
基于PSO-BP的混凝土配比设计的仿真研究
2022-08-04 05:40刘清
长春师范大学学报 2022年6期
刘 清
(闽南理工学院土木工程学院,福建 石狮 362700)
0 引言
混凝土配比的设计就是找寻适当比例的水泥、骨料、水、外加剂等组成成分,得到符合要求性能的混凝土,并且尽可能地降低成本[1]。普通混凝土的传统配比设计方法是计算-适配法,或基于逐级填充原理,或假定容量法和绝对体积法,将制成的混凝土试验标本养护到28天,测试其相关性能[2]。对于高性能混凝土,国内外提出了很多方法。其中,法国路桥中心对高性能混凝土配比设计的研究比较先进[3],其主要思想是在模型材料上用胶结浆体进行大量的流变试验,并用砂浆进行力学实验,避免了用直接的方法优化配比参数时进行的大量试配工作。混凝土配比的设计方法不仅可以参照普通混凝土的设计方法,也可针对原材料的特点需要进行特殊的配比设计,例如再生混凝土的再生骨料预吸收法[4]。但一般都是依靠人为的经验来决定混凝土产制的和易性、隐蔽性和安全性这三大特性[5],导致混凝土的质量和性能不够稳定,而且生产上的随意更改会引起管理上的混乱,造成对成品无法控制。本文以混凝土28天抗压强度作为衡量混凝土性能的一项重要参数,采用粒子群算法加神经网络来建立混凝土强度与配比之间的关系模型,提高混凝土搅拌站配料的精度,以此来提高成品混凝土的质量和性能,同时达到降低生产成本的目的。
1 BP神经网络模型概述
1.1 BP神经网络原理
