
基于生成对抗网络的类别文本生成
2022-08-08 06:11蔡丽坤吴运兵陈甘霖刘翀凌廖祥文
广西师范大学学报(自然科学版) 2022年4期
蔡丽坤,吴运兵,陈甘霖,刘翀凌,廖祥文*
(1.福州大学 计算机与大数据学院,福建 福州 350108;2.福建省网络计算与智能信息处理重点实验室(福州大学),福建 福州 350108;3.福州大学 数字福建金融大数据研究所,福建 福州 350108)
随着自然语言处理在人工智能领域的迅猛发展,自然语言生成已成为人工智能和自然语言处理的一个重要研究方向。类别文本生成[1]作为文本生成的一个子任务,旨在生成包含特定语义的文本。不同类别、不同情感的文本生成,能够使得机器更加人性化。同时,大量具有类别属性的文本的生成能够在很大程度上缓解大规模标签训练数据集获取困难的问题。
传统的文本生成方法主要基于规则模板[2],通过内容规划、句子规划以及语言实现进行文本的生成。随后,基于概率统计的方法[3]也被运用到对语言的建模中,该方法将词与上下文的关系编码成条件概率,从概率统计的角度进行文本生成。随着深度学习的不断发展,当前大多数工作采用端到端的文本生成框架[4],通过数据驱动的方法训练模型,避免了大量手工规则的构造,同时也提高了模型的泛化能力。
生成对抗网络(generative adversarial networks, GAN)[5]作为深度学习中的一个主流框架,采用博弈的思想,通过生成网络和判别网络的对抗训练实现网络的优化目标。其中,判别网络的目标是最大化真实样本与生成样本的距离,反之即为生成网络的目标。目前基于生成对抗网络的文本生成研究中,大都采用基于LSTM的生成网络对文本进行解码。为了获得更丰富的语义表达,Nie等[6]引入关系记忆网络以获得更丰富的上下文依赖关系,并采用注意力机制[7]来实现文本对自身序列的对齐。但是,当注意力查询与结果不匹配时,会导致对无关信息的关注,从而影响生成文本的多样性表达。在判别网络方面,现有的工作,如SentiGAN[8]、CatGAN[9]等,均采用卷积神经网络[10]来进行文本特征信息的提取。卷积神经网络采用局部连接的方式大大减少了网络的参数,但同时也造成文本中上下文依赖关系的丢失,缺乏对文本全局语义特征的学习,从而影响生成文本的整体流畅度。
针对上述问题,本文在生成网络的多头注意力的基础上引入双重注意力,通过额外的注意力进一步过滤掉无关的注意力结果,仅保留有用的关注信息,给文本解码留下更大预测空间。考虑到文本全局语义信息在文本分析中的重要性,本文在判别网络上引入长短时记忆网络[11]对输入文本进行编码,以获取文本的上下文依赖关系,然后将其与多窗口卷积神经网络的输出进行融合,为判别器提供更丰富的语义信息,增强生成器对文本全局语义的关注,从而提升生成文本的整体流畅度。在2个公开的真实数据集上的实验结果显示,和基准方法相比本文方法在BLEU[12]值、NLLgen[13]指标上均取得更好的性能表现,表明模型能够更好地捕获文本的上下文依赖关系,有效学习文本的局部语义和全局语义,从而帮助生成器生成更为流畅的文本。
