
基于联合分布适配的水下声源测距算法研究
2022-06-25 08:29孙玉林郭龙祥
电子与信息学报 2022年6期
李 理 孙玉林 曹 然*④ 郭龙祥
①(哈尔滨工程大学水声技术重点实验室 哈尔滨 150001)
②(哈尔滨工程大学海洋信息获取与安全工信部重点实验室 哈尔滨 150001)
③(哈尔滨工程大学水声工程学院 哈尔滨 150001)
④(哈尔滨工程大学青岛创新发展中心 青岛 266400)
1 引言
水下声场环境中,文献[1,2] 指出声源测距一般采用匹配场处理(Matched Field Processing, MFP)来解决,但匹配场处理需要对水下声场精确建模才能给出合理的预测。从Bucker[3]提出匹配场处理开始,Fizell等人[4]证明匹配场的应用价值后,匹配失真的问题层出不穷。水下声场是时变和空变的,充满着复杂和不确定性,这易造成建模声场与实测环境的失配。一些学者提出将环境参数加入改进的匹配场算法,如文献[5]中的环境聚焦匹配场处理等,但这些方法增加了计算量,并且引入了更多的包括环境参数在内的先验信息,进一步提升了构建有效匹配场模型的难度。
另外,文献[6,7]指出随着机器学习理论和技术的不断进步,基于该方法下的水声被动测距方法成为一个可靠的研究方向。通过文献[8-11]可知,机器学习应用于水声领域中已经有很长时间,而应用于水声被动测距却刚走向成熟。近几年来,文献[12-14]基于最小二乘和传感器网络实现了车辆以及水下传感器网络节点的高精度测距,文献[15-19]证明了机器学习在水声声源测距方面优于传统的匹配场处理方法,文献[20,21]也证明了神经网络估计水下声源距离和深度的可靠性。
虽然机器学习方法进行水下声源测距不需要环境先验信息,但机器学习算法通常需要足够多的训练样本支撑,而数据样本获取难度大,训练样本稀缺恰恰是水声领域的突出问题。相比于文献[15,16]将单一航次的数据划分为训练集和测试集进行性能验证的应用场景,更期望能用已知的历史信息作为训练样本训练模型,对新获取的未知数据进行有效分析。传统机器学习理论有效的一个基本假设是训练样本与测试样本满足独立同分布,不同的水声实验任务中获取的数据很难满足该前提,致使使用传统机器学习方法基于历史数据构建的模型泛化能力非常有限。针对上述问题,本文尝试采用基于迁移学习的方法进行解决。由文献[22]可知迁移学习是机器学习技术的一种,雷波等人[23]的研究初步验证了迁移学习算法在针对前向散射声呐进行主动测距,但是在被动测距的应用鲜有见刊。在迁移学习的理论中,所有已有的知识称为源域(source domain),将要学习的新知识称为目标域(target domain),其中源域和目标域分别属于不同的特征空间;而基于特征的迁移学习方法将来自源域和目标域的数据映射到共同的特征空间,减少域之间的差异性。基于迁移学习思想,本文将已标注航次航迹数据当作源域,将要进行测距任务的未标注航次航迹数据当作目标域,而学习的目标是将从源域中学到的特征更好地适配于未知航迹数据的学习过程,最终提升测距模型的泛化能力。