BP神经网络是目前应用最广泛的神经网络模型之一,是1986年以Rumelhart和McCelland为首的科学家提出的一种按照误差逆传播算法训练的多层前馈网络。BP神经网络模型包括输入层(input layer)、隐层(hidden layer)和输出层(output layer)。在进行神经网络训练前,需要对网络的输入、输出参数进行归一化处理。归一化处理公式如下:
(1)
(2)

对样本数据进行归一化处理,可以减轻人工神经网络的训练难度,还可以让那些比较大的数据仍然落在神经元转换梯度大的地方。根据样本数据建立网络模型,确定神经网络的输入输出参数和隐层单元数。
1.2 PSO优化神经网络
粒子群算法(Particle Swarm Optimization,PSO)是一种并行算法,由KENNEDY J和EBERHART R C等开发出的一种优化算法[6]。将BP网络神经元之间的所有权阈值编码成实数向量,按照粒子群算法进行迭代,每次迭代过后将向量还原为权阈值,在进行所有样本的训练,计算均方差。自行设定系统允许的最大误差,如果迭代过后的均方差小于预设值,则计算结束,输出结果,否则继续迭代,直到迭代次数达到设定的最大值。
1.2.1 基本原理
BP神经网络的激活函数采用Sigmoid函数,然后用PSO算法搜索出最佳位置,使如下均方差指标达到最小:
(3)
其中,N为样本个数;c为神经网络输出的个数;tk,p为第p个样本的第k个理想输出值;Yk,p为第p个样本的第k个实际输出值。
1.2.2 实现步骤
步骤一,确定网络允许的最大误差、最大迭代次数、最大速度、搜索范围、确定粒子数。步骤二,根据粒子群规模,随机产生一定数目的个体Xi以及其速度Vi。不同的个体代表神经网络的一组不同混凝土配比值。步骤三,根据适应度函数计算每个粒子的优劣程度。步骤四,比较适应度,找到每个粒子的局部最优值和各代粒子的所有的最优值。步骤五,检验是否达到结束要求,若满足则输出混凝土配比,若不满足则继续迭代出下一组混凝土配比值,直到达到要求。
