
基于混沌PSO的大数据智能加权K均值聚类算法
2022-06-24 10:11刘洪基
计算机应用与软件 2022年4期
刘 洪 基
(楚雄师范学院经济与管理学院 云南 楚雄 675000)
0 引 言
当前,工业过程、移动互联网、社交网络和物联网生成大量数据,并推动大数据应用的快速发展[1-2]。在各种大数据应用中,都有许多高维多视图数据,高维多视图数据通常以各种来源获得的多个特征空间和不同结构进行描述[3]。传统聚类方法将所有视图作为一个统一的变量集,对此类具有数量、种类、速度、准确性和价值等多视图的数据聚类效果较差[4]。在大数据环境下,如何实现高维多视图数据的聚类以适应各种复杂的、大规模的应用是最具挑战性的问题之一[5]。
由于大数据的广泛应用,多视图数据的聚类吸引了许多研究人员的关注。文献[6]将多视图任务的非监督特征选择保留在集群结构中,然后提出一种交替算法来实现该结构。对于多视图聚类问题,文献[7]提出了一种新颖的多视图关联传播算法,该算法特别适合于对两个以上的视图进行聚类。文献[8]提出了局部自适应聚类(Local Adaptive Clustering,LAC)算法,该算法为每个聚类的每个特征分配权重,通过使用迭代算法最小化其目标函数。文献[9]提出了一种多视图数据的自动两级变量加权K均值(Two-variables Weighted K-means,TWKM)聚类算法,该算法可以同时计算视图和单个变量的权重,但是很容易导致在单个特征和单个视图上具有较大权重的聚类,因此权重的分布不平衡。然而,上述算法主要关注于具有视图方式关系的问题,而忽略了数据集高维特征的重要性,使得聚类结果与实际应用存在较大差异,此外,上述方法由于聚类性能的限制对大数据应用中更复杂的高维数据的聚类效果较差。
为了解决实际大数据应用中的高维多视图数据聚类问题,并且进一步提升该聚类算法的聚类性能,提出一种基于混沌粒子群优化算法(Chaos Particle Swarm Optimization,CPSO)的智能加权K均值(Intelligent Weighted K-means,IWKM)聚类算法。
1 相关理论
1.1 加权K均值聚类算法
集群是数据对象的集合,这些数据对象在同一集群中彼此相似,但与其他集群中的对象不同[10]。给定数据对象集X=[xi,j]N×D,N是数据对象的数量,D是数据对象的维度。也就是说,数据对象具有D个特征。聚类问题试图找到X的k分区。簇的中心是Z=[zk,j]C×D。U=[ui,k]N×C,主要通过模糊划分矩阵描述对象是某些集群的隶属度[9]。
作为具有敏感初始聚类中心的聚类算法,K均值被广泛用于实际应用中,例如图像分割和数据挖掘[11-12]。K均值的目标是找到一个分区,以最小化带簇的平方和。在聚类过程中,用以下式子解决样本划分任务:
(1)
式中:U被定义为分区矩阵;ui,k是一个二进制变量;Z={Z1,Z2,…,Zk}是一组向量,表示k个簇的质心;(xi,j-zk,j)2是第i个对象与第j个变量上的第k个簇的中心之间的距离度量。
在经典的K均值聚类算法中,所有特征均具有相同的权重,在诸如消费者细分之类的聚类问题中,所有特征均得到同等对待。实际上,在许多实际应用中,数据集中不同特征对聚类的影响是不同的,因此有必要为不同特征分配不同的权重。K均值类型聚类中的自动变量加权是加权K均值聚类算法,目标函数为:
(2)
式中:U被定义为n×k分区矩阵;WF是特征的权重;β表示权重函数维度。
1.2 软子空间聚类算法
软子空间聚类算法根据维度在发现相应聚类中的作用来确定维度的子集。维度的贡献是通过在聚类过程中分配给维度的权重来衡量的。文献[13]提出了一种软子空间聚类算法,目标函数的建模为:
(3)
式中:WCF=wcfk,j是每个集群中每个属性的权重。
2 IWKM算法
2.1 高维多视图数据的聚类
用于将X划分为具有视图和特征权重的集群的聚类建模为以下目标函数的最小化。
minFitness(U,Z,WV,WF)=
(4)
式中:U=[ui,k]N×C是一个N×C分区矩阵,其元素ui,k为二进制,其中ui,k=1表示对象i已分配给集群k;Z=[zk,j]C×D是一个N×C矩阵,其元素zk,j表示簇k的第j个特征;WV=[wvt]T是T视图的权重;WF=[wfj]j∈Viewt是视图t下的特征权重;wvtwfj(xi,j-zk,j)2是第i个对象与第k个簇的中心之间的第j个特征的加权距离度量;wvtwfj(zk,j-oj)2是第k个聚类与平均聚类中心之间的第j个特征的加权距离度量,oj是C个聚类的平均聚类中心。该值描述集群之间的耦合程度,越大表示相异性越大。
2.2 CPSO和粒子编码

