
基于事件相机的人体动作识别方法
2022-07-12 06:34张远辉许璐钧徐柏锐何雨辰
计量学报 2022年5期
张远辉, 许璐钧, 徐柏锐, 何雨辰
(中国计量大学机电工程学院,浙江 杭州 310018)
1 引 言
人体动作识别技术已经应用在视觉监视、自动驾驶汽车、娱乐和视频检索等方面[1]。随着卷积神经网络(convolutional nerural network,CNN)的快速发展,网络的深度和结构越来越多样化,大量的卷积网络结构被提出,如3D-CNN[2],LSTM(long-short term memory)[3],双流网络(two-stream networks)[4],DBNs(deep belief networks)[5]等。这些方法都是采用传统相机或是深度相机进行采集后再利用卷积神经进行处理。若在两帧曝光时间之内人体在快速移动,则会产生运动模糊,这在动态人体动作识别中是一个难点[6]。一般情况下,通过增加帧率来解决,但是处理这些包含大量冗余信息的连续图像帧会极大地浪费计算能力、内存空间和时间。
近年来,一种事件相机应运而生,能够高效地异步记录像素亮度变化[7],每个变化被称为一个“事件”,记为e=(x,y,t,p),(x,y)为位置坐标,t为瞬时时间,极性p∈(0,1)(0表示亮度变暗,1表示亮度变亮)。图1是传统相机与事件相机输出形式的对比,图1左图是一个黑点随着圆盘转动,右图1(a)是传统相机以固定帧率获取的连续图像,每个图像中都记录了完整的场景信息;图1(b)是事件相机只输出快速运动目标(黑点)的强度变化信息,不记录静止物体(中心点和圆盘背景)的信息。

