
基于协整分析的风力机多工况监测与故障诊断
2022-07-25 12:20汪千程文泽军
中国机械工程 2022年13期
汪千程 苏 春, 文泽军
1.东南大学机械工程学院,南京,2111892.湖南科技大学机械设备健康维护湖南省重点实验室,湘潭,411201
0 引言
风能储量丰富、分布广泛、污染小、可再生,因此其开发与利用受到广泛关注。风力机是风电系统的核心装备,常年工作于酷暑、寒冬、风沙等极端环境,其可靠运行面临挑战。
有效的状态监测与故障诊断对减少风力机的非计划停机、避免灾难性后果至关重要,现有的监测与诊断方法大致可分为数学模型方法、专家知识方法和数据驱动方法[1-2]。日趋复杂的工业装备导致精确的数学模型和完备的专家知识往往难以获取,装备中普遍安装的监控与数据采集(supervisory control and data acquisition,SCADA)系统使得数据驱动方法逐渐成为状态监测与故障诊断领域的重要发展方向。
QIN[3]采用主成分分析(principal component analysis,PCA)模型表征装备的正常与异常状态。NAMDARI等[4]采用支持向量机(support vector machine,SVM)模型完成装备早期的故障诊断。ZHAO等[5]提出一种稀疏相异度算法,以实现无先验故障信息的装备早期故障诊断。上述方法大多假定变量具有平稳性,难以描述非平稳变量之间的关系。
若一组非平稳的被测信号存在协整关系,利用协整分析(cointegration analysis,CA)可以消除信号的非线性趋势和环境因素等影响,获得协整残差模型,其残差序列可用于表征变量之间长期均衡的动态关系[6]。当被检测对象的残差偏离平稳状态时,表明被检测对象的状态出现异常。
陈前等[7]将协整理论用于非平稳工程系统的状态监测与故障诊断。ZHAO等[8]利用协整分析设置残差阈值,完成了风力机状态监测与齿轮箱故障预警。针对时变转速下轴承的损伤检测,TABRIZI等[9]提出一种基于协整的故障检测方法。为了消除环境因素和运行不确定性的影响,ZHANG等[10]采用协整分析实现风力机的状态监测。HU等[11]针对非平稳故障问题,提出一种双重协整分析的故障诊断策略。现有的协整分析研究主要关注装备正常和故障两种工况,但在工程实际中,装备通常存在多种运行工况,若不加以区分可能会造成故障误报[12],如受紊流、风向变化和相邻风力机干扰等因素影响,风力机常处于偏航状态,协整分析时的偏航状态会引起残差幅值超过正常阈值、造成故障误报。DAO等[13]将偏航状态定义为“异常运行状态”,采用协整分析监测风力机状态和齿轮箱故障,但在确定残差预警阈值时,该研究未能有效区分风力机偏航和齿轮箱故障两种状态,影响故障诊断的准确性。
本文提出一种基于协整分析的装备多工况监测与故障诊断方法,以SCADA系统的运行数据为基础,采用随机森林(random forest,RF)特征选择算法提取关键特征变量;通过对关键特征序列的协整分析建立协整残差模型,获得最优残差序列;基于残差序列,采用概率图(probability plot,PP)确定每种工况对应的残差区间和预警阈值,实现状态监测与故障预警。
