
基于BERT-BiLSTM的水利新闻情感分析研究
2022-07-02 06:08苏天龚炳江
电脑知识与技术 2022年15期
苏天 龚炳江

摘要:BERT是谷歌AI团队近年来新发布的自然语言预训练模型,在11种不同的NLP测试中创出最佳成绩,被认为是NLP领域中里程碑式的进步,因此利用BERT进行文本情感分析是一个很热门的研究方向,该文中水利舆情分析主要是对水利新闻进行情感分析。该文对基于词典、机器学习和深度学习的情感分类技术进行了分析,并提出了基于完整句分割的BERT-BiLSTM水利新闻文本情感分类模型。该课题可以为水利行业从业人员和其他领域的情感分类研究提供较高的指导意义。
关键词:水利舆情系统;NLP;情感分析;BERT-BiLSTM模型;文本分类
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)15-0004-03
1 引言
我国是一个水灾多发的国家,水灾的发生往往会给人们带来很多不利的影响。近年来,随着互联网的发展,人们能够越来越方便地在网络上发表和水利有关的新闻和言论,但往往有些新闻或者言论是不正确的,甚至会给社会带来巨大的负面影响。因此,利用情感分类技术检测负面新闻的传播来维护社会稳定是非常有实用价值的。
情感分析主要从分析网络舆情发展而来。国内外的学者研究网络舆情焦距情感分析、话题识别、关键词提取等方面。早期的舆情分析并不是直接用于情感分析,而是用于调查民意、观察舆论动向等方面。1996年,美国国防高级研究计划局DARPA提出了话题检测与跟踪技术TDT的概念,即让计算机自动识别文本中的话题。由于国外的互联网发展早于国内,中文互联网也是从这个世纪才开始发展起来,因此中文舆情分析是伴随着互联网的发展才出现的。当今时代,水利舆情对社会生活的影响越来越大,利用舆情分析技术进行水利新闻情感分析的需求也越来越迫切。
2 情感分析技术的比较
2.1 基于词典的方法
基于词典的情感分析是通过分析文章中的情感词对文章做情感分析。词典方法通过规则来获取文章的情感信息,然后以情感词典中的情感词去判断文章的情感表达程度。这种做法就是建立情感词典过分依赖人工,并且不能根据词之间的联系进行情感分析。
2.2 基于机器学习的方法
随着机器学习的发展Pang[1]等人于2002年率先将机器学习的方法用到文本情感分析中,他们使用各种不同的机器学习分类器分别对从互联网上的抓取到的影评信息文本进行情感分析。实验结果表明,进行特征组合的机器学习算法得到的准确率高达82.9%。此后,研究者将研究重点放在特征组合上。Mullen和Collier[2]基于前人研究基础之上,通过更好的特征组合,使用SVM分类器进行文本情感分析,这种方式所使用的特征主要有词汇和互信息特征、主题相似特征和句法关系特征。但是机器学习的方式依赖于特征的组合[3],如果特征提取不好,最后分析结果也会不太合理。
2.3 基于深度学习的方法
2006年,Hinton等人提出了深度学习的概念,深度学习逐渐被应用到NLP中,并且在NLP方面取得了令人满意的进步。在对文本的编码方面。2013年,Tomas Mikolov[5]等人提出了Word2Vec,用于处理one-hot编码文本向量化后维度过高的问题。2015年,Zhu[6]等人提出采用LSTM将中文评论语句建模成词序列来解决情感分类问题,LSTM可以捕捉到评论语句中的长依赖关系,可以从整体上分析评论的情感语义。2019年,Raghavendra[7]使用BERT进行长文本编码时,采用了滑动窗口的方式分割长文本。文献[8]中Sun等人使用截断和分层的方式对长文本进行预处理,再使用BERT进行编码。近年各种词向量技术和深度学习算法不断涌现,但是大部分的研究都集中在短文本领域,对长文本进行合理向量化进行情感分类是一个值得研究的方向。