图1 传统相机与事件相机输出形式的对比Fig.1 Comparison of different output forms
事件相机与传统的基于帧的相机相比,一是具有高动态范围、高时间分辨率(μs级),更容易获取运动特征的优点;二是只输出局部发生光强变化的像素,可以节省大量的计算资源和能耗[8]。王含宇等[9]利用高斯跟踪器和地址查找表,实现基于事件的多方向识别。Baby S A等[10]结合3种投影图(如x-y,x-t,y-t)和运动边界直方图MBH(motion boundary histogram)的方法对人体手势进行识别,但其计算量大、运算时间长。Ramesh B等[11]提出一种事件信息的DART(distribution aware retinal transform)描述子,但该描述子在设计原理上未考虑旋转、尺度、视角的不变性。Bi Y等[12]提出一种基于图形的卷积神经网络结构用于分类事件相机目标。Gehrig D等[13]提出通过可微操作将事件流转换为网格表示的通用框架。Ramesh B等[14]利用低维度来实现特征的匹配,提出一种无回溯的KD树机制。以上的方法都是以固定的时间间隔分割事件流从而形成虚拟帧,再用传统图像识别模型进行分类学习。
然而,将事件流看作虚拟帧序列并不能充分利用事件数据的时空稀疏性,同时,经过时间积累得到的虚拟帧失去了每个时间间隔内的空间结构。为了解决这些不足,本文利用卷积神经网络提出一种直接处理事件数据的方法。将事件流等效成三维空间(x,y,t),对其空间结构和时间特征进行分层分析,获取每种动作的基本时空结构,然后利用学习到的特征进行分类。针对卷积神经网络存在模型参数量大、训练速度慢的问题,采用共享卷积核的方式,且对卷积层中每个事件进行并行卷积操作,为事件相机在动作识别中的应用提供了一种高效的网络构架,具有训练时间短、参数量小、识别率高等优点。
2 人体动作识别整体方案设计
利用事件相机进行动态人体动作识别方法的流程如图2所示,包括事件流采集、数据预处理、神经网络训练和识别3个部分。
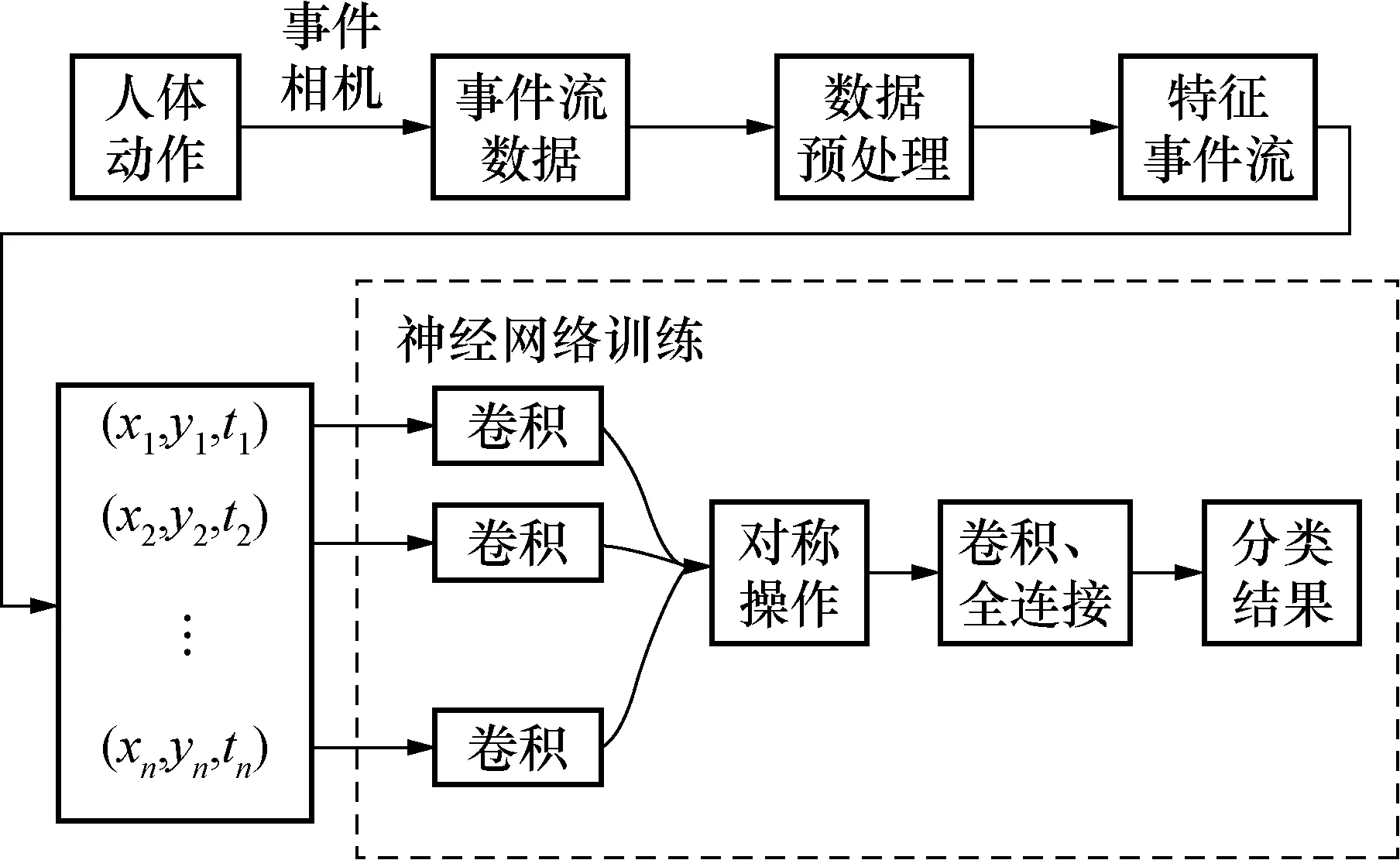
图2 动作识别方法流程Fig.2 Action recognition method flow
2.1 事流数据采集
目前由于受到硬件技术和成本的限制,没有关于使用事件相机拍摄的人体动作数据集。故在实验中自行建立了一个动作数据集,用于验证该算法的可行性。考虑9种常见的人体动作(动作过程持续时间约为2 s),分别是行走、跳跃、奔跑、挥手、转身、拾取、坐下、踢脚、喝水。图3为用事件相机拍摄的动作示例图像,其中二维图是时间间隔为30 ms的事件流显示(红色点表示极性为1,绿色点表示极性为0),三维图是在(x,y,t)空间下发生一个动作的所有事件的三维显示。

图3 事件相机记录的9种行为Fig.3 Nine behaviors recorded by the event camera
2.2 事件流数据预处理
事件相机对环境中的光强变化非常敏感,不可避免地易受到光学硬件电路和环境因素影响,在输出动作信息的同时夹杂着大量的噪声[15],从而影响后续的神经网络训练精度等问题。因此,事件流的数据预处理非常必要[16]。由于事件流与图像帧的输出方式上有明显地差异,基于帧的传统视觉处理算法不能直接应用于事件数据中。针对这一特性,本文直接对事件流序列进行处理,采用滤波和降采样的方法来达到用更少的事件数量表示一个相对完整的动作。

