
基于改进Apriori 算法的高校体测数据关联分析①
2022-06-27 03:54蒋茜茜杨风暴杨童瑶张锦荣
计算机系统应用 2022年5期
蒋茜茜, 杨风暴, 杨童瑶, 张锦荣
(中北大学 信息与通信工程学院, 太原 030051)
信息社会产生的大量数据急需强有力的数据分析工具, 将数据转换成有用的信息、知识, 因此, 数据挖掘技术[1]应运而生. 高校体测数据的关联规则挖掘能直接反映项目集中数据的潜在关联, 对帮助学生提高体能素质具有重要的意义.
张崇林等[2]通过体质测试数据处理方法分析, 认为体质测试数据适合进行关联规则数据挖掘, 并且通过关联规则数据挖掘, 发现了原知识体系利用BMI 和体脂率评价肥胖的矛盾现象, 可知Apriori 算法利用逐层迭代搜索的方法挖掘数据间的关联关系, 是目前关联规则应用最广、最经典的算法. 赵常红等[3]运用关联规则的Apriori 算法并设置支持度、置信度, 分析男、女生的不同体测数据, 各测试指标等级数量分布情况及其之间的关联性, 但是忽略了算法的运行效率. 刘辛等[4]提出一种基于数组的Apriori 算法, 减少了候选频繁集冗余, 提高了Apriori 算法效率, 找出了各体测项目间的关联关系, 但是忽略了遍历数据库的次数对运行效率的影响. 崔亮等[5]提出一种基于动态散列和事务压缩的关联规则挖掘算法, 通过估计产生候选项集的大小来动态选择是否使用hash 技术, 并且利用事物压缩技术删除不包含频繁项集的事务, 从而提高算法运行效率.
由上述文献可知关联规则Apriori 算法可应用于高校体测数据场景, 其弊端在于数据量增加到一定程度时算法效率低下[6]. 与崔亮等[5]提出的方法不同, 本文提出的基于事务压缩和hash 技术的改进Apriori 算法, 无需估计产生候选项集的大小, 是根据体测数据特征有限并且长度一致的特点, 先使用散列技术压缩要考察的候选项集, 再结合事务压缩技术减少遍历数据集的事务项数和长度, 将这两种算法优势完美结合, 从而大大提高算法的运行效率, 并且有效得到体测数据间的关联, 能较好地预测影响学生体能素质的因素, 从而辅助指导学生的体能训练.
1 基于事物压缩和hash 技术的Apriori 关联规则算法
关联规则是描述数据事务特征属性间的规律, 通过某些属性来预测其他属性的关联. 在体测数据中, 设项集itemset={item_1,item_2, …,item_n}是高校学生体测数据特征属性的集合,n是属性的个数[7]. 一条学生体测数据是一个事务T, 一个事务T是一个项集, 每个事务均与一个唯一标识符Tid相联系, 体测数据中学籍号是唯一的标识符Tid[8]. 不同学生的体测数据组成了事务集D, 它构成了关联规则发现的事务数据库.
用支持度和置信度衡量关联规则的标准, 例如形如A⇒B的关联规则, 体测数据属性项A与属性项B同时存在的概率即为该数据关联规则的支持度Support(A⇒B); 体测数据属性A存在的条件下, 属性B也存在的概率即为体测数据关联规则的置信度Confidence(A⇒B), 其分别如式(1)和式(2)表示.

1.1 Apriori 算法
Apriori 算法是利用k-项集来产生(k+1)-项集迭代的方法[9], 其操作流程如图1, 设定最小支持度min_sup和最小置信度min_conf, 扫描整个数据库, 统计长度为1 的每一项的个数, 筛选满足最小支持度的项, 得到频繁1-项集L1; 由L1自身连接生成候选2-项集C2, 得到的C2进行剪枝操作, 统计长度为2 的每一项的个数,删除不满足最小支持度的项, 得到频繁2-项集L2, 如此迭代下去, 直到不能再找到频繁k-项集[10], 最终得到频繁项集L={L1,L2, …,Lk}.

