
基于SK-EfficientNet的番茄叶片病害识别模型
2022-08-08 05:37隆娟娟宋衍霖
广西师范大学学报(自然科学版) 2022年4期
帖 军,隆娟娟,郑 禄,牛 悦,宋衍霖
(1.中南民族大学 计算机科学学院,湖北 武汉 430074; 2.湖北省制造企业智能管理工程技术研究中心,湖北 武汉 430074)
番茄是蔬菜的重要品种,消费量巨大,但番茄叶片病害的种类繁多,会降低番茄的产量和质量,给种植者带来巨大经济损失[1-2]。传统番茄病害防治主要依靠专业农业植保技术人员或经验丰富的番茄种植人员,通过人工诊断病害种类,具有较强的主观性,且耗时耗力。因此需要一种准确、快速且高效的方法来自动识别番茄病害,从而满足番茄的现代化种植需求[3]。
随着机器学习在农业领域的应用,科研工作者针对番茄叶片病害识别进行了深入研究[4]。Xie等[5]在番茄早疫病的研究中利用番茄图像纹理特征,取得88.46%的准确率;柴阿丽等[6]采用逐步判别与贝叶斯判别结合的方法实现特征参数的选择,并利用主成分分析与费歇尔判别结合的方法构建识别模型,识别率为98.32%;刘君等[7]融合CNN多卷积特征与HOG算法,将CNN抽取番茄叶部病害的浅层特征与抽取的HOG特征合并,并利用SVM分类器对6种病害番茄和健康番茄进行分类,识别率为92.49%。番茄叶片病害的机器识别方法通常是手动标记番茄病害特征,但不同病害特征在不同场景下表现不一,同种病害在不同发病阶段表现的病症差异明显,以及受光照和复杂背景等噪声干扰,使得特征提取十分困难。
相较于传统机器学习方法,基于深度学习的病害识别方法没有复杂的图像预处理和特征提取操作,而是通过引入卷积层、池化层、全连接层等操作,自动提取图像特征,并在现有研究中取得一定进展[8]。Thangaraj等[9]通过分析现有应用于番茄病害识别任务的传统图像处理、机器学习和深度学习方法,总结发现深度学习方法在性能表现上要优于传统图像处理和机器学习方法;Jia等[10]采用VGG16提取图像特征,并结合SVM分类器检测番茄叶片,平均识别准确率为89%;Tm等[11]采用简单卷积神经网络LeNet对10种番茄病害进行识别,平均识别准确率为95%;Kaur等[12]提出基于DAG-ResNet模型,并采用ECOC对PlantVillage数据集的7种番茄病害进行分类,取得了98.8%的准确率;Gonzalez-Huitron等[13]对4种轻量级模型结合迁移学习在Plantvillage数据集上进行训练分析,在性能上取得不错的效果,并开发可应用于PC、Raspberry