1 问题描述与分析步骤
在系统和环境等多重随机因素的共同作用下,装备状态常呈现非平稳、多工况等特征[16]。协整分析适合处理非平稳时间序列长期均衡的动态关系,可用于装备状态监测与故障诊断。现有的协整分析模型存在以下不足[8-11,13,15]:①关键特征变量的选取多依靠经验或只针对某一类信号,适用范围有限,可能会导致关键特征缺失,影响模型精度;②残差阈值的设定主要基于统计过程控制(statistical process control,SPC)方法,难以有效划分多重工况,易造成故障误报,降低故障诊断的准确性。
为了解决上述问题,本文提出一种基于协整分析的装备多工况监测与故障诊断方法,该方法的主要步骤包括[15]:
(1)构建训练集。以SCADA系统收集的特征变量历史数据构建训练集,通过预处理剔除异常状态数据,得到正常运行状态下特征变量的时间序列{xj},j=1,2,…,J。
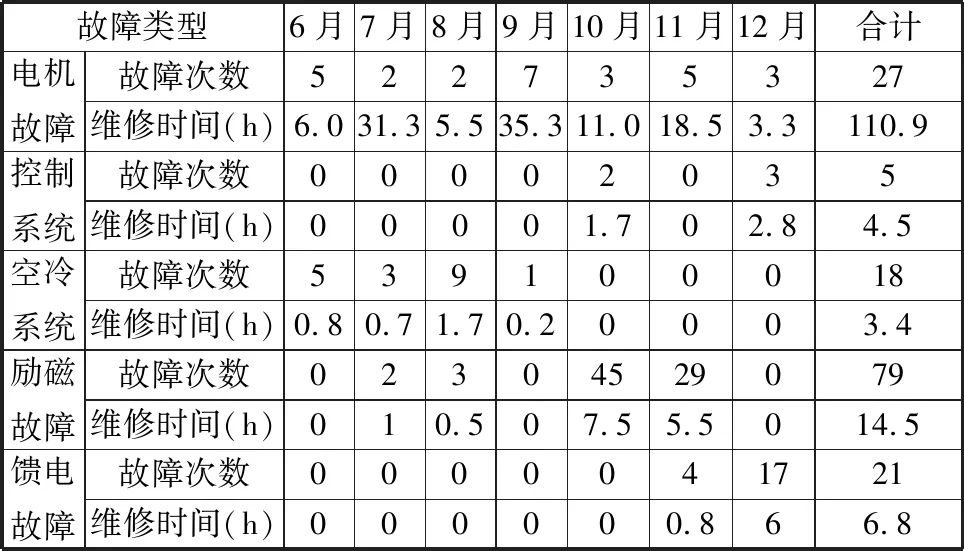
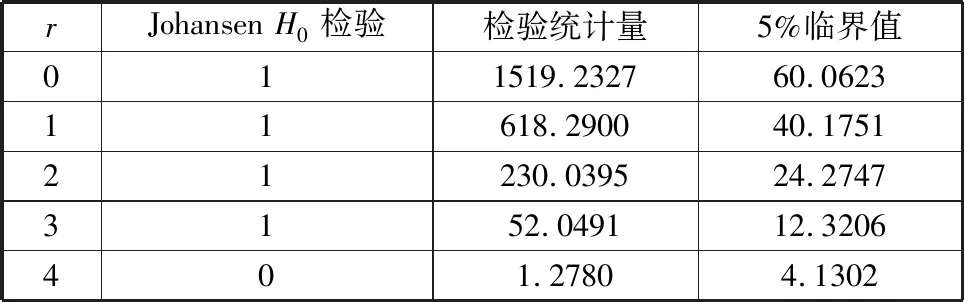
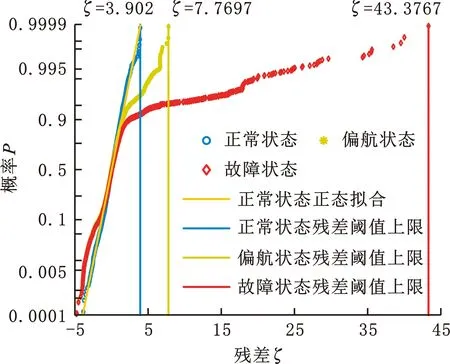
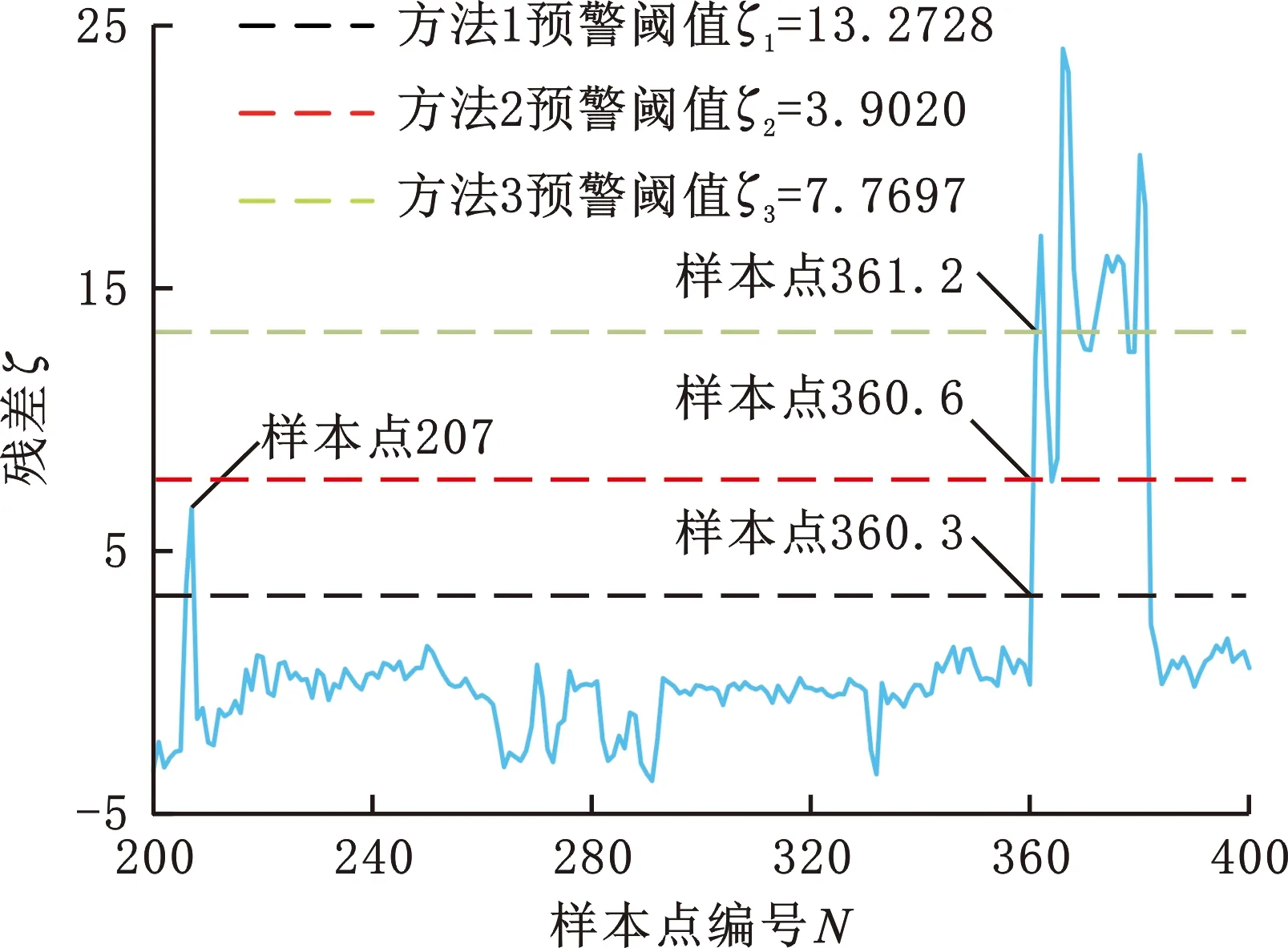
(2)提取关键特征变量。对序列{xj}采用随机森林特征选择算法,提取目标变量的关键特征序列{xj′},j′=1,2,…,J′;J′ (3)关键特征的增广迪基-富勒(augmented Dicky-Fuller,ADF)检验[15]。确定关键特征序列的单整阶数,即判断序列是否为一阶单整序列。 (4)关键特征的Johansen协整检验。确定关键特征的协整关系数目r并计算协整系数矩阵βr。 (5)构建测试集。以SCADA系统收集的关键特征运行数据构建测试集,保留异常状态数据,得到运行状态下关键特征的时间序列{zj′}。 (6)计算协整残差模型。基于协整系数矩阵βr以及构建的测试序列{zj′},计算协整残差模型ξ。 (7)协整残差模型的ADF检验。判断协整残差模型中各残差序列的平稳性,即是否为平稳时间序列。 (8)选取最优残差序列。以最大特征值对应的残差模型为最佳监测模型,其残差序列为最优残差序列。 (9)确定各工况的残差区间和预警阈值。利用概率图分析最优残差序列,划分多工况状态的残差区间,并确定每种工况对应的预警阈值。 (10)状态监测与故障诊断。观测装备运行中的残差是否超过设定的阈值,完成装备状态监测与故障预警。 随机森林是装袋算法的一个拓展体,采用重抽样技术从原始数据集中随机抽取数据构建决策树,在生成决策树的过程中引入随机特征选择策略,从海量特征中提取关键特征,达到降维和提升模型性能的目的[16]。 随机森林特征重要性的度量主要依据特征随机置换前后生成的袋外数据和袋外数据误差。