
结合动态多类信息的兴趣点推荐
2022-08-18 09:08於跃成张宗海
计算机与现代化 2022年8期
冯 申,於跃成,张宗海
(江苏科技大学计算机学院,江苏 镇江 212100)
0 引 言
近年来,像Foursquare、Gowalla和Yelp这样基于位置的社交网络(Location Based Social Networks)已逐渐渗透到人们的日常生活中。数百万用户在LBSNs上的签到行为生成了大量的签到数据,这为挖掘用户签到行为的内在模式提供了一个绝佳的机会[1]。用户签到兴趣点(如餐馆和博物馆)并与朋友分享他们的位置和体验时,签到记录中往往包含了被访问的兴趣点及其用户活动的相关上下文信息,包括签到时间、签到点的地理位置、类别或评论等。这些用户关于兴趣点的签到序列隐式地反映了用户对兴趣点的偏好和用户的日常活动模式,从而为根据用户的历史签到记录开展个性化的兴趣点推荐提供方便[2]。
传统的协同过滤方法首先从用户的签到历史中挖掘相似用户,然后根据相似用户的签到记录来推荐兴趣点[3]。矩阵分解方法是广为使用的协同过滤方法之一,其基本思想是将用户-项目矩阵分解成代表用户和项目特征的2个潜在矩阵。然而,这些方法只能对用户的静态偏好进行建模,无法捕捉用户的动态偏好[4]。
为了解决传统的协同过滤方法只能对用户的静态偏好建模的问题,研究者们提出使用深度学习模型来建模用户的动态偏好。循环神经网络(RNN)中的一种变体长短期记忆网络(LSTM)由于其结构的特性能更好地学习用户签到序列之间的长期依赖模式,被广泛应用于序列化数据建模。考虑到用户兴趣点签到数据与时间之间存在的关联,Zhu等[5]提出了一种Time-LSTM模型,以利用时间门来描述用户行为之间的时间间隔。事实上,兴趣点的签到数据除了包含时间信息外,其中包含的空间信息也是描述用户偏好的关键因素。为此,Liu等[6]提出了一种时空递归神经网络模型(ST-RNN),通过设计特定时间转换矩阵实现了RNN模型对周期性时间上下文信息的捕捉。同时,该模型结合了特定距离的转移矩阵来代替RNN的单一转移矩阵,实现了签到用户地理属性中动态距离属性的有效表示。然而,由于用户签到的数据稀疏性,ST-RNN模型并不能准确刻画相邻签到点的时间关系和空间关系。针对这个问题,Kong等[7]提出的HST-LSTM模型将时空因素引入到LSTM的门机制中,有效缓解了数据稀疏问题,并被应用于一般兴趣点的推荐。
下一个兴趣点推荐主要关注用户的长期和短期偏好建模。考虑到用户的短期偏好与最近签到行为相关,Feng等[8]通过对个性化的序列信息建模,并计算目标兴趣点与最近访问兴趣点之间的距离来描述地理影响,进而捕获用户短期的喜好。事实上,兴趣点推荐不仅取决于用户的短期偏好,还会受长期偏好的影响。受这种想法的启发,Feng等[9]提出了一种DeepMove模型,通过在签到历史轨迹中使用注意力模块来捕捉与当前移动状态最相关的历史轨迹,从而捕获用户的长期偏好。此外,综合考虑长期偏好和短期偏好对用户下一步行为的影响,Wu等[10]提出了一种长短期偏好学习模型,利用注意力机制捕捉用户对兴趣点的关注度来捕捉用户的长期偏好;同时,该模型结合短期模块,利用LSTM来学习用户最近的签到行为。
