
基于图像翻转变换的对抗样本生成方法
2022-08-24 06:29杨博张恒巍李哲铭徐开勇
计算机应用 2022年8期
杨博,张恒巍*,李哲铭,2,徐开勇
(1.中国人民解放军战略支援部队信息工程大学,郑州 450001;2.中国人民解放军陆军参谋部,北京 100000)
0 引言
在图像识别领域,一些标准测试集上的实验结果表明深度神经网络的识别能力已经超过人类的水平[1-4]。然而,在深度学习带给人们巨大便利的同时,其本身也存在一些安全性问题。对于一个非正常的输入,深度神经网络是否依然能够得出满意的结果,其中隐含的安全问题也渐渐引起人们的关注。深度神经网络已经被证实容易受到对抗样本的攻击[5-6],它是通过在原始输入图像中添加人类不易察觉的附加扰动导致模型误分类而产生的。如图1 所示,尽管添加了扰动的“靛青鸟”图像(图(c))与原始的“靛青鸟”图像(图(a))在视觉上没有明显区别,即对抗扰动(图(b))非常小,但是深度神经网络还是将添加了扰动的“靛青鸟”图像(图(c))以98.9%的置信度错误分类为“大白鲨”。直观上来看,对抗扰动与随机噪声有一定的相似性,但两者却有着根本性区别。首先,对抗扰动是人为精心设计生成的,而不是随机生成的,能够用来误导神经网络;其次,相较于训练数据中的正常随机噪声,对抗扰动是在测试网络时添加的噪声,因此不参与网络训练;然后,对抗扰动十分微小,使得原始图像与对抗样本在视觉上没有明显差别,两者不易区分[7];此外,对抗样本具有一定的迁移性,即针对一个模型生成的对抗样本可能对另一个模型也是对抗的,这种现象使得黑盒攻击成为可能[8],更加凸显了其威胁性。因此,攻击性能强的对抗样本可以用于攻击测试神经网络模型,从而作为评估模型鲁棒性的重要工具,还可以作为对抗训练的输入改善模型的鲁棒性。

图1 原始图像、对抗扰动与对抗样本的示例Fig.1 Examples of original image,adversarial perturbation and adversarial example
虽然对抗样本具有可迁移性,但如何进一步提高其迁移性以进行有效的黑盒攻击仍然有待研究。一些基于梯度的攻击方法被提出以寻找对抗样本,例如单步攻击方法[6]和迭代攻击方法[9-10]。在白盒攻击场景下,这些方法表现出强大的攻击能力,然而在黑盒设置下,上述方法的攻击成功率却比较低。这被认为是对抗样本发生了“过拟合”,即同一对抗样本在白盒和黑盒设置下的攻击能力类似于同一神经网络在训练集与测试集上的表现差异。因此,将提高深度学习模型性能的方法用于对抗样本的生成过程中,以此减轻“过拟合”,从而提高对抗样本的可迁移性。已经有很多方法被提出以提升深度神经网络的性能[1-2,10-13],数据增强[1-2]就是其中之一。数据增强能够有效防止深度神经网络训练过程中的过拟合,提升模型的泛化能力。
本文从数据增强的角度出发,优化对抗样本的生成过程,提出了基于图像翻转变换的生成方法以提高对抗样本的可迁移性。
本文的主要工作如下:
1)受数据增强[1-2]的启发,将图像翻转变换引入对抗攻击中,通过对输入图像进行随机翻转变换,从而有效地减轻对抗样本生成过程中的过拟合,提升对抗样本的可迁移性。
2)通过调整相关的参数,本文方法可以与现有的基于梯度的对抗样本生成方法进行关联和变换,充分体现了本文方法的优势和便利性。
3)在ImageNet 数据集[14]上的大量实验结果表明,与现有的传统攻击方法[9-10]相比,本文提出的图像翻转变换攻击方法有着更好的攻击性能,实现了黑盒攻击成功率的较大提升,提升了对抗样本的迁移性。因此,本文所提出的攻击方法有助于评估不同模型的鲁棒性。
1 相关工作
1.1 对抗样本生成方法
Biggio 等[15]首次基于MNIST(Modified National Institute of Standards and Technology)数据集[16]针对传统的机器学习分类器进行了“逃避攻击”,即让模型分类错误,说明传统的机器学习算法容易受到对抗样本的攻击。Szegedy 等[5]在研究中发现了深度神经网络的有趣特性,即深度神经网络面对对抗样本的攻击是非常脆弱的,并提出了基于优化的LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)方法生成对抗样本。Goodfellow 等[6]提出了仅执行一个梯度步长就能生成对抗样本的快速梯度符号法(Fast Gradient Sign Method,FGSM),该方法降低了生成对抗样本的计算成本。Kurakin 等[9]将FGSM 方法扩展为多步迭代版本I-FGSM(Iterative FGSM),大幅提高了白盒攻击成功率,并且证明了对抗样本也可能存在于物理世界中。Dong 等[10]提出了MIFGSM(Momentum I-FGSM),以此稳定梯度更新方向,优化收敛过程,提高对抗样本的迁移性。相关研究人员还证明了物理世界中也可能存在对抗样本[9,17],而不仅仅存在于数字模型中,这给深度神经网络的实际应用带来了安全威胁。
1.2 对抗样本防御方法
面对对抗样本的威胁,大量关于对抗样本防御的方法被提出以保护深度学习模型[18-21]。对抗训练[6,22-23]是其中很重要的一种防御方法,它将对抗样本引入到训练数据中参与模型训练,提高了模型的鲁棒性。Liao 等[19]提出了高级表示引导去噪器来净化对抗样本,以此消除对抗样本的影响。Guo等[20]发现存在一系列图像变换,它们有可能在保持图像关键视觉内容的同时消除对抗扰动。Samangouei 等[21]利用生成模型将对抗样本移回到原始干净图像的分布来净化对抗样本,降低对抗样本的影响。Tramèr 等[23]提出了集成对抗训练,该方法利用针对其他模型生成的对抗样本来增加训练数据,进一步提高了模型的鲁棒性,由该方法训练的模型也成为了评价对抗样本攻击能力的标准模型。
2 FT-MI-FGSM方法
令x和y分别为原始输入图像和对应的真实标签,θ是模型的参数。J(θ,x,y)是神经网络的损失函数,通常是交叉熵损失函数。对抗样本生成的目标是通过最大化J(θ,x,y)来生成一个与x视觉上不可区分的对抗样本xadv来愚弄模型,即让模型对对抗样本xadv进行错误分类。在本文中,使用无穷范数对对抗扰动进行了限制,即‖ ‖xadv-x∞≤ε。因此对抗样本生成可转化为以下条件约束优化问题:

2.1 基于梯度的生成方法
由于本文方法是在基于梯度的生成方法基础上改进而来的,故在本节中,首先简要介绍生成对抗样本的几种梯度方法。
FGSM(Fast Gradient Sign Method)[6]是最简单的对抗样本生成方法之一,其在损失函数关于输入的梯度方向上寻找对抗样本,并对对抗扰动予以无穷范数限制。更新公式如下:
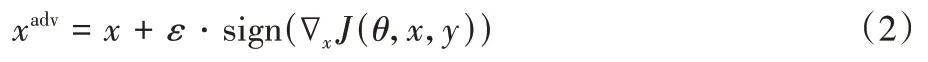
I-FGSM[9]是FGSM 的迭代版本,它将FGSM 中的梯度运算分成多步迭代进行,以此减轻单步攻击带来的“欠拟合”。该方法可表示为:
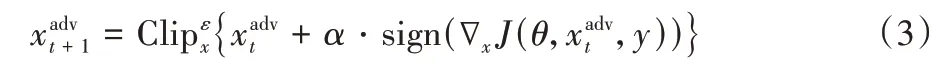
其中:α是每次迭代的步长,α=ε/T,T为迭代次数;Clip 函数的作用是将对抗样本约束在原始图像x的ε邻域内,以满足无穷范数约束。
MI-FGSM[10]首次提出将动量运用到对抗样本生成过程中,动量项能够稳定梯度更新方向,改进了收敛过程,从而大幅度提高了攻击成功率。与I-FGSM 相比,MI-FGSM 的不同在于对抗样本的更新方向不一样:

其中:μ是动量项的衰减因子;gt是前t轮迭代的梯度加权累积。
PGD(Projected Gradient Descent)[17]是对FGSM 的改进,是FGSM 的强迭代版本,它提高了对抗样本的攻击成功率。
2.2 图像翻转变换生成方法
数据增强[1-2]被证明是在深度神经网络训练过程中防止网络过拟合的一种有效方法。基于此,本文提出了图像翻转变换攻击方法,其总体思路如图2 所示。
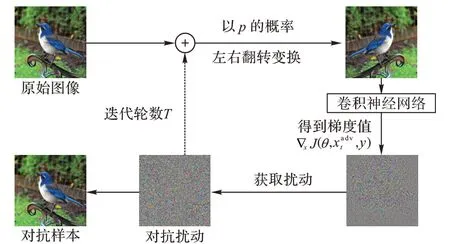
图2 图像翻转变换生成方法框架Fig.2 Framework of image flipping transformation generation method
该方法在每次迭代时对原始输入图像以p的概率进行随机翻转变换,以缓解过拟合现象。该方法对随机翻转变换的图像的对抗扰动进行优化:

图像变换函数FT(·)是图像翻转的调整,它将输入图像进行左右翻转,转换概率p控制着原始输入图像和变换图像之间的平衡。采用这种方法,可以通过数据增强来实现对模型的有效攻击,从而避免白盒模型的“过度拟合”攻击,提高对抗样本的可迁移性。
2.3 图像翻转变换生成算法描述
针对对抗样本的生成过程,FT-MI-FGSM 引入了数据增强,缓解了过拟合现象,提升了对抗样本的可迁移性。此外,FT-MI-FGSM 可通过不同的参数设置与FGSM 类方法进行关联,例如转换概率p=0,则FT-MI-FGSM 退化为MI-FGSM,即去掉算法1 的第4)步就可以得到MI-FGSM 攻击算法,这体现了本文方法的优势与算法便利性。图3 对不同的对抗样本生成算法之间的关系进行了展示。算法1~2 对单模型和集成模型下的FT-MI-FGSM 生成算法进行了总结。

图3 不同对抗样本生成算法关系Fig.3 Relationship between different adversarial example generation algorithms
算法1 FT-MI-FGSM(单个模型)。
输入原始干净图像x以及对应的分类标签y;神经网络f和损失函数J;扰动大小ε;迭代轮数T和衰减因子μ。
输出对抗样本xadv。

算法2 FT-MI-FGSM(集成模型)。
输入原始干净图像x以及对应的分类标签y;K个深度神经网络f(f1,f2,…,fK),对应的网络逻辑值l(l1,l2,…,lK)以及相应的网络集成权重ω(ω1,ω2,…,ωK);扰动大小ε;迭代轮数T和衰减因子μ。
输出对抗样本xadv。

3 实验与结果分析
3.1 实验设置
如果原始图像不能被网络正确分类,那么基于这些图像生成对抗样本则没什么意义。因此,本文从ImageNet 验证集中随机选择1 000 张属于1 000 个类别的图像(即一个类别选取一张图像),这些图像都能够被测试的网络正确分类。所有图像都事先调整为299 × 299 × 3。
在实验中,对于超参数,本文遵循文献[10]中的设置,扰动为ε=16,迭代次数T=10,步长α=1.6。对于MIFGSM,衰减系数默认为μ=1.0。对于随机变换函数FT(xadv;p),转换概率p=0.5。为了对随机翻转变换有直观的认识,图4 对随机翻转变换后的部分图像进行了展示。

图4 原始图像、变换后图像以及对应生成的对抗样本Fig.4 Original images,transformed images and the corresponding generated adversarial examples
在实验中一共研究了7 个网络,其中包括4 个正常训练的网络,即Inception-v3(Inc-v3)[24]、Inception-v4(Inc-v4)[25]、Inception-Resnet-v2(IncRes-v2)[25]和 Resnet-v2-101(Res-101)[26],以及3 个经过对抗训练的网络[23],即Inc-v3ens3、Incv3ens4和IncRes-v2ens。
3.2 单个网络攻击
首先对单个网络进行了攻击。使用I-FGSM,MI-FGSM以及FT-MI-FGSM 方法在正常训练的网络上(Inc-v3、Inc-v4、IncRes-v2、Res-101)生成对抗样本,并在所有7 个网络(4 个正常训练网络,3 个对抗训练网络,)上测试它们。实验结果展示在表1 中,其中成功率是指以对抗样本作为输入的模型分类错误率,即成功率等于攻击成功的对抗样本数量除以总的对抗样本数量,这里攻击成功的对抗样本数量也就是模型错误分类的对抗样本数量。图4 对在Inc-v3 单模型上生成的对抗样本进行了展示,从图4 可以看出,原始图像和对应生成的对抗样本之间的差别很小,即对抗扰动对于人眼几乎是不可见的。
表1 中的结果表明,FT-MI-FGSM 在黑盒设置下的攻击成功率远远高于其他攻击方法,并且在所有白盒模型上都保持较高的成功率。例如,在Inc-v3 网络上生成对抗样本并攻击Inc-v4 网络时,FT-MI-FGSM 黑盒攻击的成功率达到65.2%,在这些方法中最高。此外,FT-MI-FGSM 在对抗训练网络上的性能也更好。与其他3 种攻击方法相比,FT-MIFGSM 大幅提高了黑盒攻击的成功率。例如,在IncRes-v2 网络上生成对抗样本来攻击对抗训练网络时,FT-MI-FGSM 和MI-FGSM 的平均攻击成功率分别为26.0%和19.9%。这充分说明了将随机翻转变换引入到对抗样本的生成过程中对提高对抗样本迁移性的重要性。