1 相关工作
文本生成是自然语言处理中一项重要的基础任务,其发展经历了模块化语言模型、统计语言模型,再到如今的基于深度学习的语言模型。目前,绝大多数基于深度神经网络的文本生成模型都采用基于编码器-解码器的结构框架。主要的模型方法可以分为以下3类:基于变分自编码器(variational auto-encoders,VAE)的语言生成模型、基于GAN的语言生成模型以及预训练语言模型。其中,基于VAE的语言生成模型将文本编码成隐空间的概率分布,根据隐变量重构原来的输入来生成文本。基于GAN的语言模型通过生成网络与判别网络的对抗训练,实现对两者的优化。Kusner等[14]提出的Gumbel-Softmax分布采用近似采样的方法来解决GAN中文本数据的离散问题,而SeqGAN[15]则采用强化学习[16]的方式将GAN成功运用于文本生成中。预训练语言模型主要通过堆叠Transformer的方式,衍生出GPT[17]、GPT2[18]、GPT3[19]。
类别文本生成作为文本生成的一个子任务,要求生成的文本不仅要满足文本流畅性、多样性等需求,还要在文本的整体语义上体现出对应的类别属性。与文本生成类似,现有的研究工作主要基于VAE、GAN及其与预训练语言模型的结合。CVAE[20]构建了一个先验网络和一个识别网络,通过识别网络实现对文本属性的约束。PPVAE[21]将VAE与预训练模型结合,它将文本生成模块与条件表示模块解耦,先预训练一个文本生成网络,再根据条件需要训练对应的轻量级网络作为模型的插件以指导对应文本的生成。CSGAN[1]引入一个分类器来提供文本的类别信息,将类别信息与数据分布一同输入到生成器中,采用强化学习进行训练,迫使生成的文本能够拟合真实的数据分布并且带有输入的类别属性。SentiGAN由多个生成器和一个多类别判别器组成,并使用判别器在生成器中建立一个基于惩罚的目标,缓解梯度消失现象,使每个生成器能够生成带有自己特定情感标签的文本。C-SentiGAN[22]则是在SentiGAN的基础上引入条件编码用于条件文本的生成。CatGAN在生成器中引入了层次进化学习算法[23]对模型进行训练,通过分阶段训练使得生成文本能够拟合真实数据分布,并且满足文本多样性要求。
总体而言,现有的类别文本生成研究中,大都通过将类别属性进行编码,输入到原始文本生成中,并通过引入分类器来实现对文本类别属性的约束,文本生成正逐渐往可控的方向发展。然而,当前模型中除了大型预训练语言模型能生成具有较好可读性的文本,其他模型仍存在对文本语义信息、结构信息等关注度不够,生成的文本可读性低的问题。
