
基于Hadoop和Flink的电力供应链数据中台建设与应用
2022-07-20 03:11张茂君李俊华邢海涛朱庭楠孙健
电力大数据 2022年2期
张茂君,李俊华,邢海涛,朱庭楠,孙健
(上海华能电子商务有限公司,江苏 南京 210000)
早期业务发展过程中,电力企业为了解决一些当前的业务问题,按照垂直的、个性化的业务逻辑独立采购与建设的信息系统,其与流程、底层系统耦合较深,横向和上下游系统之间的交叉关联也较多,导致企业内部形成多个烟囱系统,彼此之间的数据规则不统一,很难做到数据的完全互联互通[1]。在新平台、新业务、新市场的拓展过程中,原系统无法直接复用和快速迭代,产生的数据也无法与传统模式下积累的数据互通,进一步加剧了数据孤岛的问题。分散的数据无法很好地应对前端业务变化,难以支撑企业的经营决策,因此需要数据中台将新老模式融合,整合分散在各个孤岛的数据,形成数据服务能力,将数据变现[2]。
针对上述问题,本文基于Hadoop和Flink等多种开源大数据技术与系统,自主研发了一种供应链大数据中台系统,系统先将供应链各环节中的数据集成,实现数据的准确、及时获取,再利用算法、数据变换等大数据技术进行有效数据治理,消除脏数据,形成结构化、半结构化和统一规则的非结构化的数据,组成统一的数据湖资源,然后通过流式和离线计算,数据分析、挖掘等大数据技术,形成有价值的数据资产和各类数据服务,在各业务系统之间实现数据互通,以数据驱动业务创新。
1 基于Hadoop和Flink的电力供应链数据中台设计
目前,市场上存在各类通用数据中台产品,直接购买虽然省去了研发、维护成本,但由于无法满足电力供应链管理企业个性化、灵活多变的实际业务需求,通用的数据中台无法直接被企业使用[3],因此,本文对照华为数据湖治理中心产品,基于Hadoop和Flink等开源大数据技术,结合电力供应链相关业务需要,自主研发构建了电力供应链数据中台。
1.1 电力供应链数据中台系统功能设计与技术选型
本文设计的数据中台系统能够针对企业在数字化运营中产生的所有数据,提供的一站式智能数据管理平台,包含数据集成、数据处理、规范设计、数据质量监控、数据资产管理、数据服务等功能。系统能够进行多维度数据分析与预测,可以快速构建从数据接入到数据消费的端到端智能数据系统。系统的功能架构如图1所示。
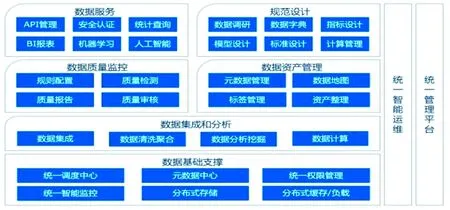
图1 电力供应链数据中台功能架构图Fig.1 Functional architecture diagram of power supply chain data middle platform
数据基础支撑模块提供数据中台的公共基础服务,是其他模块正常运转的支撑[4]。系统采用DolphinScheduler组件实现各模块间任务的统一调度和资源监控[5],依靠DataHub管理各种元数据,形成的数据仓库的元数据构成统一的元数据中心,采用角色加权限策略的方式实现统一又灵活的权限管理。系统基于HDFS文件系统和ClickHouse建立统一的分布式存储服务,采用Presto组件结合Kudu组成统一的快速检索服务。
