
基于LightGBM信贷风控模型的算法优化
2022-07-12 14:04吴照明胡西川
计算机应用与软件 2022年6期
吴照明 胡西川
1(上海海事大学信息工程学院 上海 201306) 2(上海海事大学信息工程学院计算机系 上海 201306)
0 引 言
互联网金融是一种由于当今网络的快速发展以及人们日益新潮的消费观念而诞生的新颖金融模式。其将互联网作为货币流通的媒介,获得了越来越多金融机构的青睐。广大金融机构开始搭建网络借贷平台,在全球兴起互联网借贷的浪潮。对于广大金融机构而言,新的商机也就意味着要面对新的挑战。要想在这一领域保持强劲的竞争力,获得实质性的发展,提升信贷风控能力、规避风险、降低损失显得尤为重要。
我国互联网金融发展状况呈现如下三个基本特点:
(1) 互联网金融规模逐渐扩大。以P2P网络借贷平台为例,最早的P2P是2005年3月成立于英国的Zope网站,后来如雨后春笋一样在全球迅速兴起。我国的第一家P2P网络借贷平台成立于2007年,在最初的应用后快速发展。由网贷之家发布的数据可知,截至2019年底,我国P2P网贷行业正常运营平台数量达到了342家,全年P2P网贷行业成交量达到了9 649.11亿[1]。
(2) 互联网金融的结构逐渐完善。目前我国的互联网金融已经形成三类参与机构互相合作、互利共赢的融合体系。即传统金融机构的互联网化、互联网巨头的金融业务输出、科技企业对金融机构的科技服务。
(3) 互联网金融子市场逐渐形成。在进入2019年后,互联网金融的宏观经济、监管环境与行业经营方面均得到改善。其外部环境压力显著减小,使得部分细分领域及机构得到了发展的空间,如中小金融机构、银行科技子公司、互联网巨头旗下的金融产业等。互联网金融子市场的形成已经无法阻拦。
如今,互联网金融行业的规模日益增大,相关的理财产品和服务层出不穷,但随之而来的不仅仅是机遇,更有挑战。
互联网金融行业的风险大致可以分为三种:(1) 由于互联网的虚拟性带来的风险。网络借贷平台不能像银行一样有借贷人非常准确的信息,借贷人可能会给予虚假的信息,影响平台的还贷率。(2) 由于互联网的传播性带来的风险。如果互联网金融机构出现了一点负面消息,就会被互联网无限地放大,导致无法进行及时的补救措施。如2019年10月16日,湖南24家网贷机构因不符合政府有关规定被予以取缔,导致当地其他的网贷机构纷纷被列入观察名单。(3) 由于互联网的技术性带来的风险。互联网金融无法像传统金融有着完善的法律体系来保护。它更多的是需要用技术来建立一个稳固的数据防火墙和高效合理的风控体系,毕竟互联网金融大部分业务都是以互联网作为媒介,需要更多的技术支持。一旦技术环节出现了问题,就会造成大规模的瘫痪,使得金融机构受到巨大的损失。如2018年6月27日,由于阿里云的一次宕机,导致数个如优酷、蚂蚁金服和飞猪等事业群停机了约1个小时,带来了巨大的损失。