图1 经典Apriori 算法流程
Apriori 算法的弊端在于数据量增加到一定程度时算法效率低下, 具体表现在以下3 个方面:
1)在Lk-1与自身连接生成Ck过程中, 可能需要产生大量候选项集. 例如, 假设Lk-1中有m个k-项集,则在进行自身连接需要进行比较的时间复杂度为O(k×m2).
2) 在对Ck剪枝的过程中, 判断Ck中任意一个k项候选集的(k-1)-项候子集是否为Lk-1的子集, 最快只需要扫描一次得出结果, 最慢需要k-1 次, 所以平均时间为|Ck|×|Lk-1|×k/2.
3)在筛选满足最小支持度的候选项集过程中, 对Ck中的每个项进行计数, 需要扫描数据库|Ck|次.
1.2 基于散列技术的Apriori 算法
散列技术又名hash 技术[11], 基于散列技术的Apriori算法的优势主要体现在能将生成的Ck进行压缩, 大大缩小了Ck占用空间. 首先, 扫描数据库所有的事务得到C1, 筛选满足最小支持度的候选项集得到L1; 然后利用散列技术来改进产生频繁2-项集的方法, 具体如下: 将每条事务生成其所有的2-项集并且运用散列技术构造散列函数把它散列到相应的散列表中, 即分配到不同的桶中并计数, 而且相同的数据项被分配到同一存储空间, 且对应着同一计数器, 只需计数加一即可,且降低了所需的存储空间. 同样的生成频繁k-项集也是用相同的方法, 并且在散列表中可以筛选出容器计数小于支持度阈值的k-项集, 因此可以很好的对要检测的k-项集执行压缩操作.
散列技术的缺点是其运行效率依赖于事务的平均长度, 也就是说如果数据集的特征少, 平均长度短, 其运行效率就高, 反之运行效果差. 而Apriori 方法运行效率不依赖于数据集特征的长度和数量, 所以一定程度上弥补hash 技术的缺点, 两者互补可以大大增加算法的运行效率.
1.3 基于事务压缩技术的Apriori 算法
基于事务压缩技术的Apriori 算法的优势主要体现在将进一步迭代扫描的数据库进行压缩, 进而影响扫描事务库的次数, 增加算法的运行效率[12]. 该技术的改进是根据经典Apriori 算法的性质, 即如果一个事务不包含任何的频繁k-项集, 则其也不包含任何的频繁(k+1)-项集. 因此在生成Lj(j>k)时, 遇到上述事务时,可以加上标记或删除, 扫描数据库时不需要再扫描该事务, 减少扫描事务库的次数.
1.4 基于散列技术和事务压缩相结合的改进
根据以上了解可知, 基于散列技术的改进和基于事务压缩技术作用于Apriori 算法过程中的不同部分,基于散列技术的改进体现在减少候选项集的规模, 并更进一步减少数据库扫描的次数, 而事务压缩技术能够逐渐减小数据库中事务的长度和规模, 都主要作用在Apriori 算法的剪枝部分[13], 并且两者会促进对方的效果, 而不产生负面影响.
改进算法流程如算法1 所示, 根据高校体测数据的特征有限和并且长度一致的特点, 利用散列技术遍历一次事务集, 即可生成频繁项集L1,L2,L3, 再利用事务压缩技术由L3生成L4, 如此迭代下去, 直到不能再找到频繁k-项集. 因为迭代生成候选项时可能性太多,数据量大时占用内存太大, 所以不继续使用hash 技术继续生成L4, 而改用事务压缩技术, 有效地避免hash技术的短板.

算法1. 改进Apriori 算法输入: 数据库D, 最小支持度min_sup, 最小置信度min_conf过程:1)扫描数据库, 利用散列技术生成频繁1-项集L1, 频繁2-项集L2, 频繁3-项集L3;2)通过频繁项集Lk-1 自身连接生成Ck 候选项集, 再进行剪枝;3)利用事务压缩技术减少扫描事务集的次数, 删除不满足最小支持度的项集, 生成频繁k-项集Lk;4)对k>3, 重复执行步骤2)和3), 判断频繁k-项集的长度, 如果为0,则跳出循环, 得到最终结果频繁项集L, 否则返回步骤2);5)筛选出满足min_sup 和min_conf 的频繁项集即强关联规则, 结束.输出: 强关联规则
2 实验过程及分析
2.1 数据准备
以我校2016 级7 709 名大学生第一学年的体测成绩为实验对象, 从数据库中提取与体测成绩有关的数据, 如: 学籍号、性别、身高、体重、肺活量、50 m、立定跳远、1 000 m (男生)、800 m (女生)、引体向上(男生)、仰卧起坐(女生)共11 个属性, 表1 是以学籍号为主键的体测成绩.