3 水利新闻情感分析的实现方案
3.1 实验环境
实验采取的环境见表1。
3.2 数据集制作
情感分类算法需要大量的数据来进行算法模型的训练,但是在水利舆情方面又没有专门的水利舆情数据,因此本文使用的数据来源于百度新闻和新浪新闻,直接抓取了与水利相关新闻的URL,在对具体新闻url进行内容抓取时,对URL进行了去重,以防止抓取到重复的新闻数据。在请求URL连接的时获取到的是页面代码和新闻内容混合在一起的信息,需要将新闻内容从这些杂乱的代码中提取出来,这里使用BeautifulSoup从爬取的网页信息中提取新闻标题和内容,然后把新闻内容保存下来。因为不同的新闻网站的页面结构是不一样的,因此需要写不同的新闻抓取代码来对应不同的新闻网站。在新闻抓取时为了提高爬取效率,使用了IP代理池技术防止单一IP爬取被禁止访问数据。获取的内容主要是新闻标题和文章内容。文章标题中通常蕴含了文章的关键信息和新闻的性质,因此文章标题也是必须获取的内容。后续通过算法对文章标题和内容的分析来判断文章具体情感内容。由于条件限制,本文一共抓取了1869条新闻数据,然后对数据集进行标注,分为负面新闻和正面新闻,负面新闻标为0,正面新闻标为1。然后将数据集分为训练集和测试集,对算法模型进行训练。
3.3 实现方案技术的选择
1)文本编码技术
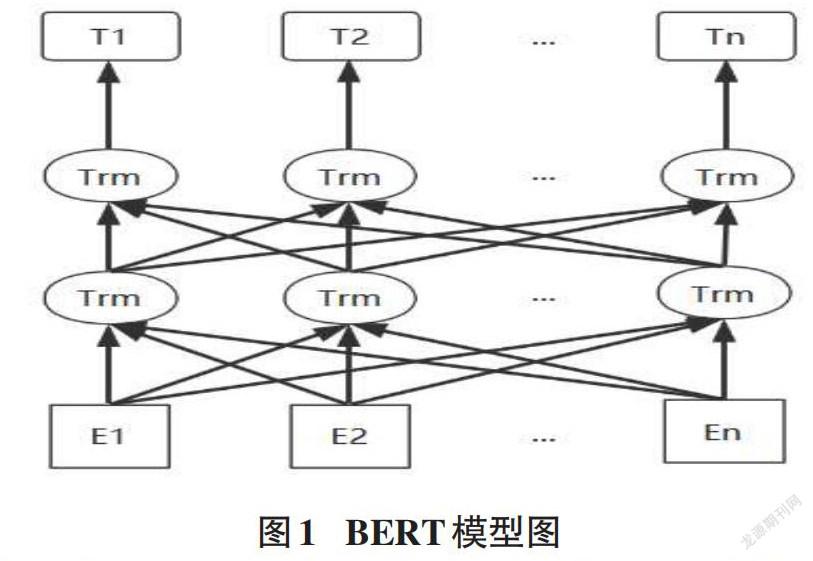
文本编码技术就是将新闻文本转化为文本向量。因為算法模型无法直接处理新闻文本,所以需要通过文本编码技术将新闻文本转化为文本向量输入算法模型中进行处理。One-Hot编码是一种常见的文本编码方式。它对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。在文本处理中就是将每个词作为一个特征进行编码。但是这样的编码形式无法表征语义信息,并且过多的特征也会使编码之后的文本向量维度非常高,造成维度灾难。Word2Vec是一种常用的文本编码模型,它在编码中可以考虑词语上下文之间的关系,维度比较少,速度也比较快,通用性很强,可以用在各种NLP任务中。但是它无法解决文章中一词多义的问题。BERT模型解决了一词多义的问题。BERT是谷歌AI部门的研究人员近年来新发布的文本预训练模型,在11种不同的NLP测试中创出最佳成绩,在NLP业引起巨大反响,认为是NLP领域里程碑式的进步。与最近的其他语言模型不同,BERT旨在联合调节所有层中的上下文来预先训练深度双向表示[9]。BERT可以通过一个额外的输出层进行微调,可以应用到大部分自然语言处理任务中,不需要针对具体的任务进行很大改动,BERT模型如图1所示。E63E06ED-28E4-4968-AF81-22528AF55FC4
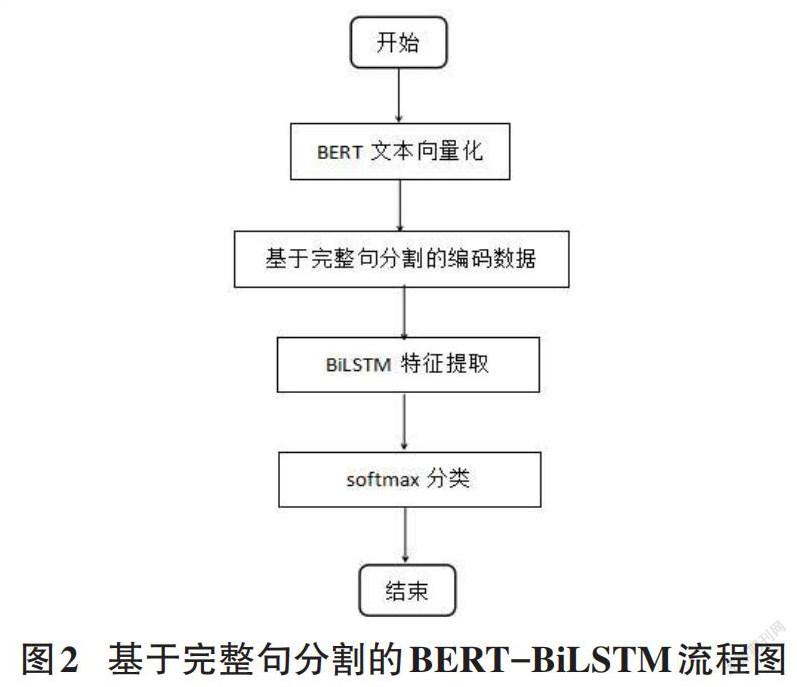
由于输入BERT中的文本长度最长为512,而有些新闻文本长度却超过了这个数字,文献[8]中的研究人员直接使用截断文本只保留512个文本或者以512为一段截成多段,但是这样会丢失数据或者破坏文本之间的关系。本文基于完整句分割的形式,在不超过512长度的基础之上每次分割出完整句,然后放入BERT进行编码,同新闻的多段编码之后拼接到一起。主要算法流程如图2所示。
2)深度学习算法