Wu等[10]同时考虑了用户的长短期偏好,提高了用户下一步签到行为推荐的准确度。然而,该模型没有考虑兴趣点评论文本信息对用户接下来选择的影响。事实上,用户评论包含了用户对兴趣点的偏好信息,通过分析评论文本中隐含的情感倾向,可以更加准确地捕捉用户对兴趣点的个性化偏好。为此,受上述研究启发,本文在考虑用户长短期偏好的基础上,同时将用户的评论信息融入到兴趣点推荐模型中,提出一种结合多类信息的兴趣点推荐模型,即DMGCR。在短期偏好方面,本文方法通过使用双向长短期记忆网络(BiLSTM)提取学习用户评论隐含的语义特征,以捕获用户对兴趣点的情感倾向; 在长期偏好方面,则利用注意力机制来捕获用户对不同兴趣点的关注程度。最终,结合长期偏好和短期偏好来学习不同用户在不同部分上的关注权重,获得下一个兴趣点推荐的概率。
1 相关工作
为了在兴趣点推荐中实现更佳的推荐效果,提供更加符合用户喜好的位置服务,近年来越来越多的研究开始挖掘评论文本隐含的信息来捕获用户偏好。Zhu等[11]提出了一个位置感知的LDA模型来挖掘用户的潜在偏好主题分布,并进一步推断用户可能想去的兴趣点。Ren等[12]利用与兴趣点相关的文本评论配置用户与POI之间的话题模型,然后通过话题提取与参数学习获取用户对兴趣点的偏好。Xing等[13]使用卷积神经网络提取用户评论信息中隐含的语义信息特征,并对这些特征进行分析得出用户的偏好信息。
最近,下一个兴趣点推荐研究的工作主要关注用户长短期偏好的影响。Ying等[14]提出了SHAN模型,它结合了长期和短期偏好来为用户推荐下一个项目,但是他们没有考虑用户的顺序行为。Zhao等[15]提出了一种STGN模型,该模型通过在LSTM结构上添加2对时间和距离门来建模签到点之间的时间和距离间隔,以提取长期偏好和短期偏好。Sun等[16]考虑到当前轨迹中不相邻地点之间的地理影响以及神经网络在短期偏好建模中的局限性,提出了一种地理扩张的RNN模型,充分利用非连续兴趣点之间的地理关系,然后通过一个上下文感知的非局部网络来挖掘历史轨迹和当前轨迹之间的时空相关性。考虑到用户的偏好受到兴趣点位置和类别因素的影响,Wu等[10]提出了PLSPL模型,该方法在长期模块中学习兴趣点的上下文特征,利用注意力机制来捕获用户的长期偏好;在短期偏好模块中,利用2个并行的LSTM模型学习用户的顺序行为以捕获对兴趣点位置和类别信息的偏好。
总的来说,现有的大多数基于LSTM模型很少同时考虑用户的长期偏好和短期偏好,在对短期偏好建模时,重点关注时间和空间的影响,忽略了兴趣点评论信息对用户做出选择至关重要。
2 DMGCR模型构建
为了将评论信息与兴趣点的位置信息和类别信息相结合,以提高兴趣点推荐中用户下一步行为预测的准确率,本文提出了一种结合多类信息的兴趣点推荐方法DMGCR。该方法主要包括长期偏好建模、短期偏好建模和预测3个部分。
如图1所示,本文模型同时考虑用户长短期偏好,在长期模块中,利用注意力机制来捕获用户对不同兴趣点的关注程度;在短期模块中,使用LSTM模型学习用户对兴趣点位置和类别的动态偏好。