数据集成和分析模块将多源异构数据源的数据集成,然后进行清洗、聚合、分析挖掘、实时流式计算、批量计算等处理,形成结构化、半结构化和非结构化的数据资源,建立数据仓库。系统采用并修改了开源组件DataX的源码,实现了Mysql、Oracle、文件等多种业务数据源的批量数据迁移,同时借助Kafka消息队列和Debezium中间件,实现了对于数据的实时获取和处理。在数据分析和计算层面,采用Python Numpy和Scipy中的常用算法,结合UDF函数,同时依赖Flink Batch和Stream API,进行业务所需的各类数据分析[6]。
规范设计模块进行智能数据规划、自定义主题数据模型、统一数据标准、可视化数据建模、建立数据指标[7],管理计算引擎等,参照国际和行业标准,形成规范、指标和数据标准[8]。
数据质量模块对系统中数据的全生命周期进行质量监控,实时通知和发掘违规数据[9]。通过可配置的质量标准检测正则表达式,结合数据质量指标,进行单列、跨列、跨行和跨表的数据质量稽核。
数据服务模块根据模板配置并生成相应的数据服务API,并且通过黑白名单,签名验证,降级和熔断等方式,保证数据服务的安全和稳定,为企业搭建统一的数据服务总线,提供一站式数据服务发布、测试和部署能力。
数据资产通过字典式的管理和检索方式提供企业数据资产清单,并且说明每个资产的含义以及使用方式,采用ElasticSearch构建资产搜索引擎,结合统一的数据权限,为登录系统的不同用户提供权限范围内的数据资产检索和使用。同时,系统通过数据地图,展示数据从产生、处理到形成资产和服务应用的全过程[10],体现数据治理前后的变化,实现数据血缘和数据全景的可视。
1.2 电力供应链数据中台系统技术架构和数据流程
数据中台首先从各业务系统中采集、再对数据进行清洗、处理、分析、挖掘,进行数据综合治理,形成统一数据规范和标准,同时管理和发布数据模型和算法,为各业务系统提供各类数据服务,在各业务系统之间实现数据互通,将数据成果形成各种高价值数据资产[11],在各业务系统中进行应用,以数据驱动业务创新,推动电力供应链管理企业的数字化转型和数据变现,具体数据流程如图2所示。

图2 电力供应链数据中台数据流程图Fig.2 Data flow diagram of power supply chain data middle platform
为实现数据中台的上述功能,结合1.1部分的技术选型结果,本文设计的供应链数据中台系统的技术架构如图3所示。
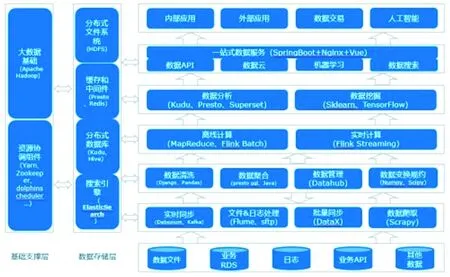
图3 电力供应链数据中台技术架构图Fig.3 Functional architecture diagram of power supply chain data middle platform
2 基于Hadoop和Flink的电力供应链数据中台核心技术原理
本电力供应链数据中台系统应用了很多开源大数据技术和算法,本节以Hadoop中的MapReduce过程和数据清洗中的去重算法为例说明下相关原理,其他的相关技术就不再逐一说明了。
2.1 Hadoop的MapReduce过程原理
Hadoop是本文数据中台的基础组件,而MapReduce是Apache Hadoop中一个批量计算的框架,在整个MapReduce作业的过程中,包括从数据的输入,数据的处理,数据的数据输出几部分[12],其中数据的处理部分又包括Map,Reduce,Combiner等操作。

图4 Hadoop的MapReduce过程流程图Fig.4 Hadoop’s mapreduce process flow diagram