(1)
在事件相机中,某一位置的像素被激活时,输出由这些像素组成的事件,反之则不会输出。因此,可以将发生“事件”这一动态过程表示成阶跃函数ε(x,y,t)的形式。
ei=(xi,yi,ti)⟺ε(x-xi,y-yi,t-ti)
(2)
那么,N个事件组成的事件流可以写为
(3)
有效事件是由物体的运动或是光强度的变换真实产生的,一个有效事件通常不会单独产生,而会激活周围位置的像素。所以,有效事件的密度值通常是大于无效事件的密度。在时空邻域U(x,y,t)内,输入事件e(x,y,t)的密度计算如下公式(4)。如果事件密度小于C,则该事件为无效事件并滤除;反之则为有效事件并保留。
(4)
通过设定阈值C,滤去大量的无效事件。但在2 s的时间内仍有约20 000个事件,为加快神经网络的训练速度和减小运行占用的内存,采用三维网格采样的方法将事件数目减少至n(n一般取1 000~5 000)。具体步骤为
(1) 计算出某一动作的三维点重心(xc,yc,tc):
(5)
(2) 以重心为中心,画a×a×a的三维网格。由于事件相机的像素为128×128,a取4。
(3) 以重心为中心的8×8×8网格范围内,每一个网格取a个点数;其余的每一个网格取a/2个点,直到取到规定的点数n。
图4是以挥手动作为例的事件流的三维对比图,完整动作时间为1.739 8 s,记录了N=27 833个事件,经过数据预处理后事件数量n=4 096。图4(a)是事件相机采集到的事件流三维图,图4(b)是经过滤波后的事件流图,图4(c)是采用网格降采样后的事件空间位置图。

图4 事件流的三维对比图Fig.4 3D comparison diagram of event flow
2.3 神经网络训练和识别
卷积神经网络对信息的特征提取主要依靠卷积和池化操作[17]。卷积操作依靠卷积核尺寸将低维感受野中的特征提取到高维中,通过控制卷积核的数量达到通道数大小的放缩。而池化操作只能改变高度和宽度,无法改变通道数。
图5为本文采用的神经网络模型结构,由多个卷积层、池化层和全连接层构成。

图5 网络模型结构图Fig.5 Network model structure diagram
图5中“Conv”,“GAP”分别是“Convolutional layer”,“Global Average Pooling”的简写,“@”符号之前的数字表示卷积核大小,之后的数字表示卷积层的通道数。n的大小取决于数据预处理中降采样后的事件数量,分别取1 024、2 048、4 096进行试验。
为了减少模型对输入事件流数量的依赖,需要采取一种具有对称性的函数来处理事件,使得不论如何变化事件的输入顺序(比如人体跳跃过程中,向上起跳或是下落都是跳跃动作)都不会对结果产生影响。首先,从样本集中随机选取组成训练集,作为神经网络的输入;再使用不同数量和尺寸的卷积核对每一个事件ei进行特征提取,将其维度扩充至高维;然后,在池化层中对特征维进行对称操作,使得网络对不同数量的事件流输入都可以产生相同维度的特征向量;再利用卷积层降维之后,和全连接层相连,最终输入到softmax分类层中进行动作识别。
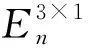
Y=σ(XW+B)
(6)
式中:W∈R9×64和B∈R9×1分别表示相邻层之间神经元连接的权重和该神经元的偏置值;σ(*)是某一种非线性激活函数,激活函数采用Relu来增加神经网络各层之间的非线性关系。
模型的最后是输出层,采用Softmax分类器得到九种人体动作的分类结果。使用Softmax函数可以将向量Y∈R9×1拟合为[0,1]范围内的实数,且所有实数之和为1。Softmax函数如下:
(7)
式中:zi表示第i个节点对应的输出值,Cz为总类别数,本实验中Cz=9。
训练过程中采用交叉熵损失函数,FLoss可表示为
(8)

3 实验与结果分析
3.1 数据集采集过程
实验在Window10系统下,利用Python语言,pytorch深度学习框架完成。硬件环境为CPU Intel i7-8750H,内存8 GB,显卡NVIDIA GeForce GTX 1060。使用的事件相机是iniVation公司生产的eDVS型号相机,并基于caer库自行开发了软件并进行了数据采集。
采集了20个人的9种人体常见的动作数据,分别是行走、跳跃、奔跑、挥手、转身、拾取、坐下、踢脚、喝水。每人每种动作依次在室外空旷环境下各采集20次,除了坐下这一动作其余都是站立完成,拾取、喝水等动作根据测试者习惯左手或是右手进行实验。每次数据采集以一个完整动作执行结束为限,下次开始前动作复位,以便采集下一次完整的动作。
3.2 实验结果分析
实验前将采集到的所有文件按照“动作名称_序列号”命名,随机取出80%为训练集,剩余部分作为测试集。读入事件流数据后采用批训练的方式进行训练,即在实验过程中一次性输入一批训练数据,可以加快动作识别网络的训练过程。经过多次实验比较,在表1所示设置的参数下,模型的收敛速度较快且准确率也较高。其中带*的参数为本文模型特有的参数选择。