表1 攻击单模型的成功率比较 单位:%Tab.1 Success rate comparison of single model attack unit:%
3.3 集成网络攻击
尽管表1 的实验结果表明,FT-MI-FGSM 能够提升对抗样本的迁移性,但还能够通过攻击集成模型进一步提高黑盒攻击成功率。本文遵循文献[10]中提出的策略,即对多个网络逻辑值的集成进行攻击。本实验考虑了3.1 节中提到的7个网络,分别运用I-FGSM、MI-FGSM 和FT-MI-FGSM 针对4 个正常训练网络的集成来生成对抗样本,并在7 个网络上测试。在实验中,迭代轮数T=10,扰动大小ε=16,每个网络的集成权重相等,即ωk=14。
实验结果如表2 所示,这表明在黑盒设置下,FT-MIFGSM 相较于其他对比方法具有更高的攻击成功率。例如,FT-MI-FGSM 攻击Inc-v3ens3的成功率为48.2%,而I-FGSM 和MI-FGSM 的成功率分别为18.8%和38.5%。在具有挑战性的对抗训练的网络上,FT-MI-FGSM 对黑盒攻击的平均成功率为40.7%,比I-FGSM 和MI-FGSM 分别高出26.0 和8.4 个百分点。这些结果表明了该方法的有效性和优越性。

表2 攻击集成模型的成功率比较 单位:%Tab.2 Success rate comparison of attacking ensemble models unit:%
3.4 超参数研究
在本节中,进行了一系列拓展实验进行超参数研究。首先,研究转换概率p对FT-MI-FGSM 攻击成功率的影响。本实验考虑攻击集成模型,即FT-MI-FGSM 针对4 个正常训练网络的集成模型生成对抗样本,并在7 个网络上测试,以此来更准确地评估转换概率p对攻击成功率的影响。通用的实验设置如下:最大扰动ε=16,迭代次数T=10,步长α=1.6,动量项衰减系数μ=1.0。本实验研究的转换概率p则从0 以0.1 的步长增长到1。当p=0 时,FT-MI-FGSM 退化为MI-FGSM。图5 展示了FT-MI-FGSM 在不同转换概率下的攻击成功率,其中实线表示的是在正常训练网络上的白盒攻击成功率,虚线表示的是在对抗训练网络上的黑盒攻击成功率。从图5 可以观察到:随着转换概率p的增大,FT-MIFGSM 上的白盒和黑盒攻击成功率变化趋势是不一样的。对于FT-MI-FGSM,随着p的增加,黑盒攻击成功率先逐渐升高到达峰值后再逐渐降低,而白盒攻击成功率总体呈降低的趋势。此外,对于FT-MI-FGSM,如果p较小,即仅利用少量随机转换输入,对抗训练网络上的黑盒成功率会显著提高,而白盒成功率只会略有波动。这种现象表明将随机转换后的输入添加到对抗样本生成过程中的重要性。特别是,还可以通过控制p的取值实现黑盒攻击成功率和白盒攻击成功率之间的平衡。本文综合考虑白盒和黑盒攻击成功率的重要性,无论是攻击单个网络还是集成网络,FT-MI-FGSM 中的转换概率p均取0.5。

图5 不同网络上转换概率与攻击成功率的关系Fig.5 Relationship between transformation probability and attack success rate in different networks
其次,研究扰动大小ε对黑盒攻击成功率的影响。本实验考虑攻击集成模型,即I-FGSM、MI-FGSM 和FT-MI-FGSM针对4 个正常训练网络的集成模型生成对抗样本,并在3 个对抗训练网络上测试。通用的实验设置如下:迭代次数T=10,动量项衰减系数μ=1.0。本实验研究的扰动大小ε则从1 以3 的步长增长到22。图6 展示了不同扰动大小下I-FGSM、MI-FGSM 和FT-MI-FGSM 在Inc-v3ens3、Inc-v3ens4和IncRes-v2ens上的攻击成功率。从图6 可以看出尽管随着扰动大小ε的逐渐增大,3 种方法在不同模型上的攻击成功率都逐渐增大,但是本文所提的FT-MI-FGSM 方法的攻击成功率总是最高的,实验结果说明了FT-MI-FGSM 的优越性。