Pi 4或移动端的GUI设备;郭小清等[14]针对番茄病害在不同发病阶段表征不一的问题,提出基于改进AlexNet的识别模型,通过移除AlexNet局部响应的归一化层,修改其全连接层,并设置不同大小的卷积核增强病斑特征的提取能力,在PlantVillage数据集上平均识别率为92.7%;汤文亮等[15]基于条件卷积和通道注意力机制自定义模型,并利用知识蒸馏法进行轻量化,在PlantVillage数据集上平均识别准确率为97.7%;张宁等[16]采用InceptionV3结合多尺度卷积和注意力机制模块,并结合迁移学习在PlantVillage数据集的5种番茄病害上平均识别准确率为98.4%。以上研究证明将深度学习应用于番茄叶片病害识别的可行性和有效性,但依旧存在一些不足,比如模型识别准确率还有进一步提升的空间,训练参数较多限制了模型部署与实际应用等。
注意力机制是神经网络领域的一个重要概念,它可以帮助网络获取兴趣区域,减少对非重要信息的关注度,从而提高网络识别效果[17-18],目前在自然语言处理[19-20]与图像分割[21]领域已取得较大进展。Fu等[22]和Hu等[23]将注意力机制融合到VGG模型并应用到图像分类任务中,取得不错的效果。本文将注意力机制应用到番茄叶片病害识别,对轻量级网络EfficientNet进行改进,引入SKNet替换SENet,SKNet是对SENet的进一步改进,可以根据输入信息的多尺度自适应调节感受野的大小,在提高番茄叶片病害图像特征的提取能力的同时更有效地利用参数。
1 番茄叶片病害识别模型
1.1 EfficientNet网络模型
模型扩展是提高网络效果的重要方法。ResNet[24]通过增加网络层数将ResNet18扩展到ResNet200,GPipe通过将卷积网络的baseline扩展4倍,在ImageNet上准确率达84.3%。传统的模型缩放通过增加网络深度、宽度以及输入图像分辨率来进行训练。这些方法虽然可以提高准确性,但需要长时间的手动调优,并会产生次优性能。2019年,谷歌提出一种新的缩放模型EfficientNet[25],通过设置复合缩放系数来平衡网络的宽度、深度和分辨率,从而在扩展网络维度时可以获得更好的模型性能。复合比例系数的计算如式(1)所示:
(1)
式中:d、w、r为缩放网络的深度、宽度和分辨率;α、β、γ为对应缩放基数;φ为复合缩放系数。在约束条件下,首先取φ=1,通过网格搜索可以确定α=1.2,β=1.1,γ=1.15,即基准模型EfficientNet-B0。接着固定α、β、γ,对φ取不同的值实现基准模型缩放,即可获得EfficientNet-B1到B7。
1.2 SKNet网络
在构建传统CNN时,一般在同一层只采用一种卷积核,对于特定任务特定模型,卷积核大小是确定的,每层网络中神经元的感受野大小是相同的,但忽略了多个卷积核的作用。Li等[26]在CVPR2019上提出选择性卷积核机制SKNet,其采用一种非线性的方法融合来自不同核的特征,根据输入的不同尺寸信息自适应调整感受野大小,由3个操作组成:Split、Fuse和Select。Split操作生成具有各种卷积核大小的多个路径;Fuse操作融合来自不同通道的信息,从而获得一个全局及可理解性的表示用于进行权重选择;Select操作根据选择圈子聚合不同大小的卷积核的特征映射。选择性卷积核机制SKNet结构如图1所示。
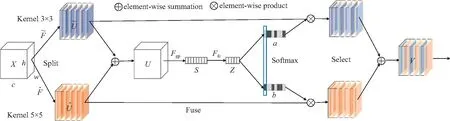
图1 选择性卷积核机制结构
1.3 基于SK-EfficientNet的识别模型
EfficientNet网络利用神经网络结构搜索[27](neural architecture search,NAS)基准模型EfficientNet-B0,并对网络深度、宽度以及分辨率进行复合缩放,对于ImageNet历史上的各种网络而言,EfficientNet在速度、精度上实现碾压的效果。SKNet是针对卷积核的注意力机制研究,使用多分支卷积网络[28]、组卷积[29]、空洞卷积[30]以及注意力机制,对不同图像使用不同的卷积核权重,从而动态调整感受野大小,相比SENet通道注意力机制具有更强的特征提取能力,也能够更加有效地利用参数。受两者特性启发,本文提出基于SK-EfficientNet的识别模型,针对EfficientNet的核心模块移动翻转瓶颈卷积(mobile inverted bottleneck convolution,MBConv)进行改进,MBConv模块由普通卷积、深度可分离卷积(包含BN和Swish)、SE(squeeze-and-excitation)模块、Droupout层构成,如图2所示。
