
基于反向权重的阅读器防碰撞算法
2022-08-17 10:07王瑞佳赵菊敏
电子设计工程 2022年15期
王瑞佳,赵菊敏
(太原理工大学信息与计算机学院,山西晋中 030600)
在大型场景中,标签密集部署且分布广泛,需采用多阅读器识别模式[1]。在多阅读器识别模式中,为了避免标签漏读的情况,阅读器的识别范围出现大面积重叠,使碰撞可能性增大[2],导致了标签识别吞吐量的减少及识别延迟的增加,严重影响系统的识别效率[3]。
现研究阶段的阅读器防碰撞算法主要分为基于功率调节的阅读器防碰撞算法、基于调度的阅读器防碰撞算法[4]。这两种调度方法在阅读器碰撞较多的大规模场景[5]中,需要进行多轮的调度,整体系统效率低下,且占用资源较多[6]。因此,迫切需要解决大规模场景中阅读器的碰撞问题。
1 基于反向权重的防碰撞算法
基于反向权重的阅读器防碰撞算法提出用反向权重图的方法表示阅读器碰撞关系;设置控制通道各个阅读器共享信息;设置碰撞阈值,简化阅读器碰撞情况;定义阅读器优先级,实现动态调度。
1.1 反向权重结构图的概念
在大规模场景中阅读器的碰撞情况复杂,在无向图中会出现多条连接不直观的情况。因此该文提出反向权重结构图的概念。反向权重结构是指类似于多个多叉树的结构,一颗多叉树代表与其他阅读器没有碰撞的集合。两个节点之间若有连接关系,则表示存在碰撞关系。节点代表阅读器,将与父节点有碰撞的全部阅读器作为该父节点的子节点。阅读器分布简图如图1 所示,根据图1 得到阅读器的反向权重结构图如图2 所示。

图1 阅读器分布简图

图2 反向权重结构图
1.2 阅读器优先级定义
文中算法的目的在于将阅读器集合映射为森林,森林数越多,则代表阅读器独立集越多,可以并行工作的阅读器数量就越多,系统的工作效率也就越高。因此该算法采用优先级的调度方式。该文定义阅读器优先级如式(1)所示:

等待时间参数使短时间的作业优先运行,提高了系统的吞吐率;节点入度可简化后续阅读器的调度分配;等待时间保证了系统的公平性。每个阅读器工作完成后,系统会更新反向权重结构图,阅读器的入度会相应的改变,因此每个阅读器的优先级也会发生相应的改变,且每个无碰撞的阅读器会实时加入识别队列中,整个系统以一种动态的反向权重结构的调度方式工作,兼顾了系统的效率和公平性。
