
部分线性工具变量模型中有效工具变量识别及应用研究
2022-07-07 07:36赵培信肖仕维李庆
应用数学 2022年3期
赵培信, 肖仕维, 李庆
(1.重庆工商大学数学与统计学院, 重庆 400067;2.经济社会应用统计重庆市重点实验室, 重庆 400067)
1.引言
部分线性模型既含有参数分量又含有非参数分量, 具有较强的数据适应性.目前该模型已被广泛应于社会经济, 生物医学及环境工程等各个领域.具体地, 部分线性模型具有如下结构:

其中β = (β1,··· ,βp)T为p维未知的参数向量, g(t)为未知的光滑函数, X和t为协变量, Y 为对应的响应变量, ε为零均值的模型误差.当X为外生协变量, 即协变量X与模型误差ε相互独立时, 基于两阶段最小二乘方法可以得到模型参数β的相合估计.但当X为内生协变量,即X与ε存在较强的相关性时, 基于两阶段最小二乘方法对β估计将不再是相合的, 而产生一定的内生性偏差.基于工具变量调整技术则可以给出β一个相合估计.具体地, 假定X为内生协变量且满足

其中Z为q维工具变量, Γ为p×q维的未知参数矩阵, e为模型误差.
近年来对基于工具变量调整的统计推断理论已有大量文献进行了研究.比如CAI和XIONG[1]研究了部分变系数工具变量模型的估计问题, 并提出了一种三阶段估计方法.ZHAO和LI[2]研究了变系数工具变量模型的变量选择问题, 并提出了一种基于光滑门限估计方程的变量选择方法.FAN和LIAO[3]则对高维的线性工具变量模型进行了研究, 并提出了一种基于惩罚的广义矩估计方法.关于工具变量模型的更多最新研究参见文[4-8].
基于工具变量的统计推断过程中, 选取有效的工具变量是进行统计推断的关键, 但是上述文献均是在假定已知有效工具变量的前提下, 研究模型参数的统计推断问题.而如何选取有效的工具变量并没有进行研究.关于有效工具变量的识别问题, 目前研究的文献不是太多.而在实际的回归建模过程中往往需要从大量的指标中选取某些指标作为有效工具变量, 因此对有效工具变量的识别成为内生协变量回归建模研究中一个重要的课题.基于此, 本文在X为内生协变量, 并且在线性模型结构(1.1)和(1.2)下, 研究工具变量Z的识别问题.
本文通过构造一个辅助回归模型, 结合惩罚估计技术, 对模型结构(1.1)和(1.2)中的有效工具变量给出一种识别方法.数据模拟研究表明所提出的有效工具变量识别方法行之有效.本文所提出的有效工具变量识别方法允许采集的数据含有部分异常值, 因此所提出的识别方法具有较好的稳健性.另外, 尽管LIU等[7]也考虑了部分线性工具变量模型中有效工具变量的识别问题, 但该文是在假定协变量X 和t相互独立的条件下提出了一种工具变量识别方法.而在实际应用中, 假定协变量X和t相互独立往往是不切实际且不易验证的.本文提出的有效工具变量识别方法不需要X和t相互独立这一条件, 而是允许二者存在相关性.因此, 本文提出的有效工具变量识别方法是对LIU等[7]所提方法的一种有效改进, 并且两种方法在模型假定上存在本质的区别.最后, 作为应用, 利用本文所提出的方法对中国大陆地区对外贸易开放与经济增长的关系进行了实证分析.研究结果表明在处理贸易开放度的内生性问题上, 各地区的国外市场接近度是一个行之有效的工具变量, 并且发现对外贸易开放对经济增长有显著的推动作用.
2.有效工具变量识别及模型估计过程
对(1.1)求条件期望可得E(Y|t)=E(X|t)Tβ+g(t), 进而可得
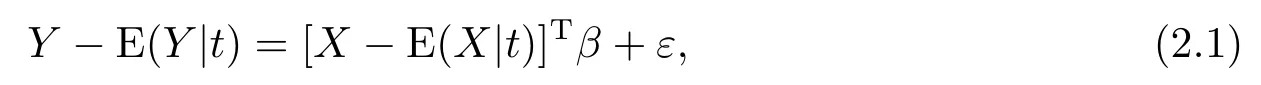