(5)
(6)

ω=ωmax-(ωmax-ωmin)×g/gmax
(7)

粒子编码是使用粒子群搜索最佳解的前提[14]。在IWKM中,初始聚类中心、视图权重和特征权重被编码为粒子表示形式。每个粒子由F×C+T+F维实数向量编码。F是聚类问题中对象的特征数。群中的第i个粒子被编码为:
(8)
2.3 精确扰动和CPSO
为了避免局部最优和过早收敛,利用跳跃或突变在丰富群体智能中粒子的搜索行为方面具有很大的优势[15]。在CPSO中,混沌逻辑序列扰动被用于帮助粒子脱离局部最优并获得更好的搜索质量,具有确定性、遍历性和随机性,将其定义为式(9)。
x(t+1)=r·x(t)·(1-x(t))
r∈N,x(0)∈[0,1]
(9)
式中:r是控制参数,x是变量,r=4,t=0,1,2,…。
本文将CPSO的精确扰动概括为以下过程的相互作用。
步骤1创建合适的扰动粒子:为了减少粒子搜索过程中总体稳定性的损失和CPU的计算代价,通过简单的随机抽样方法从总共N_S个粒子中随机选择N_S/K_spark个粒子作为扰动对象。K_spark是Apache Spark中的工作程序节点数。
步骤2精确扰动时间:扰动的时间是粒子群过早收敛的时间。pBest和gBest之间的平均距离用于判断粒子是否处于过早收敛状态,记为式(10)。
(10)
式中:N_S和dim是群的粒子数和粒子的维度;Q_d代表过早收敛的阈值;如果d(pBest,gBest)≤Q_d,则出现过早收敛和局部最优,然后应采用适合N_S/K_spark粒子的扰动。
步骤3精确扰动维度:由于粒子具有一个以上的维,因此根据惯性的优先级,优先选择一些具有较高惯性的维来进行扰动。第j维中的pBest和gBest的惯性可以由均方差给出,分别记为式(11)和式(12)。