由于技术性带来的风险最大,使得互联网金融风控模型研究在学界和业界受到高度重视。赵明明[2]提出一种基于核密度的K-Means算法,结合MapReduce分布式架构,在分布式下将聚类结果通过用户ID编号进行标签还原,并以标签的形式描绘出用户画像,将用户分成不同的群体类别。赵慧娟[3]对Apriori算法进行改进,重新定义一种类似于矩阵加法的数据存储方式,针对生成候选项集的连接步骤进行优化,以避免产生更多无效的候选项集,提高了算法效率。黎宁[4]采用归纳演绎法和案例研究法对国内互联网金融领域的金融信贷大数据风控技术进行研究。臧嘉惠[5]针对百度金融存在的问题,提出了推动社会征信体系建设完善、重视对培训机构的审核约束、加强行业监管或第三方监管、多方面提高员工的风险意识四个解决对策。李子木[6]用Spark并行大数据处理系统作为分析数据环境为金融企业提供金融风险控制机制。Peter等[7]采用基于具有时变参数的多变量隐马尔可夫模型,对金融企业的财务收益均值和协方差进行多周期预测,根据数据的动态变化实时改变预测值的大小,可以有效地帮助企业规避风险。Ari等[8]提出了一个结合切尔诺夫约束的方法,降低漂移检测(FIMT-DD)算法的标准偏差值,提高其快速增量模型树的准确率。从而增强FIMT-DD算法对数据进行分类预测的功能。Ivan等[9]将一个基于Java语言的数据挖掘软件——Xelopes作为实验平台,对朴素贝叶斯分类算法进行并行计算,以此来提升算法的高效并行化和扩展性。
结合上述算法优化的研究可以看出,在大规模数据集下,需要用数据切分的方式解决由于数据庞大导致的预测不准问题,其对于数据筛选和特征衍生具有一定的启发作用。虽然K-Means算法、Apriori算法、FIMT-DD算法、Spark通过优化之后能够消除掉一些无效的数据,提升预测的准确率,但是会带来内存消耗过多、处理大规模数据时速度减慢等问题。而根据数据动态变化实时预测和对算法进行并行运算虽然提高了准确率,加快了处理大数据时的速度,但是不仅没有降低内存消耗,反而大大增加了处理器的负担。LightGBM算法不仅能在提升预测准确率的同时,提升处理速度,还能占用较少的内存,释放更多的资源。
1 风控模型设计
1.1 LightGBM算法原理
LightGBM是一种新的Boosting框架,基本原理与XGBoost一样,使用基于学习算法的决策树,但是它基于Histogram算法实现。Histogram算法的优势有两个,第一个是它只需要#data×#feature×1Bytes的内存消耗,仅为XGBoost中exact算法的1/8。因为histogram算法仅需要存储featurebin value(离散化后的数值),不需要原始的数值,也不用排序,而binvalue一般用uint8_t(256bins)的类型就够了。Histogram算法另一个优势则是大幅减少了计算分割点增益的次数。由于histogram可以进行数据并行,所以只需要计算#bin(Histogram的横轴的数量)次。
