(2)
s.t. ‖u‖2=1,‖v‖2=1,‖u‖1≤c1,‖v‖1≤c2

该模型旨在减少由协方差组合代替相关系数组合所产生的偏差来提高特征选择的准确率。以下称之为自适应稀疏监督典型相关分析(Adaptive Sparse Supervised Canonical Correlation Analysis, ASSCCA)模型。
1.3 ASSCCA模型的求解
为求解方便,将式(2)的约束优化问题等价转化为:
λu‖u‖1+λv‖v‖1
(3)
s.t. ‖u‖2=1,‖v‖2=1
式中:λu和λv为大于零的数,分别控制u和v的稀疏程度。
为求解式(3)中的典型向量u、v,使用软阈值方法。根据文献[11],引入如下引理。
引理1考虑以下优化问题:
(4)

S(a,Δ)=sgn(a)(|a|-Δ)+=
sgn(a)max(|a|-Δ,0)=

(5)
采用块坐标下降法[12],结合引理1,式(3)的求解迭代过程如下:
(1) 固定v,解u。
(6)
(7) (2) 固定u,解v。
(8)
(9)
根据模型的求解过程,ASSCCA算法流程如算法1所示。
算法1ASSCCA算法
输入: 标准化之后的数据X∈Rn×p,Y∈Rn×q,z∈Rn×1,可调参数λ1,λ2
输出: 典型变量u和v
(1) 初始值t=0,ut∈Rp×1,vt∈Rq×1;
(2)While(算法终止条件不满足)do

(4) 固定vt,解ut+1;
(5)ut+1←argmaxut+1Γ12XTYvt+Γ13XTz满足‖ut+1‖2≤1,P1(ut+1)≤λu;
(6) 固定ut+1,解vt+1;
(7)vt+1←argmaxvt+1Γ12YTXut+1+Γ23YTz满足‖vt+1‖2≤1,P2(vt+1)≤λv;
(8)t=t+1;
(9) end while
(10) 返回典型变量u和v的值
整个算法的关键是如何求解典型向量u和v,对应的关键步骤是式(7)和式(9)。此处由ASSCCA算法的步骤(4)、步骤(5)可知,首先固定v来求解u,再用得到的u来求解v(步骤(6)、步骤(7)),反复迭代直到算法收敛。使算法终止的条件为:
(10)
经过多次实验,此处设置ξ=10-5最为合适。
2 仿真实验
为了验证本文模型算法的可实现性,以及引入自适应权重系数能否有效地提高特征选择的准确率,本节使用一组模拟数据,针对不同的参数进行多次实验,并将实验结果与Sparse sCCA模型进行对比。
2.1 仿真数据的产生
数值仿真中X(n×p)和Y(n×q)是来自共同的n个样本的不同模态的数据,z(n×1)为样本对应的某种量化结果的监督数据,其中n=200是样本个数,p和q分别为X和Y数据的特征维数。参考文献[14]中潜变量被用于模拟数据集之间相关性的构造方法,模拟数据生成过程如下:① 生成两个服从高斯分布的独立的潜变量μ1∈R200×1和μ2∈R200×1。② 通过潜变量μ1和μ2、稀疏向量αi∈R1×500,i=1,2,3,4,使X的前200个特征与Y的前200个特征典型相关,而通过潜变量μ1,使X和Y仅有前100个特征与样本的某种量化结果z典型相关,第101至200个特征与样本的某种量化结果z不存在典型相关关系。同时为了检验模型的鲁棒性,将高斯噪声E1、E2、e分别引入到X、Y和z数据集中,产生的模拟数据如下:
X=μ1α1+μ2α2+E1
Y=μ1α3+μ2α4+E2
z=μ1+e
式中:每一个向量αi(i=1,2,3,4)有100个非零项,且αi非零项~U(0.4,0.6),其中α1和α3的非零项位于前100项,α2和α4的非零项位于第101到第200项,E1∈R200×500、E2∈R200×500和e∈R200×1分别表示X、Y和z的噪声数据集,且都为高斯噪声。
2.2 参数选择与特征选择
参数的选择与一个优秀的模型和有效的算法同样重要。本文有Λ12、Λ13、Λ23、λ1、λ2共五个参数,其中Λ12、Λ13、Λ23对应的值随着典型变量u和v的变化而变化,所以设置一组u和v的初值,相应Λ12、Λ13、Λ23的初值也随之确定,并且随着算法的迭代其值也更新,因此本文只剩参数λ1和λ2需要调整。徐宗本等[15]指出可参考解的稀疏程度进行参数选择,所以根据需要保留的特征数量指导参数λ1、λ2的选取,避免了盲目选择参数的缺陷。实验采用5折交叉验证方法来产生所有的最优参数。将所有的样本随机平均分为5份,选择每一份样本轮流作为测试集,剩余4份作为训练集,用训练集拟合模型,用测试集来验证模型的偏差,循环5次,直到5份数据全被依次选择作为测试集为止。在此过程中对每一组给定的参数进行k(k=5)次实验,并且在ASSCCA模型达到最大值的情况下,选择使式(11)取得最小值时的一组参数作为最优参数。
(11)
式中:corr表示Pearson相关系数;corrtrain表示训练集上的典型相关系数;corrtest表示测试集上的典型相关系数。
在确定稀疏参数后,使用稳定性选择方法[16]来选择稳定的特征子集。对整个样本集重复执行bootstrapping(重采样方法)200次,从而生成200个新的样本集。然后在每个新样本集上执行ASSCCA,并获得200个不同的典型向量。根据这200个典型向量中候选特征子集出现的频率高低来使用频率截断,选择频率高的特征子集作为最终的最优子集。
2.3 结果分析
本文用模拟数据集进行多次实验,选择了一组最优的特征子集,并从特征选择的准确性和所求典型相关系数的大小两个指标来对比本文模型与Sparse sCCA模型的性能。
(1) 模拟数据特征选择的可视化对比如图2-图7所示,每幅图的横轴代表数据集的特征索引,纵轴代表u和v的值,即特征的权值系数,权值越大,表示该特征越重要。图2和图5分别给出了仿真生成的典型向量u和v的真实值。图3和图6分别给出了sparse sCCA特征选择模型得到的u和v,图4和图7分别给出了ASSCCA特征选择模型得到的u和v。

