
体现用户意图和风格的图像描述生成
2022-08-08 05:37王宇航张灿龙李志欣王智文
广西师范大学学报(自然科学版) 2022年4期
王宇航,张灿龙*,李志欣,王智文
(1.广西多源信息挖掘与安全重点实验室(广西师范大学),广西 桂林 541004;2.广西科技大学 计算机科学与通信工程学院,广西 柳州 545006)
图像描述(image captioning)是一个结合计算机视觉和自然语言处理的跨领域任务,其计算涉及自然文本的语义提取、图像目标的检测与特征提取、目标之间关系的识别与推理等,最终将图像识别的结果表述为一个自然语句[1-3]。深度学习技术的应用使计算机描述图像场景的能力得到大幅提升,在某些评估指标上甚至超过人类。然而,若要让机器按照用户的意愿和个性去描述一个场景,就必须使它们拥有感知用户兴趣和个性的能力。
遗憾的是,现有的图像描述模型[4-6]虽然可以生成较为流畅的描述语句,但是存在与用户交互性差、多样性低等问题。具体体现在以下2个方面:1)大多数图像描述模型仅机械地生成描述图像场景整体内容的句子,并没有考虑用户感兴趣的内容或者期望描述的详细程度[7-8];2)这种生成模式倾向于使用常见的高频词来表达生成较为“简单安全”的句子,容易造成句子缺乏多样性[9-12],无法体现用户的个性特征和用语习惯。如图1所示,现有模型[13-15]可以准确地描述出“两个棒球运动员在运动场打球”,却不能依据用户的期望描述出男子的具体细节,如体态、衣服颜色、背景等细节内容,也不能控制是全局描述还是局部描述某一个男子,并且只是用简单的语言表达出来。
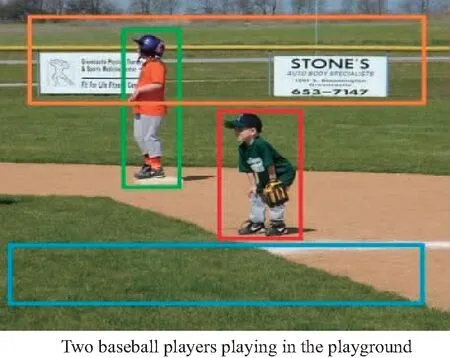
图1 现有图像描述实例
针对以上问题,本文提出场景细粒度控制的个性化图像描述方法,图2是本文提出模型的整体结构。首先,构建一个包含3类抽象节点的空间关系图(spatial relation,SR),这3类抽象节点分别代表目标(object)、属性(feature)、目标之间的关系(relationship),每个抽象节点在图中有具体区域的定位(其中1、4为属性节点,2、3为目标节点,5为关系节点);然后利用图注意力机制来获取用户所希望描述的内容和顺序,并通过添加控制阀门来调节图流动的方向,再利用图语义注意力机制结合上下文的关联度使语句更为流畅;接着,加入动态访问节点(dynamic access node),记录所访问过的节点,加入没有访问过的节点,并擦除一些废词,如介词(with)、助词(have)等,从而使描述更具多样性且不遗漏或重复描述;最后,在解码器中加入基于用户画像的字幕风格因子,如专业型(professional)、浪漫型(romantic)或幽默型(humorous),从而输出符合用户期望的风格化语句。