LightGBM的另外一个优势在于它使用了带有深度限制的按叶子生长(leaf-wise)算法来取代大多数GBDT使用的按层生长(level-wise)的决策树生长策略。Leaf-wise在分裂次数相同的情况下,可以降低更多的误差,得到更好的精度。由于一个叶子的直方图可以由它的父亲节点和它兄弟节点的直方图做差得到,LightGBM利用这个原理,可以在构造一个叶子的直方图后,用十分微小的代价得到它兄弟叶子的直方图,将速度提升一倍。
Histogram算法建立直方图的主要步骤共有四个循环。
第一个for循环:在当前模型下对所有叶子节点处理(每一个模型)。
第二个for循环:遍历所有特征,需要最佳分类特征值。使用分箱操作建立直方图。
第三个for循环:遍历所有的样本,根据公式H[f.bins[i]].g+=gi计算bin中样本梯度之和,公式H[f.bins[i]].n+=1对bin样本计数。
第四个for循环:遍历所有bin,找到最佳bin。SL为当前bin左边所有bin的梯度和,nL为当前bin左边所有bin的数量,SP、np为父亲样本的总梯度和和总数量,SR、nR为当前bin右边所有bin的梯度和和样本数量,直接由父节点减去左边得到。所以只需建立一个叶节点的直方图就可以了。
Leaf-wise和Level-wise的区别如图1和图2所示。

图1 Leaf-wise策略图

图2 Level-wise策略图
可以看出,Level-wise生成树策略分裂同一层的每个叶子,这样可以使用多线程去优化,防止过拟合,但是叶子节点的分裂效益过低。而Left-wise生成树策略按照叶子的增益效果来分裂,选择增益效果最大的叶子对其进行分裂,这样可以提升分裂效益,但会带来过拟合的问题。
1.2 分类预测模型算法的流程
基于LightGBM算法,根据提取的用户特征,来构建分类预测模型。
1) 假设对特征进行筛选和衍生之后,得到的特征表示为:

(1)
再经过分桶和0-1标准化后,进行转化:
(2)
将特征b11到bnm作为目标变量yi。
2) 计算初始梯度值。用bgistic loss函数作为特征的损失函数:
L(yi,F(xi))=yilog(pi)+(1-yi)log(1-pi)
(3)
式中:F(xi)为梯度值;Pi为损失概率。
(4)
则初始梯度值为:
(5)
式中:η为学习率;Fm(xm)设为0。原特征值转化为:
(6)
3) 建立树,总共分为五步去做。
(1)将特征值转化为bin value,即对每个特征做一个分段函数,把所有样本在该特征上的取值划分到某一段(bin)中。