本文应用联合分布适配(Joint Distribution Adaptation, JDA)算法对船舶在不同航迹时与垂直接收阵之间距离的回归和预测:引入文献[24]提出的联合分布适配算法至水下测距问题中,提出了基于联合分布适配的水下声源测距方法;详细说明了实验数据的预处理过程和目标测距算法的性能指标;对比了K近邻(KNN)、支持向量机(Support Vector Machine, SVM)、卷积神经网络(Convolutional Neural Network, CNN)和完成迁移学习后再由3种分类器回归预测的实验结果;最后分析对比了迁移学习的迁移效果,结果表明基于联合分布适配的水下声源测距算法的距离估计精度更高。
2 基于联合分布适配的水下声源测距算法
本文提出一种基于联合分布适配的水下声源测距算法,从目标距离差异引起声场统计特性不同的角度出发,建立起互谱密度矩阵信息与目标位置的映射关系,将水下声源距离估计问题转化为分类问题。联合分布适配则是针对概率分布差异提出的一种迁移学习算法,下面将介绍联合分布适配方法,并提出基于联合分布适配的水下声源测距算法。
2.1 联合分布适配方法思想
针对目标域没有标注数据的无监督迁移学习中,已有方法通常仅适配了边缘概率分布,但这会导致域间概率分布的欠适配问题,严重影响学习模型的泛化性能。由此,Long等人[24]提出了联合分布适配方法,这种方法适用于迁移学习的领域自适应(domain adaptation)方向,并在图像迁移领域有着较多的应用。JDA方法是一个适配于概率分布的方法,其主要的思想是将源域以及目标域的联合概率作为适配的对象。由于水下声源距离参数估计中的源域和目标域边缘分布不同且源域和目标域条件分布不同,为了同时适配于两个分布,该方法必须适配于两者的联合概率。
文献[25]提出JDA方法的具体过程如图1所示,给定有标注源域Ds(已标注航次航迹数据)和无标注目标域Dt(待预测航次航迹数据),如图1(a),可以看出,由于两者概率分布的差异,Ds训练得到的判别面f不能准确地分类Dt。因此该方法首先进行边缘分布适配(MDA),最小化边缘分布之间的距离,如图1(b),从而增加分类结果的准确率;然后进行条件分布适配(CDA),最小化条件分布的差异,如图1(c),使类别中心与Dt对应;最后进行流形正则化(MR)改变判别面f的位置,如图1(d)保证可以得到更加可靠的标注距离。

图1 联合适配正则化工作原理示意图
2.2 联合分布适配方法原理


本文提出算法通过上述方式将源域数据和目标域数据映射到共享特征空间,降低了不同任务域数据服从分布的差异性,最终提升了基于此构建的分类器的分类精度和泛化能力。