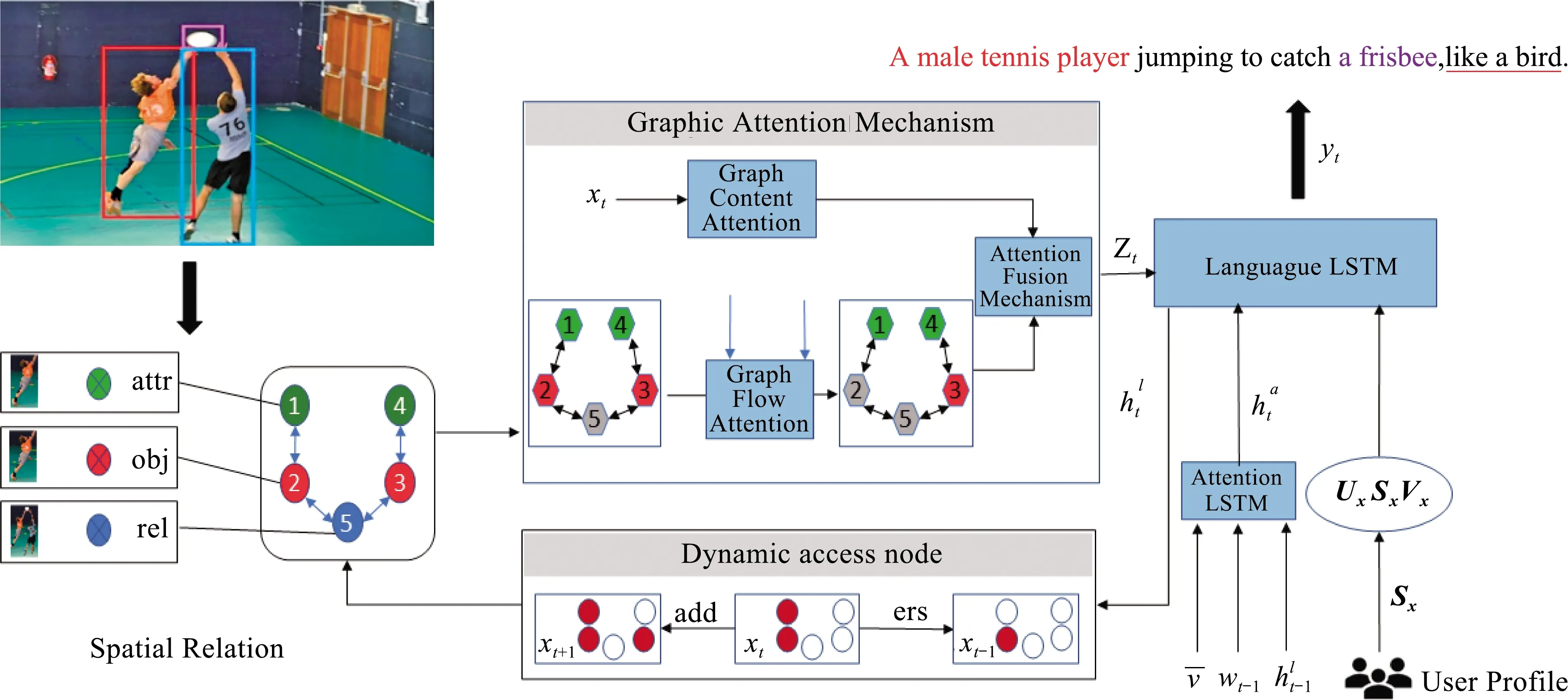
图2 本文提出的个性化图像描述模型
综上所述,本文的主要贡献如下:
1)构建了基于细粒度的场景控制模型,以控制所希望描述的图像内容。如:描述几个物体、是否描述背景、物体之间的关系、对物体进行简要描述还是详细描述,等等。
2)加入门控阀,将图流动注意力机制与图内容注意力机制相结合,使描述语句更贴合图像且更流畅。
3)提出基于用户画像的风格因子生成方法,并将风格因子加入到语言解码器中,使生成的描述具有特定风格,从而实现生成结果的个性化和多样性。
1 相关工作
1.1 图像描述
目前大多数图像描述生成的模型都是基于传统编解码架构,此举改善了最原始的RNN结构中映射长度不一致的问题[16-17]。为了解决图像输入LSTM只传输全局特征的问题,Wu等[18]提出att-LSTM通过图像标签分类提取图像属性,形成高频词。Xu等[19]引入视觉注意机制,强制每个单词对应于图像的某个区域,使用深度网络计算每个区域的对应权重,然后将权重乘以对应区域的特征。注意机制更符合生物视觉机制,但缺点是每个单词都必须对应一个区域。然而,一些介词和动词不能在图像中实际表达,如“a”和“of”,它们在图像中没有特定意义,但仍然对应于区域。为了解决这个问题,Lu等[20]提出哨兵机制,在生成每个词时,首先计算该词属于视觉词还是上下文词的概率,然后根据权重计算整体特征。Chen等[21]利用CNN的空间、多通道和多层次特性,改进了CNN的网络结构,增加了空间注意、通道注意和特征图。Rennie等[22]使用强化学习训练解码器,将推理阶段生成的描述句作为“基线”,刺激分数高于基线的结果,抑制分数低于基线的句子生成,并使用绿色编码的方法取得了良好的效果。Anderson等[23]提出了自下而上和自上而下的注意机制,结合目标检测,使目标区域划分更加合理,并使用多层LSTM使生成的描述和图像更加相关和平滑。
1.2 基于场景图的图像描述
场景图包含图像的结构化语义信息,包括当前物体的知识、属性和成对关系。因此,场景图可以为图像检索、VQA、图像生成等其他视觉任务提供有利的优先级。通过观察在视觉任务中利用场景图的潜力,Wang等[24]提出了多种方法来改进从图像生成场景图的方法。另一方面,Zellers等[25]也尝试从文本数据中提取场景图。Yang等[26]以场景图为桥梁,整合对象、属性和关系知识,发现更有意义的语义上下文,以便更好地生成描述。本文将动态节点引入抽象场景图中,作为控制信号来生成所需的和多样的图像描述,便于与人交互以达到更细粒度的控制。
1.3 个性化图像描述