袋外数据是指利用重抽样技术建立决策树时没有参与决策树构建的数据,这部分数据可以用于对决策树的性能进行评估。袋外数据误差为将袋外数据代入所建立的决策树而计算得到的模型预测误差率。特征置换后的袋外数据误差通常会增大,而特征重要性越高,随机森林袋外数据误差的变化值越大[16]。因此,通过分析特征置换前后袋外数据误差的变化,可评估每个特征对目标变量的重要性。 定义1 第k棵决策树的袋外数据 对于训练集D,通过bootstrap方法生成数据集Dk,建立第k棵决策树,则未参与第k棵决策树构建的数据D-Dk称为第k棵决策树的袋外数据Ok。 定义2 基于袋外数据误差的特征j重要性度量 将袋外数据分别代入各自的决策树,计算袋外数据误差,然后对袋外数据中的特征j进行随机置换,计算新的袋外数据误差。决策树在特征j置换前后的袋外数据误差的平均变化量即为特征j的重要性。 假设随机森林中的决策树总数为K,原始数据集有J个特征。对于特征j,基于袋外数据误差分析的特征重要性计算步骤如下: (1)计算第k棵决策树对应的袋外数据Ok和袋外数据误差Ek。 (2)保持其他特征不变,对Ok中的特征j进行随机序列置换,计算新的袋外数据Okj和袋外数据误差Ekj。 (3)重复步骤(1)、步骤(2),得到{Ek|k=1,2,…,K}和{Ekj|k=1,2,…,K;j=1,2,…,J}。 (4)计算决策树在特征j置换前后袋外数据误差的平均变化量[17]: (1) 式中,V(j)为特征j对于目标变量的重要性。 依次计算各特征对目标变量的重要性,按由大到小排序得到关键特征变量。 若一个时间序列在成为平稳序列之前需经过d(d>0)次差分,则称该序列为d阶单整,记作I(d)。如果序列{xit}(i=1,2,…,n)为d阶单整,且存在一个向量η=(η1,η2,…,ηn),使得η·Xt~I(d-b),其中,b>0,Xt=({x1t},{x2t},…,{xnt}),则称Xt为d-b阶协整,记作Xt~CI(d-b),η为协整系数[8]。 由协整的定义可知,如果一组变量具有保持线性关系的共同趋势,那么协整分析可以建立这种线性关系,即协整分析可以对两个或多个单整阶数均为一阶的非平稳序列进行线性组合,使其变为一个平稳序列。例如,{xit}为一阶单整的非平稳序列,如果它们满足协整关系,则存在一组系数a1,a2,…,al,使得φ=a1x1t+a2x2t+…+alxlt成立,其中,φ为协整残差。 对于非平稳时间序列,通常将其转变为平稳序列再开展相关研究。时间序列单位根检验也称为时间序列平稳性检验,常用方法是增广迪基-富勒检验。若非平稳时间序列存在单位根,则采用差分方法得到平稳序列。 3.2.1关键特征的ADF单位根检验 考虑下列回归模型: xt=ρxt-1+et (2) 式中,x0=0;t为观测时刻;ρ为系数;et~(0,σ2)为均值是0、标准差是σ的白噪声序列随机误差。 对于时间序列{xt},若|ρ|<1,则{xt}是平稳的;若|ρ|=1,则{xt}是非平稳的,{xt}的单整阶数为1并含有一个单位根。 