1.3 数据来源
现有数据是混凝土各自组成成分的用量以及对应的28天抗压强度值,见表1。本数据来自史峰和王辉的《MATLAB智能算法30个案例分析》[7],其中,1~9组数据为训练集,用于建立神经网络模型;10~19组为测试集,用于测试模型的预测能力。
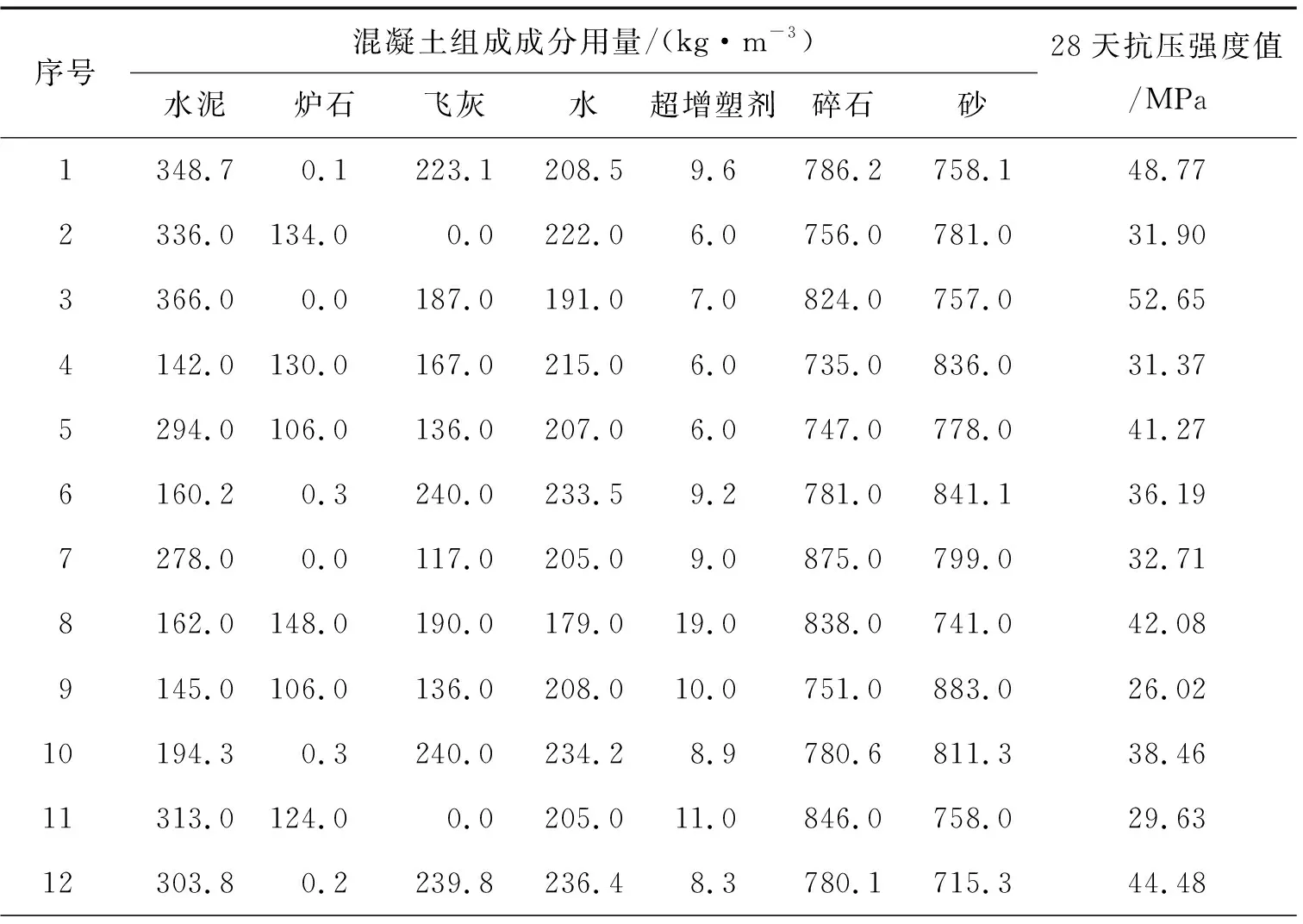
表1 混凝土组成成分用量原始数据
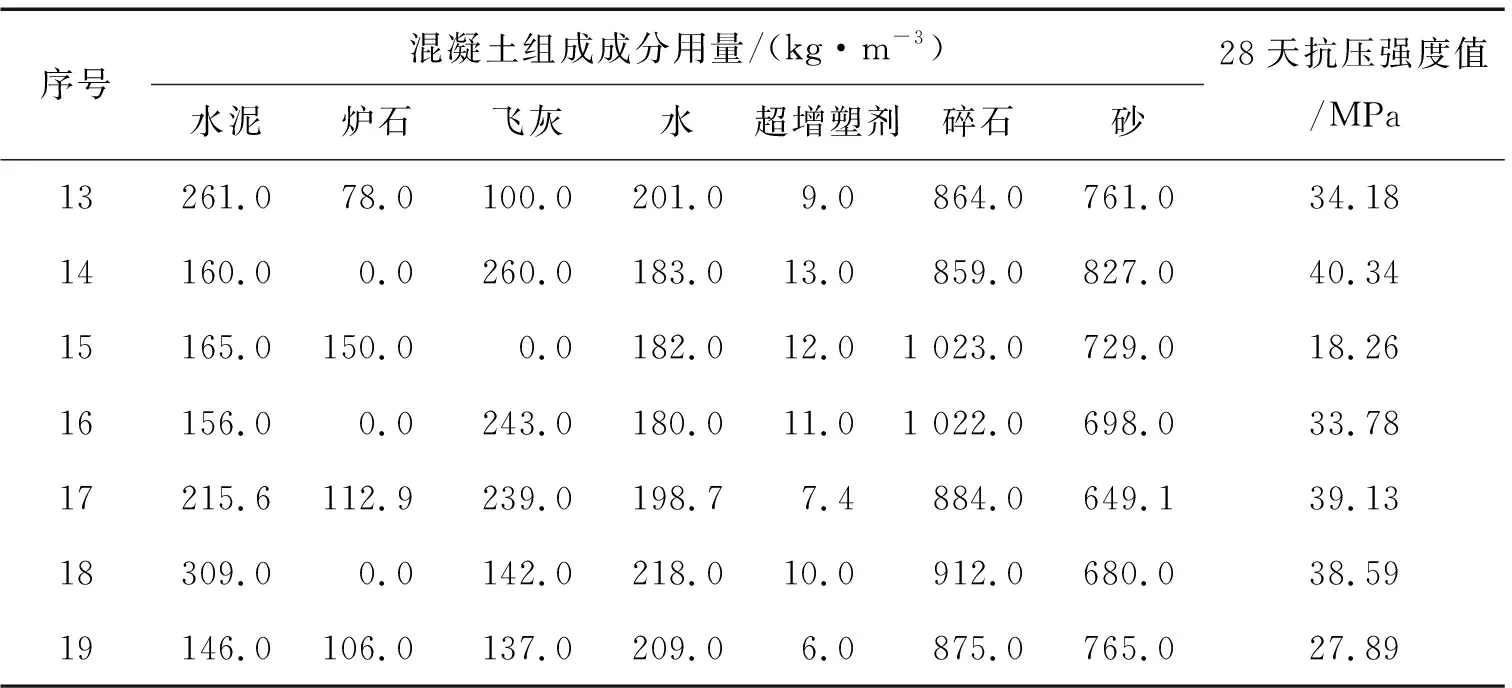
续表
根据表1,设定神经网络的输入为混凝土各配料的量,所以输入层单元数为7,输出为混凝土28天抗压强度值,即输出层单元数为1。隐层单元数没有精确的推导公式,但是可以用以下经验公式作为参考:
(4)
其中,n1为隐层单元数,n为输入神经元的个数,m为输出神经元的个数,a为在0~10之间的常数。
一般来说,隐层单元数比输入神经元个数要多,取隐层单元数为10。其他参数自行取值,但不可超出其参数的取值范围,最终的神经网络模型结构为7×10×1。
2 结果与讨论
2.1 BP神经网络测试
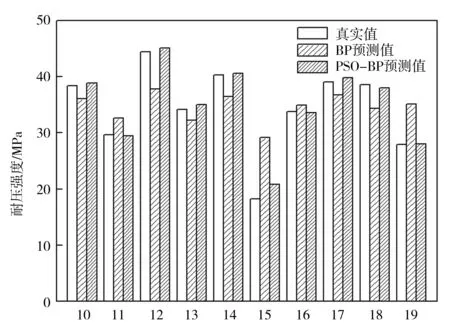
将表1的数据输入到BP神经网络模型中,得到每组数据的仿真结果,如图1所示。
样品编号 图1 BP和PSO-BP神经网络测试结果