(2) 对每个特征构建一个直方图,将原来的特征值表进一步转化:
(7)
式中:eij=(sij,nij);sij为bin中样本梯度之和;nij为bin中样本数量。
(3) 从直方图中的sij、nij来求分裂增益,选取最大的增益,则此时的特征和bin的取值为最佳分裂特征G和最佳分裂特征值H。
(8)
(9)
(4) 建立根节点:
Ti=argmax(Gi) 1≤i≤m
(10)
即根节点为(Ti,Gj,Hj)。
(5) 根据Gi和Hi对样本进行切分。直到所有叶子不能分割或者达到切分最大限度。
4) 更新初始梯度值Fm(xi)。
5) 重复第3)步、第4)步,把所有的树建成。至此,分类预测模型主要部分已经完成了[10]。
1.3 分类预测模型的改进
基于LightGBM的分类预测模型主要使用histogram算法来建立树,即用直方图来找出最佳分裂特征和特征值。这种算法不仅可以减少内存的消耗,还可以加快计算的速度。但是,这种算法也有不足之处。在采用了leaf-wise策略优化后,虽然减少了很多不必要的开销,但容易长出较深的决策树,导致过拟合。一般采用设置最大深度来防止过拟合。
由于实验数据过多,设置的最大深度仍然可能造成过拟合。所以使用pair-wise算法来降低深度。pair-wise算法是指将两个相互作用因子通过其交互作用的比例,对产生的case进行筛选,从而找出最佳性价比的集合。基于pair-wise算法的原理,可以在建立树的过程当中,减少节点的分裂,降低深度,防止过拟合。
在1.2节风控模型算法设计的第3)步中,对样本进行切分后,做一个判断函数:
(1) 遍历整棵树,获取每个点的位置、分裂特征和特征值,即(Ti,Gi,Hi)。
(2) 从上而下获取上述三个因子的两两组合。
(3) 遍历每个节点,判断每个节点中三个因子的两两组合是否在上面出现过,若出现则删除,否则保存。
(4) 按照不同的顺序执行第(2)和第(3)步,即第(2)步和第(3)步的遍历顺序为从下而上。
(5) 得到两组数据,找出相同的点。
(6) 按照原先树的节点顺序将点排列,组成一棵新的树。
2 实验与结果分析
2.1 风控模型指标体系的建立
模型的主要算法确定完毕,接下来就是指标体系的建立。此次实验的数据来自国外lending club P2P借贷网站2018年2月至2019年2月的用户借贷信息,数据大概有60万条,144个特征,将其中缺失值超过30%的特征剔除,还有102个特征,其中float64数值型特征有77个,object型特征有25个,表1为部分特征[11]。
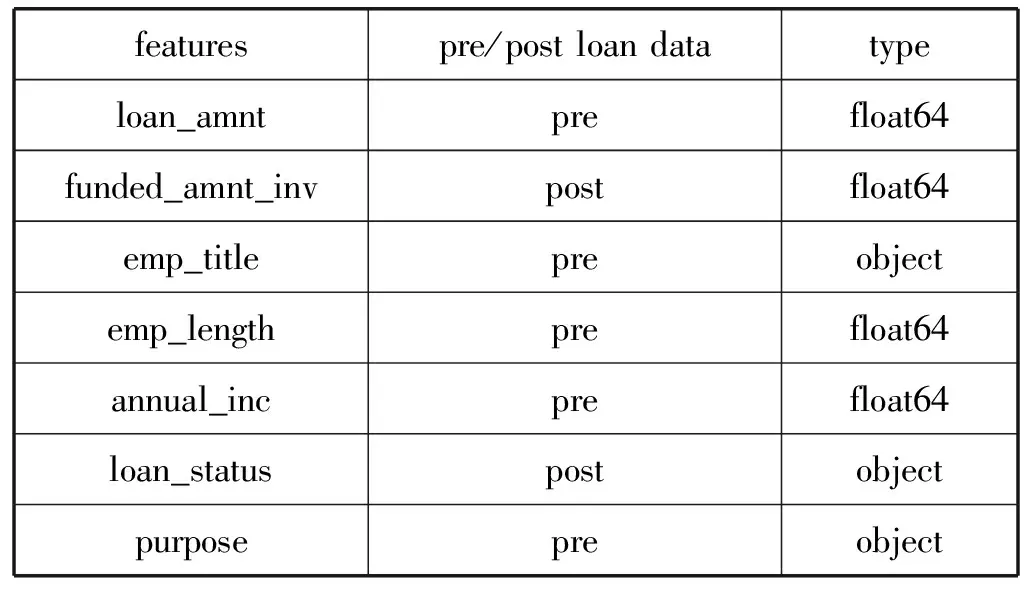
表1 原始数据部分特征