变量yt的ADF检验方程为 Δyt=γyt-1+θ1Δyt-1+θ2Δyt-2+…+ θp-1Δyt-p+1+et (3) γ=ρ-1 其中,Δyt为yt的差分;{yt-1}为{yt}的一阶滞后序列;θi为系数,i=1,2,…,p-1;p为滞后阶数,通常采用赤池信息准则(Akaike information criterion,AIC)确定;Δyt-i为yt的i阶差分;et为随机误差[18]。 使用最小二乘法对式(3)中的系数γ进行估计,通过检验系数γ的t统计量,从而判断序列yt是否为一阶单整序列。检验假设H0:γ=0(yt非平稳);H1:γ<0(yt平稳)。计算系数γ的t检验统计量: (4) 式中,σγ为γ的标准差。 由ADF分布临界值表查得在给定显著性水平下对应γ的临界值。若tγ小于临界值,则拒绝H0假设,即原序列不存在单位根,是平稳时间序列;否则原序列不平稳,则必须对其差分进一步检验单位根,建立相应的检验模型再次开展假设检验,若差分序列的t检验统计量小于临界值,则拒绝H0假设,说明差分序列是平稳时间序列,原序列为一阶单整序列。 3.2.2关键特征的Johansen协整检验 假设有一阶单整分量的向量时间序列{yt},它的p阶向量自回归(vector auto regression,VAR)可以表示为 yt=A1yt-1+A2yt-2+…+Apyt-p+ξt (5) 式中,yt=(y1t,y2t,…,ymt)T是由m个一阶单整非平稳变量构成的m×1维向量,t=1,2,…,T;yt-1,yt-2,…,yt-p是与yt对应的p个m×1维滞后项;A1,A2,…,Ap为m×m维参数矩阵;ξt是m×1维残差向量。 式(5)两边同时减去yt-1完成差分变换,可得到对应于p阶向量自回归的误差修正模型[11]: (6) (7) 式中,Em为单位矩阵;α为调整系数矩阵;β为协整系数矩阵;ξt~N(0,Ω)为平稳的残差向量;Ω为ξt的方差。 α和β均为m×r维矩阵,其秩均为r。 整合式(6)、式(7),可得 (8) 为确定协整关系数目r和协整系数矩阵β,建立两个辅助回归方程,并完成系数的最小二乘估计[19]: (9) (10) 利用残差矩阵R0t、R1t构建积矩阵Swz(w,z=0,1): (11) 建立并求解特征值方程,可得协整系数矩阵β: (12) (13) 式中,λ为特征方程的解;βi(i=1,2,…,m)为λi的特征向量且λ1≥λ2≥…≥λm。 如果由r个最大的特征值给出了协整向量,则剩余m-r个非协整组合的特征值λr+1,λr+2,…,λm为0。以特征值的迹统计量Qr来检验变量的协整关系,给出Johansen检验假设H0:存在r(r=0,1,…,m-1)个协整关系。迹统计量Qr为[9] (14) 按顺序依次检验统计量Qr的显著性,Qr大于检验临界值时,拒绝H0假设,继续按顺序开展统计量显著性检验,直到检验假设H0不被拒绝为止。确定协整关系数目r后,即可得到协整系数矩阵βr,由此建立协整残差模型[20]: (15) ξt即为所求的协整残差模型。 