2.3 测距算法流程
本节提出一个基于联合分布适配的声源测距算法,图2为水下声源测距算法具体流程图。
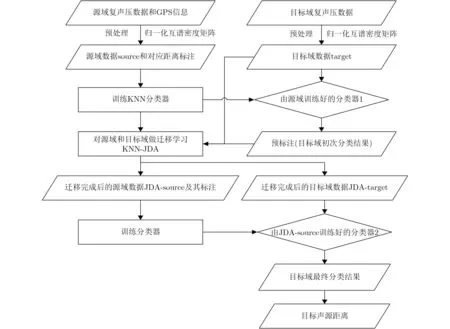
图2 水下声源测距算法流程图
(1)数据预处理。对采集到的声压时域信号求互相关得到采样协方差矩阵,对其做傅里叶变换得到归一化的互谱密度矩阵,将该矩阵作为数据特征。
(2)为源域和目标域标注。根据距离信息和对应样本数为源域数据与目标域数据标注。
(3)迁移学习。用源域数据和源域标注训练的KNN分类器给出目标域的预标注,将源域数据、源域标注和目标域数据、目标域预标注作为输入,寻找令最大均值差异最小化的变换矩阵,同时调整源域和目标域的边缘分布适配与条件分布适配,进行联合分布适配,在此过程中迭代寻优使得源域和目标域的分布差异最小化,由此得到新的源域数据(JDA-source)和目标域数据(JDA-target)。
(4)预测目标域的标注。由JDA-source和源域标注作训练集训练所选分类器,用训练好的分类器预测JDA-target,然后将预测结果映射到距离信息得到目标声源距离。
3 实验验证及结果分析
本文使用了联合分布适配进行迁移学习,使用支持向量机、K近邻、卷积神经网络进行分类,其中联合分布适配前使用的预标注分类器为KNN。
3.1 实验数据及预处理方法介绍
基于文献[15,16,20],一些基于传统机器学习的水下声源测距算法优于传统匹配场的Bartlett处理器,本文不再多进行对比。本文用于验证所提出算法的数据集来源于文献[26]中R/V New Horizon在Noise09试验中辐射的船舶噪声数据,预处理过程参考了牛海强等人[7]对实验的做法。
在Noise09试验中,利用接收阵列接收的船舶辐射噪声共有5组连续的信号。其中,垂直接收阵列(VLA)包含16个间距为1m的水听器,用于接收船舶辐射噪声,接收阵元水听器的采样频率为25 kHz,文献[26]给出试验数据集来源的船舶航迹和接收阵列位置如图3所示。
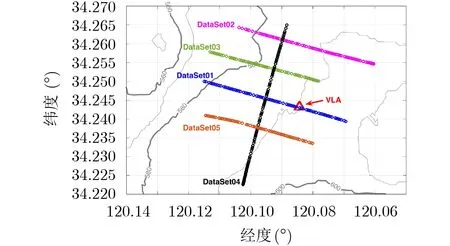
图3 船舶轨迹和接收阵列GPS信息图
数据处理过程中,将试验数据转换为采样协方差矩阵,设置快拍(snapshots)为10,并对采样协方差矩阵做傅里叶变换得到互谱密度矩阵,取其上三角并向量化,得到维度为7200维的数据特征,数据的样本数由采样频率和航行时间决定,每组数据样本数不尽相同。
阵列接收信号经过上述预处理得到源域数据和目标域数据,再由GPS记录值计算出对应样本的目标船舶距离,由目标船舶距离映射得到源域和目标域的标注。
3.2 实验设计