图1 DMGCR框架
此外,考虑到用户评论的情感信息对用户接下来的决定有重要影响,本文模型在短期偏好模块中将评论情感信息与兴趣点位置信息和类别信息相结合。为了充分利用用户评论中隐含的情感倾向信息,本文利用BiLSTM学习评论文本中隐含的语义特征,以捕获用户对兴趣点的情感倾向。在预测模块部分,结合长期偏好和短期偏好来学习不同用户在不同部分上的关注权重,计算下一个兴趣点推荐的输出概率。
2.1 相关定义

定义1签到序列。

定义2长期序列。

定义3短期序列。
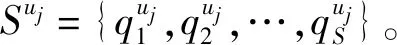
2.2 学习长期偏好
在用户签到序列中,并不是所有的历史签到数据都与用户的下一步行为同等相关,为此,在学习用户长期偏好时需要更多地关注其中重要的信息。类似于Wu等[10]提出的模型,通过引入注意力机制,本文模型可以捕获用户对每个兴趣点不同的偏好,并为它们分配不同的权重。这就能够衡量出用户下一步行为与过去签到行为之间的相关性。
2.2.1 嵌入层表示
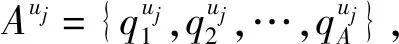
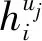
(1)

2.2.2 注意力机制
为了学习用户的长期偏好,本文利用注意力机制来捕获嵌入层学习到的用户潜在向量和兴趣点潜在向量之间的相似性[19]。换言之,就是刻画用户对不同兴趣点的关注程度。
考虑到运算速度和空间效率,如公式(2)所示,本文使用点积注意函数来计算注意力权重:
f(Q,E)=QET
(2)
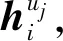
(3)


(4)
其中,Ulong表示用户的长期偏好。

2.3 学习短期偏好
用户的下一步签到不仅与用户稳定的长期偏好相关,还与用户的短期动态偏好相关[21]。考虑到短期序列中用户在不同时间喜好不同的兴趣点,Wu等[10]利用LSTM模型学习用户短期签到的顺序模式。该方法考虑到随着时间变化,用户对兴趣点的位置和类别偏好也随之变化。于是分别使用2个LSTM模型学习用户对位置和类别的动态偏好。本文也采用该方法来学习用户的短期偏好,在此基础上,考虑兴趣点的评论信息对用户下一步行为有重要影响,将签到兴趣点的评论文本融合到模型中。
2.3.1 学习用户对兴趣点位置和类别的偏好
用户的下一步签到行为受用户的短期偏好影响,用户的短期偏好会随时间动态变化。在不同的时间下,用户对兴趣点的位置和类别有不同的偏好[5]。本文使用Wu等[10]方法,通过LSTM模型来学习用户的短期偏好。
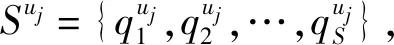
(5)
其中,xt表示输入向量,[vuj;vl;vt]表示用户uj嵌入向量、位置嵌入向量、时间嵌入向量的连接。it表示步骤t时的输入门,决定了需要存储的信息,ft表示步骤t时的遗忘门,选择了遗忘不重要的信息。ot是步骤t时的输出门,决定了最终要输出的信息。c′t表示步骤t时的新候选状态向量。⊙是2个向量的元素积,ft⊙ct-1表示决定忘记上一个状态ct-1中的信息后保留的信息;it⊙c′t表示从新的候选状态向量c′t中决定添加哪些新的信息。ct是结合上一个状态ct-1和新候选状态c′t信息的最终状态向量。ht是隐藏输出向量,代表了用户的动态偏好。σ是激活函数,输出0-1之间的数。Wi、Wf、Wo、Wc是门的权重,Wi、bf、bo、bc是相应的偏置参数。

2.3.2 用户评论文本的情感分析
由于用户评论的内容中蕴含着情感倾向的信息,在推荐中评论数据的情感显得尤为重要。因此,对评论文本内容信息的深入挖掘可以有效解决推荐中存在的冷启动问题[12]。本文考虑通过挖掘用户评论中包含的信息,以捕捉用户对兴趣点的情感倾向。主要方法是:先对评论文本向量化处理,接着利用BiLSTM去学习评论文本隐含的语义特征,最终结合学习到的情感特征值来计算用户对兴趣点的情感倾向。