从图1可以看出,此神经网络对测试样本的仿真值与真实值存在相当大的误差。均方误差MSE的数值越小越好;另一个描述误差的数值R2,越接近于1表示模型越准确。由研究结果得到MSE为0.059 042,R2为0.758 22,说明并不能准确地描述出输入与输出的关系。这说明,这样训练出来的BP神经网络中的权阈值并不是最优的,需要用优化算法进行权阈值优化。因此,设置粒子群算法参数,迭代次数50次,种群规模20,粒子维数7,学习因子c1=1.914 45,c2=0.914 45。优化完成后继续用表1的测试样本进行测试,测试结果如图1所示,可见用粒子群算法优化网络权阈值得到的神经网络模型明显比单纯BP网络模型效果更好。PSO+BP神经网络模型的均方误差MSE已经降到0.001 550 8,R2为0.992 09。根据PSO+BP神经网络模型,可以设计出已知强度条件下的混凝土配比值。用PSO+BP神经网络模型描述混凝土强度与各自材料用量的关系,具有很强的可靠性和适应性。
2.2 最佳混凝土配比
利用粒子群算法迭代寻优,设置最终得到的混凝土28天抗压强度值为35,迭代次数为100。使用PSO-BP神经网络进行迭代运算,得到如图2所示的误差变化图。
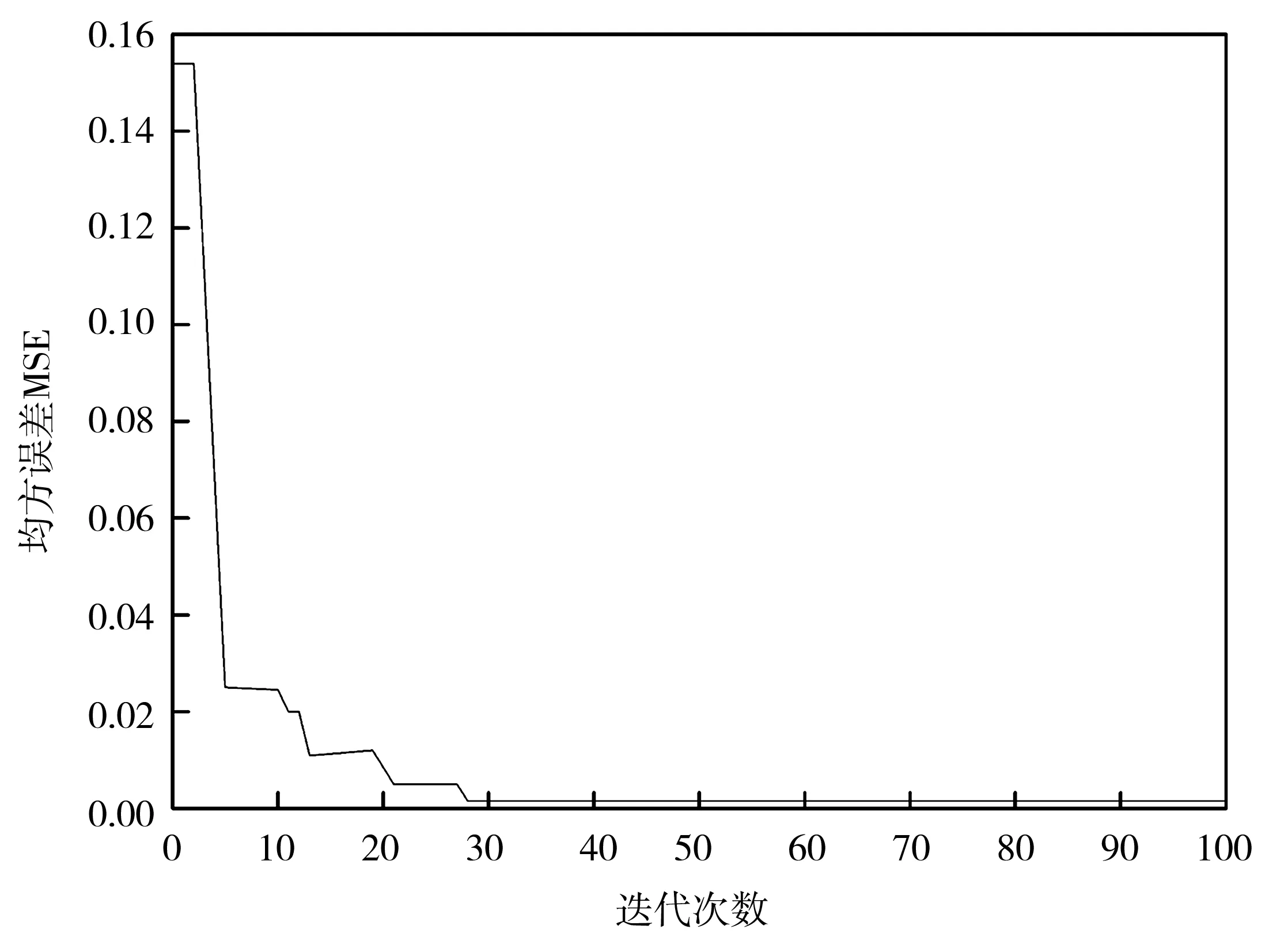
图2 配比迭代后的仿真误差曲线
从图2可以看出,这种方法收敛速度快,当迭代到第27次左右,误差就降到一个很低的水平了。除此之外,精度也很高,误差保持在0.000 1的范围内,因此,通过这种方法可以有效地设计配比值。最终混凝土最佳配比分别为:水泥293.737 kg/m3,炉石0,飞灰93.683 kg/m3,水234.399 kg/m3,超增塑剂19 kg/m3,碎石1 037.664 4 kg/m3,砂640.9 kg/m3。