尽管在描述语句生成的流畅性和准确性方面取得了令人振奋的成果,但现有的主流图像描述模型只能生成单调且风格单一的描述语句,然而一些研究试图引入更具吸引力的描述。其中,Park等[27]基于用户先前的描述文本提取更活跃的词汇,以模仿用户个性化。Gan等[28]收集涵盖2种风格的数据集,并试图通过无监督学习来传递文字游戏(双关语),训练制作有趣的字幕。Shuster等[29]完成了更多关于人类性格风格的描述模型。Chen等[30]通过ASG模型控制描述内容,并在更精细的层次上完成图像描述的生成。Liu等[31]将图像描述应用到艺术领域,使机器面对图像,像诗人一样写诗。本文利用用户级特征,如性别、年龄和教育程度,完成用户的个性化分类,以达到更加精准的个性化图像描述控制。
2 PICFCS模型
一个真正有用且能与人沟通的图像描述模型,应该是一个能体现用户个性、可供用户选择的可控型图像描述模型。基于这一认知,本文提出一种细粒度场景控制的个性化图像描述(personalized image captioning with fine-grained control of scene, PICFCS)模型,如图2所示。该模型由场景细粒度控制模块和用语风格控制模块组成,其中,场景控制模块通过图结构来控制用户所希望表达的场景中的特定目标、目标属性和各目标间的关系,以反映用户的描述意图,从而生成更具多样性的图像描述。而用语风格控制模块则是通过由用户画像所控制的风格因子来生成特定风格的描述语句,以生成个性化的图像描述。本文采用编码器—解码器框架来构建模型,编码器会根据用户意图和用户画像对给定图像I和风格因子进行编码,而解码器则会生成符合用户意图和个性的描述语句Y={y1,y2,…,yT}(T为最大生成语句长度)。
2.1 目标空间关系图
首先,以输入图片I为基础,通过在VisualGenome数据集上运用图像卷积和目标检测等一系列预处理,获得场景图像中的目标、目标属性以及目标之间的空间关系,以此来生成抽象空间关系图。具体如下:添加用户感兴趣的目标节点oi,构建出目标在图中的位置,如果对多个目标感兴趣则添加多个目标节点,如果用户希望具体了解目标的信息则添加一个或多个属性节点f,并建立目标与属性之间的有向边。当用户希望描述目标与目标之间的关系时,则生成目标与目标之间的关系节点r,并建立从主语目标指向关系r和从关系r指向宾语目标的2条边。角色刻画不仅需要描述节点在图像中对应的视觉特征,还要体现出它所代表的角色意图。