深度学习算法比较著名的是CNN卷积神经网络算法,在卷积神经网络中,网络的每一层都接收来自其前一层的输出作为其输入,并将其输出作为输入传递给下一层。一般的卷积神经网络中都会有输入层、卷积层、池化层、全连接层,最后是一个分类层进行分类。RNN(循环神经网络)的神经元接受的输入除了前一层网络的输出,还有自身的状态信息,其状态信息在网络中循环传递。但是RNN存在一个主要问题是梯度消失。因为神经网络的反向传播算法基于梯度下降的,也就是在目标的负梯度方向上对参数进行调整。如此一来就要对激活函数求梯度。又因为 RNN 存在循环结构,因此激活函数的梯度会乘上多次,这就导致:如果梯度小于1,那么随着层数增多,梯度快速减小,即发生了梯度消失(Gradient Vanishing);如果梯度大于1,那么随着层数增多,梯度更新将以指数形式膨胀,即发生梯度爆炸(Gradient Exploding)。LSTM是由RNN演化而来的。
长短期记忆模型(LSTM)继承了RNN处理文本序列模型的特点,在训练时能够控制梯度的收敛性,并在一定程度解决了梯度爆炸和梯度消失的问题,同时也能够保持长期的记忆性。为了更好地处理序列信息,研究者提出了双向长短期记忆网络(Bi-directional LSTM,BiLSTM)。BiLSTM模型相对于LSTM兼顾了上下文信息,可以提取文本中更深层次的语义信息。BiLSTM结构如图3所示。
3)激活函数
在使用BiLSTM进行文本特征提取后,需要使用分类器对文本特征进行分类,这里使用Softmax分类器进行分类。Softmax分类器就是将上层的输出通过Softmax函数映射成0到1范围内的值,所有映射结果的累计和为1。因为每一个映射的结果相当于分类成对应值的概率,就可以选择概率最大的值作为最终结果。Softmax函数又称归一化指数函数,函数表达式为:
Softmax函数本身针对多项分布提出,当类别数是2时,它退化为二项分布。由于Softmax函数先拉大了输入向量元素之间的差异(通过指数函数),然后才归一化为一个概率分布,在应用到分类问题时,使得各个类别的概率差异比较显著,最大值产生的概率更接近1,這样输出分布的形式更接近真实分布。所以这里使用Softmax进行分类。在使用BiLSTM提取了深层次的语义信息之后,将句子的特征向量输入到Softmax函数中,然后计算得到对应的结果。
3.4 算法评价准则
为验证模型的有效性,使用机器学习中比较常用的算法评价标准:准确率(Precision)、召回率(Recall)和F1值(F-Measure)来衡量[10],计算公式如式(2)~式(4)。
其中TP(True Positive)表示正面新闻预测为正面新闻的数量;FP(False Positive)表示负面新闻预测为正面新闻的数量;FN(False Negative)表示正面新闻预测为负面新闻的数量。之所以选择这个算法评价指标是因为在舆情分析中,负面新闻所占的比例是非常小的。如果把所有的水利新闻都预测成非负面新闻,那么准确率也是非常高的,这样的准确率是没有任何意义的。因此准确地将负面新闻识别出来才能说这个算法模型是合理的,所以在关注准确率的同时,也要关注召回率。而F1值可以同时考虑准确率和召回率,让两者同时达到最高,取得平衡。
4 对比实验
由于数据集条件的限制,这里采用了80%的新闻文章作为训练集,20%新闻文章作为测试集。为了展现提出的算法模型的优势,算法模型对照实验分别采取了BERT-LSTM、BERT-BiLSTM和本文提出的基于完整句分割的BERT-BiLSTM三种算法模型进行对比实验,实验结果数据如表2所示。
5 实验结果及分析
通过对比实验中的结果数据可以看出,基于完整句分割的BERT-BiLSTM模型相较于BERT-BiLSTM和BERT-LSTM的准确率和召回率更高,F1值也更高。
6 结束语
本文分析了目前情感分析算法的优劣,提出了基于完整句分割的BERT-BiLSTM新闻文本情感分析算法模型。算法模型首先基于完整句对新闻文本进行分割,然后使用BERT模型将新闻文本编码为文本向量,之后将文本向量输入到BiLSTM中进行文本特征提取,最终用Softmax对提取的文本特征向量分类得到结果数据。实验结果表明,本文提出的算法相较于之前的效果较好,但是由于数据来源较少,算法的整体识别率还有待提高,因此在后续工作中,可以增加数据并进一步优化算法以达到更好的效果。