记Zk为工具变量Z =(Z1,··· ,Zq)T的第k个分量, 注意到E(ε|Z)=0, 则结合(2.2)式可得


3.迭代计算
在这一节, 考虑工具变量识别以及模型参数估计方法的迭代计算问题.首先讨论最小化目标函数Q(θ)的计算方法.结合ZOU和LI[12]提出的线性逼近方法, (2.5)式中的惩罚函数pλ(|θk|)可以渐近表示为

注意到(3.3)式为经典的最小一乘估计目标函数, 因此可以通过已有的统计软件(如R软件、SPSS软件等)进行求解.另外在求解(3.3)式的过程中, 调整参数λ需要指定, 并且参数向量θ需要给出一个初始估计.首先我们可以通过最小化如下不带惩罚项的绝对偏差目标函数来得到θ的一个初始估计

另外类似文[13], 本文建议用BIC准则对调整参数λ估计.具体地, 我们通过最小化如下BIC准则函数来得到λ的估计.
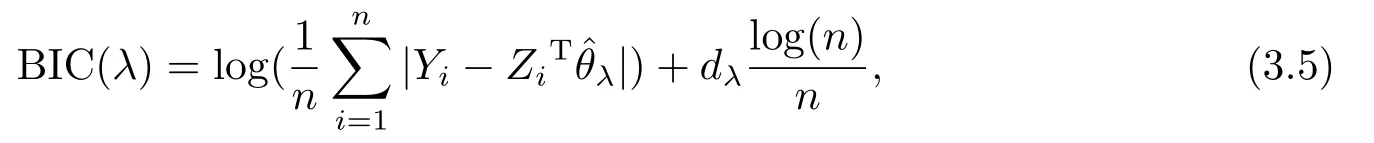
其中dλ表示中非零元素的个数.在实际应用中, 我们可以通过格子点法来求解(3.5)式.具体地讲, 我们在一个相对较大的闭区间, 比如在区间[0,5]上以步长0.01取均匀的格子点, 并在每一个格子点上通过(3.5)式计算BIC的值, 那么最小的BIC值对应的格子点则为所选择的最优调整参数λ.
接下来, 我们给出有效工具变量识别以及模型参数估计过程的具体迭代算法如下:
第1步 最小化(3.4)式得初始估计量θ0;
第3步 利用有效工具变量Z∗, 并结合(2.6)式给出内生协变量X的工具变量调整形式X∗=;
第4步 基于工具变量调整后的协变量X∗, 并利用最小化(2.7)式给出模型参数β的稳健估计, 并基于核估计法给出非参数函数g(t)的估计(t).
4.数值模拟研究
为实施模拟, 我们从如下模型产生数据
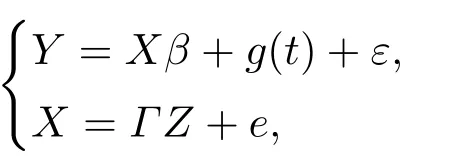
其中Γ = (3,1.5,1,0.5,0,··· ,0)为1×10维参数矩阵, β = 2, g(t) = sin(2πt), 对应的工具变量Zk∼N(1,1.5), k = 1,··· ,10.由Γ的前三个元素非零, 其他元素均为零可知Z1, Z2和Z3为三个有效的工具变量, 而Z4,··· ,Z10均为无效工具变量.协变量t由区间[0,1]上的均匀分布产生, 响应变量Y 以及内生协变量X均由模型产生, 其中模型误差ε ∼N(0,0.5)并且e = 0.5ε.该数据产生方法保证了E(Xε)0, 即X为内生协变量.在模拟过程中, 样本容量n分别取200,400和600 三种情况, 惩罚函数pλ(·)分别取Lasso惩罚[9], SCAD惩罚[10]以及Adaptive-Lasso惩罚[14]三种情况.另外为验证本文所提出方法的稳健性, 对样本容量的每一种情况, 我们对响应变量Y 和内生协变量X人为设置部分异常点.在模拟过程中, 我们考虑异常值占数据的10%和20% 两种情况.对每一种情况, 异常值通过模型误差取为ε ∼N(0,3)进行产生.
关于有效工具变量识别的模拟结果见表4.1和表4.2, 其中“C”表示基于1000次重复实验把真实无效工具变量正确估计为无效工具变量的平均个数, “I”表示基于1000次重复实验把真实有效工具变量错误估计为无效工具变量的平均个数.另外, 表4.1和表4.2还给出了选择有效工具变量的错误选择率(FSR), 其定义为FSR=IN/TN, 其中IN表示基于1000次重复实验把无效工具变量估计为有效工具变量的平均个数, TN表示基于1000次重复实验选择为有效工具变量的平均个数.由表4.1 和表4.2, 我们可以得到如下结论:

表4.1 异常值占10%时,基于不同惩罚函数选择有效工具变量的结果

表4.2 异常值占20%时,基于不同惩罚函数选择有效工具变量的结果
(i)随着样本量n的增加, 基于三种惩罚方法的有效工具变量错误识别率均逐渐趋于0, 并且对无效工具变量的识别也逐渐趋于无效工具变量的实际个数6.这表明本文提出的有效工具变量的选择方法是行之有效的;
(ii)对任意给定的样本量n, 在不同异常值数量下的模拟结果是类似的, 即异常值对模拟结果没有明显的影响.这表明本文提出的工具变量选择方法具有较好的稳健性;
(iii)对任意给定的样本量n, 基于Lasso, Adaptive-Lasso和SCAD三种惩罚方法所得出的模拟结果也是类似的.
接下来我们给出关于模型参数β的模拟结果.因此在接下来的模拟过程中, 用Lasso惩罚选择有效工具变量, 其他情况下的模拟结果是类似的, 为此我们不再重复展示.另外作为比较, 我们还给出了关于β的朴素(naive)估计结果, 即不经过工具变量调整, 直接利用内生协变量X并通过最小化目标函数来得到β的估计.
基于1000次重复实验, 图4.1和图4.2给出了估计绝对偏差||在各种样本量情况下的箱线图(Box-plot), 其中“AE”表示本文提出的基于工具变量调整的估计方法所给出的模拟结果,“NE”表示基于朴素(naive)估计过程所给出的模拟结果.由图4.1和图4.2可以看出, 随着样本量的增加, 基于本文提出的方法所给出的绝对偏差逐渐减小, 而基于朴素(naive)估计过程给出的绝对偏差即使n增加时仍相对较大.这就表明忽略协变量内生性的朴素估计过程将会产生一定的估计偏差, 而本文提出的工具变量调整的估计过程可以有效地消除协变量内生性的影响, 从而给出了模型参数的相合估计.另外, 我们还可以看出对任意给定的样本量n, 在不同异常值数量下, 基于本文提出方法的模拟结果是类似的.这表明本文提出的基于工具变量调整的估计方法对模型参数的估计同样具有较好的稳健性.
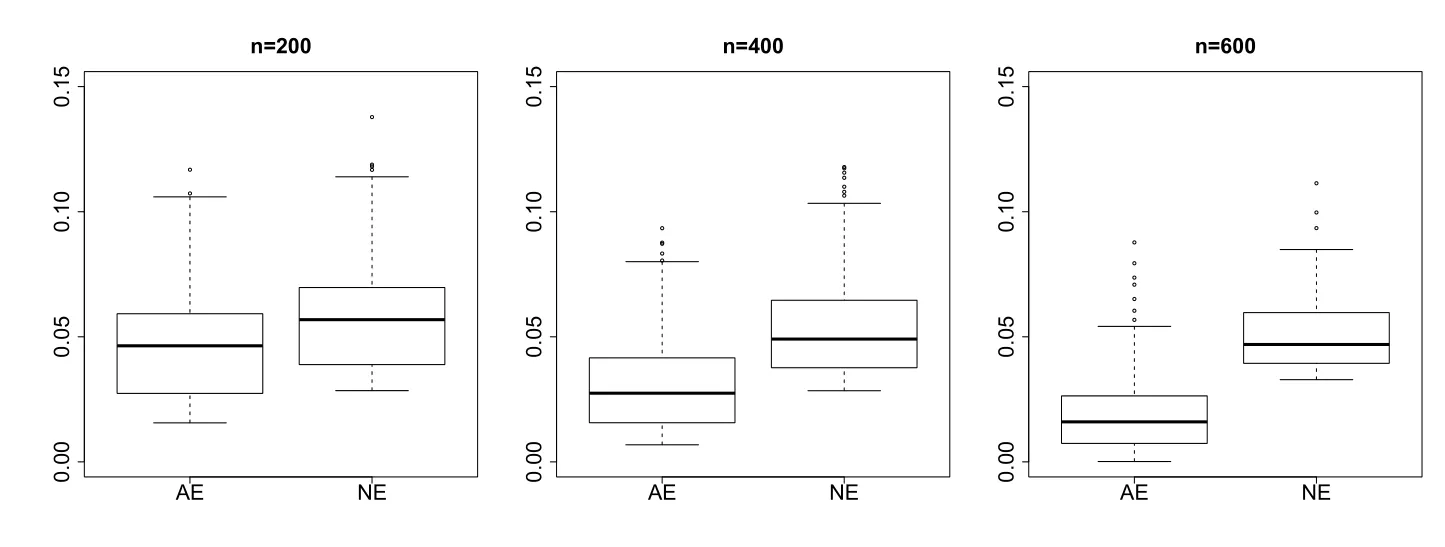
图4.1 异常值占10%时, 模型参数β估计量绝对偏差的箱线图