若残差模型对应的r个残差序列均为平稳时间序列,则都可用于描述系统的稳定性。这r个残差序列中,最大特征值对应的模型包含系统信息最多,为最佳监测模型,称为最优残差序列。 3.3.1基于SPC的残差阈值确定方法 残差处于控制限之内表明装备运行正常;残差超出控制限,则认为装备运行异常。目前,利用最优残差序列确定装备状态残差区间和预警阈值的方法主要为:①以v±3σ为残差阈值的上下限即方法1,其中,v、σ分别为残差序列的均值和标准差;②以装备正常运行状态下残差的最大幅值、最小幅值确定残差阈值的上下限即方法2[8-11,13,15]。 上述两种方法均可用于装备状态监测和提前预警,但也存在不足:方法1残差阈值区间过大,提前预警效果较差,甚至会造成报警延误;方法2没有考虑装备运行中可能存在的多种工况,具有局限性。为此,本文基于概率图,提出考虑装备多重工况以确定残差阈值的第3种方法。 3.3.2基于概率图的残差阈值确定方法 概率图是根据样本的真实数据以及指定理论分布的累积概率所绘制的散点图,能直观检测样本数据是否符合某一概率分布。由统计学理论可知:若样本总体服从正态分布,则它在散点图上近似呈一条直线[21]。 装备正常运行时,残差序列多服从正态分布,具体表现为:均值附近的概率较大;离均值越远,点越少、出现的概率越小。装备出现异常时,系统会偏离正常状态,输出的残差幅值也会偏离正常值,概率密度曲线将出现偏移,正常状态下发生概率较小的数据点会大量出现[12]。因此,通过概率图拟合得到的最优残差序列,绘制多重工况概率图,根据不同工况下残差序列小概率点对应的残差最小幅值、最大幅值,可以确定各工况对应的残差分布区间及预警阈值,实现装备多工况状态监测与故障诊断。 本节以某风电场3 MW直驱式风力机为研究对象,利用其2014年6月至12月的SCADA数据和故障维修数据进行分析,已知该风力机每隔10 min获取一条状态数据。根据零部件类型,故障可分为电机故障、控制系统故障、空冷系统故障、励磁故障和馈电故障,故障统计如表1所示。 表1 故障次数及维修时间 由表1可知,电机故障导致的维修时间最长,因此,本文主要考虑风力机正常、偏航和电机故障3种状态,其中,正常和偏航状态下的电机状况良好,但利用协整分析进行状态监测与故障诊断时,偏航状态会引起残差幅值超过正常阈值,造成电机故障误报。为排除这一干扰,本文提出一种装备多工况监测与故障诊断方法,具体分析过程如下。 已知该风力机SCADA系统采集风速、转速、功率、环境温度等42个特征变量,利用随机森林特征选择算法提取反映电机故障的关键特征变量。由文献[22]可知,转速是能反映电机故障与否的有效特征变量。对SCADA数据进行预处理,筛除异常状态数据,得到正常运行状态下各特征变量的时间序列,以转速作为随机森林的输出变量,将其余41个特征作为随机森林的输入变量,计算得到最重要的前4个特征变量:风速、功率、无功功率和定子温度2。绘制上述关键特征的时间序列,如图1所示。 (a)风力机风速时间序列 (b)风力机转速时间序列 (c)风力机功率时间序列 (d)风力机无功功率时间序列 (e)风力机定子温度2时间序列图1 风力机正常运行状态的SCADA数据Fig.1 SCADA data under normal operation of wind turbine 由图1可知,风力机运行环境的变化使其特征变量的变化为典型的非平稳随机变化。ADF检验表明上述5个特征变量均为非平稳时间序列,一阶差分后可得到平稳时间序列,即原序列均为一阶单整序列。通过AIC准则确定模型的滞后阶数为5。利用Johansen协整检验确定协整关系的数目,如表2所示。 风力机的风速、转速、功率、无功功率和定子温度2之间存在4个协整关系,计算可以得到4个协整向量,由4列的协整向量组成的协整系数矩阵为 (16) 将协整系数矩阵β代入式(15),并结合SCADA系统收集的关键特征运行数据,计算得到协整残差模型: 表2 Johansen协整检验结果 (17) Johanson协整检验是基于最大特征值的统计方法,特征值越大,对应模型包含的信息越多,监测系统运行状态的能力越好。残差模型的特征值是从大到小排列的,故选取特征值最大的残差模型ξ1t进行归一化处理,得到风力机运行状态的最佳监测模型: ξ1t=y1t-0.7794y2t-0.0022y3t+ 0.0319y4t+0.0076y5t (18) 将风力机的上述5个特征变量代入式(18),构造最优残差序列并开展ADF检验,得到检验值为-13.29,小于5%临界值-1.9416,表明最优残差序列为平稳时间序列,可用于评估风力机的运行状态。 为排除因风速未达到切入风速导致的偏航状态对风力机电机故障诊断的干扰,本文将风力机分为正常、偏航、电机故障3种状态。通过数据预处理得到3种状态对应的残差序列,其中,电机故障状态残差序列包含故障数据、偏航数据和正常数据,偏航状态残差序列包含偏航数据和正常数据,正常状态残差序列只包含正常数据。绘制3种状态的残差序列概率图(图2)。 图2 风力机3种状态的残差分布概率图Fig.2 Probability plot ofresidual distribution of 3 states of wind turbine 风力机正常状态的残差区间为[-3.8957,3.9020],偏航状态的残差区间为[-4.8234,7.7697],故障状态的残差区间为[-4.8234,43.3767]。当风力机出现偏航和故障时,残差下限变化不大,而残差上限会出现明显偏离,因此,本文通过分析3种状态的残差上限完成工况划分。残差幅值3.9020是风力机正常状态与偏航状态的分界线,残差幅值7.7697是风力机偏航状态与电机故障状态的分界线,从而得到如下的划分结果:风力机正常状态的残差区间为[-4.8234,3.9020],偏航状态的残差区间为(3.9020,7.7697],电机故障状态的残差区间为(7.7697,43.3767]。 取同一台风力机运行状态下的SCADA数据来验证模型、残差预警阈值的有效性。