
采用分类经验回放的深度确定性策略梯度方法
2022-08-01 01:42时圣苗
自动化学报 2022年7期
时圣苗 刘 全 ,2,3,4
强化学习(Reinforcement learning,RL)中,Agent 采用“试错”的方式与环境进行交互,通过从环境中获得最大化累积奖赏寻求最优策略[1].RL算法根据Agent 当前所处状态求解可执行动作,因此RL 适用于序贯决策问题的求解[2].利用具有感知能力的深度学习作为RL 状态特征提取的工具,二者结合形成的深度强化学习(Deep reinforcement learning,DRL)算法是目前人工智能领域研究的热点之一[3−4].
在线DRL 算法采用增量式方法更新网络参数,通过Agent 与环境交互产生经验样本e(st,at,rt,st+1),直接将此样本用于训练网络参数,在一次训练后立即丢弃传入的数据[5].然而此方法存在两个问题:1)训练神经网络的数据要求满足独立同分布,而强化学习中产生的数据样本之间具有时序相关性.2)数据样本使用后立即丢弃,使得数据无法重复利用.针对以上问题,Mnih 等[6]采用经验回放的方法,使用经验缓冲池存储经验样本,通过随机选取经验样本进行神经网络训练.然而经验回放方法中未考虑不同经验样本具有不同的重要性,随机选取无法充分利用对网络参数更新作用更大的经验样本.Schaul 等[7]根据经验样本的重要性程度赋予每个样本不同的优先级,通过频繁选取优先级高的经验样本提高神经网络训练速度.优先级经验回放一方面增加了对经验样本赋予和更改优先级的操作,另一方面需要扫描经验缓冲池以获取优先级高的经验样本,因此增加了算法的时间复杂度.与优先级经验回放不同,本文提出的分类经验回放方法对不同重要性程度的经验样本分类存储.将此方法应用于深度确定性策略梯度(Deep deterministic policy gradient,DDPG)算法中,提出了采用分类经验回放的深度确定性策略梯度(Deep deterministic policy gradient with classified experience replay,CER-DDPG)方法.CER-DDPG 采用两种分类方式:1)根据经验样本中的时序差分误差(Temporal difference-error,TD-error);2)基于立即奖赏值进行分类.其中,TD-error 代表Agent 从当前状态能够获得的学习进度,RL 经典算法Sarsa、Qleaning 均采用一步自举的方式计算TD-error 实现算法收敛.CER-DDPG 中,将大于TD-error 平均值或立即奖赏平均值的经验样本存入经验缓冲池1 中,其余存入经验缓冲池2 中.网络训练时每批次从经验缓冲池1 中选取更多数量的样本,同时为保证样本的多样性,从经验缓冲池2 中选取少量的经验样本,以此替代优先级经验回放中频繁选取优先级高的经验样本.分类经验回放方法具有和普通经验回放方法相同的时间复杂度,且未增加空间复杂度.
本文主要贡献如下:
1) 采用双经验缓冲池存储经验样本,并根据经验样本中的TD-error 和立即奖赏值完成对样本的分类;
2) 从每个经验缓冲池中选取不同数量的经验样本进行网络参数更新;
3) 在具有连续动作空间的RL 任务中进行实验,结果表明,相比随机采样的DDPG 算法,本文提出的基于时序差分误差样本分类的深度确定性策略梯度方法(DDPG with temporal difference-errer classification,TDC-DDPG)和基于立即奖赏样本分类的深度确定性策略梯度方法(DDPG with reward classification,RC-DDPG)能够取得更好的实验效果.并与置信区域策略优化(Trust region policy optimization,TRPO)算法以及近端策略优化(Proximal policy optization,PPO)算法进行比较,进一步证明了本文所提出算法的有效性.
1 背景
1.1 强化学习
马尔科夫决策过程(Markov decision process,MDP)是序贯决策的经典形式,其中动作不仅影响到立即奖赏,同样影响后续的状态或动作,以及采取后续动作所获得的未来奖赏.因此,通常使用MDP对RL 问题进行建模,将RL 问题定义为一个五元组 (S,A,P,R,γ).S表示状态空间,A表示动作空间,P:[0,1]表示状态迁移概率,R:R为奖赏函数,γ为折扣因子[8].通过MDP 可以构建Agent 与环境的交互过程,每一离散时间步t,Agent 接收到来自环境的状态表示st,在此基础上执行动作at.该时间步之后,Agent 收到来自环境反馈的标量化奖赏rt并处于下一状态st+1.
Agent 执行的动作由策略 π 定义,策略 π 为状态映射到每个动作的概率:(A).RL 的目标为求解最优策略π∗,在遵循策略π∗的情况下能够获得最大的累积奖赏其中,T表示该情节终止时间步.
状态动作值函数Qπ(s,a) 表示Agent 在当前状态st下执行动作at,遵循策略 π 所获得的期望累积奖赏