图4.2 异常值占20%时, 模型参数β估计量绝对偏差的箱线图
另外图4.3给出了在样本量n=400, 异常值占20%时的情况下, 非参数函数估计ˆg(t)的模拟结果, 其中点虚线为没经过工具变量调整的naive估计结果, 长虚线为基于本文方法有效工具变量调整后的估计结果, 实线为真实曲线.从图4.3可以看出基于本文的工具变量调整方法给出的估计曲线非常接近于真实曲线, 而基于naive过程的估计曲线则有相对较大的偏差.这主要是因为基于naive过程对参数分量β的估计是有偏估计, 从而导致对g(t)的估计也产生较大的偏差.
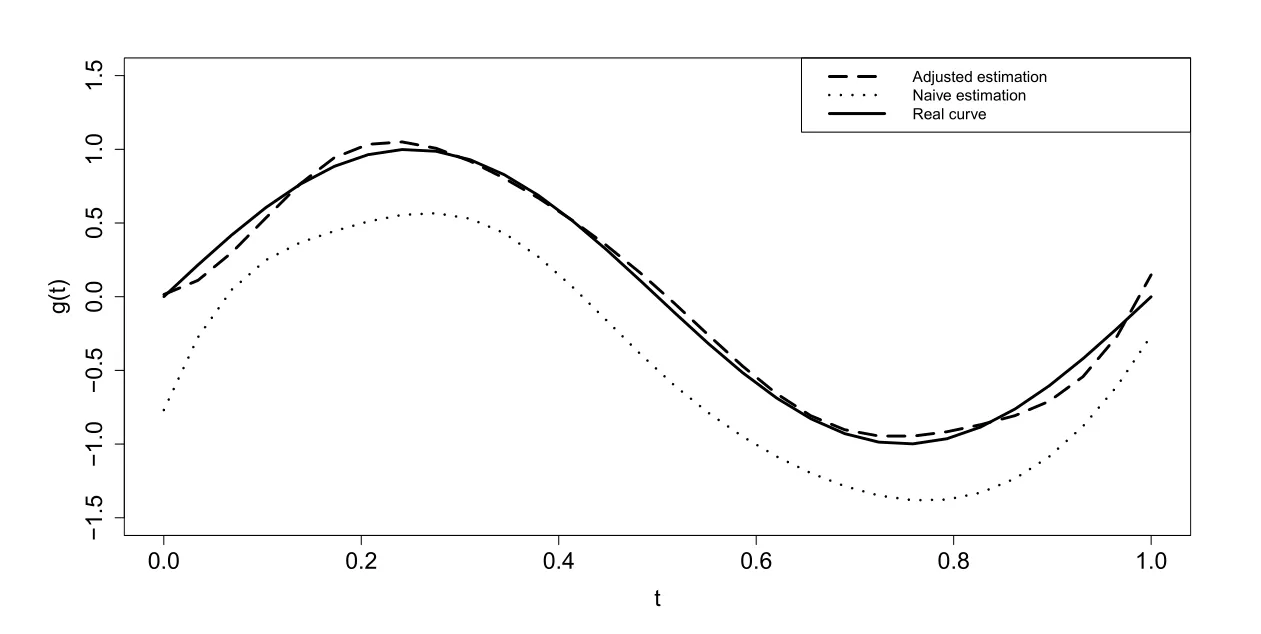
图4.3 样本量n=400, 异常值占20%时, 非参数函数g(t)的估计曲线
5.实际案例分析
本文基于中国大陆地区31个省, 自治区和直辖市2010–2019年的各省相关数据, 对贸易开放度与中国经济增长的关系进行实证分析研究.本文所涉及的数据均来自国家统计局网站《中国统计年鉴》.首先, 参考已有文献, 我们对各变量的设定和对应数据的计算方法进行简单说明.响应变量Y:采用以2009年为基期, 各省, 自治区和直辖市的实际GDP来代表各省, 自治区和直辖市的经济发展水平.协变量X: 采用各省, 自治区和直辖市的进出口总额与该地区生产总值的比值来衡量各省, 自治区和直辖市的对外贸易开放度.另外我们从就业, 教育和地理位置三个方面选择三个指标作为工具变量.具体地, Z1表示各省, 自治区和直辖市与国外市场的接近度, 类似文[15], 其计算方法为各省, 自治区和直辖市省会城市到海岸线距离的倒数(乘100倍)乘以人民币对美元的名义汇率; Z2表示各省, 自治区和直辖市的年底从业人员数;Z3表示各省, 自治区和直辖市的人力资本存量, 其用各省6岁及以上人口的平均受教育年限来衡量.因此, 可建立模型为
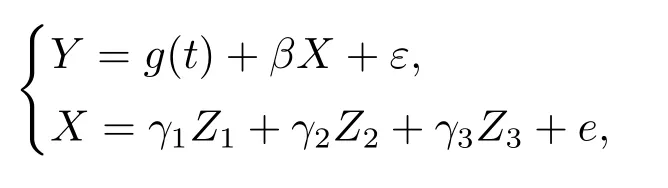
其中t表示年份.
在接下来的模拟过程中, 惩罚函数仍考虑SCAD惩罚, Lasso惩罚以及Adaptive- Lasso惩罚三种情况, 并对所有数据进行自然对数变换.关于有效工具变量识别的模拟结果见表5.1.从表5.1可以看出, 基于三种处罚方法给出的模拟结果是非常类似的, 这也进一步验证了上一节数值模拟得出结论.并且从系数γ1的估计值不为零, 而系数γ2和γ3的估计值均为零可知“Z1: 国外市场接近度”为识别出的有效工具变量, 而“Z2: 从业人员数”和“ Z3: 人力资本存量”则为无效工具变量.