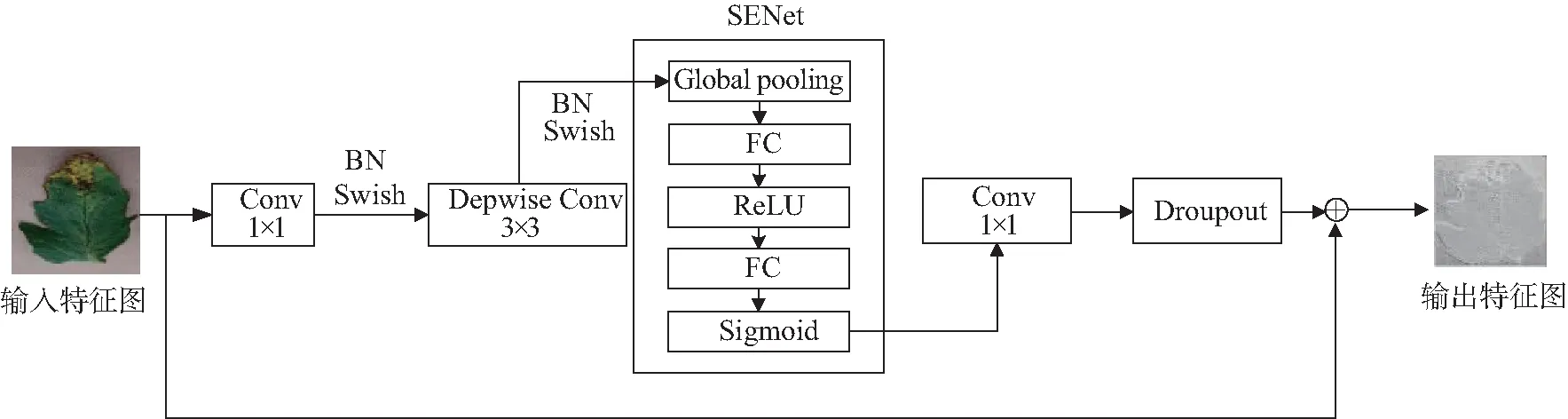
图2 原始MBConv模块
本文将MBConv模块中SENet替换为SKNet,在1×1卷积后分别进行3×3深度可分离卷积和dilation为2的3×3空洞卷积,对输入特征进行不同卷积核大小的完整卷积操作,得到2个新的特征图,接着,对两者的输出特征进行求和融合,获得全局特征,再通过全局平均池化来获得全局信息Sc,如式(2)所示。
(2)
式中:Fgp表示全局平均池化;Uc表示Split融合后得到的新的特征图;H×W为特征图Uc的分辨率;i和j代表UC在H和W上不同的通道图。
在全局平均池化层后通过2个全连接层得到不同卷积核所占权重比Z,如式(3)所示。
Z=Ffc(s)=δ(B(Ws)),
(3)
式中:δ表示ReLU函数;B表示批正则化处理BN;Ffc表示全连接层;Ws表示通道s的权重。
在通道方向进行Softmax操作,回归出通道和卷积核之间的权重信息,最后将Droupout失活函数得到的特征图与原始特征图进行融合,形成最终的SK-MBConv模块,如图3所示。

图3 改进后SK-MBConv模块
由此改进后的SK-EfficientNet网络结构如图4所示,由16个改进SK-MBConv模块、2个卷积层、1个全局平均池化层和1个全连接层构成。图中不同颜色代表了不同阶段,首先利用3×3卷积核对输入的224×224×3的图像进行升维操作,得到维度为112×112×32的特征图,接着对特征图进行不同维度的SK-MBConv,当出现相同的SK-MBConv时,进行连接失活和输入的跳跃连接;最后经过1×1逐点卷积恢复原通道,并使用全连接层进行分类。
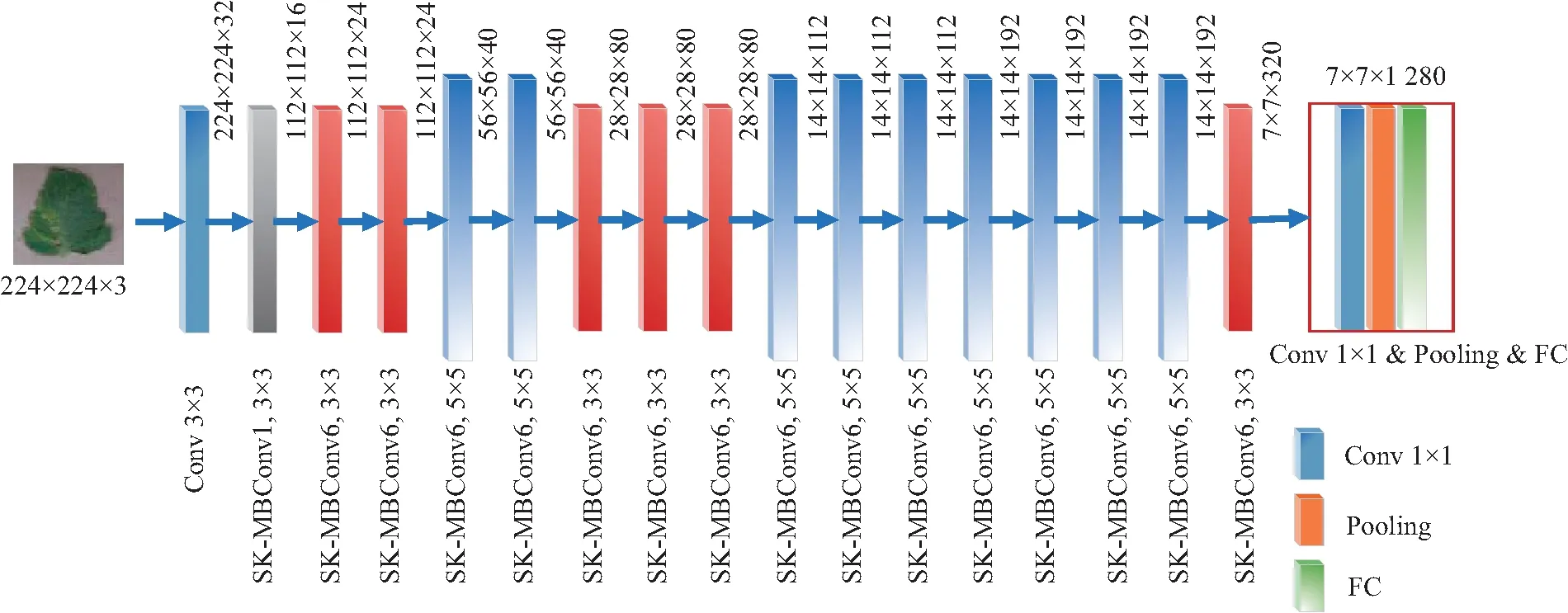
图4 SK-EfficientNet识别模型
2 实验结果与分析
2.1 实验环境与参数设置