Qπ(s,a)满足具有递归属性的贝尔曼方程

迭代计算贝尔曼方程可实现值函数的收敛.当前时刻状态动作估计值函数与更好地估计rt+1+γQπ(st+1,at+1)之间的误差称为TD-error

通过求解状态动作值函数仅局限于解决具有离散动作空间的RL 问题,面对具有连续动作空间的RL 问题,策略梯度方法提供了解决问题的方式[9].
1.2 深度确定性策略梯度方法
RL 算法分为基于值函数和基于策略两种方法.基于策略的方法可以解决大状态动作空间或连续动作空间RL 问题[10].确定性策略梯度(Deterministic policy gradient,DPG)方法以行动者−评论家(Actor-critic,AC)算法为基础,通过行动者将状态映射到特定动作,评论家利用贝尔曼方程实现值函数的收敛[11−12].
DDPG 中,使用深度神经网络作为非线性函数逼近器构造行动者µ(s|θµ) 和评论家Q(s,a|θQ) 的网络模型.受到深度Q 网络(Deep Q-network,DQN)的启发,设置行动者目标网络µ′(s|θµ′) 和评论家目标网络Q′(s,a|θQ′).由于DPG 中行动者将状态映射到确定动作,因此解决连续动作空间RL任务存在缺乏探索性问题[13].DDPG 算法通过添加独立于行动者网络的探索噪声Noise构造具有探索性的行动者网络µ′[14]

网络模型学习时,评论家网络通过最小化损失函数L(θQ) 更新网络参数

其中,

行动者网络采用蒙特卡罗方法进行采样以逼近期望值,可通过链式法则近似更新行动者网络参数,如式(7)所示

目标网络采用“soft”更新方式,通过缓慢跟踪学习的网络更新参数

“soft”更新方式使得不稳定问题更接近于监督学习,虽减慢了目标网络参数更新速度,但在学习过程中能够获得更好的稳定性.
DDPG 同样用到了经验回放机制,将行动者网络与环境交互产生的经验样本e=(st,at,rt,st+1)存入经验缓冲池中,网络训练时通过从经验缓冲池中随机选取每批次经验样本用于网络参数的更新.随机选取方式未考虑不同经验样本的重要性,如何更有效利 用缓冲池中的样本数据成为经验回放机制面临的主要挑战.
2 采用分类经验回放的DDPG 算法
本节将介绍CER-DDPG 算法的思想和结构,对采用的分类方法分析说明,最后描述算法流程并分析.
2.1 分类经验回放
经验回放机制在消除数据样本之间关联性的同时能够提高样本利用率.在Agent 与环境交互产生的经验样本中,不同经验样本对网络训练所起作用不同,某些经验样本比其他经验样本更能有效地促进网络模型学习.等概率选取每一个经验样本会在简单样本上花费较多的时间,增加了算法训练时间步数.因此,本文所提出的分类经验回放方法最主要的一点是对不同重要性程度经验样本分类存放,在网络模型学习时分别从不同类别经验样本中选取每批次样本数据.对于重要性程度高的经验样本,每批次以较多数量选取,同时为保证样本数据多样性,每批次选取少量重要性程度低的经验样本.
TDC-DDPG 中,使用两个经验缓冲池存放经验样本.初始化网络模型时,将两个经验缓冲池中所有样本TD-error 的平均值设置为0.每产生一条新的经验样本,首先更新所有经验样本TD-error的平均值,再将该条样本数据的TD-error 与平均值进行比较,若该经验样本中的TD-error 大于所有样本TD-error 的平均值,则将该样本存入经验缓冲池1 中,否则存入经验缓冲池2 中.
RC-DDPG 方法根据经验样本中的立即奖赏值进行分类,具体分类方法与TDC-DDPG 方法相同.CER-DDPG 算法结构如图1 所示.
图1 中,在每一时间步t,行动者网络执行动作at,产生经验样本e=(st,at,rt,st+1) 后,首先对该样本数据进行分类,然后再进行存储操作.优先级经验回放中使用一个经验缓冲池存储所有经验样本,根据样本不同重要性程度赋予每个样本不同优先级,网络训练时扫描经验缓冲池获取经验样本,通过更频繁地选取优先级高的样本加快网络模型训练速度.CER-DDPG 方法在经验样本存储前,将其按照重要性程度分类,减少了赋予以及更改优先级的操作,并且在选取每批次数据样本时从不同经验缓冲池中随机选取,不需要扫描经验缓冲池,能够获取高重要性程度经验样本的同时减少了算法时间复杂度.