为了验证所提出算法的泛化能力,本文将5个航次航迹的数据集分为3个源域和目标域的组合,用4个航迹的已标注数据对剩余1组航迹的未标注数据进行预测。源域和目标域的划分、距离范围和各个实验任务的样本数及维度如表1所示。

表1 源域和目标域划分及其规模和维度
5个航迹中目标船舶与接收阵列之间的距离在0~2960 m,因为数据量少以及需要尽量减少预测距离误差,所以标注时需保证每个标注下的样本数量不会太少且标注对应距离间隔不会过大。由此,为源域和目标域数据标注1~149,间隔为1,映射在0~2960 m,间隔为20 m。
实验中,本文首先使用K近邻、支持向量机两个典型的浅层分类器,和卷积神经网络作为深层分类器代表,共3个分类器对原始数据进行距离标注预测,之后用联合分布适配对源域和目标域数据迁移,再用3个分类器重新预测。其中,对于KNN,其参数决定最邻近的k个样本作为同一推测类别,在本文所用实验数据中不同实验任务需选用不同的k值从2~5,从而保证预测误差达到最低。对于SVM,我们经过对线性核、多项式核、高斯核的分别测试,得出结论,高斯核效果最好,所以本文中均使用高斯核对经过预处理的数据进行训练和分类,其中高斯核自带参数γ取值经过从0.0005到1间隔为0.0005分别训练计算预测结果误差,得到最优值,并得到误差最小的结果。对于CNN,本文使用的结构主要由两层卷积-池化层和两层全连接层构成,由于本文实验条件中每类数据量较小,因此不进行随机丢弃,优化器选择Adam。
3.3 实验结果及分析
图4、图5为实验1的预测结果图(蓝色为预测结果,红色为实际距离)和样本空间的数据可视化(TSNE,同一形状颜色的点标注相同)3维图。
实验1的预测距离范围为900~3000 m。从图4(a)-图4(c)对比来看,KNN和SVM要明显优于CNN,CNN的距离预测精度很低,这是因为每个类别数据量不够多的情况下CNN容易过拟合,值得注意的是,3个分类器对2000 m以上的部分预测误差均较大。图4(d)-图4(f)对比来看,经过JDA算法迁移后的数据再进行分类,分类误差比迁移前更小,CNN和KNN分类器的提升尤为明显,而SVM的性能最好,同时,3个分类器的远距离预测结果提升也极其明显。经过对迁移前和迁移后的样本数据做数据可视化得到图5可以看出,联合分布适配前样本数据的分布较为杂乱,分类器很难判别给出正确结果,而联合分布适配后同一标注的样本数据更加集中,有利于分类器构建超平面进行判别给出正确的分类结果。
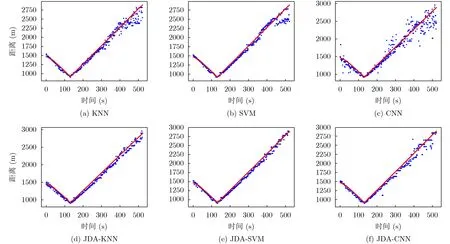
图4 实验1测距结果
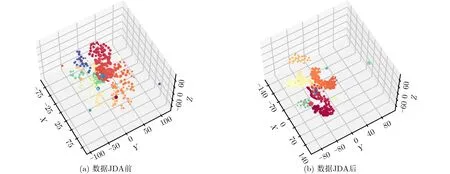
图5 实验1的数据可视化(TSNE)3维图
图6、图7为实验2的预测结果图(蓝色为预测结果,红色为实际距离)和TSNE3维图。