通过查阅大量的消费金融行业的资料,从用户个人信息、用户行为特征、贷款平台信息、贷后数据评分四个方面,以时间和空间两个维度来进行特征的衍生,建立风控模型的指标体系。由于特征比较多,就不一一列举,下面介绍几个比较重要的特征。在对用户个人信息进行特征的分析时,发现有些特征如addr_state(借贷人住址)、emp_title(工作标题)、purpose(借贷目的)等为文本型数据,对其进行分析得到相应的词云图如图3和图4所示。

图3 emp_title词云图
图4 addr_state词云图
可以看出,文本型特征的数据种类繁多,且这些特征在模型里的重要程度非常高,所以要对这些文本型特征进行编码,对于具有2个唯一类别的分类变量(dtype==object),使用Scikit-Learn LabelEncoder进行标签编码,对于具有2个以上唯一类别的分类变量,使用get_dummies(datafram)函数进行one-hot编码。
在用户个人信息和行为特征中,注意到可以用annual_inc(借贷人年收入)/12除以loan_amnt(期望贷款金额)/int(term(贷款周期))来形成一个新的特征loan_purse,这个特征代表借贷人每月还款本金与月收入的比,把它叫做贷款人的还贷压力。接下来,还可以用open_acc(借贷人信用档案中未结信用额度)除以total_acc(当前借贷人信用档案中总信用额度)代表借贷人的信誉度,把它作为reputation。用issue_d(贷款发放时间)减去earliest_cr_line(借贷人首开信用卡时间)代表借贷人的信用历史,把它作为re_history。用旧的特征来衍生新的特征。
在众多特征中,有着许多的连续型特征如open_il_24m、dti、delinq_amnt等,用卡方分箱法对其进行分箱,并且计算所有特征的WOE和IV值,选取出IV值大于0.02的变量,用它们对应的WOE值对数据进行替换。最后,形成的指标体系如表2所示。

表2 指标体系展示

续表2
2.2 模型结果展示
实验平台为PyCharm Community Edition 2019.3.3 x64,操作系统为Windows 10旗舰版,CPU为Intel Core i7,16 GB内存。实验平台如图5所示。

图5 实验平台截图
对网上爬取的数据进行数据清洗和数据规范化处理等相关操作形成格式区间统一的数据。处理前和处理后的文件对比如图6所示。

(a) 处理前

(b) 处理后图6 数据处理前后对比
对数据进行清洗、筛选、特征衍生形成特定的指标体系后,从新的数据集中以70%:30%的比例选取训练集与预测集,在基于LightGBM算法的分类预测模型上进行训练。通过反复实验对比,得出了本次实验的最近参数,即LightGBM树的最大叶子数设为128,最大树深度设为7 643,提升学习率设为0.097 14,拟合树的棵数设为10,设计出表现最好的模型。再对数据进行分类和预测,得到输出的结果,根据每个用户的得分,划分不同的区间。输出结果部分如表3所示。