通过对2层LSTM输出的语义特征矩阵进行相加,将来自上文的语义信息和来自下文的语义信息进行结合。最终,将隐藏层最后时刻输出的语义特征向量输入到一个全连接层去计算评论文本的情感值R。
用户在选择兴趣点时,更加关注兴趣点的评论数量和评论包含的情感信息。对于其中的某一条评论数据,其发表评论的时间也会影响到该评论对用户的参考程度,进而影响到不同时间下兴趣点整体评论的情感极性变化。兴趣点i整体评论的情感倾向Si如公式(6)所示:
(6)
其中,C表示兴趣点i的评论的个数,c表示第c个评论。Rc(i)表示兴趣点i的第c个评论的情感值(该值介于[-1,1]之间)。tcur表示当前时间,tRc(i)表示第c个评论的评论时间。
2.4 长期和短期偏好的融合
当决定接下来去哪里时,不同的用户对长期和短期偏好表现出不同的依赖[21]。对于学习不同用户的不同依赖,即学习不同用户对长期模块和短期模块的个性化权重,本文将长期和短期偏好模块学习的结果与基于用户的线性组合单元相结合。这里的用户偏好不同于前面在长期模块和短期模块中的偏好,它们代表了用户对长期偏好和短期偏好的个性化权重。通过线性组合来计算用户uj对下一个兴趣点i的偏好Pi如公式(7)所示:
(7)
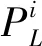
(8)
其中,N是候选兴趣点的总数,e是指数函数。
2.5 DMGCR模型算法优化
上文已经定义了兴趣点的输出概率,因此,目标用户uj在下一个时间t最可能访问的兴趣点是具有最大概率的兴趣点。给定有E个样本的训练集,所提出模型的损失函数定义如公式(9)所示:
(9)
其中,J是本文模型的推荐和实际情况之间的交叉熵损失。E和N分别代表训练集和候选兴趣点的数量。yij是指示变量,当兴趣点j为真实值时,yij的值为1,否则为0。Oij是由本文模型计算的兴趣点j的输出概率。‖Θ‖2是避免过度拟合的正则化项。λ控制正则化项的重要性。为了最小化目标函数,使用随机梯度下降(SGD)和时间反向传播(BPTT)算法来学习参数[23]。算法1中给出了详细的学习算法。
算法1DMGCR算法
输入:用户集U,签到序列Qu,长期序列Auj,短期序列Su,评论序列Rl
输出:训练的模型
1.初始化Θ
2.while(iteration≤Iter)do
3.for用户ujin 用户集Udo
4.计算uj的嵌入向量ruj

8.end for
9.根据公式(3)计算注意力权重ai
10.根据公式(4)计算长期偏好Ulong
13.使用公式(6)计算评论文本的情感倾向Si
14.使用公式(7)和公式(8)计算兴趣点输出概率
15.使用公式(9)使用梯度下降更新Θ
16.end for
17.end while
18.输出训练的模型
3 实验结果及分析
3.1 数据集
本文使用Foursquare和Yelp这2个公开可用的LBSN数据集进行评估实验,这2个数据集都提供用户签到数据[24]。本文中每个签到记录包含用户id、兴趣点id、兴趣点的经纬度、类别名称、签到时间戳、评论文本等信息。这2个数据集中的所有签到记录都被视为用户序列。此外,本文对这2个数据集执行了一个预处理步骤,以过滤掉不活跃的用户和不受欢迎的兴趣点,去除少于10个签到的用户和少于10个用户访问的兴趣点[25]。然后,按照时间戳顺序对每个用户的签到记录进行排序,把前80%作为训练集,剩下的20%作为测试集。数据集统计结果如表1所示。

表1 数据集统计
3.2 基线方法
将本文提出的DMGCR模型与以下6种基本方法进行了比较:
FPMC:通过集成矩阵分解和马尔可夫链方法对一般偏好和顺序行为进行建模。
ST-RNN:基于RNN模型,用特定时间的转移矩阵和特定距离的转移矩阵来建模时间和空间特征。
Time-LSTM:这是LSTM的扩展,它使用时间门来建模连续输入之间的时间间隔。
DeepMove:利用注意力机制从历史轨迹中学习用户的长期偏好,并利用RNN模型从当前轨迹中学习短期偏好。
ST-LSTM:将时间和空间影响结合到LSTM模型中,以缓解兴趣点预测问题中的数据稀疏性。
PLSPL:该方法综合考虑用户的长期和短期偏好,在长期模块中,利用注意力机制学习用户对兴趣点的长期偏好;在短期模块中,使用LSTM模型学习对位置和类别偏好。
3.3 评估指标
本文使用精确率和平均准确率这2个指标评估不同兴趣点推荐方法的性能,其中精确率使用P@k表示,平均准确率使用MAP@k表示[26]。它们是评估排名列表质量的标准指标,值越大,性能越好。对每个用户,P@k表示真实访问POI是否出现在前k个推荐POI中,MAP@k衡量推荐列表的顺序。使用这2个指标是希望推荐的兴趣点不仅出现在前个列表中,而且出现在推荐列表的顶部。本文在实验中设置k=1,5,10,20。给定带有E个样本的训练集,这2个度量函数定义如下:
(10)
(11)