如图4所示,Hadoop客户端启动一个作业后,会向工作追踪器请求一个Job id,然后将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的jar文件、配置文件和客户端计算所得的计算划分信息。这些文件都存放在工作追踪器专门为该作业创建的文件夹中。文件夹名为该作业的Job id。 jar文件的副本数由mapred,submit,replication属性控制,输入划分信息告诉了工作追踪器应该为这个作业启动多少个Map任务等信息[13]。
工作追踪器接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度,当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个Map任务,并将Map任务分配给任务追踪器执行。对于Map和Reduce任务,任务追踪器根据主机核的数量和内存的大小有固定数量的Map槽和Reduce槽。Map任务会分配给含有该Map处理的数据块的任务追踪器上,同时将程序jar包也复制到这上面来运行,即“运算移动,数据不移动”,但是分配Reduce任务时并不考虑数据本地化[14]。
任务追踪器每隔一段时间会给工作追踪器发送一个心跳,告诉工作追踪器它依然在运行,同时心跳中还携带很多其他信息,比如当前map任务完成的进度等信息。当工作追踪器收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当工作追踪器查询状态时,它将得知任务已完成,便显示一条消息给用户。
2.2 数据清洗-去重算法Hyperloglog原理
Hyperloglog算法(以下简称“HLL”)是基于loglogcounting等算法,使用一个几乎均匀的hash函数获取需要统计的元素的hash值,然后通过分桶平均消除误差[15]。
HLL把hash值分成一个一个的桶,并且用hash值的前k个位来寻找它的桶位置,桶的数量表示成:m=2k,例如一个hash字节二进制码为“1010100000001101”,长度L=16,假设K=6,说明一共有64个桶,则该hash值所表示桶的位置是0b001101=13,然后计算该hash值中后L-K的序列中第一个1出现的位置:6,因此在索引号为13的桶中进行计算,如果桶中的数字比6小就设置为6,否则就不变。通过统计每个桶中储存的值的平均数,就可以计算得到估算的基数值[16]。HLL中使用调和平均数进行计算:
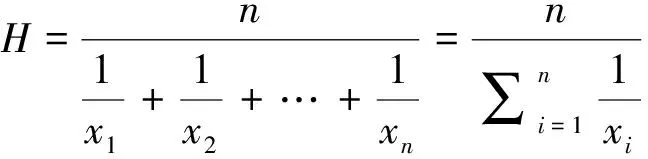
(1)
它的基数估算公式是:
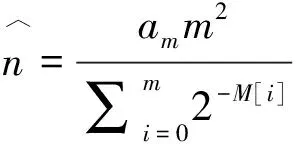
(2)
其中,M[i]表示第i个桶中的数值,表示为该hash值下第一个1对应的最大位置。另外am的计算公式为:

(3)
3 基于Hadoop和Flink的电力供应链数据中台建设
数据中台是包含底层存储计算与上层数据分析应用的一整套体系,它屏蔽了底层存储平台数据处理计算的复杂性,降低了技术人才的需求,让数据的使用成本更低[17]。本节从软硬件实现、核心功能实现和技术难点解决三个方面介绍数据中台的建设过程。
3.1 电力供应链数据中台软硬件实现