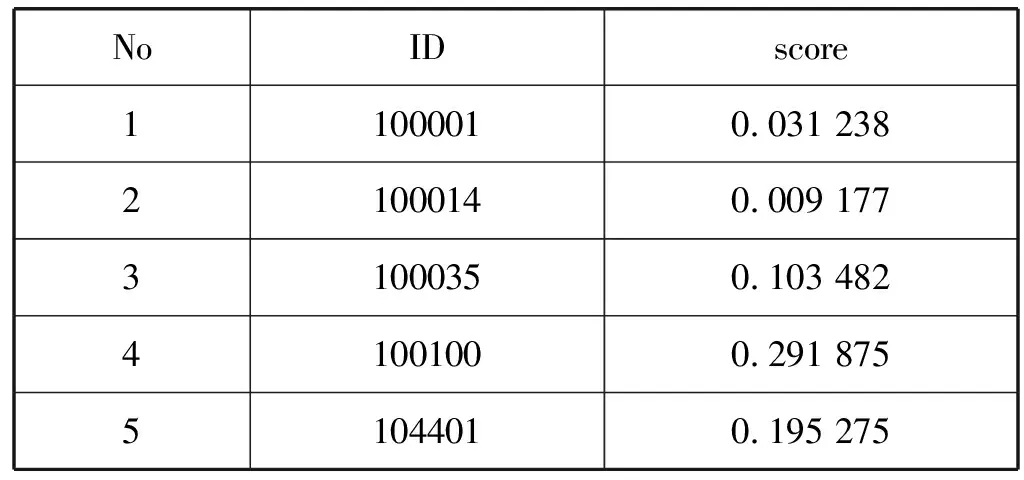
表3 借贷人得分
由于得分主要集中于0.1到0.2之间,所以从0.1到0.2这一区间中每隔0.01划分一个区间,0.1以下和0.2以上再各分一个,总计12个区间,分数越高,用户的按时还款率越高。通过一个简单的分数判定,来预测平台用户的还款率。
2.3 实验结果分析
由于提供实验数据的平台已经对客户进行了信用分级,分级情况如图7所示。
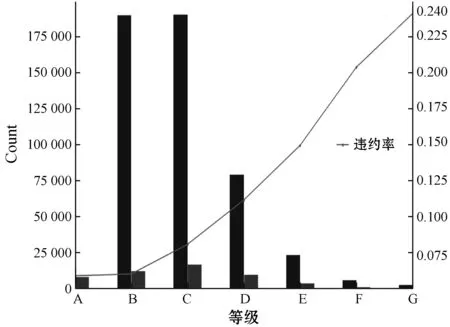
图7 信用分级
可以看出,该平台将客户分为了7个等级,每个等级上左边的柱形图代表按时还款的人数,右边的代表违约的人数。而A和G等级中的违约人数太少,无法形成有效的柱形图,就只统计按时还款的人数,方便分析。通过观察发现,从A到G等级,随着等级的升高,客户的违约率越高,而最高的违约率没有超过24%,即借贷人的按时还款率在76%到100%不等。根据图7得出的结论和表3中的实验结果,将得分小于0.1的借贷人作为还款率最低的那部分人处理,即还款率为76%;大于0.2的借贷人则为还款率100%的客户。而0.1至0.2之间以0.01作为间隔划分为10个区间,将此区间得分减去0.1再乘以2.4,最后加上76%作为还款率,如得分为0.103 482的借贷人,处于第一号区间,则根据公式[(score-0.1)×2.4+76%)],得其还款率为76.836%。经过观察发现,得分越高的借贷人,其年收入越高,年收入与得分的关系如图8所示。

图8 年收入与得分关系
可以看出,借贷人年收入与得分成正比,且借贷人年收入高于200 000时得分接近0.2,即达到最大还款率;而在年收入低于25 000后接近最小还款率。为了验证实验结果的合理性,将原始数据中的借贷人年收入和违约率作为关系特征来建立关系,从中分析借贷人年收入和违约率规律。建立的关系曲线如图9所示。
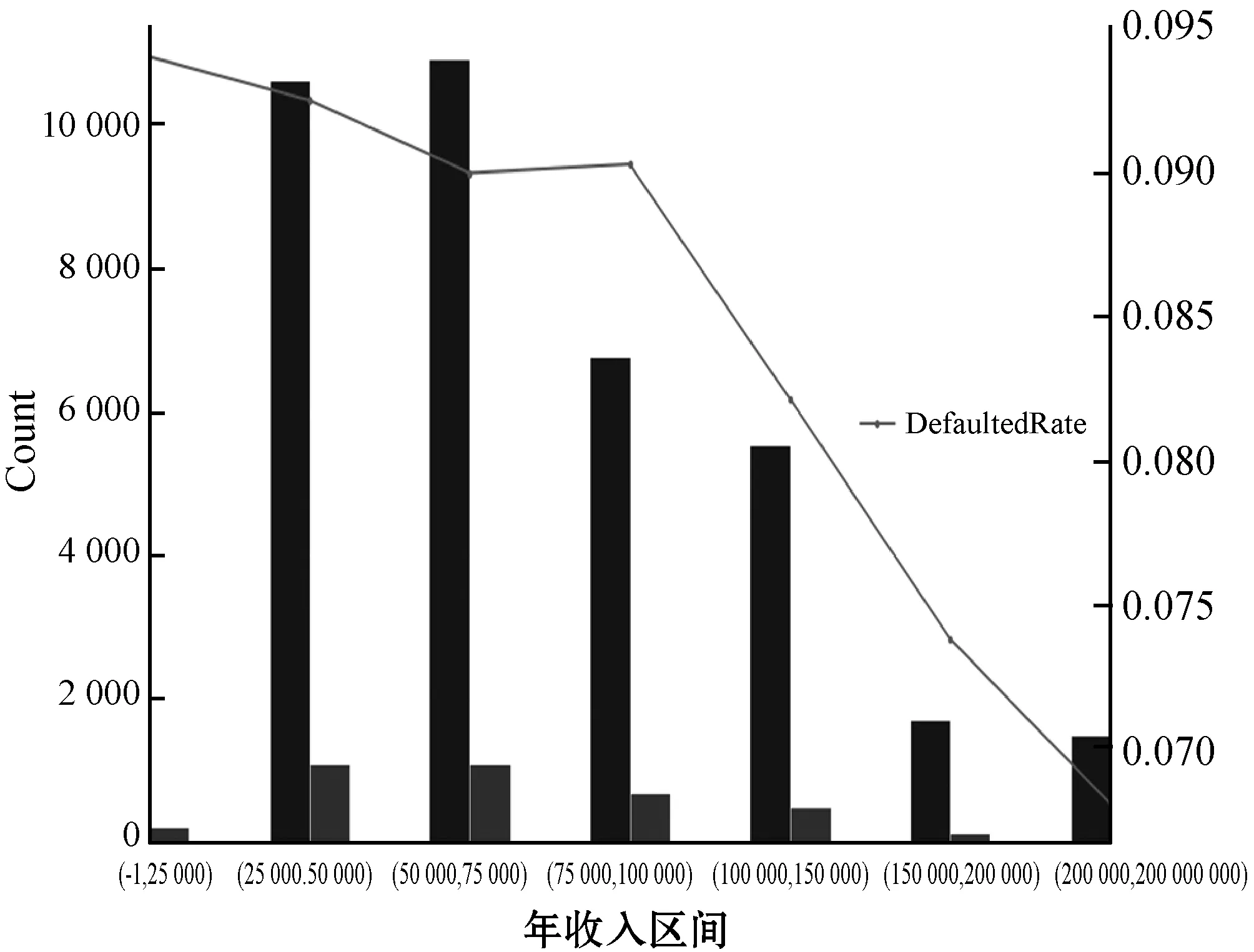
图9 年收入与违约率关系
图9的设计类似图7,每个区间左右边的条形图分别为按时还款的人数和违约人数。从图9中不难看出借贷人的违约率是与年收入成反比,即借贷人年收入越高,违约率越低。经过进一步观察发现,在0到25 000这一区间达到了违约率的峰值,而在200 000到2 000 000的区间违约率低到忽略不计。这与图8中的结论互相印证,证明了实验结果是合理有效的。
此外,根据对实验结果的分析发现,得分低于0.1的借贷人在过去两年内的违约次数基本达到了6次以上,且信用卡透支次数也达到了4次以上;而随着得分的升高,借贷人的信用历史和信誉度都随之升高,符合现实规律。