表1 动作识别神经网络模型的参数设置Tab.1 Parameter setting of action recognitionneural network model
实验结果如图6所示,图中横坐标为迭代时期数,纵坐标为训练数据的准确率、交叉熵。

图6 3种n取值对应的变化过程Fig.6 corresponding to three n values
图6(a)中表示3种n的取值在训练过程中准确率的变换过程。随着迭代次数的增加,模型在训练集上的准确率整体呈上升趋势,直到迭代到一定的次数之后结果基本趋于稳定。同时可以看出n为2 048时较快趋于稳定且准确率最高。图6(b)中表示3种n的取值在训练过程中交叉熵值的变换过程。由图7(b)可知稳定时,n=1 024的交叉熵值为0.294,n=2 048的交叉熵值为0.204,n=4 096的交叉熵值为0.319。

表2 3种n值的准确率对比Tab.2 Accuracy comparison of three n values
考虑到模型的参数优化和运算时间,同时尽量遵循用较少的事件来描述一个完整动作过程的原则。如图7所示,选取n为2 048时论文方法在测试集中各类动作的准确率均在87%以上,平均准确率为91.3%。

图7 行为识别结果的混淆矩阵Fig.7 Confusion matrix of behavior recognition results
相机作为一种光学传感器,容易受到光照的影响,为了测试本文行为识别方法的鲁棒性[18]和事件相机的优势,分别在一般光照、强逆光和暗光下采集数据。每次采集时,传统相机和事件相机同时记录,分别保存为视频和自定义的二进制文件。
自定义的二进制文件具体格式为: 事件位置坐标(x,y)采用short数据类型(占用2字节), 时间戳t(单位:s)采用double64数据类型(占用8字节),极性不记录(背景光强相反会引起极性相反,故不在本实验考虑范围),以一个挥手动作为例,二进制文件共记录了27 833个事件,总字节数为27 833×(2+2+8)=333 996;而对应的彩色视频记录为 128×128 pixels,帧率为60帧/s,时长2 s,总字节数为5 898 240,由此可知二进制文件的字节数约为视频文件的1/17,故采用二进制文件可以节省大量内存空间。
图8为不同光照下采集动作数据的图像。

图8 不同光照下采集动作数据的图像Fig.8 Images of action data are collected under different light
如图8(a)、8(b)、8(c)的左图是用OpenCV显示得到的传统帧图像,右图是事件帧图像。可以明显看出,图8(a)中的左图所示,传统相机记录时存在地面反光;图8(b)中的左图所示,在强逆光下传统相机存在曝光过度的问题;图8(c)中的左图中出现较多模糊和光线较暗;而事件相机都未出现这些问题。
从表3中可以看出,一般光照下基于事件相机的识别准确率可以达到91.3%,可满足实际使用的要求;在强逆光和暗光的环境对准确率的影响也较小。但不同光照条件对基于传统相机的识别准确率存在严重的影响。这说明本文的行为识别方法具有良好的鲁棒性。

表3 不同光照下传统相机和事件相机的识别准确率Tab.3 The recognition accuracy of traditional camera and event camera under different light (%)
3.3 与已有动作识别方法对比
为了进一步验证本文方法的有效性,在一般光照下与文献[10,13]的行为识别方法进行对比,对比实验结果如表4所示。

表4 不同方法对比的实验结果Tab.4 The experimental results were compared by different methods
从表4中可以看出,本文与文献[10,13]的识别方法相比:1) 文献[10]采用的方法是通过提取x-y,x-t,y-t等人工特征,识别步骤繁琐;而本文利用卷积神经网络可以自动提取行为特征,端到端的方式输出识别结果,为事件相机识别方法提供了新的思路。2) 本文在输入网络前进行数据的预处理,将事件流数据看作为三维数组直接进行噪声去除,比文献[10,13]提高了动作识别模型的准确率。3) 在训练时间上,得益于事件数据的预处理步骤和模型中共享的卷积核来减少参数,大大减少了模型参数量和训练时间。
4 结 论
在不同光照条件下,利用事件相机采集9种常见人体动作数据集,对原始数据进行滤波、空间降采样预处理后作为网络的输入,再利用神经网络通过训练自动学习事件流空间中的动作特征,最后使用分类器对每一种动作进行识别分类。该方法省去了提取人工特征的步骤,实现了端到端的处理数据输入。实验表明动作识别方法的有效性和可靠性,在一般光照下识别的准确率达到91.3%,不同光照条件对所提出的识别方法影响较小。
猜你喜欢
中国机械工程(2022年8期)2022-05-09
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
儿童时代·幸福宝宝(2021年1期)2021-03-29
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年13期)2020-01-14
小资CHIC!ELEGANCE(2019年40期)2019-12-10
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