为确保训练的可靠性,本文采用十折交叉验证法进行实验,将数据集随机划分10份,其中8份训练集、1份验证集以及1份测试集,循环10次。实验采用的系统平台为64位CentOS,深度学习框架为Pytorch,编程语言为Python;计算机处理器Intel(R)Xeon(R)CPU E5-2630 v4@2.20 GHz,内存64 GiB,硬盘1 TiB,并采用Tesla P40 GPU加速图像处理。
在模型训练过程中,采用批量训练的方法将训练集与验证集分为多个批次(batch),其中训练批次设置为16,验证批次为8,共迭代70轮。同时采用随机梯度下降优化算法(stochastic gradient descent,SGD)对模型进行优化,设置学习率为0.001,正则化系数为0.000 5,防止出现过拟合。
2.2 实验数据来源
本文所用数据集来源于PlantVillage数据集和Dataset of Tomato Leaves数据集,其中PlantVillage数据集收录了大量的植物病虫害图像,本文选取番茄叶片图像,共10个类别,包含9种病害和健康叶片,共18 160张。Dataset of Tomato Leaves数据集为Mendeley Data中的自然场景番茄叶片图像,由单叶片、多叶片、单背景和复杂背景组成,共6个类别,5种病害和健康叶片,图像总数622张。图5和图6分别给出了2个数据集的示例样本。

图5 PlantVillage番茄叶片病害示例

图6 Dataset of Tomato Leaves番茄叶片病害示例
2.3 实验数据预处理
数据样本分布不均匀和自然场景样本过少会对模型的识别性能产生影响,故本文采用数据增强的方法对2.2节介绍的2类数据样本进行扩充,模拟真实农业场景,以提高适应性。采用的数据增强方法有:1)随机裁剪,对图像随机选择像素位置和方向进行裁剪;2)旋转,对图像沿着顺时针方向随机旋转90°、180°和270°;3)颜色增亮,通过更改色调(H)、饱和度(S)、亮度(V),改变亮度V与饱和度S的分量,让色调H保持不变,从而达到增亮的效果;4)高斯模糊添噪,在实际应用中图像的清晰度各不相同,通过给图像添加高斯噪声与椒盐噪声来模拟真实场景。2类数据集部分病害增强预处理效果如图7所示,最后把数据集图像的大小设为256×256。经过预处理以后,得到PlantVillage图像样本共31 117张,Dataset of Tomato Leaves图像样本共6 526张,作为最终实验的番茄病害样本数据集,2类数据集图像增强前后对比如图8所示。