由于PICFCS中的节点不是单独的,结合相邻节点的上下文信息有益于对节点的语义和角色信息的理解。尽管PICFCS中的边是单向的,但节点之间的影响却是相互的。此外,由于节点的类型不同,信息从一种类型节点传递到另一种类型节点的传递方式与其反方向也是不同的。因此,本文将原始PICFCS的边扩展为不同的双向边,从而生成一个具有多关系的图,利用多关系图卷积神经网络进行图中上下文编码。以图3为例,模型先检测到目标节点“horse”“man”“grass”,然后模型添加其属性节点“a brown”“a young”“dry”,最后建立与“horse”相关的2个关系节点。
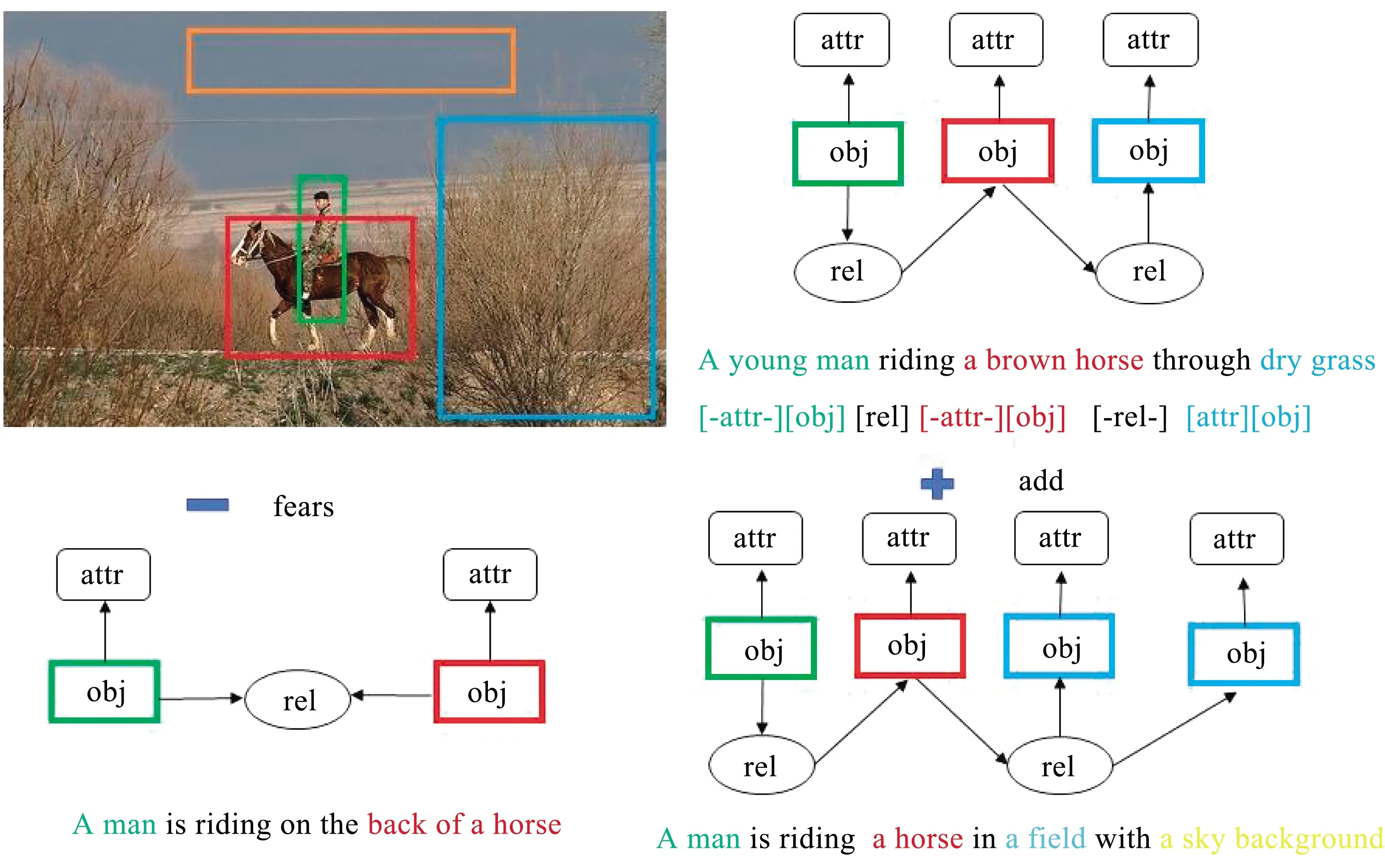
图3 目标空间位置关系
角色感知图编码器将基于图像I的目标空间关系图编码为节点嵌入的集合χ={x1,…,xi,…,x|v|},其中节点xi不仅要表现出其在图像中对应的视觉特征,而且要能反映出它的角色意图,这对于区分具有相同图像区域的目标节点和属性节点来说至关重要。此外,因为目标空间关系图中的节点并不是单独存在的,因此结合相邻节点的上下文信息有利于节点的语义识别和角色理解。基于以上原因,本文构建一个角色感知图编码器,在该编码器中嵌入一个角色感知节点来体现用户意图,还使用一个多关系图卷积网络来进行上下文编码。
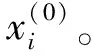
(1)
式中:Wr∈R3×d为角色嵌入矩阵,d为特征维度;Wr[k]为Wr的第k行;而pos[i]是一种位置嵌入,用于区分同一目标的同属性节点。
虽然目标空间关系图中的边是单向的,但相连节点之间的影响是相互的。而且,由于节点的类型不一样,要怎样才能使信息从A节点传递到B节点不同于它从B节点传到A节点呢?针对这一问题,本文对原有的不具有双向边的目标空间关系图进行扩展,从而得到一个多关系图Gm={V,ε,R}。R中有6种边来捕捉相邻节点之间的相互关系,分别是:目标到目标、目标到属性、目标到关系及其反方向。本文使用多关系图卷积神经网络在Gm中编码图的上下文信息,用式(2)来计算。
(2)
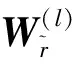
2.2 图注意力机制
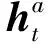
(3)
(4)
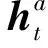
(5)
(6)
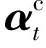
(7)
(8)
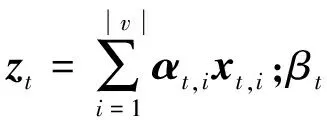
2.3 动态访问节点
为了了解不同节点访问的情况,本文在每个解码阶段进行了记录,用αt表示每个节点的注意力得分。本文加入了视觉哨兵门来实现注意力强度的修改,使模型更专注于重点单词而不是一些不可视的虚词,用式(9)计算。
(9)
