
基于大数据分析的县域油茶产业经济发展规划分析工具设计
2022-07-03 06:04朱碧琴
中国新技术新产品 2022年6期
陆 珊 朱碧琴
(湖南环境生物职业技术学院,湖南 衡阳 421001)
0 引言
油茶作为一种木本油料,主要生长在我国南方,在鼓励政策的扶持下,我国几个油茶产区的发展均较为迅速。加上农业科技辅助,集中量产和定产都具有其一定的优势。油茶种植又带动了周边产业的发展,形成了油茶种植、加工、销售等产业链条,有效带动了农村经济的发展。规模化的油茶产业不但形成了辐射周边的油茶经济圈,而且可以带动旅游、环保等相关产业,打造成具有浓郁乡土气息的油茶经济带,造福一方。虽然油茶经济具有若干的优势,但是并不一定适合全国各地,而且盲目地建设新项目,存在较大的风险,需要专业的团队进行细致地调研,提出科学建议。为了深入地分析,科学地评判,大数据分析是一种实用、对路的好工具。大数据分析是建立在海量数据基础上的分析与评判,兼顾了同业数据、周边数据、历史数据、成功案例、失败教训等多方面信息,以特定的运算规则进行深度计算,得出建立在充分数据基础上的可信数据,是一种广泛应用的尖端科技成果。将大数据分析应用于油茶产业的经济发展规划,可以深度挖掘历史数据,同时汇总类似产地经验,并在该基础上得出方向性的建议。大数据分析技术代替了农业专家的调研职能,有助于农业经济发展。
1 基于大数据分析的县域油茶产业经济发展规划分析工具设计
1.1 获取县域油茶产业大数据
互联网信息包罗万象,其中关于县域油茶产业的相关信息才是大数据处理分析的有用信息,需要进行删选和甄别。该文将大数据分为传统数据、感知数据和网络数据。。在传统的规划发展中,传统数据作为数据集合的主力军,其优势为在时间和空间2 个方面非常准确地表现出一定区域的特点,但是该优势在实际操作中体现得并不充分。对空间布局说,还要讲求视觉审美以及空间构造。数据缺乏人的行动能力和空间构造能力。那么,对这种比较灵活的规划来说,人的影响因素也是必须要考虑的一部分。
考虑到数据分析计算中所使用的油茶产业数据的完整度和准确度,在其产量因素的数据收集时,主要采用的是2017—2021 年浙江、江西、广东、湖南等几个省份的油茶生产数据。经过整理发现,从2017—2021 年,这几个省份的油茶产量占全国总产量的绝大部分,因此对这些地区和时间段数据的分析具有代表性,可以真实地反映出县域油茶产业经济发展的状况和趋势。为了能够综合评价油茶产业经济的增长潜力,在数据对象中增加了影响经济增长规模的油茶产量数据、种植面积、疏林地、灌木林地等数据,以便从多个角度统计数据,对油茶产量影响因素进行定量分析。
充足的林地资源是保障油茶产业发展的基础,因此针对油茶产业的研究,有针对性地选择森林资源丰富的省份。根据《中国林业统计年鉴》,油茶林地资源情况汇总于表1。

表1 县域油茶林地资源表(单位:hm2)
在该研究中,影响生产的因素一般分为2 类,其中,基本的影响因素主要有自然资源、地理位置、气候等对生产场合发生影响的因素;此外,人文环境也会对油茶产业经济发展造成影响,是潜在的重要影响因素,例如县域基础公共设施、农业专家的技术支持、地区平均收入水平等,这些因素都会直接或间接,地作用于油茶产业的发展状况。因此在核定大数据处理的信息范围时,需要充分地采集各方面信息,形成多维度、多角度、丰富的数据处理基础。
1.2 建立基于大数据的计算功能模块
完成数据采集后,核心功能是对这些数据按照设计的算法进行计算。计算功能模块如图1 所示。