图7 数据增强预处理效果
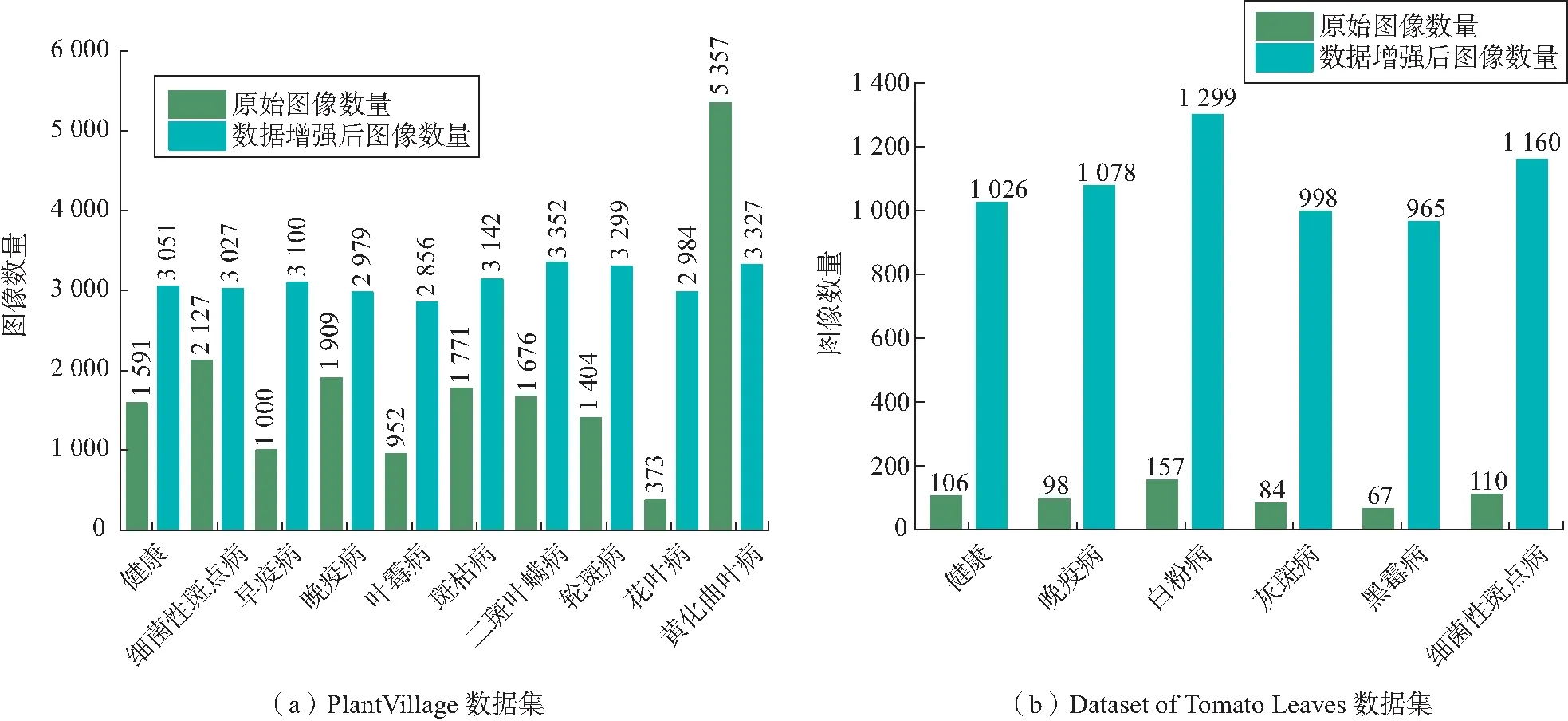
图8 数据增强前后对比
2.4 PlantVillage数据集下实验结果与分析
为验证改进后EfficientNet模型性能优势,针对单一环境下的PlantVillage番茄叶片病害图像数据集,训练多个模型进行对比实验,包括ResNet50、MobileNet、InceptionV3以及原始EfficientNet模型。评价参数采用平均识别准确率、模型参数和单张识别时间,每个模型训练10次取其平均值,计算得到对比实验结果如表1所示,不同模型训练准确率对比如图9所示。改进后模型的平均识别准确率为99.64%,高于ResNet50、MobileNet和InceptionV3,相比原始EfficientNet模型提高0.23个百分点。改进后模型参数仅需3.83 MiB,对内存需求明显低于ResNet50和InceptionV3,相比MobileNet和原始EfficientNet更加轻量化,体现出改进后模型提高了番茄病害识别率,降低了模型参数内存的需求。在时间消耗方面,改进后EfficientNet模型测试单张图片的平均耗时为1.08 s,优于ResNet50、InceptionV3和原始EfficientNet模型,MobileNet虽然耗时稍低一些,但其平均识别准确率比本文改进的模型要低1.42个百分点。在番茄叶片病害的实际应用中,识别准确率是比识别速度更为重要的性能指标,因此本文改进的模型针对番茄叶片病害识别问题具有一定的性能优势。

图9 不同模型训练过程中识别准确率的变化

表1 不同模型对比实验结果
为进一步比较各模型的性能,采用Softmax交叉熵损失函数来分析,绘制不同模型的损失函数,对比结果如图10所示。由图10可以发现本文改进的模型在对比模型中训练损失最小,收敛速度最快,在迭代次数超过30次后,损失值趋于平稳。验证了改进后的模型能够更好地应用于实际场景下番茄叶片病害识别工作。
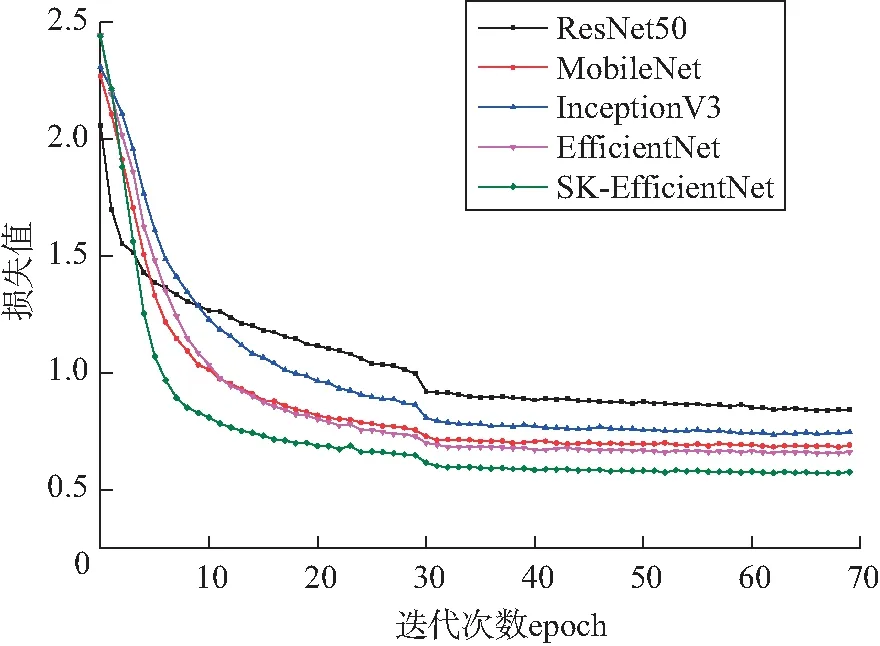
图10 不同模型训练过程中损失值的变化