式中fvs是一个由θvs参数化的全连接网络,它生成一个标量来表示是否生成节点相关的词。为了保证图中所有节点都应被文本描述所表达,不能出现缺失或者重复的现象,本文采用一种图节点动态更新机制。通过动态增加和动态擦除来实现动态节点更新,对于已表达过的节点采用式(10)和式(11)进行动态擦除。对第i个节点表示为xt,i,根据其强度ut,i更新。
(10)
xt+1,i=xt,i(1-ut,iet,i)。
(11)
如果一个节点并不需要再表达,则可置为0。采用式(12)和式(13)对新加入的节点进行更新,包括节点的属性。
(12)
(13)
式中fers、fadd为擦除和添加具有不同参数的全连接网络。
2.4 用户画像与风格化
要实现可控的个性化图像描述,就必须知道用户的特征,而用户的特征可以通过用户画像来刻画。本文所采用的数据来源于2016年CCF竞赛平台,由搜狗公司提供的用户搜索数据,其中每条数据包含用户的搜索关键词ID、Age(年龄)、Gender(性别)、Education(教育程度)。由于用户在搜索数据的过程中,所使用的关键词和用户本身属于从属关系,对同一类用户而言,他们所使用的关键词通常具有一定的相似性和相关性,即同类用户所用关键词之间的相似度较高,因此我们对具有相似搜索关键词的用户聚为一类。如:1)18 岁以下的人群搜索学业相关的数据会更多;2)女性一般会比男性在护肤、化妆品上进行更多的搜索;3)受教育程度高的人会使用更专业的术语来搜索数据。因此,本文采用基于搜索关键词的用户画像构建方法。为了简单起见,基于用户画像,本文将用户的风格简化成3类:专业型、幽默型和浪漫型。本文提出的用户画像的构建及其风格归类过程如下:
首先,采用句向量和词向量混合训练的 Doc2vec 模型对关键词进行向量构建。
其次,采用式(14)的S-TFIWF 权重计算方法对关键词加权,并基于K-means算法对加权后的数据进行聚类处理,通过计算关键词之间的相似度建立用户喜好词库。
(14)
最后,采用Stacking集成模型,融合SVM分类算法对搜索关键词进行分类和预测,最终得到用户的标签信息,即用户的用语风格。
对本文所用的用户数据集进行可视化处理,并根据用户的一些特点做基本的风格分类,结果如图4所示。
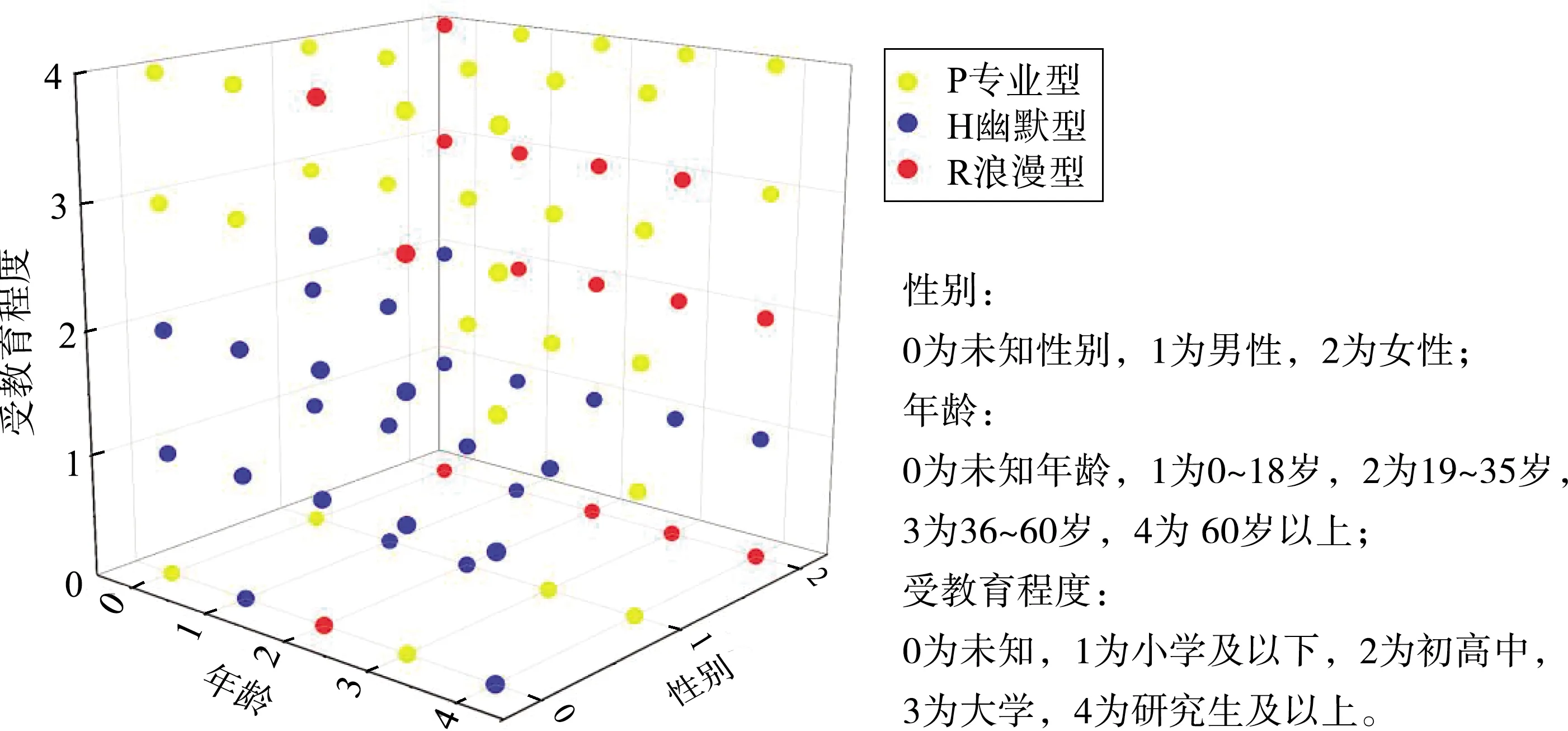
图4 用户风格聚类
2.5 语言解码器
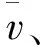
(15)
传统的语言LSTM网络用于生成图像描述时,主要是捕捉句子中单词之间的长期顺序依赖关系,而没有考虑语言中其他语言模式的风格。为了解决这个问题,本文提出一个分解式语言LSTM模块,将传统语言LSTM模型中输入xt的权重矩阵Wx分解为3个矩阵Ux、Sx、Vx的乘积,
Wx=UxSxVx。
(16)