本文介绍的电力供应链数据中台完全由自主研发完成,已服务于公司电力供应链管理中的各业务系统,在软硬件上支持自行水平扩展扩容,根据1.3节介绍的本数据中台技术架构,目前服务于公司的数据中台软件实现情况如表1所示,其中,例如Hadoop、Flink等主要软件都做了高可用部署,系统服务层由Java基于Spring Cloud架构开发,通过Hystrix实现了限流和熔断降级等策略,支持服务在线灰度发布。
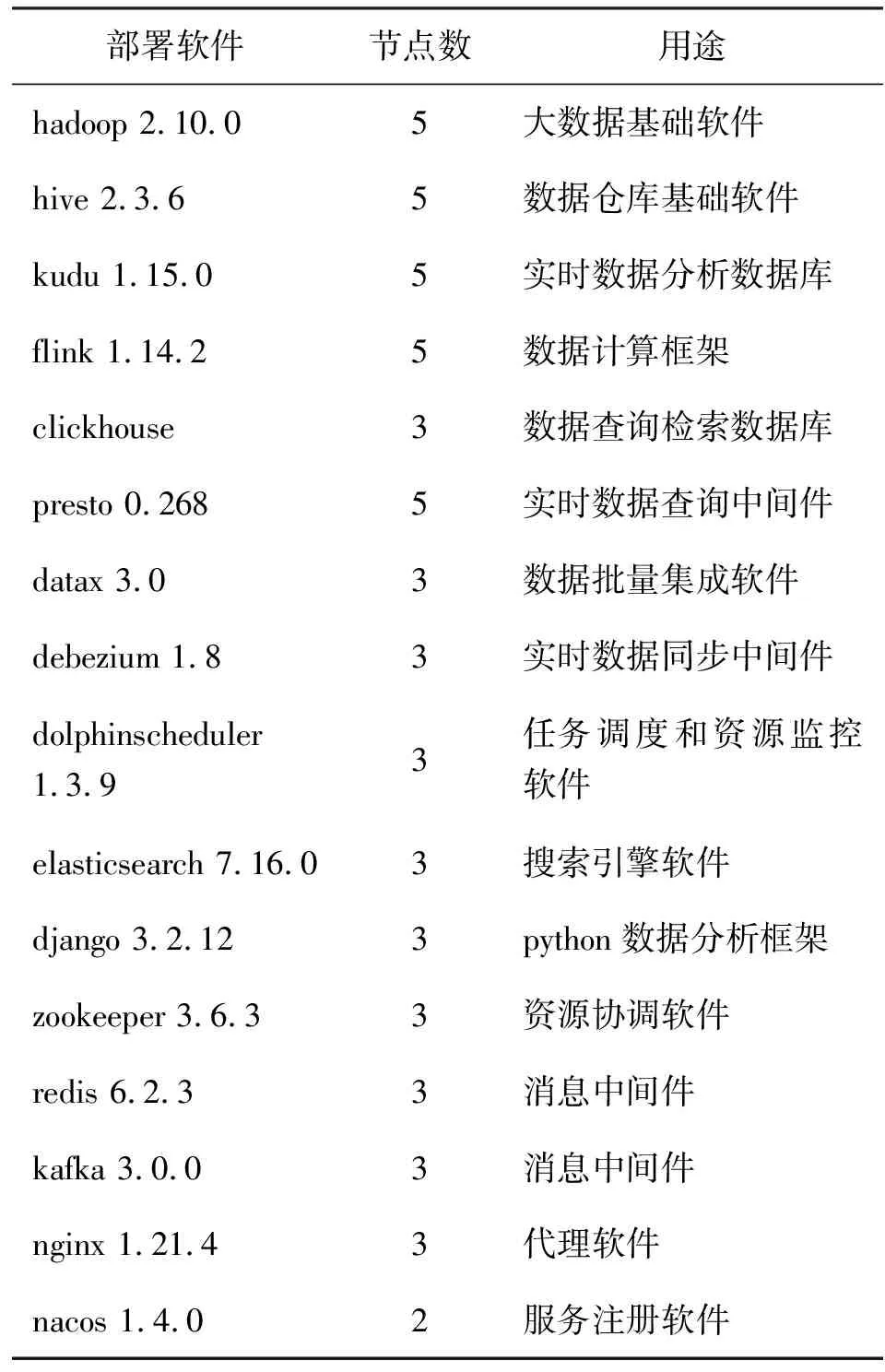
表1 电力供应链数据中台软件部署情况表Tab.1 Software deployment table of power supply chain data middle platform
在硬件层面,本系统基于华为云服务器资源,遵循分布式系统的一般结构,各节点支持水平在线扩展[18]。系统通过多级路由、网关和防火墙将内外网、办公网和研发网进行了隔离,还增加了攻击检测模块,保障系统网络安全,具体硬件网络架构如图5所示。

图5 电力供应链数据中台硬件网络架构图Fig.5 Hardwarenetwork architecture diagram of power supply chain data middle platform
3.2 平台核心功能的开发实现
本文的数据中台系统能够实现电力供应链全生命周期的数据采集、处理、服务和资产化应用,其中包含许多关键功能,在此以批量数据集成、流批一体化实时数据同步和业务数据聚合功能为例进行介绍。
3.2.1 批量数据集成功能
系统的批量数据集成支持多种异构数据源,支持单表、整库、增量、周期性等多种形式将数据迁移到数据中台。本系统与业务系统进行批量数据集成的步骤如图6所示:

图6 电力供应链数据中台批量数据集成流程图Fig.6 Batchdata integration flow diagram of power supply chain data middle platform
公司业务数据库有Mysql、Oracle两类,数据集成功能以DataX为基础,开发了向导式的配置和管理页面,将业务库数据、数据接口、csv或txt格式的数据文件中的数据以云加密的方式汇集到数据中台[19]。系统通过DolphinScheduler管理不同的数据集成任务,实现不同业务数据的定时批量汇集。
3.2.2 流批一体实时数据同步
在本系统服务于公司的实际业务中发现,批量的数据集成不能够完全满足业务对于数据的需求,基于调度工具的作业调度会带来级联的处理延迟,比如凌晨 1 点开始迁移和处理昨天的数据,可能需要到早上 6、7 点才能做完,并且无法保证在设置的调度时间内数据可以完全就绪。此外,级联的迁移和处理还会带来复杂的数据血缘管理问题,大任务的批处理可能会突然打满集群的资源,所以也要求我们对于负载管理进行考量,这些都会给业务增加负担[20]。而单纯的实时数据同步虽然解决了数据时效性的问题,但是却无法保存足够的历史数据,而且还会使同一份数据无法保证在实时和批量上的一致与同步[21]。鉴于此,本系统提出并研发了一种基于Flink和Hive的流批一体实时数据同步功能,具体流程如图7所示,可以相应的解决以上问题。