2 模型建立
2.1 问题形式化描述
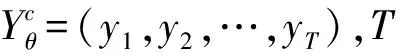
本文的模型总体结构如图1所示。该模型主要包括3个模块:1)生成网络Gθ,学习真实数据分布,结合类别信息生成包含对应类别属性的文本。2)判别网络Dφ,分别对生成网络生成的每个类别的文本进行分析,区分生成文本与真实文本,将其作为学习的信号反馈给生成器,辅助生成器的优化训练;生成网络和判别网络构成了生成对抗网络,为本模型的主体结构。3)模型优化。采用基于层次进化学习算法的优化方式,首先将生成网络n个温变策略及m个目标函数策略生成多个子网络,再利用判别网络对这些子网络的生成文本进行判别,通过目标函数F1和F2进行2个阶段的评价选择,选出本轮最好的策略产生的生成子网络Gθbest。
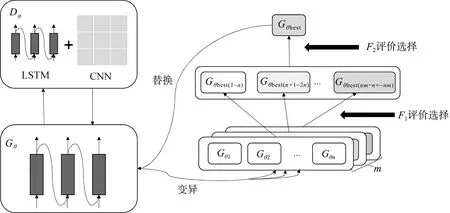
图1 模型的总体架构
2.2 生成网络
本文采用基于关系记忆网络RMC(relational memory core)[24]的生成网络,引入多头自注意力实现文本对自身上下文的对齐,并引入双重注意力[25]对注意力结果进行进一步过滤,减少噪声,最后通过Gumbel-Softmax获得文本的采样输出。具体网络结构如图2所示。

图2 基于双重注意力的生成网络
2.2.1 基于双重注意力机制的文本解码
首先将上一时间步的预测词yt-1通过嵌入层生成嵌入表示Eyt-1,然后将其与类别嵌入Ec进行拼接,再通过线性转换Wx,生成当前时间步的输入向量表示:
xt=[Eyt-1;Ec]Wx。
(1)
为了增强对生成文本长期依赖关系的记忆,引入记忆矩阵Mt来对文本的上下文信息进行存储。首先,将上一时间步得到的上下文信息Mt-1和当前输入xt进行线性映射,构成h组Query、Key和Value,采用多头自注意力机制来实现文本序列对自身注意力的对齐。其中Mt-1WQ作为Query,[Mt-1;xt]WK和[Mt-1;xt]WV分别作为Key和Value。
(2)
式中,WQ∈Rn×dq,WK∈Rm×dk,WV∈Rm×dv,最终生成的多头注意力结果为fatt。为了进一步过滤掉无关信息,将注意力结果fatt传入到双重注意力模块(attention on attention,AOA),通过与注意力查询生成信息向量和一个注意力门,在原始多头注意力上增加一个注意力以进一步过滤掉无关的注意力结果,从而保留有用的信息,最终的注意力结果表示为fAOA。
fAOA=((fatt⊕I)⊗W1+b1)·σ((fatt⊕I)⊗W2+b2),
(3)