Q_pBest
(11)
Q_gBest
(12)
式中:N_S和m是群的粒子数和当前迭代数。如果sd(pBestj)≤Q_pBest或sd(gBestj)≤Q_gBest,则第j维的pBest、gBest是惰性的,需要进行扰动。其中Q_pBest和Q_gBest分别是pBest和gBest的惰性阈值。
2.4 IWKM流程
IWKM算法的流程如图1所示。
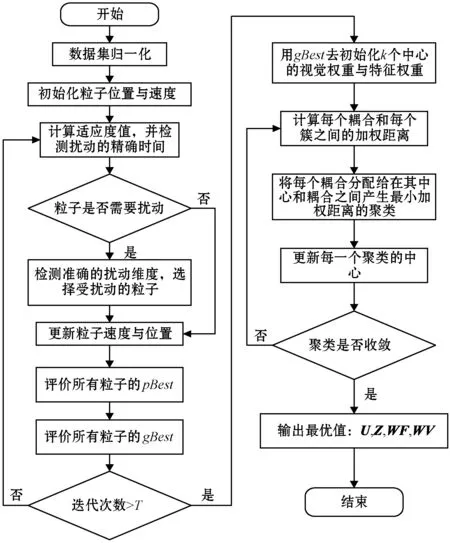
图1 IWKM算法流程
3 实验评估
3.1 测试环境和spark
在分布式和并行计算环境中,Apache Spark是一个重要的开源集群计算框架,它为隐式数据并行和容错的整个集群编程提供了一个接口[16]。Spark的弹性分布式数据集(RDD)是分布式程序的工作集,可以提供受限形式的分布式共享内存。因此,本文选择了Apache Spark作为大数据应用中IWKM的计算平台。在本文实验中,对IWKM进行了测试,并在包括Apache Spark和Single Node在内的各种计算环境中进行了比较。Single Node配备了Intel Core i5- 4210M 2.6 Hz,3.8 GB RAM和Ubuntu 14.04LTS操作系统。
Apache Spark有一个主节点,配置为Intel Core i7- 3820@3.6 GHz,64 GB DDRIII和1 TB高效云磁盘,十个工作节点,相关配置为Intel Xeon E5- 2690@2.9 GHz,16 GB DDRIII和500 GB高效云磁盘,应用版本为Apache Spark 1.6.0。
3.2 测试数据集
为了评估本文算法的性能,还通过RI(Rand Index)、JC(Jaccard coefficient)和Folk的评估指标,将IWKM与LAC、亲和传播(Affinity Propagation,AP)[17]、归一化分割(Normalized Cut,Ncut)[11]、密度聚类(Density Clustering,DC)[18]和TWKM进行了比较。为了公平比较,PSO和CPSO使用相同的30人口规模和150个适应度值进行评估。IWKM和其他五种算法已在5个高维多视图数据集中进行了测试,其中包括多特征数据集、互联网广告数据集、Spambase数据集、图像分割集和心电图数据集。这些数据集及其应用的基本信息如表1所示。
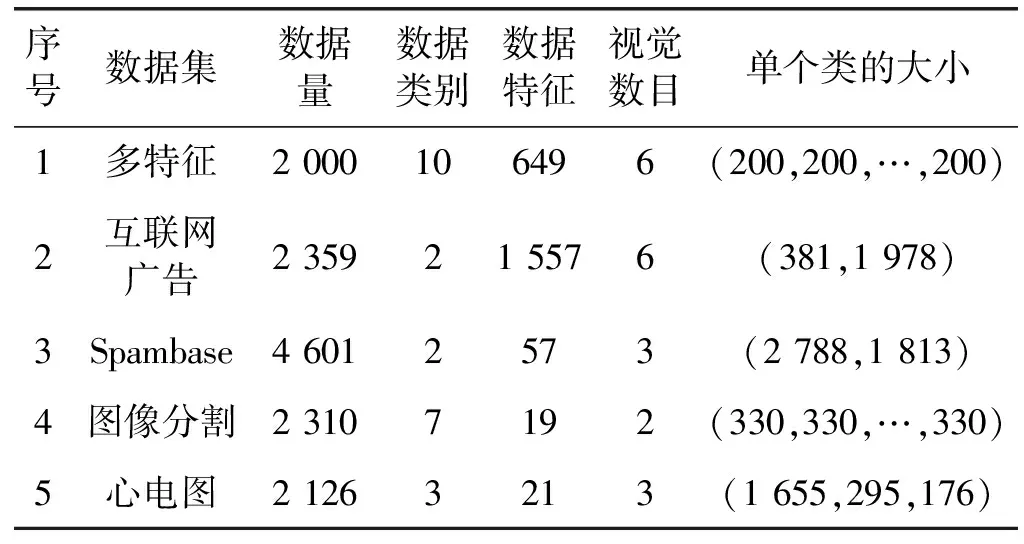
表1 高维多视图数据集的特征
多特征数据集是从荷兰实用程序图的集合中提取的手写数字数据集,其中包含2 000个属于10类(0~9)的数字对象。每类有200个对象。每个对象均由649个特征表示,这些特征分为以下六个视图:1) Mfeat-fou视图包含76个字符形状的傅里叶系数;2) Mfeat-fac视图包含216个配置文件相关性;3) Mfeat-kar视图包含64个Karhunen-Love系数;4) Mfeat-pix视图包含240个像素窗口;5) Mfeat-zer视图包含47个Zernike时刻;6) Mfeat-mor视图包含6个形态特征。
互联网广告数据集包含来自各种网页的3 279幅图像,这些图像被分类为广告或非广告。有20幅图片的值缺失。我们的实验在3 259个实例上进行,删除了缺失值的实例。在六个视图中描述了实例。视图1包含3种图像几何形状(宽度、高度和长宽比);视图2在包含图片的页面网址(基本网址)中包含457个词组;视图3包含495个图像URL的短语(图像URL);视图4在图像所指向的页面的URL中包含472个短语(目标URL);视图5包含111个锚文本;视图6包含19个图像的文本alt(替代)html标签(alt文本)。
Spambase是一个数据集,其垃圾邮件的收集来自邮局主管和具有现场垃圾邮件的个人,非垃圾邮件的收集来自现场工作和个人电子邮件,其中包含4 601个属于2类(垃圾邮件、非垃圾邮件)的对象。每个对象都由57个要素表示,这些要素分为三个视图,分别是单词频率视图、字符频率视图和大写游程视图。1) 单词频率视图包含word类型的48个连续实数属性;2) 字符频率视图包含char类型的6个连续实数属性;3) 大写游程视图包含测量连续大写字母序列长度的3个连续实数属性。
在该数据集中,从7幅室外图像的数据库中随机抽取了2 310个实例。手动分割图像以为每个像素创建一个分类。每个实例都是一个3×3的区域。数据集包含19个特征,可分为2个视图:形状视图包含9个有关形状信息的特征,而RGB视图包含10个有关颜色信息的特征。
自动处理2 126例胎儿心电图(Cardiotocograms,CTG)并测量相应的诊断特征。CTG还由三位专家产科医生进行分类,并为他们每个人分配了共识分类标签。分类既涉及形态学模式(A,B,C,…),也涉及胎儿状态(N,S,P)。因此,该数据集可用于10类或3类实验。在此实验中,将其用作3类数据集。在数据集中,可以将21个要素划分为3个视图:每秒指标、可变性视图和直方图视图。
3.3 评估指标