图1 计算功能模块流程图
数据录入是分析处理的基础环节,在上一步确定的数据采集范围内,设置相应的数据导入接口,有序调用数据。鉴于多地域历年数据存在形式不统一,数据库繁杂的情况,需要在数据录入环节设计两种接口:针对历史孤立数据的文件导入接口;针对网络标准数据的平台数据调用接口。数据通过录入环节进入大数据分析处理的统一数据库中,实现了数据准备,下一步需要对数据进行处理。分析过程分为预处理和处理2 个环节。其中预处理的目的是在纷杂的海量数据中发现有用的数据,即去伪存真的过程;处理则是对有用的数据按照特定的算法运算,找到其中的规律性内容。
数据预处理采用聚类算法,如公式(1)所示。

式中:为聚类中偏离量;为聚类所有数据的均值;为样本欧氏距离;为该聚类的中心;为样本数量。
算法流程如下:对所有数据类型分类处理;针对每类计算其平均值;用该平均值替换各聚类中心的数值;在限定迭代次数内重复计算,如果该计算结果与聚类中心的值差小于设定阈值,则终止计算并储存结果,否则继续计算。数据预处理后,形成了缩减后的数据集合。这些数据集合从不同的方面体现了油茶产业经济发展的特点与趋势,作为后续分析提炼的基础,因此需要按照设计的格式与顺序储存,以便后续调用。为保证数据集合的有效性,需要对数据的空位、唯一性和组合关系进行检查,保证数据正确。空位检查主要是检查在一组数据中心,是否有某一个属性数据的数值是无效的,如果出现了空位,就会自动填充。唯一性检查是检查这组数据的属性是不是唯一的,如果同组数据中有不同属性的数据,那么会自动清除,并补充一个具有相同属性的数据。组合关系检查的工作主要在于对空间化的数据进行关系检测,侦测数据前的链接是不是符合软件的计算标准。完成数据有效性检查后,即进入核心的数据分析处理环节。数据处理主要依靠面板模型。经过检验方式选取最恰当的计算方式。
检验方式如公式(2)所示。

式中:P为第种影响因素的影响效果;x为该因素的发生概率;λ为该因素影响效果的加权因子;n代表该因素的影响频次;γ代表该因素的影响因子;代表影响因素的总数量,即有效数据集合的总数。
通过计算每种影响因素所形成的的影响效果,加之影响因子的正向或负向定义,综合考虑了各参与因素对发展规划的作用与影响,形成具有综合指导意义的影响效果集合{P},在该集合中代入待规划县的现实数据,并对各影响因素的结果按照降序排列,即可得到大数据计算结果。
1.3 精细优化策略工具箱实现规划分析
上步获得的计算结果是建立在同业县的历史数据基础上的分析判断结果,直接用于指导待规划县的未来发展状况有失偏颇,需要对数据进行动态修正。建立精细优化策略工具箱为大数据算法提供参考。精细优化工具箱是一个纽带,它将遇到的问题、中期的分析以及所采取的应对措施连接为一个整体。优化策略工具箱有4 种功能:初期数据分析、数据库提取、数值评价与策略优化。其中初期数据分析是对问题进行数据挖掘,分析角度设定为对油茶产量的4 个基本要素,从主要方面到次要方面,从属性到数量进行全方位分析,包括设定位置林地的面积、空间形态以及土质状态。针对一个地方的优化策略,由于基础不同,其初期对应的问题不尽相同,因此必须进行优化。
在数据库提取的工作过程中,初期的问题分析已经将方案问题属性传送过来,根据当前的数据库储存量,从数据库中选择足够解决问题的相对应数据,并提取出来,打包送往下一部分处理。前文提及关于县域油茶的数据,主要分为传统数据、感知数据和网络数据。传统数据主体为各县统计部门的历史记录,以及农业部门的档案信息;感知数据主体为通过调查、收集整理到的样本量数据,是调查取样和走访获取到的相关产业的运营数据,需要经过分析整理才能使用;网络数据主要为相关产业线上销售的关联数据,以及客户的评价信息。为了提高分析结果的精准性,需要不断完善数据库。
在评价环节中,针对县域油茶产业进行分析。工具箱最终给出的评估内容主要包括林地选址、劳动力规划、交通情况、气候条件以及产品供需关系等。在该环节中,通过对比其他省市县级单位的油茶产业数据,查找本县的实现情况与成功案例之间的差异,并在结果中对差异点逐项进行对比,在该县开展油茶生产,以及相关配套产业的开发中,有多少资源可以联合利用,又有什么方面会形成冲突,造成该县的油茶产业不利的发展条件,都在评价环节中综合评判。并且,任何事情不是一成不变的,在历史时期能够促进油茶产业发展的要素中的数据时利好要素,相关的行业背景、市场饱和度都会对判断结果产生影响。因此,需要在判断与评价中,充分利用大数据分析的全面性,结合各方面要素,并对该县的实际情况各项背景信息加权处理,留出适当的裕度,使评价结果在限定的合理区间内具有自由度,评价结果才有现实意义。最后,在显示端给出具体的结果评估文件,正式提出优化策略。经过大数据采集准备、数据计算分析和策略修正,完成了县域油茶产业经济发展规划分析,取得了结合该县实际情况的油茶产业经济发展规划建议,完成了发展规划分析。
2 对比试验
2.1 试验准备
为了证明所设计的县域油茶产业经济发展规划分析工具能够计算出正确的结果,对县域经济发展起到推动作用,通过代入实际数据加以验证。
历史数据集如公式(3)所示。