表5.1 基于不同惩罚方法系数γ1 −γ3的估计结果
对参数分量β的估计, 我们同时给出基于工具变量调整的估计(AE)以及未经过工具变量调整的朴素估计(NE), 具体模拟结果见表5.2.由表5.2可以看出,对β的估计, 基于工具变量调整给出的估计值大于未经过工具变量调整的估计值.这就表明对外贸易开放度对当地的经济增长存在显著的正影响效应, 并且如果忽略对外贸易开放度的内生性, 则会低估外贸易开放度在经济增长中发挥的作用.
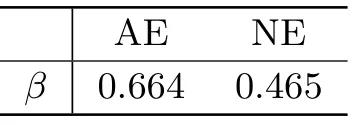
表5.2 参数分量β的估计结果
图5.1给出了基于本文所提出的方法对非参数函数g(t)的估计曲线, 该曲线反映了我国GDP随着时间的变化趋势.从图5.1可以看出2010年以来我国的GDP是逐年增长的,但2016年以后增长速度有所放缓.

图5.1 非参数函数g(t)的估计曲线
研究结果表明在处理贸易开放度的内生性问题上, 各地区的国外市场接近度是一个行之有效的工具变量, 并且发现对外贸易开放对经济增长有着显著的推动作用.目前我国正处在改革开放的攻坚期和深水区, 全球性市场, 技术和资源等要素的竞争日趋激烈.因此, 在“一带一路”的倡议下, 各省, 自治区和直辖市需要全方位, 宽领域地实行对外贸易的开放, 积极地推进对外贸易的发展.
猜你喜欢
临床肝胆病杂志(2022年6期)2022-11-25
心理学报(2022年10期)2022-10-12
中国循证心血管医学杂志(2022年1期)2022-03-15
今日农业(2021年14期)2021-11-25
西南林业大学学报(2021年5期)2021-10-21
意林(2020年10期)2020-06-01
小读者(2020年2期)2020-03-12
阅读(快乐英语高年级)(2019年11期)2019-09-10
证券市场红周刊(2018年5期)2018-05-14
学苑创造·A版(2015年6期)2015-07-01