在分解式LSTM模型中,矩阵集Ux、Vx在不同的样式之间共享,这些样式被设计用来对所有文本数据中的一般事实描述建模。矩阵Sx代表特定的用户用语风格,因此可以提取文本数据中的底层样式因素。具体来说,本文用SP表示标准语言描述中的专业型文体的因子矩阵集,SR表示浪漫型文体的因子矩阵集,SH表示幽默型文体的因子矩阵集。最终,本文得到了分解式LSTM的计算过程用式(17)来表示。
(17)
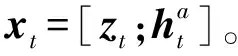
3 实验结果与分析
本章用实验来评估所提出模型的有效性, 首先介绍实验用的基准数据集和评估指标, 并给出实验的实现细节, 然后将本文方法与最新的一些方法进行比较, 并对生成描述语句的结果进行定量和定性分析。
3.1 数据集及评价标准
3.1.1 数据集
本文主要使用FlickrStyle 10K(1)https:∥zhegan27.github.io/Paper.html和MSCOCO 2014(2)http:∥cocodataset.org/数据集来验证模型的有效性。FlickrStyle 10K是在Flickr 30K数据集中创建的,该数据包含10 000张图片,每张图片至少标注了1个幽默型语句、1个浪漫型语句和5个真实标注语句,实验将7 000张图像用于训练,2 000张图像用于测试,1 000张图像用于验证,测试集中收集了由5名不同工作人员撰写的5种浪漫和幽默型的评价说明。MSCOCO 2014数据集包含123 287张图像, 每张图像至少有5个真实标注语句用于图像描述任务,实验中将113 287幅图像用于训练,5 000幅图像用于验证,5 000幅图像用于测试。
3.1.2 评价标准
实验中使用的评价指标包括BLEU1—BLEU4、METEOR、CIDEr[32]、SPICE[33]和ROUGE-L[34]。对于多样性测量,首先对每个模型的相同数量的图像标题进行采样,并使用2种类型的度量来评估采样标题的多样性:1)n-gram多样性(Div-n),一种广泛使用的度量[4,9],即距离图与总字数的比率;2)SelfCIDEr[35],一种评估语义多样性的最新指标,源自潜在语义分析,分数越高标题就越多样化。
3.2 实验细节
本文实验在pytorch框架上实现,使用python 3.6语言编程, 在NVIDIA GeForce RTX 3090 GPU上进行实验。本文使用Faster R-CNN来检测图像中包含的目标, Faster R-CNN首先在Visual Genome数据集上进行预训练, 然后在MSCOCO数据集上进行微调。因此, 对于每一幅经过预处理得到的大小为256×256的图像, 可以得到36个2 048维的图像特征向量。