表1 学生2016 年的体测成绩
2.2 数据清洗及转换
实验数据来源于我校体测中心, 所以得到的数据较为规范, 但是数据中存在部分学生体测成绩缺项, 又考虑到部分特殊学生免测的情况, 所以要对原始数据先进行预处理, 经过数据清洗、数据转换和数据消减,实现算法在高校学生体测中的应用.
数据清洗的实际操作主要有:
(1)针对缺项数据, 如果缺项数据较多则删除该学生的体测成绩[12]; 如果缺项较少, 则可以通过求该项目成绩的平均值、众数或者中位数填充;
(2)针对免考学生的数据, 由于各项成绩为缺项,可以直接删除, 使得清洗后的数据标准、干净且连续.
数据转换将不同标准的连续型数据转换成标准相同的离散型数据, 便于后续的统一处理. 虽然体测项目间的评判标准不同, 但是都可以划分为A、B、C、D 四个等级, 即优秀、良好、及格、不及格, 其次, 为了方便统计以及提高数据挖掘的效率, 用数字1 和2分别代替性别的男和女, 用小写字母开头代替各项目的名称, 如: 肺活量用fhl 代替.
数据转换结果如表2 所示, 经过数据清洗及转换得到的标准数据最终有7 337 条.

表2 数据转换结果
2.3 数据消减
数据消减是在保持数据库的完整性的情况下, 从上述数据集中获得精简的数据集, 能够保证不影响最终的算法结果. 男生和女生体测项目和评价标准有所不同, 所以本文将在数据挖掘时对男生和女生的体测成绩数据分别进行处理. 数据消减就是针对数据库中筛选出的男生、女生的体测数据, 消除与体测项目属性无关的项, 例如学籍号, 性别.
2.4 实验验证
试验环境为Intel(R) Core(TM) i5-5200U 2.20 GHz处理器, 4 GB 内存, 操作系统为Windows 10, 算法在Python 3.8 下实现.
设定min_conf= 0.9, 设置不同的最小支持度, 利用Apriori 算法以及本文提出的事务压缩和hash 结合的算法得到的结果如表3 所示, 在相同的最小支持度下得到的关联规则数目相同, 表示改进后的算法确保了Apriori 算法的准确性, 由此可以得到改进算法的可靠性; 随着最小支持度的增加, 改进后的算法执行效率大大提高. 改进后的算法在保证挖掘精度的同时提高算法效率.
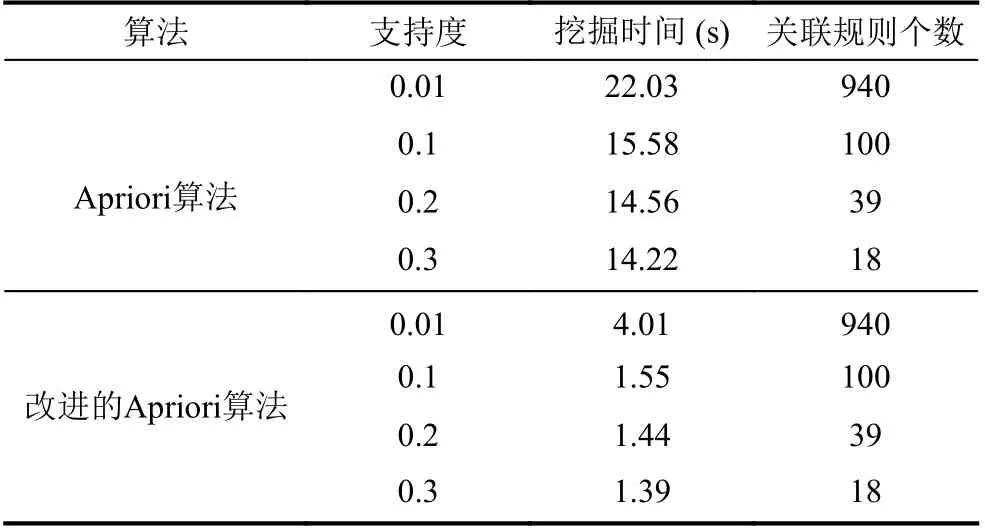
表3 两种算法比较
为了能直观地反映出改进后的算法运行效率更高,在设置不同最小置信度、最小支持度情况下, 将得出的实现数据进行分析对比, 结果如图2 和图3 所示. 图中结果可知, 本文提出的改进算法效率明显优于经典Apriori 算法、基于hash 的Apriori 算法以及基于事物压缩的Apriori 算法. Apriori 算法和基于事物压缩的Apriori 算法随着支持度和置信度的增加执行效率比较接近, 其中基于事物压缩的Apriori 算法效率稍高; 基于hash 改进算法相较于Apriori 算法和基于事物压缩的Apriori 算法本身具有一定的优越性, 本文将hash技术与事务压缩技术相结合得到了更好的效果.