3.4 方法性能比较
在这一小节中,比较了DMGCR方法与其他方法之间不同的性能。表2和表3分别验证了在Foursquare和Yelp数据集上使用P@k和MAP@k评估方法的性能。
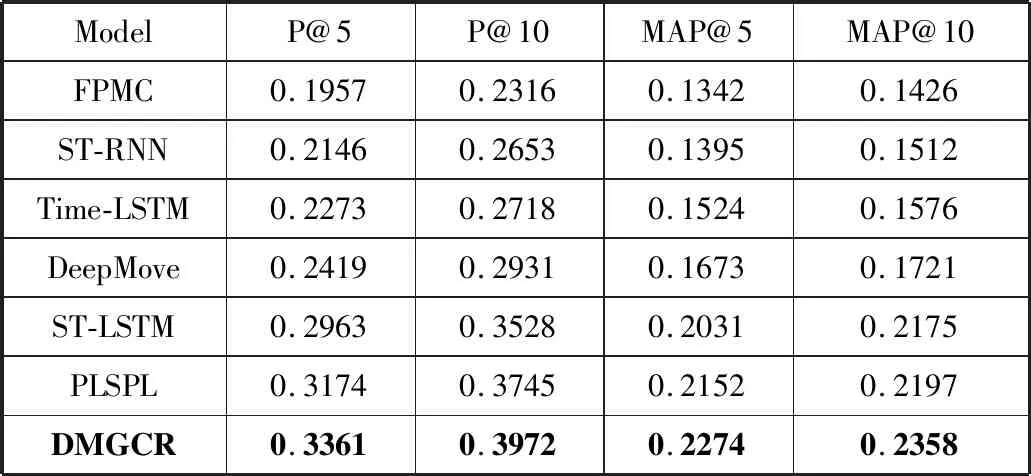
表2 Yelp数据集上的性能比较
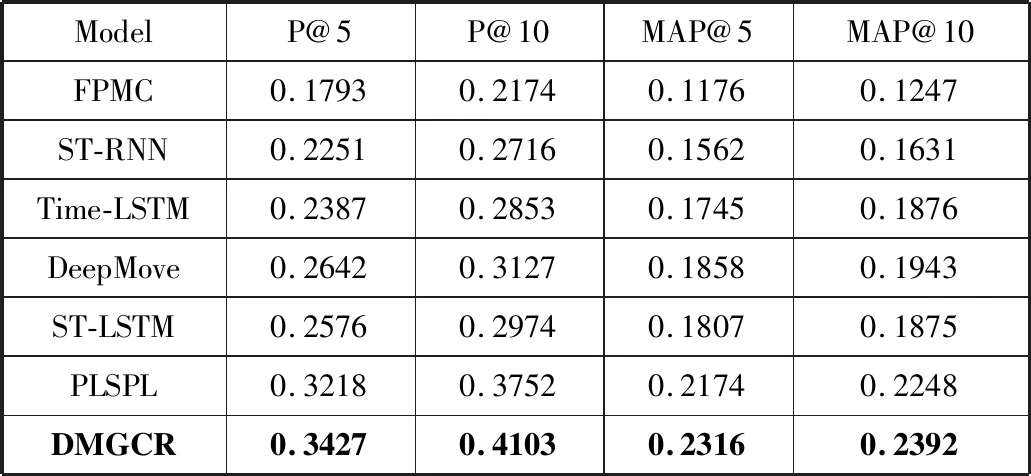
表3 Foursquare数据集上的性能比较
可以观察到:在2个数据集上,DMGCR模型的所有评估指标都优于相比较的方法。具体来说,对于Yelp数据集上的P@5,DMGCR方法几乎比DeepMove高3.9%,比ST-LSTM高13.4%,比PLSPL高5.9%。在Foursquare数据集上,DMGCR在所有指标下也高于其他方法。这表明本文模型可以更好地捕捉用户的长期和短期偏好,同时,也表明了考虑用户评论文本信息的有效性。
此外,ST-RNN由于采用了深度模型RNN,比使用马尔可夫链方法的FPMC模型在学习用户的顺序行为上表现更优。Time-LSTM模型是使用LSTM来建模连续输入之间的时间间隔,总体要比ST-RNN推荐效果更好。DeepMove在所有指标上都比FPMC、ST-RNN、Time-LSTM表现更好,这是因为DeepMove将LSTM模型应用于长期和短期偏好。此外,DeepMove利用注意力机制从历史轨迹中学习用户的长期偏好。PLSPL模型与DeepMove相比,综合考虑兴趣点位置和类别因素的影响,使用LSTM学习用户对位置和类别的偏好,从而在推荐准确度上有明显的提升。但与DMGCR模型相比,PLSPL模型忽略了用户的评论情感倾向信息,模型的推荐性能还不能达到更佳的效果。DMGCR模型综合考虑了用户长期和短期偏好,尤其在对用户短期偏好建模时,不仅考虑了位置信息和类别信息因素,还融合了用户的评论情感倾向信息,因此推荐准确率最高。与推荐效果较好的PLSPL方法相比,DMGCR模型平均提高了2.3%的准确率。以上数据说明,在兴趣点推荐中引入用户评论文本,能够有效提高推荐的效果。
3.5 影响因素分析
3.5.1 长期和短期模块的影响
为了验证结合长期和短期模块在模型中的有效性,本文研究了在Yelp和Foursquare数据集上P@5、P@10和P@20的性能,比较了以下3种情况:
1)仅考虑长期偏好学习模块;
2)仅考虑短期偏好学习模块;
3)同时考虑长期和短期偏好学习模块。
比较结果如图所示。
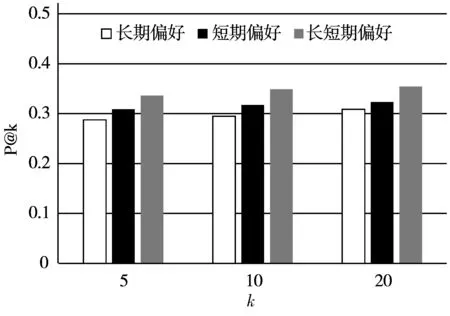
(a) Yelp数据集上受长短期偏好影响的P@k性能比较
图2可以观察到:短期偏好比长期偏好表现得更好。由于长期偏好反映了用户的固有特征,这些特征很难从本质上表现出来,而短期偏好可以通过最近行为的序列信息来学习[27]。此外,在所有评估指标下,长期和短期偏好学习模块的结合显示出比任何单个部分更好的性能。这表明结合用户的长期偏好和短期偏好对于更好地学习用户的签到行为至关重要。
3.5.2 融入评论信息的影响
为了验证融入用户评论信息在模型中的有效性,本文设计并对比了DMGCR模型的一个简化模型DMGCR-LC,它是一个只考虑位置偏好和类别偏好因素而没有考虑评论文本因素后构建的测试模型。比较结果如图3所示。