式中:I由上下文信息Mt-1和当前输入xt拼接后经线性转换获得;W1和W2为线性转换矩阵;b1和b2为偏置;σ为激活函数Sigmoid。然后,将获取的经过过滤的注意力信息经多层感知操作(MLP),再经LSTM门控机制,最终获得当前时间步的记忆矩阵Mt及输出ot。
(4)
(5)
(6)
式中,ψ1和ψ2表示LSTM的门控机制操作。
2.2.2 基于RealFormer的文本解码
为了增强注意力机制在生成网络中的作用,本文对注意力模块进行了层次叠加。但是,网络的加深会导致梯度不能很好地回传,从而无法带来模型性能的提升。同时,为了避免模型在注意力叠加时的梯度消失风险,引入RealFormer(residual attention transformer)[26]结构,在原模型的注意力矩阵中加入残差,使得第一层的注意力能够传到最后一层,避免了模型梯度消失的风险。具体模型单元如图3所示。
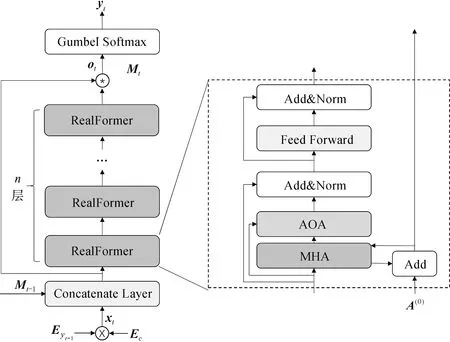
图3 基于RealFormer的生成网络单元
因此,式(2)的注意力计算改为:
fatt(n)=Softmax(A(n))([Mt-1;xt]WV)(n);
(7)
(8)

2.2.3 基于Gumbel-Softmax的近似采样
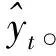
(9)
(10)
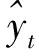
2.3 判别网络
本文的判别网络将特征提取分为2个模块:基于LSTM的全局特征提取和基于CNN的局部特征提取,然后将2个模块的特征提取结果进行融合和过滤,最后将特征结果用于文本的判别。具体网络结构如图4所示。
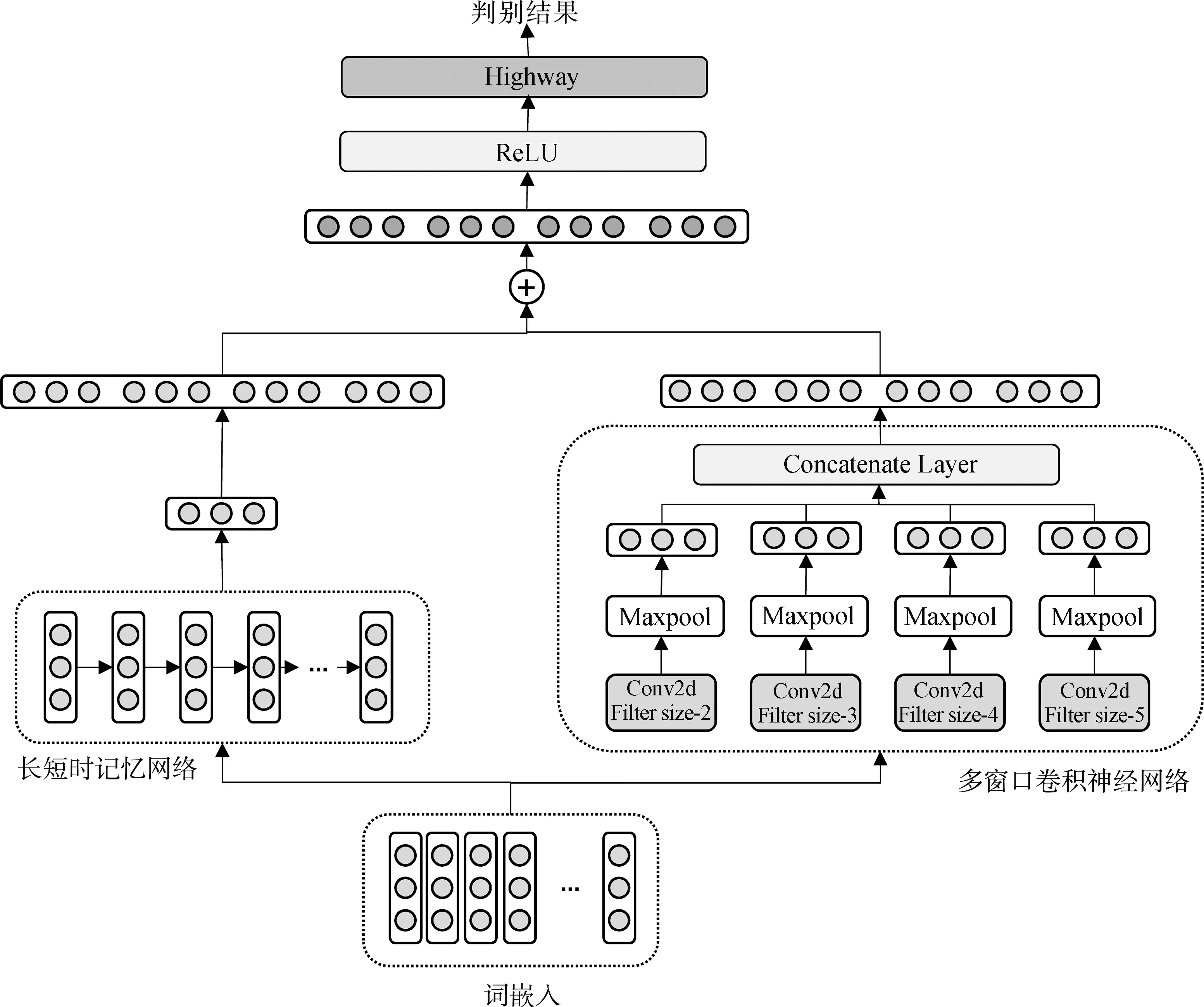
图4 基于多重特征提取的判别网络
2.3.1 特征提取
由于CNN具有强大的局部特征捕获能力,本文采用不同尺寸的滤波器对每个生成样本和真实样本进行特征提取。为了保证每个句子长度一致,将所有样本中最长的句子长度设为句子长度l,即每个句子由l个词的词向量组成的矩阵表示,设每个词的词向量维度为lw,则句子的矩阵表示为S∈Rl×lw。使用窗口大小为W∈Rh×1的滤波器来对句子矩阵进行卷积操作,获得对应的特征fi。
fi=ReLU(S⊗W+b)。
(11)
通过不同大小的滤波器,最终获得关于句子的一系列特征。然后,分别对每个特征进行最大池化操作,保留该特征下的最显著特征。最后,将经过最大池化后的各个滤波器的特征进行拼接,获得最终的特征表示f。
为了提取更全面的语义信息,本文采用LSTM对句子进行编码,以获取句子中词与词之间的上下文依赖关系,从而弥补卷积神经网络无法充分捕获文本全局语义信息的不足。将文本的嵌入表示输入LSTM中,取其最后的隐藏状态hn作为文本的全局特征表示。