图1 CER-DDPG 算法结构示意图Fig.1 CER-DDPG algorithm structure diagram
分类经验回放中最关键的是经验样本分类的衡量标准.本文提出的CER-DDPG 方法分别采用经验样本中的TD-error 和立即奖赏值对样本进行分类.
1) TD-error 经验样本分类.DDPG 算法中,评论家采用时序差分误差的形式对行动者网络做出的动作选择进行评价,网络参数更新时使用一步自举的方式计算TD-error,TD-error 反映了Agent 从当 前状态经验样本中的学习进度,利用TD-error尤其适用于增量式DRL 算法参数的更新.因此,TDCDDPG 中根据经验样本TD-error 进行分类,认为TD-error 大的经验样本对神经网络参数更新幅度更大,重要性程度更高,并将TD-error 值大于平均值的经验样本存入经验缓冲池1 中.
2)立即奖赏经验样本分类.神经科学研究表明啮齿动物在清醒或睡眠期间海马体中会重播先前经历的序列,与奖赏相关的序列会更频繁地被重播[15−16].受到该观点启发,RC-DDPG 方法中根据经验样本中的立即奖赏值对样本进行分类,认为立即奖赏值大的经验样本重要性程度更高,将立即奖赏值大于平均值的经验样本存入经验缓冲池1 中,其余存入经验缓冲池2 中.
2.2 算法
为更有效地利用经验样本以及提高经验回放机制的效率,将对经验样本的分类方法应用到DDPG算法中,提出的CER-DDPG 算法描述如算法1 所示:
算法1.采用分类经验回放的深度确定性策略梯度方法