图2 不同支持度性能对比

图3 不同置信度性能对比
2.5 结果分析
原始的体测数据经过数据预处理后得到2 266 条女生体测数据和5 071 条男生体测数据, 设置最小置信度min_conf= 0.9, 最小支持度min_sup= 0.3, 将这两类数据分别用文中提到的4 种算法进行关联规则挖掘,将各运行效率进行比较, 如表4 所示, 可以看出本文提出的基于事物压缩和hash 结合的算法执行效率更高,与经典Apriori 算法执行效率相比, 女生体测数据算法执行效率提高了86.12%, 男生提高了90.63%; 与基于事物压缩的Apriori 算法相比, 女生体测数据算法执行效率提高了80.57%, 男生提高了89.32%; 与基于hash 的Apriori 算法相比, 女生体测数据算法执行效率提高了48.1%, 男生提高了55.69%; 可见, 该4 种算法应用于男生的体测数据的执行效率比女生更高, 说明数据集量越大改善效果越明显.

表4 4 种算法执行效率比较 (s)
表5 和表6 分别是男生和女生体测成绩的关联规则挖掘结果, 由表5 可以看出挖掘出的男生第一条关联规则50 m:C ⇒ytxs:D, 支持度为72.1%, 置信度为93.5%, 说明男生50 m 成绩如果是C 等级, 那么他的引体向上的成绩为D 等级的可能性为93.5%, 而这种事件发生的可能性为72.1%, 可知此学生的50 m 成绩可以预测其引体向上的成绩, 以此类推. 可通过某学生的历史数据来预测其他成绩的及格情况, 达到预警的效果, 使该学生加强某方面的锻炼, 进行有针对性的体能训练, 帮助老师安排训练计划有着指导性的意义.

表5 关联规则 (男生)

表6 关联规则 (女生)
3 结论与展望
现在数据挖掘技术已经非常成熟, 然而数据挖掘和体能分析结合的应用却很少, 本文通过对比4 种算法实现的结果和执行效率, 表明改进后的算法在高校学生体测中的应用具有一定的可靠性和有效性, 对于比较大的数据集效率改善更明显. 并且将本文所提出的算法, 与经典Apriori 算法相比, 可知执行效率提高了85%以上, 并且挖掘出体测成绩间的潜在关联, 分析身体素质的不足之处, 对学生重视体育锻炼, 辅导老师安排学生的训练计划具有指导性的意义.
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
节能与环保(2022年7期)2022-11-09
小型微型计算机系统(2022年4期)2022-05-09
计算机与数字工程(2020年7期)2020-10-09
电脑知识与技术(2017年27期)2017-11-20
计算技术与自动化(2017年3期)2017-10-26
科技创新与应用(2017年3期)2017-02-18
中国科技纵横(2016年20期)2016-12-28