2.3.2 特征融合与过滤
将获取的局部语义特征f和全局语义特征h进行融合,获得包含文本完整语义特征的特征表示z。
z=ReLU(f+hn)。
(12)
为了充分利用文本高低层次的语义特征,同时避免梯度信息回流受阻,引入高速网络,通过门控的方法控制每层网络中的信息传输,使更多梯度信息可以回传。
2.4 基于层次进化学习的优化算法
本文采用与CatGAN一样的层次进化学习算法对生成器进行优化。在每一次对抗训练过程中,生成模型首先通过不同突变策略产生多个子模型Gθ1,Gθ2,…,Gθnm。接着,对每一目标函数策略下不同方向的温变策略进行评估,选择出每一目标函数策略中最优的一个子模型。然后,再在所选择出的m个子模型中,通过各个模型生成的文本进行模型性能的评估,选择出最优的一个Gθbest替换当前的生成模型。
(13)
式中:n为温变策略的种数;m为目标函数策略的种数;nm为突变策略的总数。在2个阶段的模型评价中,采用F1和F2来进行模型性能的评价。第一阶段的评价函数F1主要对文本的生成质量进行评价。
(14)
(15)
式中:Yθ表示生成网络生成的样本;Yr表示真实样本;Pθ表示生成样本的数据分布;Pr表示真实样本的数据分布;Dφ(Y)为判别器对样本Y的判别结果。第二阶段的评价中,考虑到在提高文本质量的同时,应保持文本的多样性,防止生成的文本趋于一致。因此,在第二阶段的评价函数F2中加入了多样性指标来平衡两者之间的关系,具体公式为
(16)
最后,根据新的生成模型生成的样本及真实样本采用RaGAN[27]的目标函数对判别模型进行更新。
3 实验
3.1 数据集描述
为了对模型的有效性进行验证,本文采用2个公开数据集:电影评论数据集(MR)[28]和Amazon Review数据集(AR)[29]进行实验。其中,MR数据集是经过斯坦福解析器解析电影评论语料库所获得的情感文本数据集,包含消极和积极2种情感极性的文本;Amazon Review数据集由亚马逊用户的评论构建而成,该数据集包含书本、手机及配件、电子音乐、应用等各类商品的评价,文中的AR数据集为从原Amazon Review数据集获取的仅包含书本和应用2种类型评论的子数据集。数据集的具体信息如表1所示,其中MR数据集的消极评论文本表示为type0,积极评论文本表示为type1;AR数据集的书本评论文本表示为type0,应用评论文本表示为type1。

表1 数据集的统计信息
3.2 实验对比模型
为了验证本文提出的类别文本生成模型的有效性,本文选取SentiGAN[8]模型、CSGAN[1]模型以及CatGAN[9]模型作为基准模型。它们作为基于生成对抗网络的文本生成模型,在类别文本生成任务中取得了优秀的性能,模型的具体描述如下:
SentiGAN模型使用多个生成器和一个多类别判别器,每个生成器生成带有自己特定情感标签的文本。首先,将多个生成器同时进行训练, 使其能够在无监督的情况下生成不同情绪标签的文本;然后使用判别器在生成器中建立一个基于惩罚的目标, 使得每个生成器能够生成带有自己特定情感标签的文本。
CSGAN模型由一个生成器、一个判别器和一个分类器构成。在GAN的基础上引入一个分类器来提供文本的类别信息,将类别信息与数据分布一同输入到生成器中,采用强化学习进行训练,迫使生成的文本能够拟合真实的数据分布并且带有输入的类别属性。
CatGAN模型采用Gumbel-Softmax以近似采样的方法解决离散数据不可导问题,并在生成器中引入关系记忆核心,在扩大记忆容量的同时更好地捕获文本的长程依赖关系。此外,还引入层次进化学习算法对模型进行训练,通过分阶段的训练使得生成文本能够拟合真实的数据分布,并且满足文本多样性要求。
3.3 评价指标
遵循现有工作的做法,本文从生成文本的质量、多样性等各个方面对模型进行有效性验证。在生成文本的多样性评价上,采用了NLLgen和NLLdiv指标,NLLgen的取值与文本的多样性成负相关,而NLLdiv与文本多样性成正相关;在生成文本的质量评价上,采用了机器翻译的常用指标BLEU。
NLLgen=-Yr~Pr[logPθ(r1,r2,…,rT)],
(17)
NLLdiv=-Yθ~Pθ[logPθ(y1,y2,…,yT)]。
(18)
BLEU值的计算采用基于词重叠率的方法。
(19)
(20)
(21)
式中:lθ为生成的候选句子的长度;lr为参考句子的长度;Wn为1/N, 本文中的N取值为2、3、4、5;i表示生成的候选句子Yθ中的n-gram;hi(Yθ)表示n-grami在Yθ中出现的次数;hi(Yrj)表示n-grami在第j个参考句子中出现的次数。
3.4 实验参数设置
本文的模型主要包含一个生成器和一个判别器模型,具体参数设置如表2所示。训练过程主要分为预训练阶段和对抗训练阶段。预训练阶段采用MLE将生成器预训练到一个较好的状态,采用Adam优化算法进行学习,学习率设为0.05,总轮数设为150;对抗训练阶段,同样采用Adam优化算法对生成器和判别器的网络参数进行更新,学习率均设为0.000 1,网络迭代的最大轮数设为2 000。
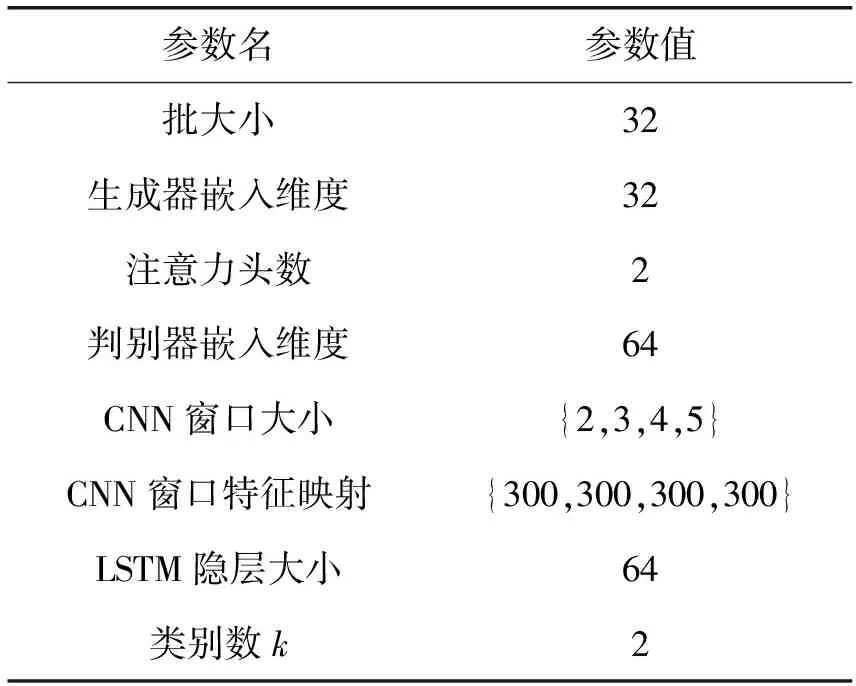
表2 实验中的参数设置
3.5 实验结果分析
为了验证本文方法的有效性,分别在MR数据集和AR数据集上展开实验,表3和表4分别展示了模型在真实数据集MR和AR上的实验结果。各个评价指标的结果均取所有类别对应结果的调和平均值,并取多次实验的平均结果为最终结果。其中,CatGAN-AL表示2.2.1节提出的基于双重注意力的生成网络和基于LSTM和CNN的判别网络组成的生成对抗网络;RealGAN-AL表示2.2.2节提出的基于RealFormer的生成网络和基于LSTM和CNN的判别网络组成的生成对抗网络。
