
分层教学中决策树归纳分类及应用
2022-08-24 09:48刘杨
淮北职业技术学院学报 2022年4期
刘 杨
(安徽水利水电职业技术学院 质量管理办公室,安徽 合肥 231603)
0 引言
正如不能用一把尺子去衡量万物,也不能用一个标准去衡量每一个学生。由于学生家庭因素、成长经历、个人努力程度的不同,他们在知识现状、知识学习能力、思维品质、思维能力等方面都会存在或多或少的差异。近年来,人们对个人在教育中的主体地位和个性在人的发展中的影响逐渐重视,这使班级授课制统一进度与个体差异之间的矛盾日益突出,如何做到因材施教、关注学生的个性差异成为教学发展的应然诉求,实施分层教学是解决这一问题的有效方案。
分层教学模式承认学生差异,注重因材施教和个性化培养,是我国教育教学研究中的热点之一。[1]分层教学是指根据教学内容,综合考虑学习者生理、心理特点及学习能力,尊重学习者存在的差异性,将水平相近的学生分为一组,便于采用个性化和具有针对性的教学方法,提升学生整体水平。尽管这种教学策略的有效性得到了广泛认可,但其有效性建立在对学生合理分组上,这一问题一直是制约分层教学大规模推广的阻碍之一。
传统的分层策略通常由一组教师团队或教学规划团队基于教学实施经验分析得出,但这种分组方式受团队自身环境的主观性影响较大,这使得对分层规划人员的要求相对较高。不具备较多教学经验的规划人员往往会引入不合理的分层设计。此外,在需要规划的学生规模较大或者教学环境发生较大变化时,传统的分层经验的可靠性会受到一定程度的损失,并会耗费较多的分析时间。
那么,如何科学合理地对学习者进行层次划分则成为分层教学的关键问题。分层教学的层次划分涉及学习者的学习情况、心理素质、情谊特征、认知风格和性格倾向等,需要的信息数量巨大,形式多样,采用先进的科学手段才能快速有效地实现分析过程。数据挖掘可使用户从海量数据中获取需要和感兴趣信息,含有多种分类方法,决策树归纳是其中的一种。[2]决策树归纳分类所需的训练数据少,便于理解和解释,可视性强,分类规则形成简便。故将决策树归纳应用于分层教学研究中,可以为分层教学的层次划分提供科学的指导和理论依据。本文就决策树归纳技术进行研究,分析其在分层教学中的应用。