实验2的预测距离范围同样为900~3000 m。图6(a)、图6(c)的对比结果与实验1的结论基本相同。但从图6(d)-图6(f)对比来看,迁移前的KNN和SVM在2000 m以上的远距离分类上部分预测误差甚至超过1000 m,迁移后的3种分类器在该部分的预测误差普遍减小,JDA效果明显。通过图7可以看出数据经过联合分布适配后聚类效果提升明显,因此分类精度也显著提升。
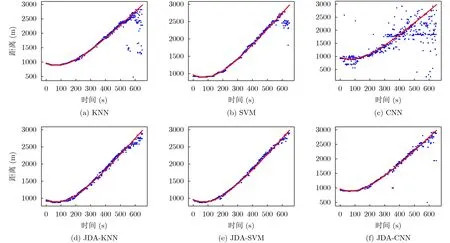
图6 实验2测距结果
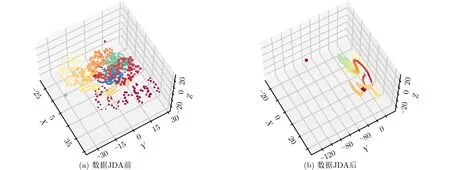
图7 实验2的数据可视化(TSNE) 3维图
图8、图9为实验3的预测结果图(蓝色为预测结果,红色为实际距离)和TSNE3维图。
从图8的测距结果可以看出,本数据的一个特点是针对1600~1800 m的区间,SVM和CNN的识别效果均不佳。图8(a)-图8(c)对比来看,在迁移学习前,SVM距离预测结果精度最高,只有在1600~1800 m的距离预测误差较大,而KNN的远距离预测出现1000 m以上的误差,CNN预测结果最差;迁移学习后,SVM除在1600~1800 m的距离预测误差比KNN略高外,其余距离的测距精度均较KNN更高。图8(d)-图8(f)对比来看,KNN的远距离预测性能提升尤其明显,SVM在1600~1800 m的距离预测误差有一定程度的减小,CNN总体提升明显。由图9可以看出,样本数据经过联合分布适配后明显更有利于减少分类结果相差极大的情况。
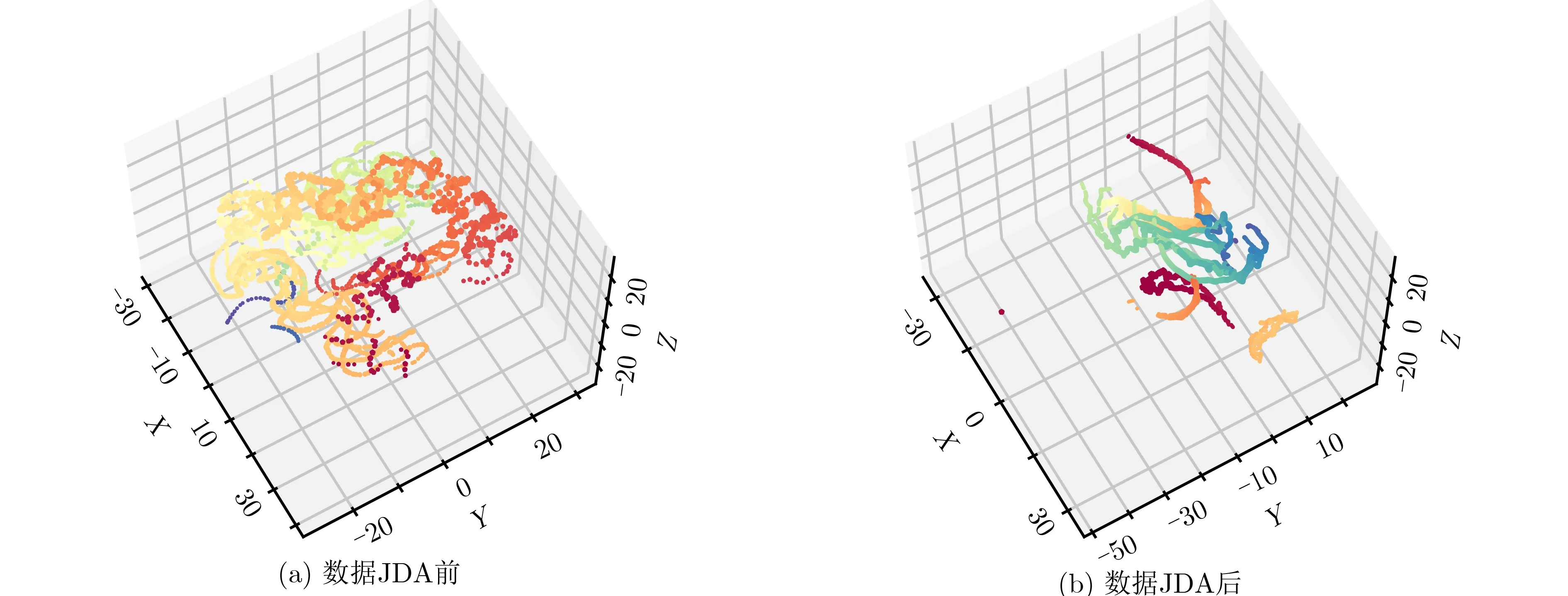
图9 实验3的数据可视化(TSNE) 3维图
为更好量化距离估计方法的预测性能,用均方根误差(RMSE)和平均绝对误差(Mean Absolute Error, MAE)[7]对预测性能进行评估,其中均方根误差与平均绝对误差分别定义为
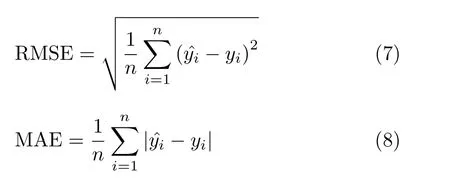
其中,预测值:yˆ ={yˆ1,yˆ2,...,yˆn},真实值:y={y1,y2,...,yn}。RMSE能较为直观地给出预测距离和实际距离之间的偏差,而MAE考虑了错误范围估计中的误差大小以及总体平均的预测效果。
在本文中,3个预测任务分别独立完成,与GPS真值作对比计算度量误差。图10,图11分别是3种分类器的预测以及进行联合分布适配后再预测目标域两种度量误差的直观比较图。
从图10可以看出,从单独的各个实验任务来看,CNN和KNN的分类误差最大,在最大预测距离不超过3 km的情况下,均方根误差甚至达到300 m以上,平均绝对误差最高在100 m以上。经过JDA迁移学习后,均方根误差和平均绝对误差均有明显改善,误差降低幅度极大。其中CNN主要是因为数据量较小,难以形成有效的学习过程,而KNN分类方式过于简单,所以两者在迁移学习前分类误差相对较大,SVM的分类误差相对于KNN和CNN最小。