作为分类模型评价指标之一,混淆矩阵可直观表示各类别误分为其他类别的比重。行列交叉的数值是该类别被预测为对应列标签的概率,对角线处的数值是该类别被预测准确的概率,对角线的颜色越深代表模型识别效果越好。本文对测试集在SK-EfficientNet模型上的混淆矩阵进行可视化,如图11所示。由图11可以看出,本文改进的模型在测试集上也取得了不错的识别效果,对于番茄大部分病害都能完全被识别正确,晚疫病的误识别率比其他稍高,但平均识别准确率能达到99%以上。由此可知本文改进的模型具有较好的鲁棒性,可以为番茄叶片病害识别提供参考。
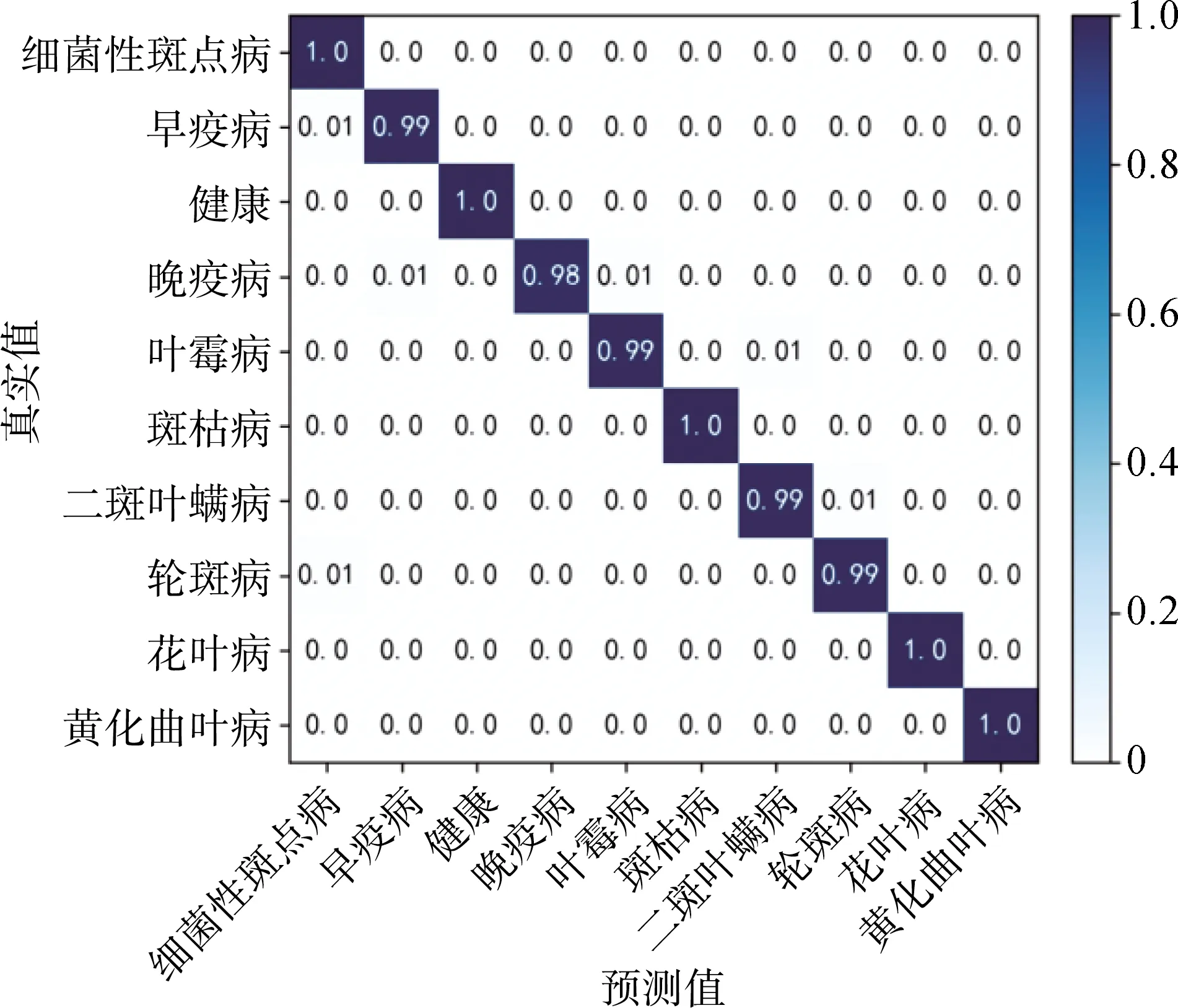
图11 SK-EfficientNet识别番茄病害的混淆矩阵
为了进一步验证番茄图像数据集在EfficientNet-B0到B7的分类效果,本文分别构建SK-EfficientNet-B0到B7分类模型,计算得到对比实验结果如表2所示。从表2可以看出,由于目前实验计算机计算能力有限,SK-EfficientNet-B6、B7模型训练受到了限制,SK-EfficientNet-B2表现出了更好的精度优势。
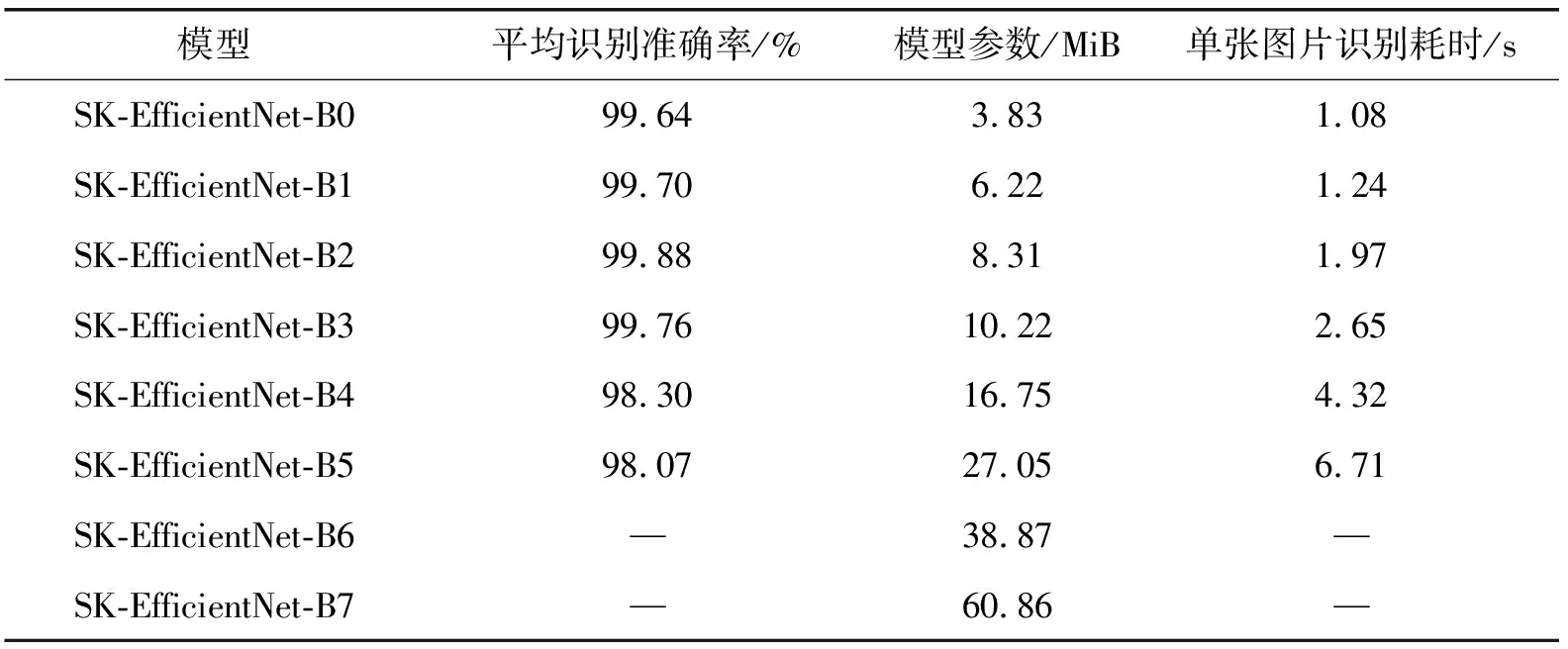
表2 不同EfficientNet对比实验结果
此外,为更好地分析改进后网络对图像特征表达的过程,将各SK-MBConv模块卷积层输出的特征图进行可视化,为便于可视化,只列出前3个SK-MBConv。由图12可以发现,随着网络层数的增加,网络特征提取层关注的图像特征越来越抽象,特征的纹理性也逐渐被更高级的语义性所代替;本文改进的网络从过程上能够获得较为丰富的边缘信息,从结果上可以取得较高的识别精度,适用于番茄叶片病害识别问题。

图12 部分SK-MBconv可视化卷积特征图
2.5 Dataset of Tomato Leaves数据集下实验结果与分析
为验证本文提出的模型在自然场景下的识别效果,针对自然环境下的Dataset of Tomato Leaves数据集,再次训练模型进行实验对比,结果如表3所示。相比ResNet50、MobileNet、InceptionV3网络,本文改进的网络在识别精度上有很大提升,改进后的模型平均识别率为93.28%,相比原始模型提升3.81个百分点,单张图像识别耗时也明显降低。