算法1 中,第3 步为对行动者网络添加探索噪声过程,第 5~7 步为产生经验样本的过程,第8~9步为经验样本的分类和获取过程,第10~13步为网络模型学习过程.
由于不同任务中Agent 每一时刻获得的立即奖赏值不同,因此产生的经验样本TD-error 和立即奖赏值存在差异,难以采用固定数值作为分类的衡量标准.CER-DDPG 方法中,使用TD-error 和立即奖赏平均值进行样本分类,并且在产生经验样本过程中不断更新TD-error 和立即奖赏平均值,能够动态性地将不同经验样本准确分类.分类经验回放方法相比普通经验回放方法仅增加了 O(1) 的时间复杂度,可忽略不计.优先级经验回放中根据优先级大小频繁选取优先级高的经验样本,CERDDPG 方法通过每批次从经验缓冲池1 中选取较多样本数量同样能够选取到重要性程度高的样本,与优先级经验回放相比,CER-DDPG 方法效率更高.
3 实验
为验证CER-DDPG 方法的有效性,在OpenAI Gym 工具包中MuJoCo 环境下进行实验测试.Mu-JoCo 环境包含了一系列具有连续动作空间的RL任务,本文分别在HalfCheetah、Ant、Humanoid、Walker、Hopper 和Swimmer 任务中进行测试.实验以深度确定性策略梯度(DDPG) 算法作为baseline,分别以TD-error 分类的深度确定性策略梯度(TDC-DDPG)方法和立即奖赏分类的深度确定性策略梯度(RC-DDPG)方法进行对比实验.
3.1 实验参数设置
为保证实验对比公平性,本文实验参数设置与参考文献中DDPG 算法一致,TRPO 与PPO 算法来自OpenAI baselines 算法集.对行动者网络添加的噪声均使用参数相同的Ornstein-Uhlenbeck 噪声分布,每批次样本数量均相等.DDPG 中,经验缓冲池大小设置为1 000 000,批次选取样本数量取N64.TDC-DDPG 和RC-DDPG 中,D1和D2均为500 000,批次样本数量取N148,N216.每情节最大时间步数设置为Tmax1 000,时间步数超过1 000 时情节重新开始.行动者网络学习率αµ1×10−4,评论家网络学习率αQ1×10−3.折扣因子γ0.99,目标网络更新时τ0.001.