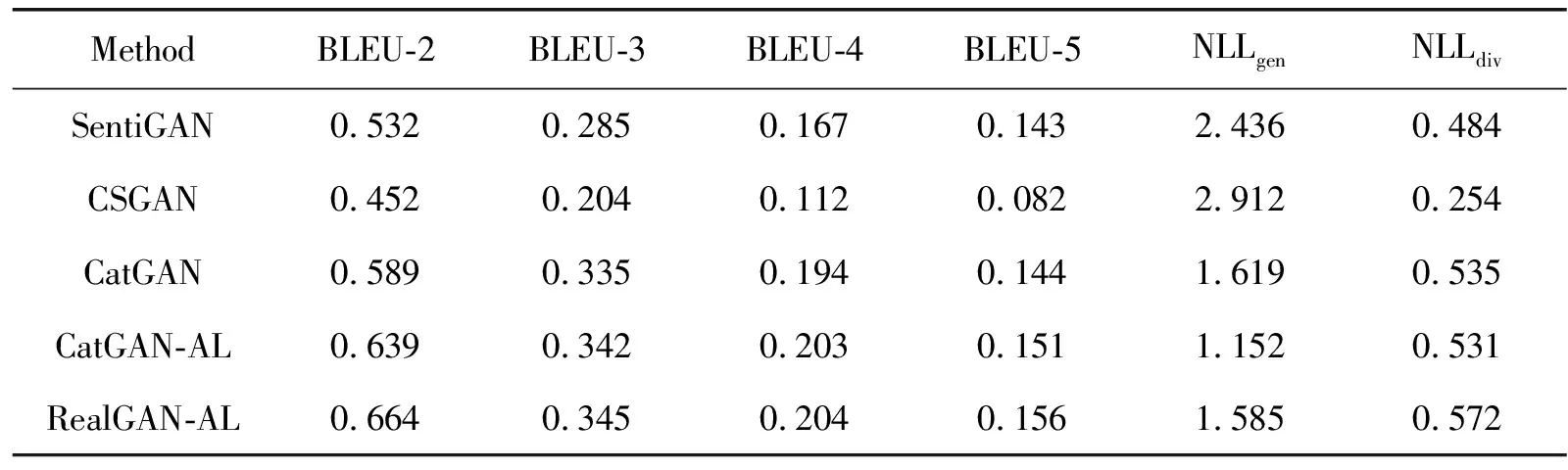
表3 模型在MR数据集上的实验结果
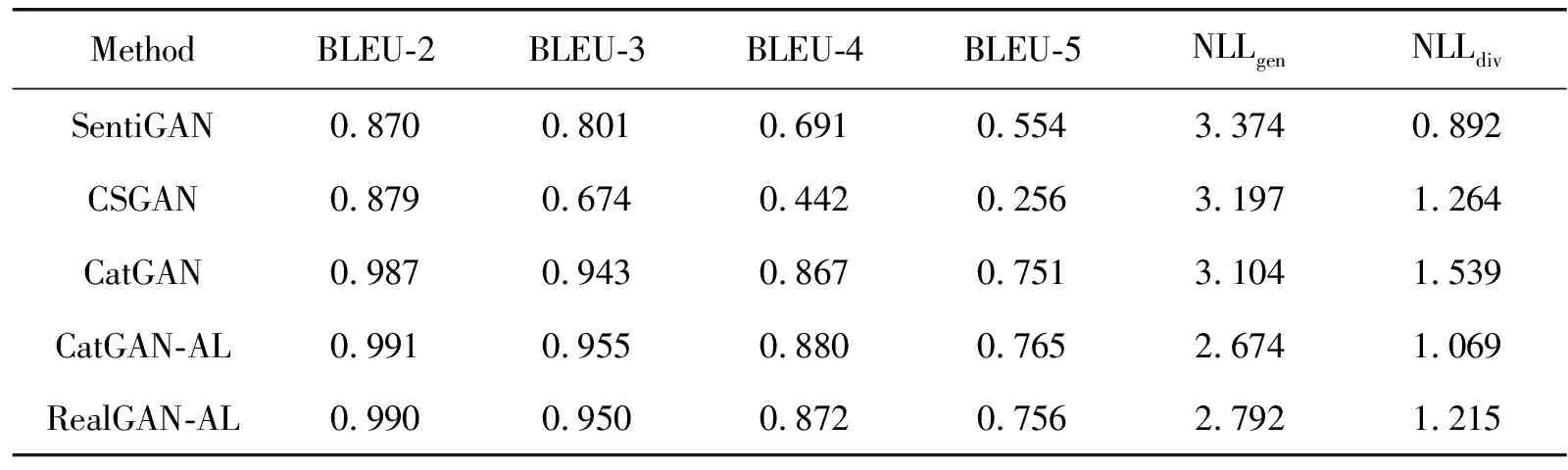
表4 模型在AR数据集上的实验结果
从实验结果可以看出,与基准方法相比,本文的方法能够较好地捕获文本的上下文依赖关系,使生成的文本具有更高的流畅度,并且能够在一定程度上缓解在文本质量提升时存在文本趋于一致性的问题,保持文本的多样性。具体如下:
在MR数据集上,CatGAN-AL模型在4个BLEU指标上均取得了0.007以上的提升,在NLLgen指标上也取得了0.467的提升,在多样性NLLdiv指标上,也取得了与当前最好结果相近的结果。RealGAN-AL模型在4个BLEU指标上都取得了0.01以上的提升,在多样性NLLdiv指标上取得了0.037的提升。这表明本文方法不仅能够丰富文本的语义信息,而且可以过滤掉生成过程中的无关信息,在提升文本质量的同时保持文本的多样性。
在AR数据集上,CatGAN-AL模型在4个BLEU指标上都取得了0.004以上的提升,在NLLgen指标上也取得0.430的提升。RealGAN-AL模型在4个BLEU指标上都取得了0.003以上的提升,在NLLgen指标上取得0.312的提升。这表明本文方法在长文本上依然具有良好的捕获文本上下文依赖关系的能力。对于多样性NLLdiv指标的性能下降,我们认为问题在于AR数据集中文本的长度较长,最长的文本长度为41,在提升文本整体流畅度的同时会损失较多的多样性;此外,长文本中包含更多信息量,在文本的生成过程中自注意力机制会关注到更多的信息,即使引入双重注意力机制对无关信息进行进一步过滤也未能起到明显的作用。但是,RealGAN-AL模型相对于CatGAN-AL模型有0.146的提升,这也表明了注意力的增强能够帮助消除解码过程的噪声,提升生成文本的多样性。从总体上看,本文方法能够在提升长文本流畅度上取得更好的性能。
3.6 消融实验
为了验证模型各个模块的有效性,本文在MR数据集和AR数据集上进行消融实验。其中,w/o AOA表示去除CatGAN-AL模型生成器中的双重注意力模块;w/o LSTM表示去除CatGAN-AL模型判别器中基于LSTM的全局语义特征提取模块。各个评价指标的结果均取所有类别对应结果的调和平均值,并取多次实验的平均结果为最终结果。表5和表6分别展示了CatGAN-AL模型在2个数据集上的消融实验结果。
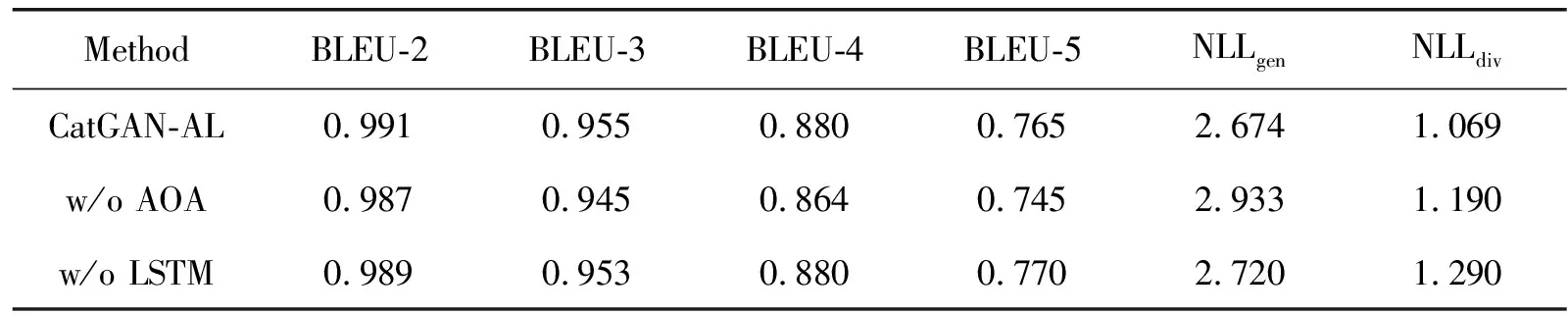
表6 模型在AR数据集上的消融实验结果