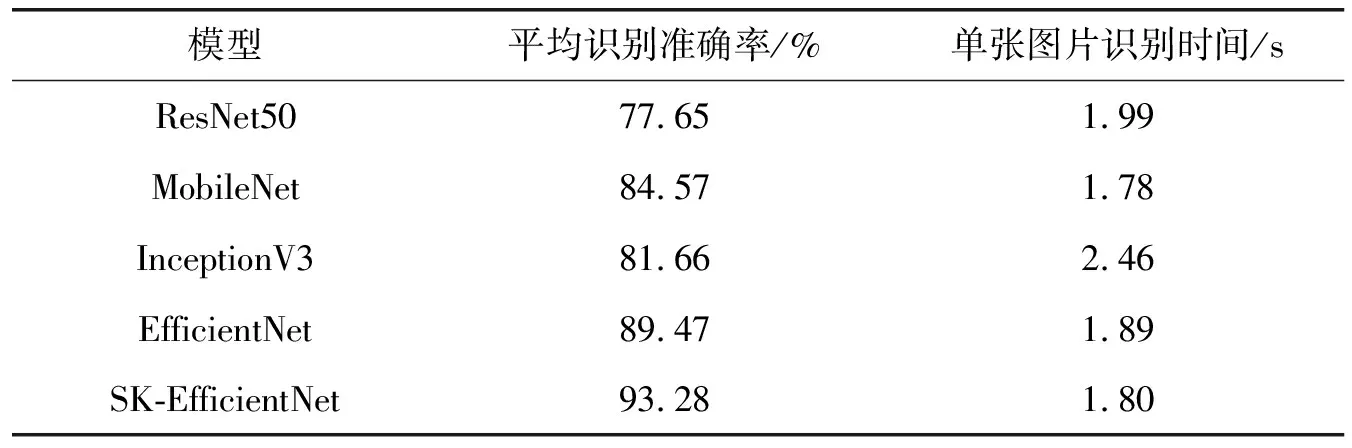
表3 自然场景下不同模型对比实验结果
为验证本文改进的模型在自然场景下的鲁棒性,选取测试集中带有复杂背景的细菌性斑点病和多叶片黄化曲叶病,观察改进模块SK-MBConv不同网络层对病害所关注的特征信息,对特征热力图进行可视化。由图13可以发现,随着网络层数的增加,提取的病害特征越来越清晰,受复杂背景等干扰信息的影响越来越小。由此可以说明本文改进的模型具有较强的特征提取能力,在一定程度可以去除复杂背景等干扰信息的影响,增强模型的鲁棒性。
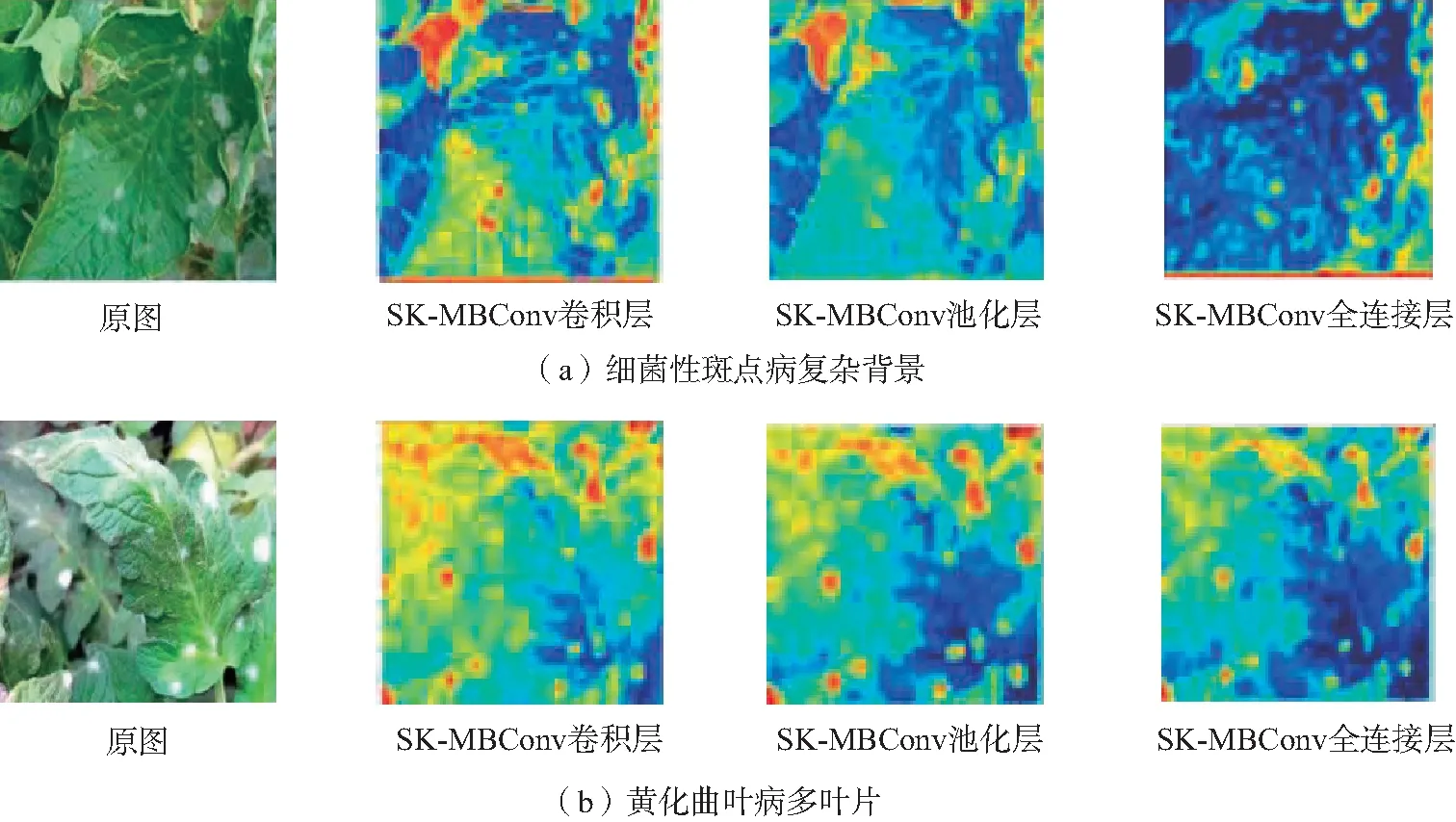
图13 SK-MBConv不同层热力图
3 结论
本研究针对目前大部分番茄病害识别模型识别精度不够高,所需参数多的问题,提出一种基于SK-EfficientNet的番茄病害识别模型,通过将SKNet网络融入EfficientNet核心模块MBConv,并设置多组对比实验,分析模型识别率和所需参数,最后将该模型应用于自然场景,得到如下结论:
1)SKNet相比SENet,其优越性在于可以使卷积核根据输入特征的多尺度信息自适应选择感受野的大小,提高对图像特征的提取能力,具备更高的分类性能,也更有效地利用了参数。实验结果证明在单一环境下基于SK-EfficientNet模型平均识别率达到99.64%,模型参数仅需3.83 MiB,优于其他模型。
2)在目前实验室计算机计算能力的限制下,SK-EfficientNet-B2取得了最好的识别效果,平均识别准确率99.88%。
3)本文模型在自然场景下的应用优势更为突出,平均识别率达93.28%,相比原模型高出3.81个百分点,能够为自然场景番茄叶片病害识别提供参考。但目前识别精度仍不高,有进一步提升的空间,后续工作将针对自然场景继续改进模型。
猜你喜欢
小猕猴学习画刊(2022年12期)2022-02-06
今日农业(2021年21期)2022-01-12
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
今日农业(2020年23期)2020-12-15
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