图7 电力供应链数据中台流批一体实时数据同步流程图Fig.7 Flow-batch integration real-time data synchronizationflow diagram of power supply chain data middle platform
系统通过Debezium中间件监听数据库日志将业务数据实时同步到Kafka中,然后在元数据层面,把Kafka表的元数据信息存储到Hive的MetaStore 中,做到离线和实时的表元数据统一。计算引擎上,Flink自身提供批流一体的ANSI-SQL语法,流和批复用一套Sql和Runtime框架。数据层面,Flink的hive streaming sink可以将Kafka表中的数据实时的同步到对应的离线表,将离线表作为实时的历史数据[22]。经过以上几个方面的处理,本系统就实现了实时数据和批量数据的统一与一致。
3.2.3 数据清洗和聚合
数据清洗聚合功能对原始数据集中的数据进行去除重,处理缺失值和异常值,再按照自定义的聚合规则,对清洗后的数据进行多次聚合,并且根据需要对聚合结果进行变换等规范化处理,归一化数据样本,消除指标之间的量纲和取值范围差异的影响,提升数据模型精度[23],使数据更适用于后续的分析挖掘和计算。
为满足复杂业务的需要,提高业务数据聚合结果的复用性,系统使用Presto查询引擎,结合Ods,Dwd,Dwb,DM,App五层数仓结构[24],贯穿Hive和Kudu两种类型的数据库,在Ods,Dwd和Dwb层实现通用的数据聚合结果,然后在DM和App层形成符合特定业务需求的业务数据聚合结果,从而实现多次分优先级的跨库复杂聚合,满足不同业务场景下对于数据OLAP和OLTP的要求。
3.3 数据中台系统技术难点解决
本文介绍的电力供应链数据中台系统在建设过程中遇到过一些技术难点,例如数据同步过程中的缓存与最终结果一致性问题,数据源DDL操作在数据仓库及实时聚合数据结果中的同步实时更新问题等,最终在团队的共同努力下都得到了有效解决。下面以数据源DDL操作在数据仓库及实时聚合数据结果中的同步实时更新问题的解决方案为例向大家介绍。
在数据中台系统进行实时数据同步的过程中经常会遇到源数据的DDL操作,Hive支持DDL操作的前提是要进行分桶,而且DDL的操作响应时间过长,无法满足快速查询和处理的需要,在加入Presto后,虽然能保证查询时效,但只支持新增以及整个分区的删除,无法进行逐条更新操作[25],因此,为解决这个问题,系统借助于Redis,在更新数据时,先将更新后的该条数据存入Redis,然后将剔除该数据后的分区数据整体备份到临时分区,然后将Redis中的新数据与临时分区合并,最后将原有分区的数据整体删除,将临时分区的数据整体写入新分区[26],以便后续处理和聚合使用。经过以上处理就解决了数据源DDL操作在数据仓库及实时聚合数据结果中的同步实时更新问题。
4 数据中台具体应用举例
本文建设的电力供应链数据中台在公司内部已经进行了多方面的应用,对企业实现电力供应链全流程的数据互通,形成高价值的数据资产及应用起到了重要作用,截至2021年上半年,华能智链数据中台系统已经连接了合约中心、资金管理等6个业务系统,为相关业务系统提供了40多个数据服务;集成并处理了5个业务系统的200多万条数据,形成了合约、客商等4大主题142类数据资产,研发了36个数据资产分析应用;通过整合原业务追踪可视化系统,研发了11类数据分析建模应用,现以如下几个应用为例介绍数据中台在公司业务中的具体应用情况。