根据风力机SCADA系统采集的数据可知,在样本点207附近,风速未达到切入风速,风力机转速和功率很小,处于偏航状态;在样本点362附近,风速达到切入风速,但风力机转速和功率很小,处于电机故障状态。根据得到的最优残差序列,利用基于概率图的残差阈值确定方法(方法3)进行分析,并与基于统计过程控制的残差阈值确定方法(方法1和方法2)进行比较,结果如图3所示。 图3 不同残差阈值确定方法的工况划分Fig.3 Condition division of different residual threshold determination methods 由图3可知,根据概率图确定的电机故障预警阈值为7.7697,风力机在样本点360.6时,残差幅值超出方法3确定的阈值上限,此时风力机电机发生故障。而利用SCADA系统直接进行监测,直到样本点362时系统才会发出电机故障警报。风力机每隔10 min记录一个样本点,获取一条状态数据,故与传统方法相比,方法3能提前14 min监测到电机故障。根据残差序列均值和标准差确定的电机故障预警阈值为13.2728,即方法1在样本点361.2时发出警报,并能较准确地识别出电机故障,但报警提前期仅为8 min,提前预警能力不如方法3。根据正常状态下残差序列最大幅值确定的电机故障预警阈值为3.902,即方法2在样本点360.3时发出警报,能提前17 min识别出电机故障,但不能有效排除样本点207时偏航状态造成的干扰,预警准确度不如方法3。 本文基于风力机的SCADA数据,在协整分析的基础上集成随机森林和概率图等理论,针对非平稳多工况的装备提出一种状态监测与故障诊断方法。本文在协整分析之前利用随机森林特征选择算法、提取关键特征,提高了协整残差的精度。在协整分析之后提出基于概率图的残差阈值确定方法,有效实现了多种工况的状态监测与提前预警,提高了故障诊断的准确性。 后续可结合不同类型工业装备以及故障类型展开故障诊断方法研究。此外,可根据装备不同月份、季度故障次数的统计,寻找其季节性特征,并通过调整装备故障诊断的残差阈值,开展维修策略优化研究。2 基于随机森林的关键特征提取
2.1 随机森林特征重要性度量方法
2.2 随机森林特征重要性计算步骤
3 基于协整分析的建模
3.1 单整与协整的定义
3.2 协整分析建模步骤
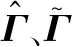
3.3 协整残差区间和预警阈值的确定
4 案例分析

5 结论
猜你喜欢
农业工程学报(2022年7期)2022-07-09
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
能源工程(2021年1期)2021-04-13
北京航空航天大学学报(2020年10期)2020-11-14
船舶与海洋工程(2019年6期)2019-12-25
北京航空航天大学学报(2019年9期)2019-10-26
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
智富时代(2018年3期)2018-06-11