为了使以上描述更为清晰,进行了举例说明。假设阅读器的碰撞情况如图1 中重叠部分所示,各个阅读器的识别时间如表1 所示。

表1 阅读器识别时间
各个阅读器开始时等待时间均为0 s,阅读器优先级如表2 所示。

表2 阅读器优先级
第一轮选择运行状态的阅读器集合过程如图3所示。
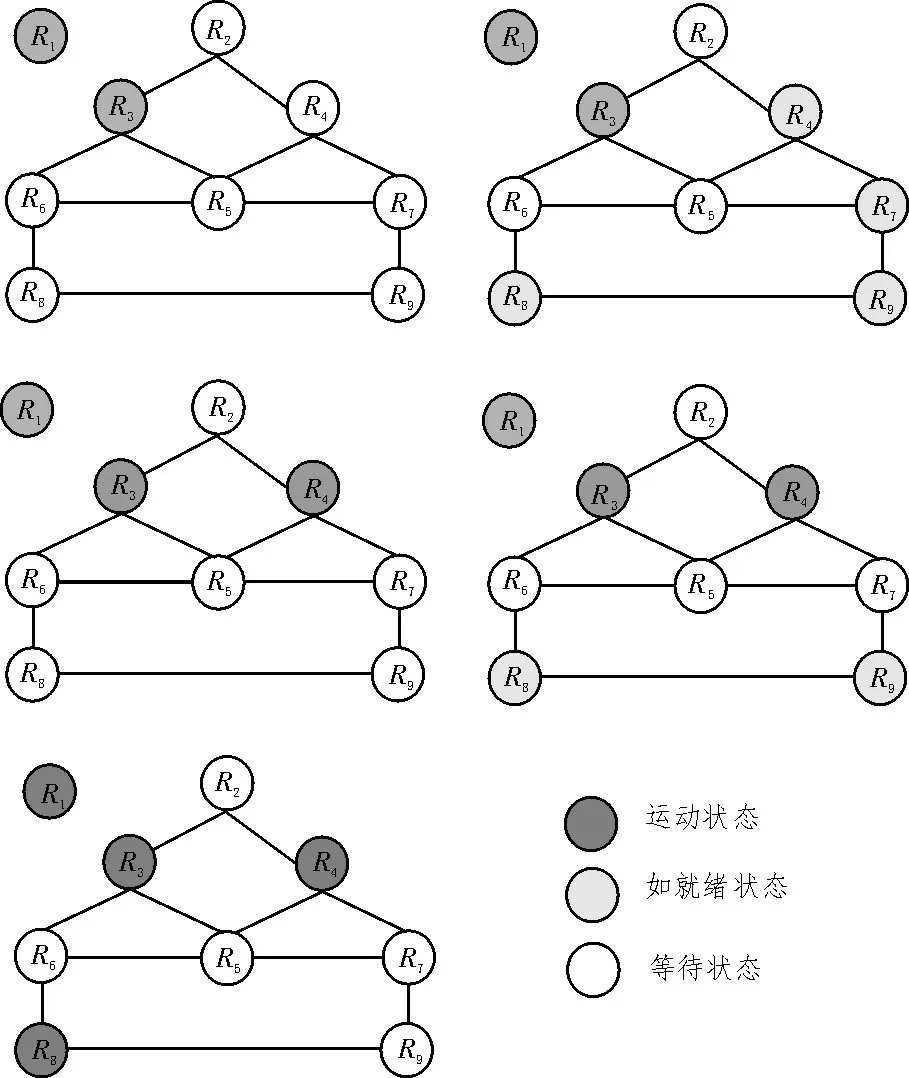
图3 第一次轮选择阅读器集合过程
1.3 碰撞队列和识别状态的设置
文中算法为了尽量避免消息延时的情况,选择使用分布式构架,并通过设置控制通道使阅读器之间可以共享信息。控制通道上发送阅读器开始识别(start)和结束识别(end)的消息。为节省资源,“start”以“S”代替,“end”以“E”代替。为每个阅读器建立碰撞队列和状态信息。
微生物肥料已成为新型肥料中年产量最大、应用面积最广的品种,预计到“十三五”结束时,年总产量比现在翻一番——
碰撞队列:存放碰撞阅读器识别状态的队列。队列的长度为每个阅读器在树形结构图中的入度。一个队列长度中存放产生碰撞的阅读器编号信息。
识别状态:用来区分阅读器的工作状态,以挑选无碰撞的阅读器独立集服务。分为等待状态、就绪状态、运行状态和结束状态。
等待状态:所有阅读器刚开始的识别状态为等待状态,或者碰撞队列中存在阅读器信息时,该阅读器为等待状态。
就绪状态:碰撞队列中没有阅读器,可以加入识别队列的阅读器的状态。
运行状态:正在识别的阅读器的状态。
结束状态:完成识别的阅读器的状态。
刚开始时,所有的阅读器都为等待状态,在第一轮通过阅读器优先级遍历反向权重结构图后,将选择出的独立集阅读器改为就绪状态,开始识别时各阅读器的状态变为运行状态。运行状态中的阅读器需要向其他阅读器发送自己的识别信息,为了避免控制通道信息的碰撞,各阅读器按照优先级的顺序在控制通道上广播带有自己编号和“S”的信息,周围阅读器将广播中的信息存储到自己队列信息中。阅读器若监听到一个阅读器的“E”信息后,检查自己的队列信息,并将该阅读器的信息从队列中清除。若此时队列不为空,保持等待状态。若此时阅读器队列为空,则转为就绪状态。当监听到“E”信息后,等待T时间若没有新的“E”信息,则更新反向权重结构图。其中,等待T时间是因为同时完成识别的阅读器根据优先级的大小,先后发送“E”信息,时间间隔为T。若就绪状态中出现与之有碰撞情况的阅读器,则比较两个阅读器的优先级,若优先级高则进入运行状态,优先级低则进入等待状态。识别完成后的阅读器将状态改为结束状态。