3.2 实验结果及分析
图2 展示了在不同任务中3 种算法的实验效果,每个任务训练500 个阶段,每阶段包含2 000 个时间步,通过对比每个训练阶段获得的平均累积奖赏衡量算法优劣.
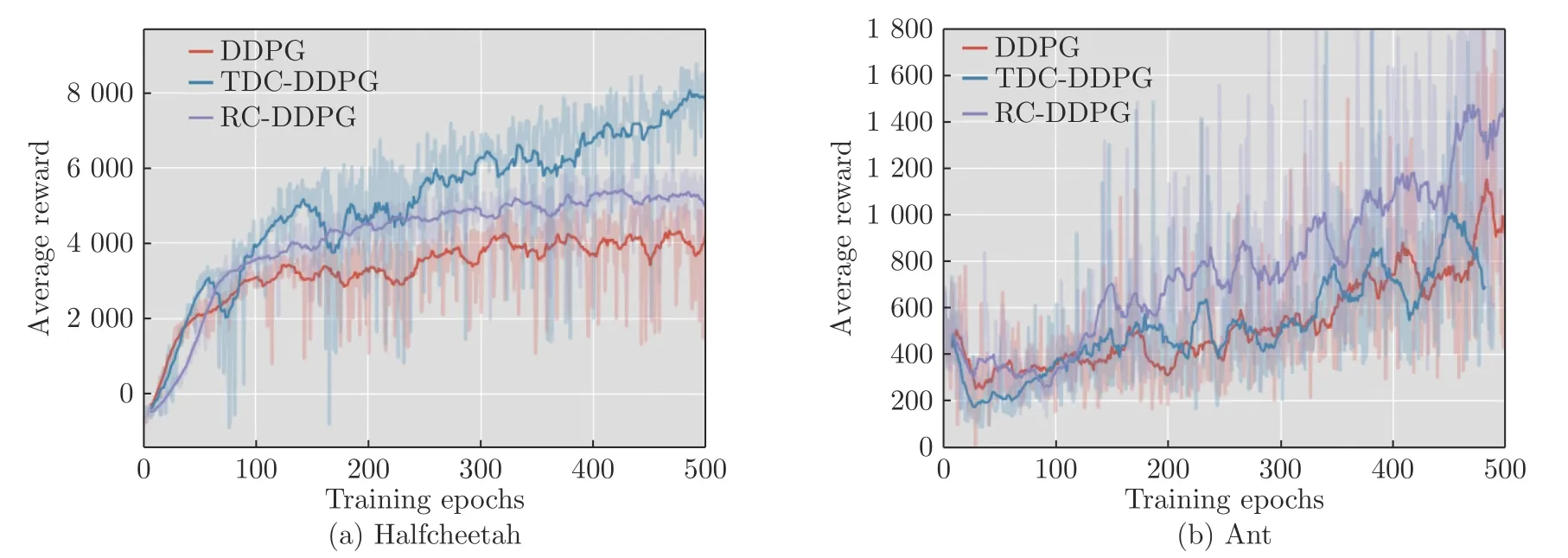
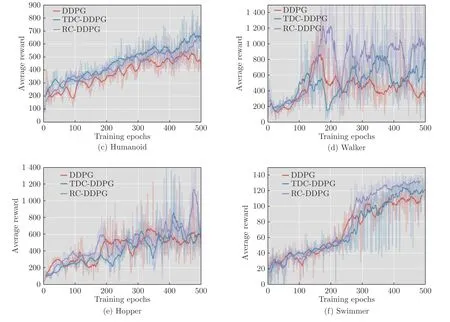
图2 实验效果对比图Fig.2 Comparison of experimental results
如图2 所示,在大多数任务中TDC-DDPG 和RCDDPG 算法性能优于随机选取经验样本的DDPG算法,说明采用分类经验回放的方法能够选取到对网络模型学习更有效的经验样本,在相同训练阶段内学习到累积奖赏更高的策略.
在HalfCheetah 任务中,通过控制双足猎豹Agent 快速奔跑获取奖赏.在网络模型训练的初始阶段中3 种算法均能够取得较快学习速度.而第20 个训练阶段后,DDPG 算法表现趋于平稳,TDCDDPG 和RC-DDPG 算法仍然能够以较快的学习速度提升算法性能,最终训练阶段具有明显优势.
在Humanoid 和Swimmer 任务中,训练初始阶段TDC-DDPG 和RC-DDPG 算法优势并不显著,随着训练时间步的增加,在训练阶段后期算法优势逐渐明显.因为在这两个任务中,每一时间步Agent获得的立即奖赏值在很小的范围内波动,导致RCDDPG 方法中两个经验缓冲池中样本类型很相近,TDC-DDPG 方法根据经验样本TD-error 分类,立即奖赏值同样会影响到TD-error 的大小,因此初始训练阶段算法性能优势表现不明显.然而在Walker任务中,每一时间步获得的立即奖赏值大小不均导致3 种算法训练得到的实验结果波动性均较大,但本文提出方法实验效果更优.
Hopper 任务通过控制双足机器人Agent 向前跳跃获取奖赏.由于状态动作空间维度低,Agent会执行一些相似动作导致经验样本相似,因此分类经验回放方法性能提升不明显.
表1 展示了500 个训练阶段内3 种算法在不同任务中所取得的平均奖赏值、最高奖赏值以及标准差.