本文使用的三个外部标准可以定义如下:
(1)RI=(SS+DD)/(SS+SD+DS+DD),RI越大,说明聚类结果与真实情况越吻合。
(2)JC=SS/(SS+SD+DS),该指标用于衡量两个数据的相似度,JC越大,相似度越大,聚类精度越高。

3.4 参数分析
为了分析3个参数(Q_d、Q_gbest和Q_pBest)对高维多视图数据的聚类性能的影响,在Single Node上对3个数据集(Mfeat数据集、互联网广告数据集Spambase数据集)中的IWKM进行了测试。为了减少统计错误,所有数据集均独立进行了10次模拟。
根据过早收敛的阈值评估,将Q_d在Mfeat和Spambase数据集中以5步长设置在[5,45]。将Q_d在互联网广告数据集中以3步长设置在[2,20]。关于它们的平均评价指标的统计结果如图2所示。可以看出,当Q_d分别选择为30、8和25时,IWKM具有在Single Node上的3个数据集中进行聚类的最佳性能。参数Q_gbest和Q_pBest是维度惯性的阈值,用于测量每个维度中位置的可感知变化是否发生。三个数据集上的参数Q_gbest和Q_pBest也与Q_d类似地进行分析。关于它们的平均评价指标的统计结果分别示于图3和图4。由于在Spambase中JC和RI的值几乎相等,因此JC和RI的曲线重叠。根据参数分析的结果,将选择最佳参数值Q_d、Q_gbest和Q_pBest并在下一个实验中进行测试。

(a) 多特征数据集

(b) 互联网广告数据集
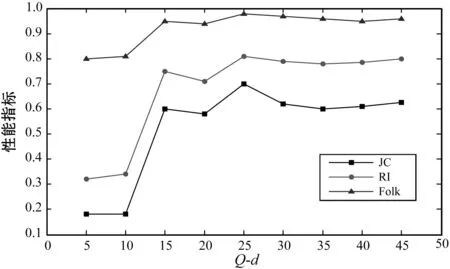
(c) Spambase数据集图2 参数Q_d变化曲线

(a) 多特征数据集

(b) 互联网广告数据集

(c) Spambase数据集图3 参数Q_gbest变化曲线
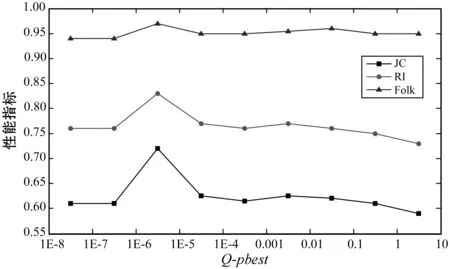
(a) 多特征数据集

(b) 互联网广告数据集

(c) Spambase数据集图4 参数Q_pbest变化曲线
3.5 PSO和CPSO的比较
为了验证CPSO在IWKM中聚类中心、视图权重和特征权重的优化,我们在Single Node上的三个高维多视图数据集中测试了CPSO和PSO。通过CPSO和PSO将数据集运行10次,图5记录并比较了各种算法的平均结果。在CPSO中,提出一种精确的扰动,包括合适的扰动粒子、精确的扰动时间和扰动维数,以提高优化性能。可以看出,CPSO可以在Single Node上的所有三个高维多视图数据集中实现更好的解决方案精度,并尽早获得最佳解决方案。显然,CPSO在IWKM集群方面比PSO具有更好的性能。因此,可以得出结论,作为一种重要的优化方法,CPSO可以帮助IWKM在高维多视图数据中获得更好的初始聚类中心、视图权重和特征权重。
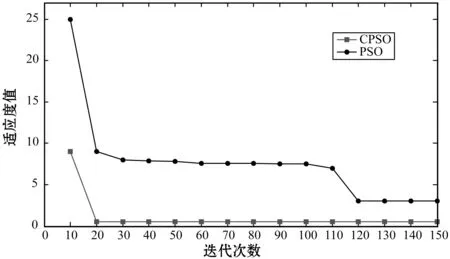
(a) 多特征数据集