2.3 混凝土成本筛选
混凝土生产配比的选择需要考虑众多因素,例如,当固定28天混凝土抗压强度值时,所对应的混凝土配比值不是固定的,理论上来说有无数种,运行一次程序,就得到一种混凝土配比值。在这些配比值当中该如何取舍,需要考虑的是成本问题。在得到的有限配比值中肯定有一组是最经济的,通过计算每一组配比值得出混凝土的成本,筛选出成本最低的一组作为最佳配比。计算成本时不包括运费、员工工资等外部因素,只计算混凝土本身各种材料的费用总和。由于配比设计中只包含主要成分,因此可以用单位重量混凝土所需的价格比较不同配比混凝土的性价比。设混凝土生产配比值为x1,x2,…,xn,单位是kg/m3,每种材料的价格是a1,a2,…,an,单位为元/kg。因此,可以计算出成本Y(元/kg)为
(5)
设定混凝土28天抗压强度值为35,得到10组混凝土生产配比值。每组配比结果如表2所示。
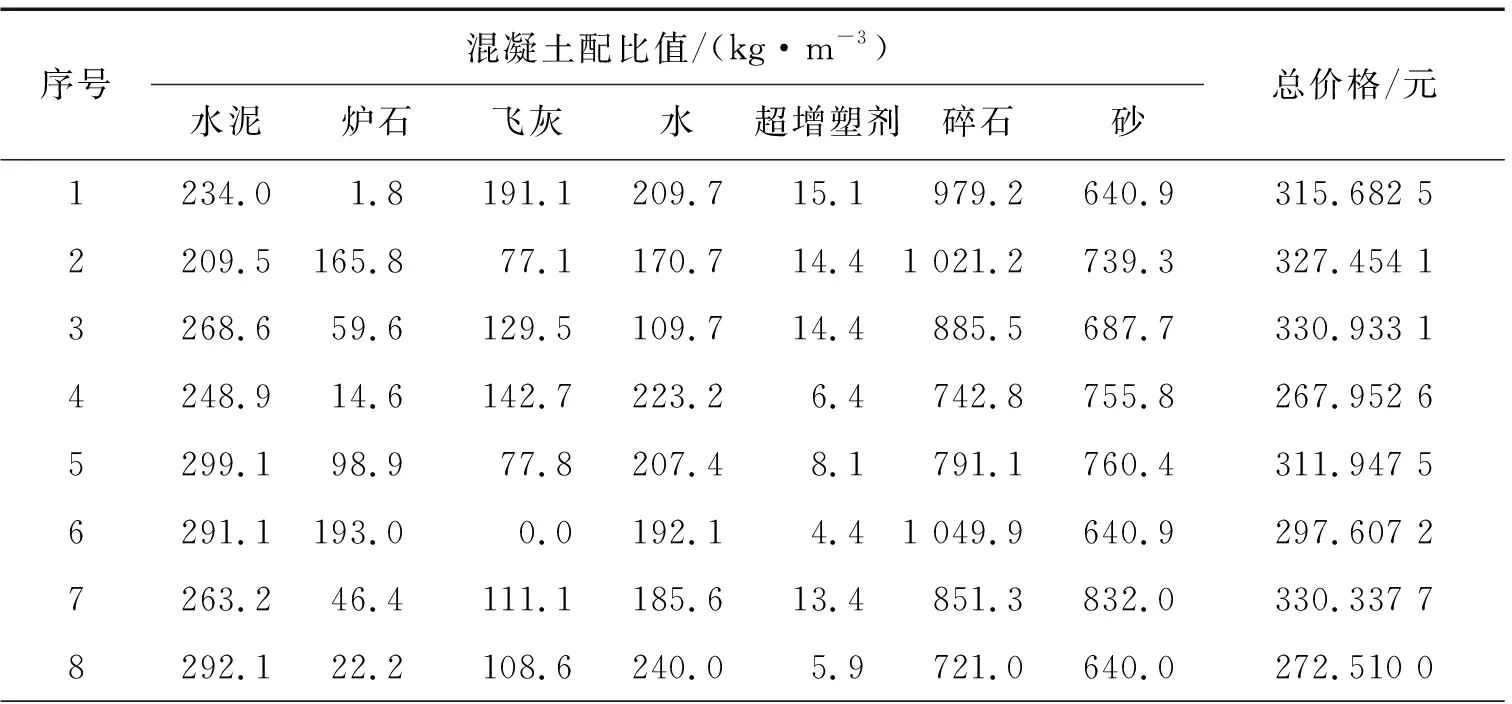
表2 10组28天抗压强度值为35的混凝土配比值
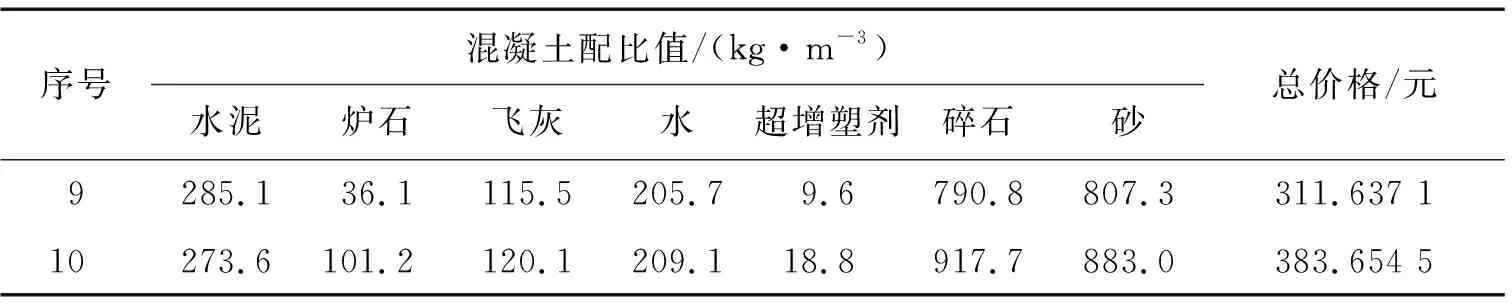
续表
对于这些不同种类的混凝土不同配比值,计算每组的成本总和。2021年市场上每种混凝土组成材料的平均价格分别为:水泥是0.46 元/kg,炉石0.15 元/kg,飞灰0.07 元/kg,水0.002 8 元/kg,超增塑剂5.9 元/kg,碎石0.05元/kg,砂0.087 元/kg。由表2可以看出第4组混凝土的价格最低,因此选取第4组混凝土生产配比,即水泥用量248.9 kg/m3,炉石14.6 kg/m3,飞灰142.7 kg/m3,水223.2 kg/m3,超增塑剂 6.4 kg/m3,碎石 742.8 kg/m3,砂 755.8 kg/m3。