1.4 算法具体步骤
基于反向权重的阅读器防碰撞算法的具体实现步骤为:
1)根据阅读器碰撞情况画出反向权重结构图。
2)在每一棵树上选择优先级最高的阅读器,将阅读器的等待状态改为就绪状态。
3)以就绪状态节点为首节点,遍历反向权重结构图,挑选无碰撞的阅读器集合,将其状态改变为就绪状态。
4)遍历完成后,使所有就绪状态的阅读器开始识别,状态变为运行状态。
5)运行状态的阅读器按照优先级在控制通道上广播自己的编号以及“S”信息。
6)等待状态的阅读器不断监听控制通道的信息。当阅读器监听到某一个阅读器编号及“S”信息后,将该阅读器编号放入自己的碰撞队列中。当阅读器监听到某一个阅读器编号及“E”信息,检查自己的碰撞队列,将该编号从队列中删除。
7)等待T时间。更新反向权重结构图。将结束状态的阅读器从结构图中删除,重新调整阅读器之间的碰撞关系。
8)判断反向权重结构图中是否还有节点,若有则继续执行,若无则直接执行步骤11)。
9)等待状态的阅读器检查碰撞队列是否为空,若为空将等待状态转为就绪状态,若不为空,则继续监听控制通道的信息。
10)就绪状态的阅读器根据反向权重结构检查是否存在有碰撞情况的阅读器,若无,则将就绪状态转为运行状态,开始识别;若有,则根据反向权重结构图计算阅读器优先级,将优先级高的阅读器加入识别队列,状态改为运行状态,将优先级低的阅读器转为等待状态,继续监听控制通道信息。
11)阅读器识别完毕,系统工作完成。
2 仿真实验和性能比较
该节将通过仿真手段验证文中提出的基于反向权重的阅读器防碰撞算法(FLSM),并将其与最小反向权重的阅读器防碰撞算法(MRWA)、传统的极大独立集阅读器防碰撞算法(MISR)以及经典的阅读器调度算法NFRA++进行性能比较。在模拟实验中,0~500 个阅读器和200~10 000 个标签均匀分布在长度和宽度都为200 m 的区域中,将阅读器识别半径设置为7 m。服务器主要用于时间同步和给阅读器发送指令,服务器半径R=100 m。