图6 对抗训练网络上扰动大小与攻击成功率的关系Fig.6 Relationship between perturbation and attack success rate in adversarially trained networks
最后,研究迭代次数T对黑盒攻击成功率的影响。本实验考虑攻击集成模型,即I-FGSM、MI-FGSM、FT-MI-FGSM 针对4 个正常训练网络的集成模型生成对抗样本,并在3 个对抗训练网络上进行测试。通用的实验设置如下:扰动大小ε=16,动量项衰减系数μ=1.0。本实验研究的迭代次数T从2 以2 的步长增长到16。图7 展示了不同迭代次数下I-FGSM、MI-FGSM 和FT-MI-FGSM 在Inc-v3ens3、Inc-v3ens4和IncRes-v2ens上的攻击成功率。从图7 中可以看出:随着迭代次数T的逐渐增大,3 种方法在不同模型上的攻击成功率呈现的变化趋势是不一样的,其中I-FGSM 对应的曲线呈现降低的趋势,而MI-FGSM 和FT-MI-FGSM 所对应的曲线则是先增大然后缓慢下降的趋势,拐点大致在迭代次数取8~12。另外,从图7 还可以看出:无论迭代次数取何值时,FT-MIFGSM 方法的攻击成功率几乎总是最高的,这表明了FT-MIFGSM 的有效性。

图7 对抗训练网络上迭代次数与攻击成功率的关系Fig.7 Relationship between iteration number and attack success rate in adversarially trained networks
3.5 进一步研究
前面部分已经在ImageNet 数据集上对本文所提的FTMI-FGSM 进行了有效验证。本节在MNIST 和CIFAR 10(Canadian Institute For Advanced Research 10)[27]两个数据集上进行了拓展实验进一步验证FT-MI-FGSM 的有效性。相关实验设置和模型选取参照文献[28],在MNIST 和CIFAR10数据集的实验中,扰动大小ε=1255,迭代次数T=10,动量项衰减系数μ=1.0,转换概率p=0.5。实验结果如表3所示。从表3 可以看出:无论是在MNIST 还是CIFAR10 数据集上,FT-MI-FGSM 都有着最高的攻击成功率,以在CIFAR10上的实验为例,采用FT-MI-FGSM 在模型VGG16(Visual Geometry Group 16)[2]上生成对抗样本,然后攻击模型ResNet50[4],即在模型ResNet50 上进行检验,所得的攻击成功率为42.3%,而I-FGSM 和MI-FGSM 的攻击成功率分别为40.5%和40.7%,这凸显了FT-MI-FGSM 的优越性。

表3 MNIST和CIFAR10数据集上的黑盒攻击成功率比较 单位:%Tab.3 Black-box attack success rate comparison on MNIST and CIFAR10 datasets unit:%
4 结语
本文提出了一种基于图像翻转变换的对抗样本生成方法FT-MI-FGSM,该方法在对抗样本生成过程的每次迭代中对输入图像进行随机翻转变换,以缓解过拟合现象,从而生成更具迁移性的对抗样本。与传统的FGSM 类方法相比,在ImageNet 数据集上的实验结果表明,本文方法在黑盒设置下的攻击成功率有了大幅提高。此外,通过使用攻击集成模型的方法,进一步提高了对抗样本的迁移性,实验结果表明,与原有方法I-FGSM 相比,FT-MI-FGSM 在对抗训练网络上的平均黑盒攻击成功率提升了26.0 个百分点。FT-MI-FGSM 的工作表明,其他数据增强的方法也可能有助于构建强攻击,这是未来可以探索和研究的方向之一,关键是如何找到有效应用于迭代攻击的数据增强方法。
猜你喜欢
天天爱科学(2022年9期)2022-09-15
上海师范大学学报·自然科学版(2022年3期)2022-07-11
当代水产(2022年6期)2022-06-29
中国药学药品知识仓库(2022年10期)2022-05-29
北京航空航天大学学报(2021年7期)2021-08-13
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
水上消防(2020年4期)2021-01-04
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
湖南师范大学学报·自然科学版(2014年5期)2014-11-14