经过迁移学习后,SVM分类后距离误差明显低于其他分类器,KNN的分类效果其次,CNN分类效果最差,误差相对较大。从与实际值的偏差来看,SVM的RMSE降低值最小,降低幅度较大;KNN的误差降低值其次,降低幅度较大;CNN的误差降低值最大,降低幅度较小。从图11MAE来看,经过迁移学习后,SVM分类结果精度最高,其次是KNN, CNN效果最差;CNN降低值最大,其次是KNN, SVM降低值最小;SVM降低幅度较小,KNN和CNN的降低幅度较大。
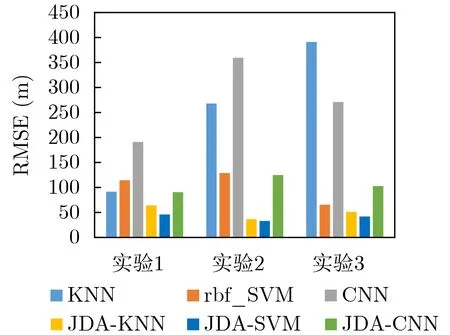
图10 测距评价指标RMSE
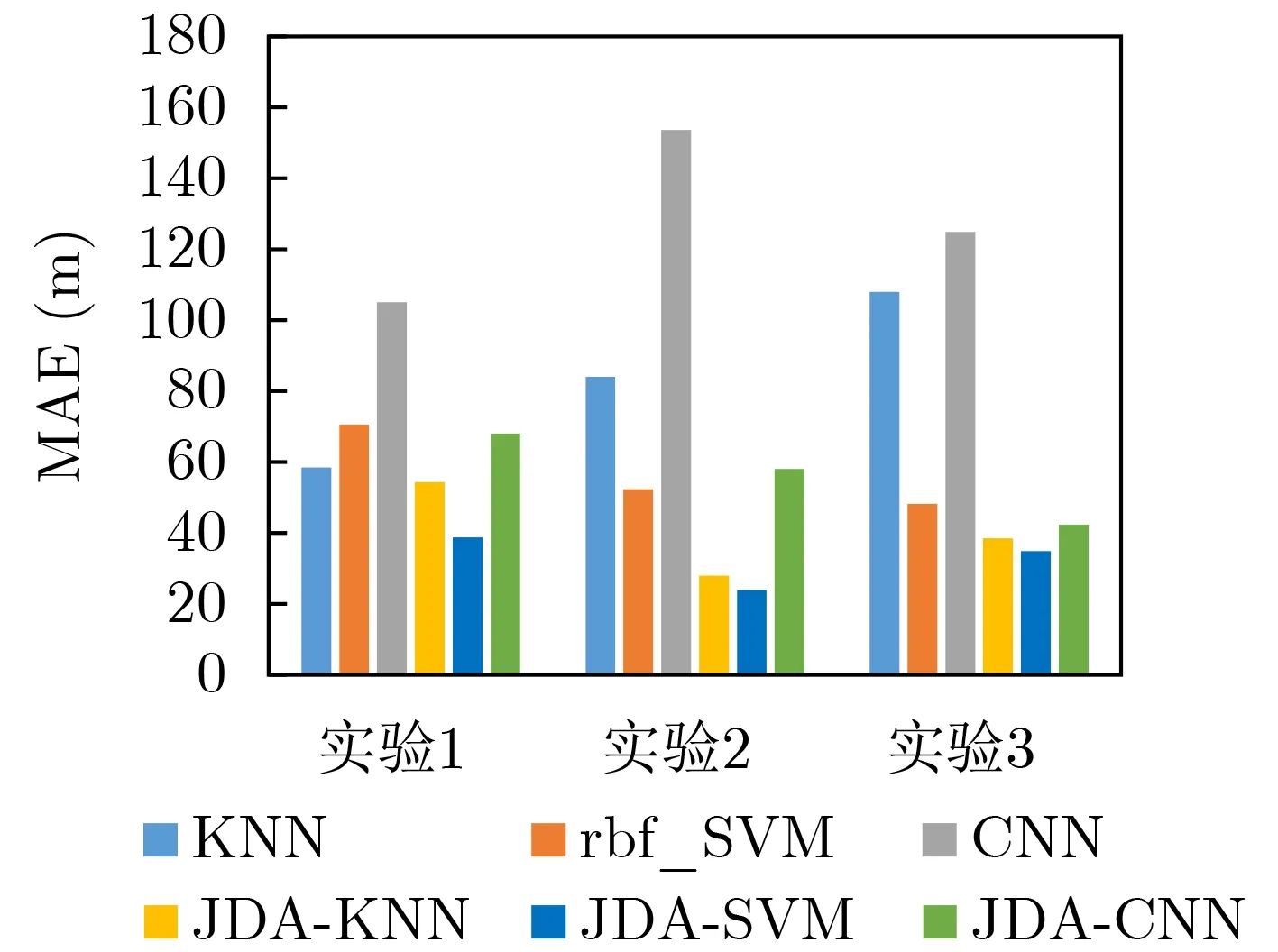
图11 测距评价指标MAE
4 结论
本文提出了一种基于联合分布适配的水下声源测距算法。考虑到不同时间和方位上的航船轨迹数据服从不同的分布基于机器学习的声源测距方法造成的影响。本文将归一化的互谱密度矩阵作为输入,通过对已标注数据和未标注待预测数据进行JDA映射,从而使得原本服从不同概率密度函数的数据实现一致性分布,之后训练3种机器学习模型对水下声源距离进行预测以求对所提出算法进行验证。实验结果表明,在同样样本空间的条件下,经过联合分布适配迁移后在不同时间不同航迹下的距离预测结果的RMSE都降低超过20 m,降低幅度都超过40%,预测结果的MAE除实验1中的KNN都降低超过10 m,降低幅度都超过30%,相比没有进行迁移学习前可以更好地完成水下声源测距任务。此外,使用并不服从独立同分布的历史数据构建的分类模型,对未来数据进行分析在水声领域成为可能,这对于解决该领域天然面临的数据稀缺性问题具有显著的实际意义。同时本研究还得到一个重要结论,即尽管深度学习算法在特征提取方面有着理论上更强的能力,但是针对具体的任务时,例如水声测距任务的数据特点,并不能使得普通的深度学习算法凸显优势,反倒由于数据量不足和差异性过大导致训练结果比诸如KNN和SVM之类的典型浅层分类器更差。
致谢 感谢Scripps海洋学研究所的海洋物理实验室团队提供的Noise09实验数据集。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
舰船科学技术(2022年11期)2022-07-15
计算机技术与发展(2020年11期)2020-12-04
科学(2020年3期)2020-01-06
电子制作(2019年23期)2019-02-23
电子制作(2017年7期)2017-06-05
电子制作(2016年19期)2016-08-24
青年文学家(2015年29期)2016-05-09
舰船科学技术(2015年8期)2015-02-27
太空探索(2014年1期)2014-07-10