(b) 互联网广告数据集

(c) Spambase数据集图5 PSO与CPSO的比较
3.6 IWKM视图权重比较
为了进一步评估获得视图权重的性能,在五个不同的高维多视图数据集中测试了TWKM和IWKM。两个算法在数据集中运行了10次,并记录了IWKM和TWKM的平均结果并在表2中进行了比较。显然,IWKM和TWKM可以为5个高维多视图数据集获得有效权重。特别是在互联网广告和图像分割这两个数据集中,TWKM和IWKM在获得视图权重方面具有相似的性能。但是,在Apache Spark和Single Node上,在其他3个数据集(Mfeat、Spambase和心电图)中,IWKM可以获得比TWKM更好、更合理的视图权重。TWKM计算出的视图权重常常集中在一个视图上,这与现实应用不符。IWKM计算的权重比TWKM计算的权重更合理,并且特征的权重处于相同情况。因此,可以得出结论,在视图权重方面,IWKM比TWKM具有更好的性能。

表2 TWKM和IWKM计算的视图权重

续表2
利用CPSO进行优化得到六个聚类算法的最优参数值如表3所示。为了进一步验证本文算法在大数据应用中对高维多视图数据进行聚类的综合性能,在Apache Spark和Single Node两种不同的计算平台上,通过RI、JC和Folk的评估指标,在五个高维多视图数据集中将IWKM与其他五种算法进行了比较。

表3 实验中六种聚类算法的参数值
在实验中,视图数与特征数的乘积记录为pf×v,用于描述高维多视图数据的复杂性。特征数越大,高维多视图数据越复杂。在表1中,根据pf×v的值,Mfeat的数据集(特征数:649,视图数:6,pf×v=649×6=3 894)、互联网广告数据集(特征数:1 557,视图数:6,pf×v=1 557×6=9 342)比Spambase数据集(特征数:57,视图数:3,pf×v=57×3=171)、图像分割数据集(特征数:19,视图数:2,pf×v=19×2=38)、心电图数据集(特征数:21,视图数:3,pf×v=21×3=63)更复杂。
表4总结了IWKM与其他五种算法在Apache Spark和Single Node上的综合比较。比较它们的平均结果(10倍)和标准偏差以减少统计误差。从这些结果中,可以看到IWKM在Mfeat数据集和互联网广告数据集中明显优于的其他五种算法。在Spambase数据集中,IWKM的性能优于TWKM和DC,但AP在Mfeat数据集中的效果最差。在Mfeat数据集中,DC和IWKM均比LAC、AP、Ncut和TWKM更好。在互联网广告数据集中,AP、TWKM和IWKM的性能优于LAC、Ncut和DC。LAC明显优于Spambase数据集中的其他五种算法(包括IWKM),但Spambase数据集的复杂度低于Mfeat数据集和互联网广告数据集。因此,可以得出结论,在这些复杂的数据集中,IWKM在针对具有更多视图和更高维度数据集来说,例如多特征和互联网广告数据集,胜过其他五种算法。在心电图数据集中,IWKM优于其他的五种算法。但是,在图像分割中,Ncut和TWKM的性能要优于IWKM。由于心电图数据集比图像分割数据集更为复杂,因此高维多视图数据集越复杂,IWKM的性能越好。总之,IWKM可以更加有效地处理大数据应用中的高维多视图数据集的聚类。同时,在这些复杂的数据集中,IWKM优于其他五种算法。

表4 五种算法的比较
4 结 语
针对传统聚类算法无法处理大数据中多视图高维数据问题,提出一种基于混沌粒子群优化算法的智能加权K均值聚类算法。通过实验证明了CPSO可以帮助IWKM在高维多视图数据中获得更好的初始聚类中心、视图权重和特征权重,为聚类精度的提升提供良好的初始值要求。另外本文方法能够有效实现多视图高维数据的聚类,且针对视图越多、维数越高、数据越复杂的数据集越能够体现该算法的优越性。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
农业工程学报(2022年6期)2022-06-27
计算技术与自动化(2022年1期)2022-04-15
汽车实用技术(2022年5期)2022-04-02
河南科技(2021年26期)2021-03-22
科学导报(2020年85期)2020-01-13
世界知识画报·艺术视界(2017年7期)2017-07-27
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