在解码阶段,使用LSTM作为语言生成器, 其输入层和隐藏层数量均设置为512,嵌入向量的维度设置为512。设置参数λ的值为0.2。整个训练过程分为以下2个阶段: 在第一阶段, 利用交叉熵损失函数训练模型, 训练的批量大小为64。设置动量大小为0.9,学习率为1×10-4。在训练过程中, 每经过5个epoch, 学习率衰减为原来的0.7倍。使用集束搜索技术从候选语句集中选择最合适的描述语句, 集束的大小设置为3。
3.3 实验结果分析
3.3.1 在FlickrStyle上生成描述示例
表1展示了所提出的模型在FlickrStyle上的实验结果,其中不同颜色代表描述对应颜色的目标。从表1的第2列不难看出,本文提出的方法可以有效地从位置、属性、关系等方面按照用户的意图生成相应的图像描述,以图(a)为例,“Two people”既可描述成“A man and a woman”,也可以更加细粒度地描述成“A group of skiers”。从第2列的描述语句对图(c)中目标与目标之间的动作关系“jumping to catch”的描述可知,模型可以通过有向节点的控制来表达用户所希望描述的物体及物体之间的关系,更加细粒度地描述用户所感兴趣的内容或要忽略的内容,从而更高效地表达关键性的、用户需要的细节信息。从图(b)第4列可以看出,“Two horses graze in a field near trees”可以浪漫地表述成“Two horses graze in a field, as a landscape painting”,也可以幽默地表述成“A horse graze in a field near trees, wants go home”。本模型可以显著提升句子的可读性,丰富了图像描述中文字的表现力。

表1 在数据集FlickrStyle上的实验结果
表2展示了本文方法与其他方法的性能对比,其中Ours_P、Ours_R和Ours_H分别代表本文的专业型、浪漫型以及幽默型字幕生成方法。与普通的图像描述数据集相比,FlickrStyle数据集中的标准描述语句更具多样性、表现力和吸引力。从表2中可见本文方法的各项评价指标都要优于对比方法,说明本文方法所产生的描述更具多样性、更受欢迎和易于记忆。这种带有样式的图像字幕任务有望为许多现实世界的应用程序提供便利。
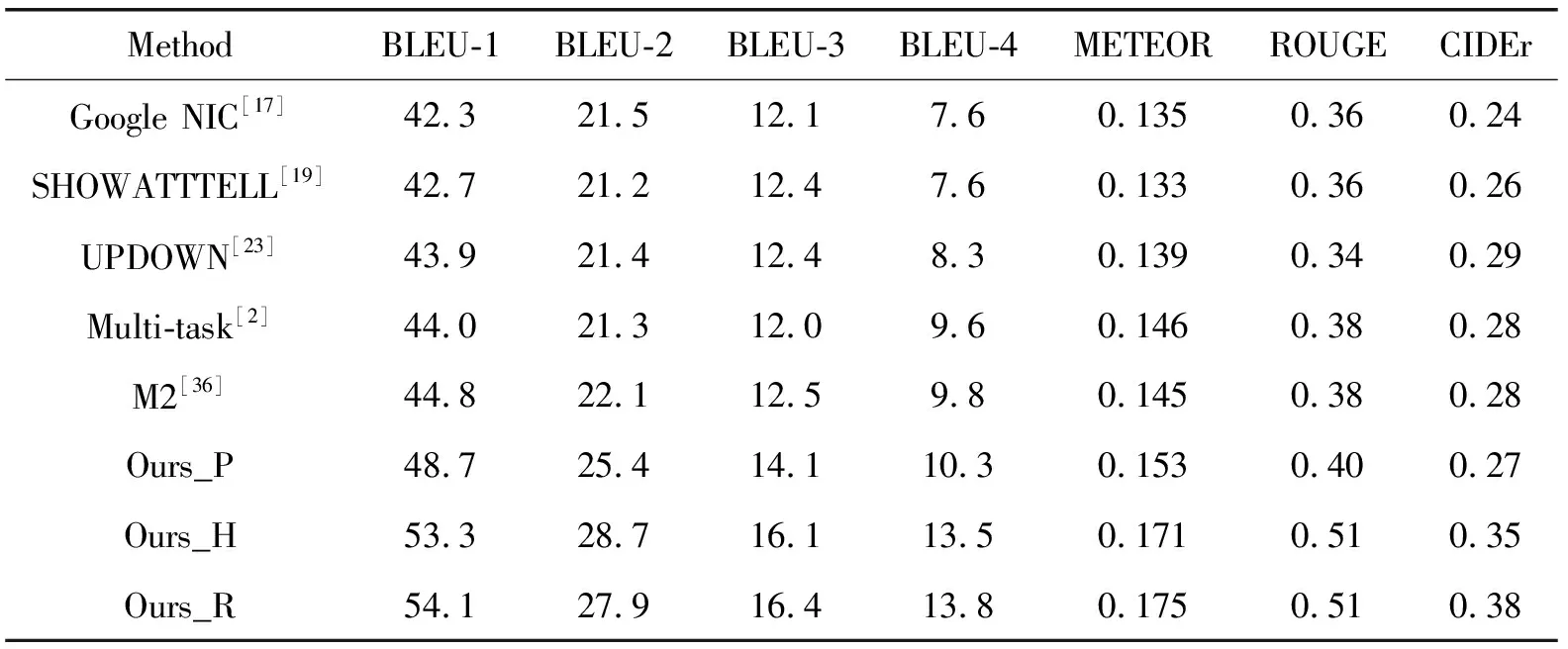
表2 不同图像描述生成方法在FlickrStyle上的性能比较
从图5中可以看出,本文模型能够生成更细粒度的描述,描述的表达方式也更具个性化,更接近真人的文字表达。

图5 基于场景图的模型对比实例
3.3.2 多样性评估