(a) 受评论影响P@k性能比较
从图3中可以观察到,DMGCR的推荐性能表现相比DMGCR-LC有了一定的提升,这是由于DMGCR模型使用BiLSTM有效提取了用户评论文本隐含的语义特征,捕获了用户对兴趣点的情感倾向信息,从一定程度上缓解了数据稀疏性问题。实验结果表明了结合评论信息、位置信息、类别信息等因素的推荐效果更好,进而验证了DMGCR模型能够更好地建模用户的下一步签到行为,有助于提高推荐的准确率。这与实际生活中人们的选择习惯相吻合,用户在选择自己感兴趣的地点时通常会考虑地点的评论情况,某地点的评论情感信息越积极用户越有可能选择该地点。
4 结束语
本文针对下一个兴趣点推荐问题,提出了一种结合动态多类信息的兴趣点推荐模型,称为DMGCR。该方法通过在长期模块中利用注意力机制捕捉不同兴趣点对用户的重要程度,刻画了用户的长期偏好;在短期模块中,将评论信息与位置信息和类别信息相结合,通过BiLSTM学习出评论文本隐含的语义特征,捕获了用户对兴趣点的情感倾向。最终结合长期偏好和短期偏好来计算用户下一步签到行为的概率。在真实数据集上的实验结果表明,该方法比其他基线方法表现更好。在未来的工作中,笔者将在模型中加入更多的上下文信息,如社交网络关系,以进一步提高下一个兴趣点的推荐性能。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
云南教育·小学教师(2022年4期)2022-05-17
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
艺术评论(2020年3期)2020-02-06
电子制作(2018年18期)2018-11-14
电子制作(2018年17期)2018-09-28
现代防御技术(2014年6期)2014-02-28
克拉玛依学刊(2013年5期)2013-03-11