4.1 电子商城周报
数据中台研发的电子商城周报功能,自动收集、处理商城商品的各类信息,以及来自京东、史泰博等多个渠道的商品价格数据,为商城管理人员自动生成商城信息周报,周报内容主要包括商城物资销售及供应统计信息和商城财务信息,应用截图如图8所示。

图8 电子商城周报应用截图Fig.8 Application Screenshot of the e-shop weekly
该功能使商城管理人员的工作所需时间从5人/天缩短至1人/5分钟。同时还提高了数据的准确性和完整性。
4.2 客商图谱
数据中台研发的客商图谱应用,通过从内外部收集和分析客商的工商、财税、合同履约、信用、物流、收付款情况与合作范围等几个方面的数据,展示每个客商的风控评级、履约能力、经营情况,回款能力等全方位信息,反映不同客商之间的关联关系,辅助公司进行客商优选与评估[27]。应用截图如图9所示:

图9 客商图谱应用截图Fig.9 Application screenshot of customer map
4.3 物资价格和购买行为分析
数据中台研发的物资价格和购买行为分析应用,如图10所示,通过对商城和线下物资的供销价格与购买行为进行分析,发现物资价格波动与供销量的关联关系,找出高需求量低价格的商品采购渠道及高利润的商品销售方式,辅助指导物资的购买行为,节省业务成本。

图10 物资供销价格与购买行为分析应用截图Fig.10 Application screenshot of material supply and sales price and purchase behavior analysis
4.4 仓储平衡利库和智能路径规划
本应用主要是指数据中台分析和处理物资供销及仓储数据,判断现有库存是否满足需求单位的物资供应需求,如果不满足,应该如何从不同的物资库中进行平衡调拨[28],并且给出各物资的调拨规划方案,包括取货顺序、取货数量,取货仓库等信息,然后将仍不满足的物资选出来供后续生成采购订单。最后根据需求物资的始发地和目的地,以及平衡利库的结果,结合交通路况,给出指定个数的运输路径方案。
5 结语
基于Hadoop和Flink的电力供应链数据中台是电力供应链与大数据技术的有效结合。基于数据质量管理和规范设计的数据安全体系和数据运营体系能够保障数据中台可以长期健康、持续运转。数据中台的各种数据服务、数据资产应用和大数据相关技术能够串联电力供应链上下游相关业务系统,实现智慧供应链“招”“购”“售”“运”“融”一站式服务能力[29-31],打通电力供应链各环节数据壁垒,实现数据贯通,发掘数据的价值,为不同客户提供更加灵活的供应链服务方案,提高各个参与方的黏性,实现共赢的电力供应链生态环境。
猜你喜欢
经济研究导刊(2022年25期)2022-11-05
房地产导刊(2022年10期)2022-10-18
今日农业(2022年16期)2022-09-22
工业设计(2022年8期)2022-09-09
现代计算机(2021年16期)2021-08-06
科学与财富(2021年36期)2021-05-10
军民两用技术与产品(2021年10期)2021-03-16
进出口经理人(2021年8期)2021-02-12
英语文摘(2020年9期)2020-11-26
小学阅读指南·低年级版(2020年11期)2020-11-16