参考文献:
[1] Pang B,Lee L,Vaithyanathan S.Thumbs up:sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 conference on Empirical methods in natural language processing - EMNLP '02.Not Known.Morristown,NJ,USA:Association for Computational Linguistics,2002.
[2] Zainuddin N,Selamat A.Sentiment analysis using Support Vector Machine[C]//2014 International Conference on Computer,Communications,and Control Technology (I4CT).September 2-4,2014,Langkawi,Malaysia.IEEE,2014:333-337.E63E06ED-28E4-4968-AF81-22528AF55FC4
[3] 陈龙,管子玉,何金红,等.情感分类研究进展[J].计算机研究与发展,2017,54(6):1150-1170.
[4] Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18(7):1527-1554.
[5] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems. 2013: 3111-3119.
[6] Zhu X D,Sobhani P,Guo H Y.Long short-term memory over recursive structures[C]//ICML'15:Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37.2015:1604-1612.
[7] Pappagari R,Zelasko P,Villalba J,et al.Hierarchical transformers for long document classification[C]//2019 IEEE Automatic Speech Recognition and Understanding Workshop.December 14-18,2019,Singapore.IEEE,2019:838-844.
[8] Sun C,Qiu X P,Xu Y G,et al.How to fine-tune BERT for text classification?[C]//Chinese Computational Linguistics,2019.
[9] 劉思琴,冯胥睿瑞.基于BERT的文本情感分析[J].信息安全研究,2020,6(3):220-227.
[10] 陈才.NLP技术在农业舆情分析系统中的应用研究[D].北京:北京工业大学,2019.
【通联编辑:唐一东】E63E06ED-28E4-4968-AF81-22528AF55FC4
猜你喜欢
电脑知识与技术(2017年3期)2017-03-27
智能计算机与应用(2017年1期)2017-03-23
计算机应用(2016年12期)2017-01-13
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