本文模型图像描述生成的一个好处是可以基于多样化生成不同的图像描述,以不同层次的细节描述不同方面的图像内容。如表3所示,本文模型生成的描述比竞争者的模型更加多样化,特别是在SelfCIDEr评分上,该评分侧重于语义相似性。表1中演示了带有不同用户意图的示例图像,本文模型至少能生成3种不同用户意图的描述。
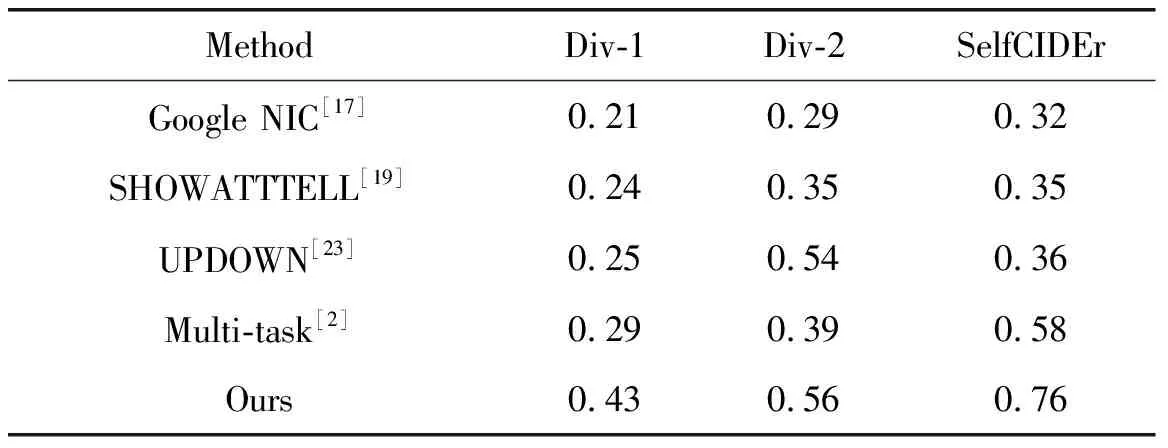
表3 与先进模型的多样性评估对比
3.3.3 用户喜爱度评估
本文设计了一个网站,使用500张图片,每10张图片为一组,调查对比风格化的图像描述和传统无风格的图像描述。使用同一张图片,将NIC、Multi-task、风格浪漫型模型和风格幽默型模型生成的4个描述呈现给用户,让他们选出更吸引他们的描述。表4的结果表明,88.5%的用户认为带个性化的描述更具吸引力,也更适合放入社交媒体中。

表4 用户喜爱度投票结果
3.3.4 消融实验结果分析
本文模型主要包含以下几个模块:空间关系图(spatial relation,SR)、多关系卷积神经网络(MR-GCN,MG)、图语义注意力(graph content attention,GCA)、图流动注意力(graph flow attention,GLA)、动态访问节点(dynamic access node,DAN)、风格因子(factored,FAT)和集束搜索(beam search,BS)。为了验证各模块的贡献,进行了消融实验,结果如表5所示,其中“√”表示对应的模块被选中。由于MSCOCO数据集中的描述语句是不带风格化的,因此表5中最后一组在加入了风格化模块后就无法测试MSCOCO数据集了,对应实验结果用“—”表示。第3组在编码器中加入了空间关系图,极大地提升了模型的性能,这说明区分同一区域不同的节点至关重要;第4、5组中分别加入了图语义注意力和图流动注意力,可以看出2个注意力之间有一定的互补性,使得描述语句更通顺;第6、7组中的动态访问节点以及集束搜索均在数据量更大的MSCOCO上表现更佳;最后一组加入风格因子后,模型的性能得到进一步提升,这主要得益于风格因子的多样性。
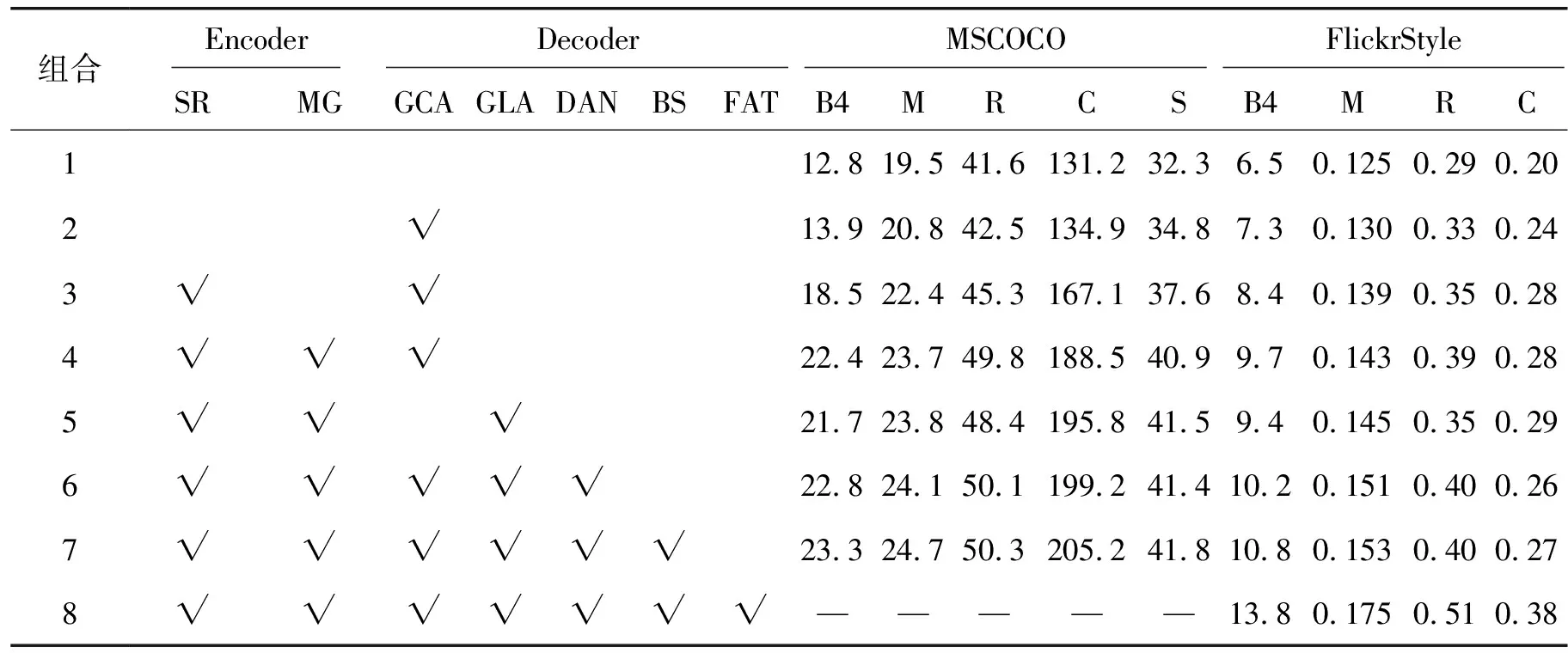
表5 消融实验结果
4 结语
本文旨在探索一种可以同时实现对图像描述内容控制和描述语句风格控制的方法。本文PICFCS模型不仅可以控制图像描述生成中的不同细节(例如:描述什么物体,是否描述物体的属性,以及物体之间的关系等),还通过用户的年龄、性别以及受教育程度等标签构建用户画像,并通过用户画像选择更贴近用户风格的语句描述,从而提升描述模型与用户之间的交互性。结合风格化的图像描述,使得描述语句更具可读性,更接近真人的表达,使机器与人类之间的交流更自然、更顺畅。