本县油茶产业的对应数据集如公式(4)所示。

残差数列如公式(5)所示。


则绝对关联度如公式(6)所示。

相对误差序列如公式(7)所示。
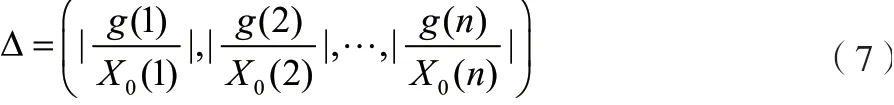
式中:() 代表第项数据的原始值。
小误差概率如公式(8)所示。

式中:代表计算过程。
均方差比值如公式(9)所示。

式中:是原始数列的方差,是残差数列的方差。当上述参数数值都>0 且<表2 中的数据时,则分析工具的结果收敛,具有指导意义。

表2 精度参照表
设置该文的分析工具为实验组,传统分析方法为对照组,从表1 中随机抽取数据进行对比计算。
2.2 试验结果
对照组和试验组的三次精度计算结果见表3。
由表3 可知,试验组的三次计算结果精度等级都是1,并且其4 项参数的数值都比对照组的参数值更优秀。证明所设计的基于大数据的县域油茶产业经济发展规划分析工具在计算中形成了收敛的计算结果,与真实情况更为接近,表明该方法所分析的经济发展规划更符合实际情况,对规划的预测是有效的。

表3 试验结果表
3 结语
县级单位作为我国经济发展的基层单元,面临着资源少、特色不明显、外部竞争激烈等很多难题,因此,在经济发展的规划中常常受到许多因素制约。通过采用先进的技术手段,对自身条件进行精准地分析,同时借鉴同等级其他县城的成功经验或失败原因,可以少走弯路,更快速地带领全县人民脱贫致富。大数据分析处理技术作为一种新型的网络化分析模式,具有强大的运算功能,能够在海量数据中逐一排查并发现有价值信息,并通过设计合理的计算模型,方便快捷地找到复杂问题的解决途径,有助于助力地区经济的发展,形成别具一格的经济发展路径。该文从油茶产业经济的角度尝试了大数据分析的规划指引能力,实现了第一阶段的目标。后续还将深入研究,寻找更为准确的算法模型,并将其应用于地区发展的其他领域,指导规划发展决策,为科学策划提供一种高技术工具。
猜你喜欢
领导决策信息(2018年50期)2018-02-22
现代园艺(2017年21期)2018-01-03
现代园艺(2017年21期)2018-01-03
中国西部(2017年4期)2017-04-26
湖南农业(2017年1期)2017-03-20
中国卫生(2016年2期)2016-11-12
中国工程咨询(2016年4期)2016-02-14
中国卫生(2015年7期)2015-11-08
基础教育(2014年3期)2014-04-16