2.4 模型效果对比
将ROC曲线、AUC值和F1-score作为模型的评估标准。ROC曲线全称为“受试者工作特征曲线”(Receiver Operating Characteristic),横轴为“假正例率”(False Positive Rate),即在不同标准下受到的同一刺激;纵轴为“真正例率”(True Positive Rate),即受到刺激下做出的反应。通过对ROC曲线的观察,来判断模型的准确性,一般ROC曲线越靠近左上角,其假正例和假反例总数越少,模型的查全率就越高,模型预测得就更为准确。而AUC为ROC曲线下的面积,它能量化地反映出基于ROC曲线衡量出的模型性能;AUC越大,说明该分类器的分类性能越好。F1-score是一种均衡精度和召回率的综合评价指标。
通过求出基于LightGBM算法预测模型的ROC曲线,以及与逻辑回归、决策树、SVM和XGBoost的F1-score、AUC值的对比,来体现LightGBM在用于信贷风控模型的优势。图10为LightGBM算法的ROC曲线。

图10 ROC曲线图
图10中的虚线为基准线,实线则为改进后的LightGBM算法的ROC曲线。由ROC曲线可知优化后的LightGBM算法已经达到了很高的准确率,表4给出了该算法与其他分类预测算法的对比结果。

表4 算法各项指标对比
由图10和表4结果可知,与逻辑回归、决策树、SVM和XGBoost算法相比,LightGBM算法预测得更为准确,得分更高,AUC值更大。LightCBM算法在分类预测上有着极大的优势,在运用到消费信贷风控模型上面有着很不错的前景。
3 结 语
通过对LightGBM算法进行研究,再融合pair-wise算法进行改进,建立互联网金融信贷风控分类预测模型。用借贷人的相关信息作为实验数据,开展分析和预测。实验表明,相较于其他算法模型,LightGBM具有速度快、效率高、更精准、占用内存少,以及可以并行计算等优点。互联网金融的数据会越来越庞大和复杂,基于LightGBM算法的互联网金融风险预测模型在实践中会有重要的应用价值。
本文还有不足之处,例如,数据集存在着一定的完整性缺失,指标体系也不够全面,对实验结果有一定的影响,有待进一步研究改善。
猜你喜欢
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
影像视觉(2018年12期)2018-11-29
中学生数理化·高一版(2017年2期)2017-04-25
初中生世界·八年级(2017年3期)2017-03-24
百家讲坛(2016年6期)2016-09-28
商界(2015年9期)2015-10-15
民生周刊(2015年17期)2015-09-10