图4 表示400 个阅读器均匀分布在识别场景中,各个算法识别标签数目的对比。从图中可以看出,各个算法都具有相同的变化趋势,随着时隙数的增加,识别标签的数目先增加,然后都趋向于稳定。从整体效果可以看出,该文提出的算法识别标签个数最多、算法性能最好。
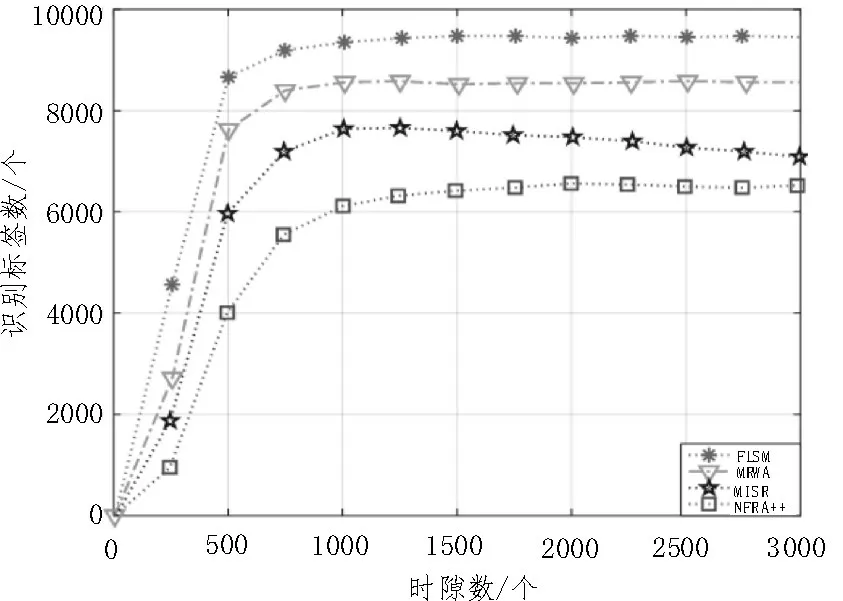
图4 各个算法识别标签数量对比
图5 是各个算法激活所有阅读器所用帧数的对比。基于调度的阅读器防碰撞算法主要目的在于找到最大个数的无碰撞阅读器集合,使其并行工作以提高整体识别效率。从图中可以看出,该文提出的算法激活所有阅读器所用帧数最少。因为该文提出的防碰撞算法在阅读器调度过程中将阅读器碰撞入度考虑在内,更快地消除了阅读器之间的碰撞问题,因此该算法激活所有阅读器所用帧数最少。
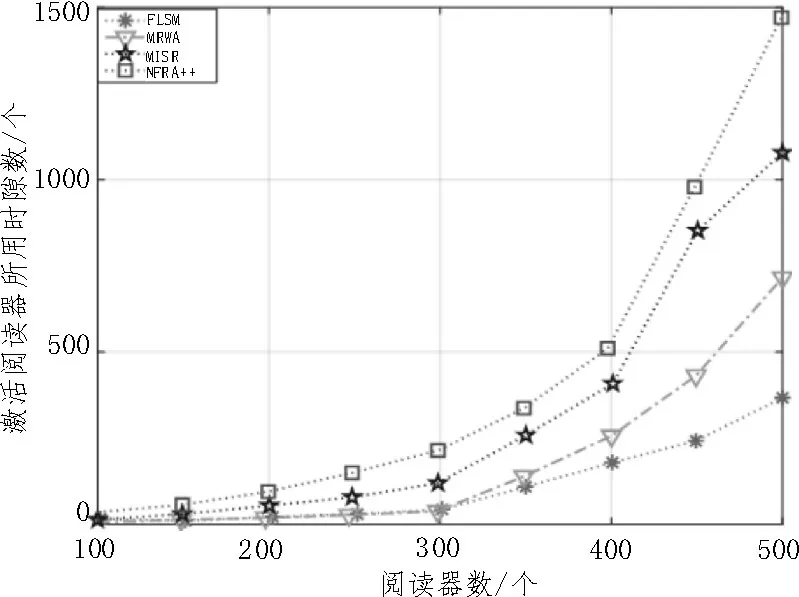
图5 激活阅读器所用时隙数对比
图6 为各算法在相同识别环境中吞吐量的比较。从图中可以看出,该文算法吞吐量呈现稳定上升的趋势。因为标签数量少时,阅读器碰撞和标签碰撞都相对较少,阅读器识别个数并没有达到饱和,所以随着激活阅读器个数的增加,系统吞吐量呈现上升的趋势。随着标签数量的增多,阅读器之间的碰撞和标签之间的碰撞增加,阅读器识别个数最终会趋于稳定。从图中可以看出,该文提出的算法吞吐量最高。
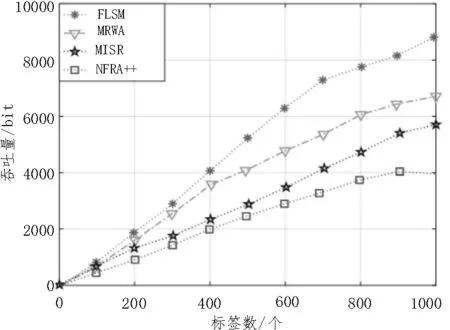
图6 吞吐量对比
3 结束语
针对大规模阅读器碰撞问题,该文提出了基于反向权重阅读器防碰撞算法,该算法利用反向权重结构图表示阅读器之间的碰撞信息;根据阅读器优先级实现阅读器之间的动态调度。该算法不仅解决了传统功率调节阅读器防碰撞算法标签漏读的问题,而且在大规模射频识别系统表现出了良好的性能。
猜你喜欢
浙江共产党员(2022年10期)2022-11-23
英语世界(2020年10期)2020-11-06
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
英语世界(2020年2期)2020-03-08
中学生数理化·高一版(2019年3期)2019-04-15
军营文化天地(2018年2期)2018-12-15
计算机应用(2017年8期)2017-10-21
计算机技术与发展(2017年6期)2017-06-27