表1 连续动作任务中实验数据Table 1 Experimental data in continuous action tasks
从表1 可以看出,与DDPG 方法相比,TDCDDPG 和RC-DDPG 方法取得的平均奖赏和最高奖赏值更高,不同训练阶段累积奖赏值差异更大,导致标准差更大.
为进一步证明算法的有效性,在HalfCheetah、Ant、Humanoid 和Swimmer 任务中增加了与TRPO 算法以及PPO 算法的对比实验.从图3 可看出,TDC-DDPG 和RC-DDPG 方法在与最新策略梯度算法比较中同样取得了更好的实验效果.
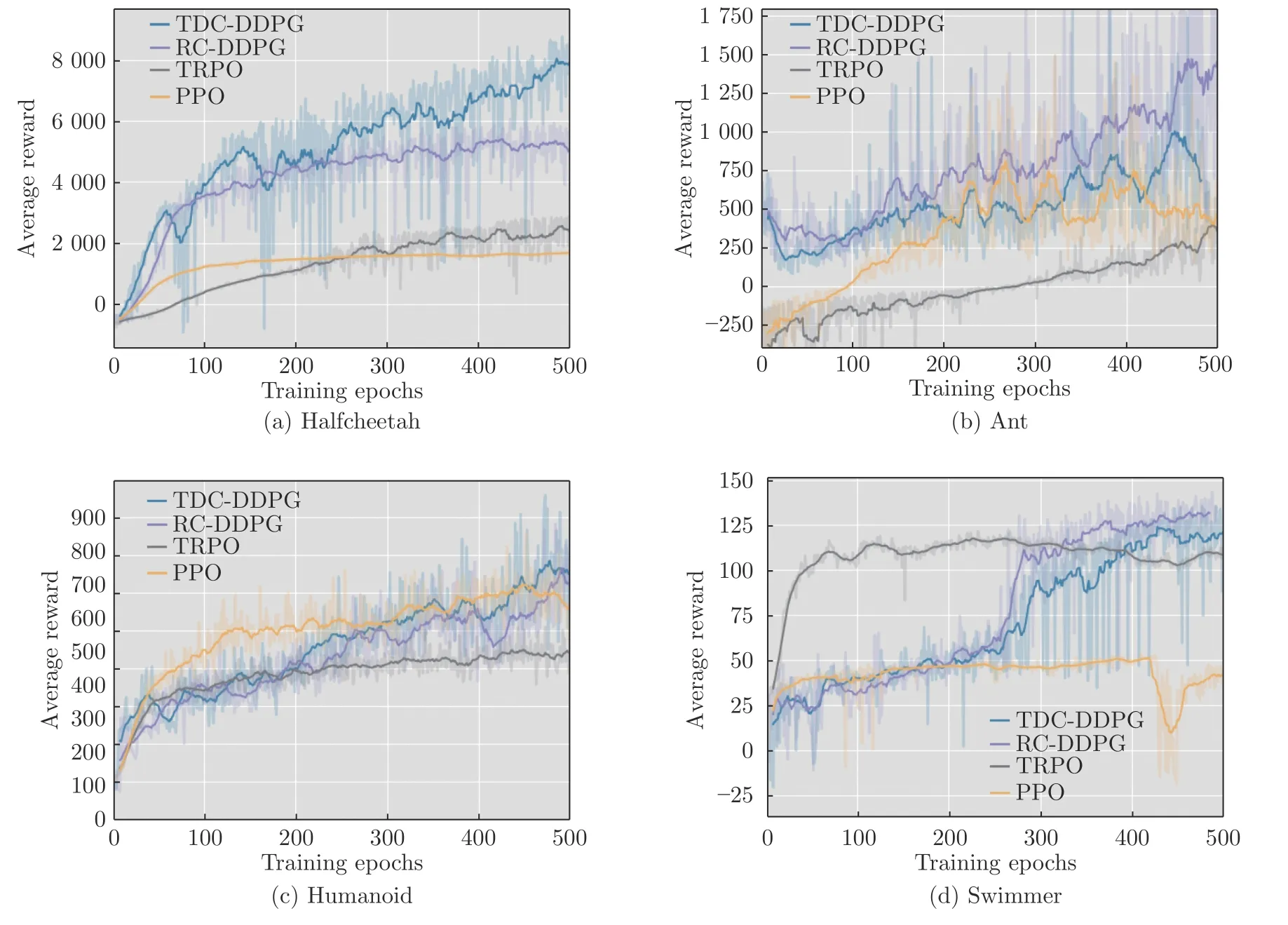
图3 CER-DDPG 与最新策略梯度算法的实验对比Fig.3 Experimental comparison of CER-DDPG with the latest policy gradient algorithm
4 结束语
DDPG 算法在解决连续动作空间RL 问题上取得了巨大成功.网络模型学习过程中,使用经验回放机制打破了经验样本之间存在的时序相关性.然而经验回放未考虑不同经验样本的重要性,不能有效利用样本数据,对样本设置优先级又增加了算法时间复杂度.因此,本文提出分类经验回放方法并利用经验样本的TD-error 和立即奖赏值进行分类存储用于解决经验回放中存在的问题.在具有连续状态动作空间RL 任务中的实验结果表明,本文提出的TDC-DDPG 和RC-DDPG 方法在连续控制任务中表现更优.
猜你喜欢
贵州社会科学(2022年8期)2022-10-12
党课参考(2021年20期)2021-11-04
中学生数理化·高一版(2021年2期)2021-03-19
体育科技(2020年5期)2020-04-02
长江丛刊(2018年4期)2018-11-14
党课参考(2018年20期)2018-11-09
领导决策信息(2018年16期)2018-09-27
当代经济(2017年7期)2017-04-26
数学学习与研究(2017年3期)2017-03-09
科学大众(中学)(2015年11期)2015-12-09