通过消融实验可以看出,双重注意力模块和全局特征提取模块的共同引入,能够让模型有更好的表现。双重注意力模块能够在文本质量提升的同时保持文本的多样性,防止生成的文本趋于一致性;基于LSTM的全局特征提取能够提升生成样本的BLEU值,特别是BLEU-4和BLEU-5,表明全局特征提取模块可以使模型关注到文本的上下文依赖关系,达到提升生成文本流畅度的目的。从总体结果上看,本文的方法能够在提升生成文本流畅性的同时保持一定的文本多样性,证明了模型中双重注意力模块和全局特征提取模块的有效性。
3.7 参数分析
评价函数F2中λ值为平衡生成文本质量和多样性的权重系数。为了研究λ取值对模型性能的影响,本文在CatGAN-AL模型上尝试使用[0.000 1,1]区间不同λ值在2个数据集上分别进行实验,实验结果如表7、表8所示。
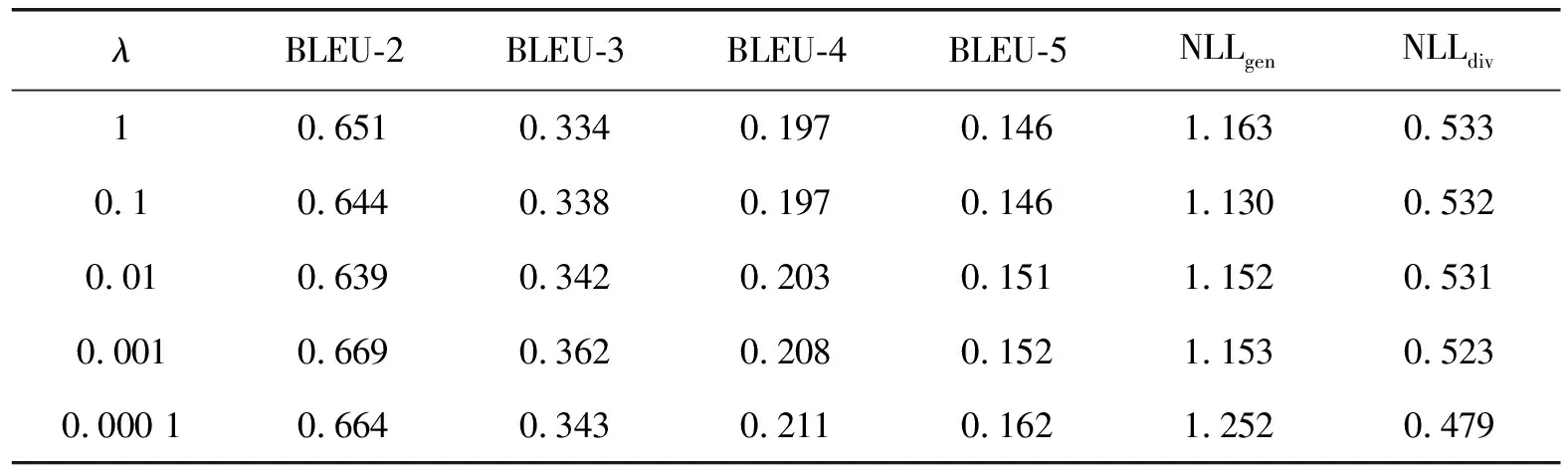
表7 模型在MR数据集上的参数分析结果
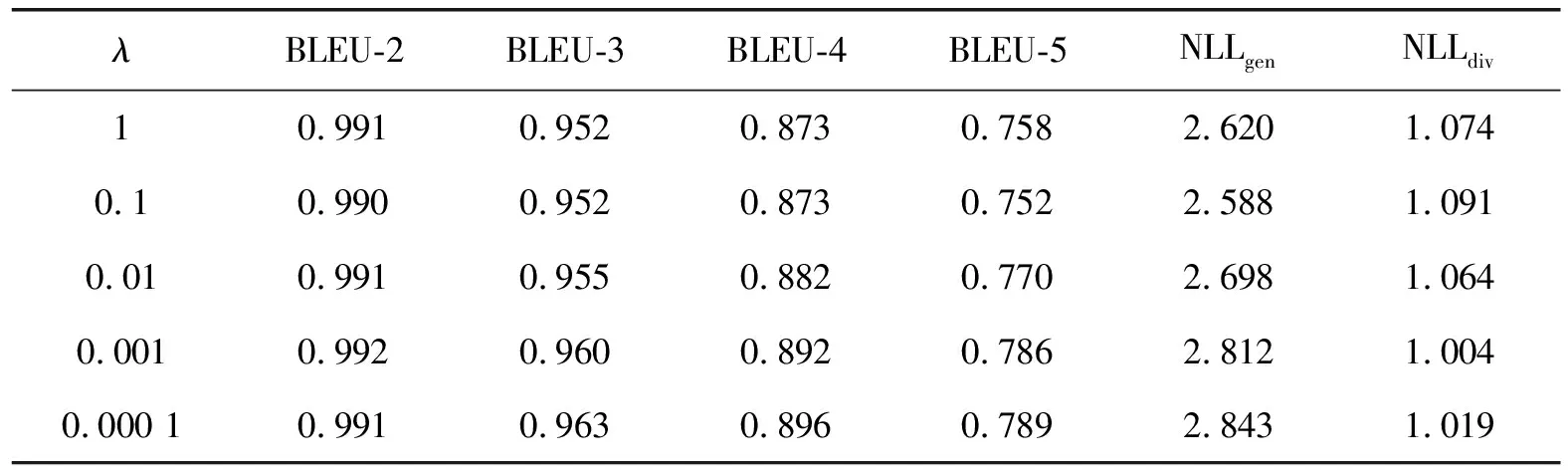
表8 模型在AR数据集上的参数分析结果
从上述实验可以看出,随着λ值的增大,模型更加关注生成文本的多样性,在NLLgen和NLLdiv指标上取得较好的结果;但是,同时也削弱了对文本质量的关注,在BLEU值上有所下降。因此,为了平衡生成文本的多样性和流畅性,本文实验中将λ设为0.01。
4 结语
本文提出一种融合局部语义特征和全局语义特征的判别方法,该方法通过对文本局部特征和全局特征进行提取,使得在获取文本关键信息的同时能够关注文本的上下文依赖关系,增强判别器对文本上下文依赖的关注,迫使生成器能够关注整体语义,生成流畅度更强的文本。此外,本文在生成器的多头注意力上叠加了一个双重注意力,帮助生成器过滤掉无关信息,保留更大的空间用于预测文本的生成。同时,引入残差注意力实现注意力的叠加,增强了注意力的作用效果。通过实验验证,本文的方法能够充分捕获文本的整体语义,在文本的整体流畅度上有较大的提升。未来工作将继续研究如何在提升文本质量和保持文本类别正确性的前提下,提高文本的多样性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
开放教育研究(2020年2期)2020-03-31
民族古籍研究(2018年1期)2018-05-21
传媒评论(2017年3期)2017-06-13
中国修辞(2017年0期)2017-01-31
西夏学(2016年2期)2016-10-26
第二课堂(课外活动版)(2016年2期)2016-10-21
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
浙江大学学报(工学版)(2015年1期)2015-03-01