混凝土生产配比的仿真设计,可以不进行实际操作而节约时间和成本,事先设计好最理想生产配比,直接应用到混凝土搅拌站中即可。
3 结语
本文提出的粒子群算法结合BP神经网络的方法能够很好地解决混凝土配比的设计问题。从计算机仿真结果可以看出,利用粒子群算法优化权阈值后的神经网络能够很好地描述混凝土各组成的用量与最终成品的强度之间的关系。由此神经网络模型就可以继续通过粒子群算法进行特定目标值的输入搜索,最终得到数组能够达到要求的混凝土配比。如果需要可再根据其他要求从其中筛选更适合的方案。这种方法不仅能设计混凝土生产配比,还能粗略地判断出混凝土强度的上下限,避免设计要求的不合理性。但是这样的设计只是理论上的计算,并不是绝对准确的,应用到实际生产过程中可能会造成误差,这时需要对设计好的混凝土生产配比进行微调,直到满足需求。
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
昆明医科大学学报(2022年1期)2022-02-28
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
商洛学院学报(2020年4期)2020-07-08
人民珠江(2019年4期)2019-04-20
铁路计算机应用(2018年5期)2018-06-01
浙江工业大学学报(2017年5期)2018-01-22
河北遥感(2017年2期)2017-08-07
中学生数理化·教与学(2017年4期)2017-04-22