图2 典型向量u的真实值
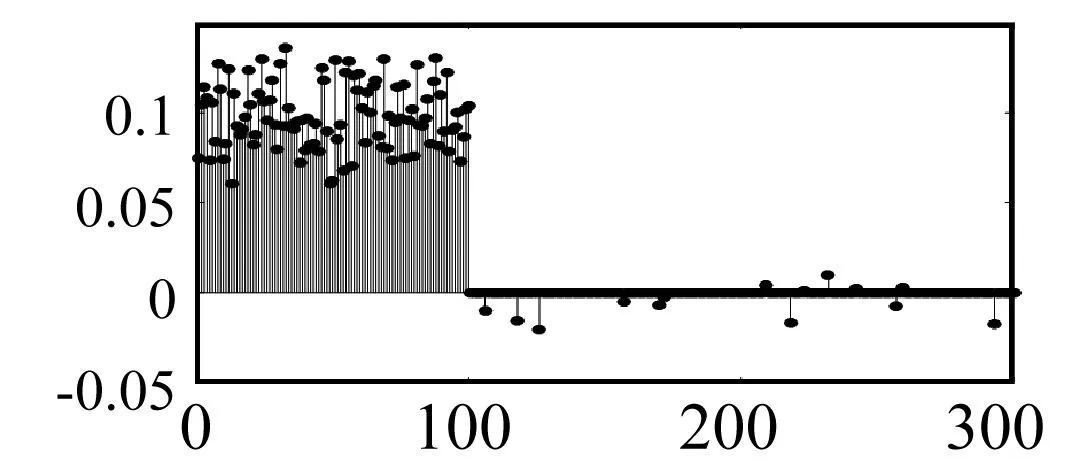
图3 sparse sCCA模型u的估计值

图4 ASSCCA模型u的估计值

图5 典型向量v的真实值

图6 Sparse sCCA模型v的估计值

图7 ASSCCA模型v的估计值
从图3、图4与图2的对比中可以清晰地看到固定权重系数的Sparse sCCA模型所得到的u选择出了与样本某种量化结果数据z相关的前100个特征,但同时也引入了许多冗余特征,造成了样本某种量化结果数据z与数据集X和Y相关性的特征子集选择的偏差;而本文的模型ASSCCA减小了Sparse sCCA模型选择特征子集时引入的偏差,选择出了数据集X和Y特定于某种量化结果数据z的特征子集,所得的u较准确地反映了某种量化结果数据z与数据集X和Y之间相关性的特征子集,特征选择更优,有助于更好地理解和解释与样本某种量化结果数据有关的特征子集所提供的重要信息。对比图6、图7与图5,典型向量v也有类似的实验结果。该仿真实验结果表明自适应权重的引入对于研究样本某一量化结果与数据集相关性的特征选择问题有很大的优势。
(2) 模拟数据的典型变量Xu和Yv真实相关系数和Sparse sCCA与ASSCCA模型对应的目标函数满足最大值时的典型变量Xu和Yv的相关系数(见表2)。

表2 Sparse sCCA和ASSCCA模型相关系数对比
其中rr表示典型相关系数。表2中的数值表示五折交叉验证后的相关系数平均值±标准差。
从表2中可以看出,与模型Sparse sCCA相比,ASSCCA得到的相关系数不仅在训练集上取得最优,而且在测试集中也取得最优,并且相应的标准差更小,即结果更稳定。这说明ASSCCA模型更鲁棒,泛化能力更强(其中粗体的值为最优)。
综合以上与Sparse sCCA模型的对比分析,本文的模型不仅充分利用了样本某种量化结果的监督数据,而且引入了一组新的自适应权重系数,该系数不仅有助于重新调整目标函数协方差对的值,使模型减小了用协方差代替相关系数对特征选择产生的偏差,而且在组合相关系数较大的条件下有效提高了特征选择的准确率。
3 结 语
本文在Sparse sCCA模型的基础上,引入了一组自适应权重系数,提出了一种新的自适应稀疏监督典型相关分析(ASSCCA)的特征选择模型。在模拟数据集上的仿真实验表明,与其他模型相比,本文的ASSCCA模型以较大的组合相关性实现了特征选择,在与监督数据较高的相关性意义下提高了特征选择的准确率。适用于已知某些监督数据信息的肿瘤疾病等的特征选择问题。
在未来的研究中,将考虑构建一种将数据集与其他类型的监督数据进行联合关联、回归等多任务统一的模型,使模型既能揭示数据集之间的关联性又能实现关于某种监督数据的预测。
猜你喜欢
中学生数理化·中考版(2019年11期)2019-09-10
湖南教育·B版(2018年12期)2018-12-24
数学学习与研究(2018年3期)2018-03-14
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
考试周刊(2016年54期)2016-07-18
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
新高考·高一物理(2015年5期)2015-08-18
现代电子技术(2015年10期)2015-05-29