1 决策树归纳分类
分类是根据已知类别的数据集构建分类模型,然后,对未知类别数据进行分类的过程。大量的数据对象构成一个数据集,每一个数据对象都具有多个属性。在分层教学中,每个学生就是一个数据对象,他们的姓名、学号、年级、专业、获得的学分、专业排名、奖惩情况、心理健康、性格特点等就是属性。所谓分类就是要给数据对象赋予一个类标号。分类一般分两步完成,如图1所示。第一步,建立一个模型,通过对已有类标号的数据集(也称为“训练集”)进行学习,构建分类器;第二步,利用分类器,对未分类的数据(也称为“测试集”)分类。分类的核心就在于使用某种算法,通过大量的训练集,构造出分类器。之后,通过分类器,对新的未分类的数据做分类。

图1 数据分类过程
决策树是树形结构的分类模型,如图2所示,由根节点、中间节点、树叶节点和分枝组成。根节点和中间节点代表一个属性,根据属性节点可以对数据对象进行划分,每一个划分就是一个分枝,叶节点则代表一个类别。
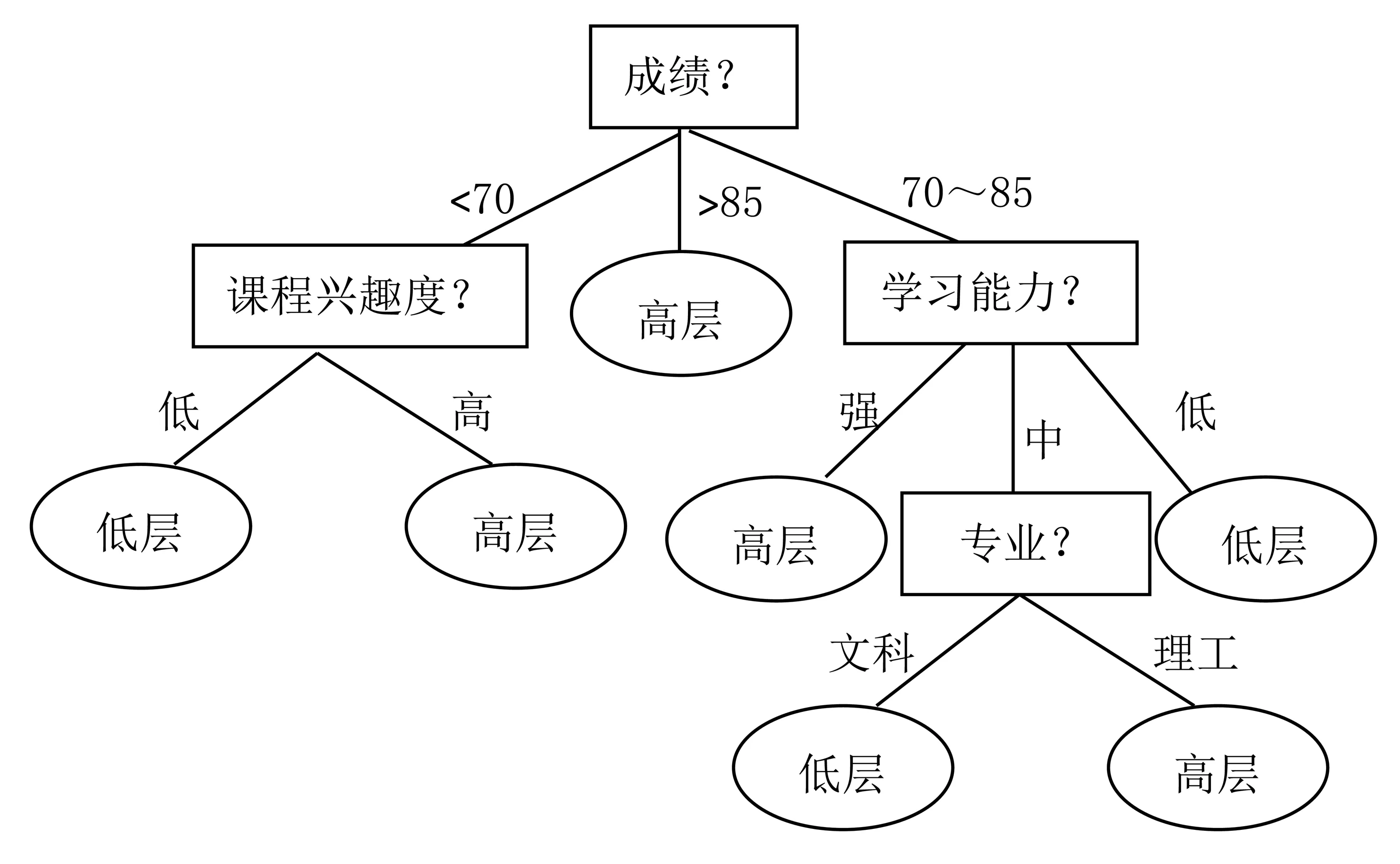
图2 决策树结构
决策树的构建采用自顶向下递归算法。[3]树节点从根节点开始,采用基于熵的信息增益来对数据对象的每一个属性进行度量,从而选择出能够进行最好分类的属性作为节点,对数据对象进行划分,创建分枝,然后,根据剩余属性的信息增益再次选择节点,依次往下,直到分枝下的数据对象都在同一类,则标记类标号,是为树叶节点。
设数据样本有s个,构成集合S,可以分成m个类别,记为Ci(i=1,2,…,m)。设Ci类中数据样本有si个,则对该样本分类所需的期望信息为:
(1)
其中:pi是概率,表示样本属于类Ci的概率,用si/s表示。
假设属性A具有v个不同值{a1,a2,…,av},将数据样本集划分为v个子集{S1,S2,…,Sv}。设sij是子集sj中类Ci的样本数,则由属性A划分子集的信息熵为:
(2)
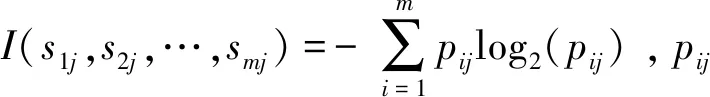
则属性A的信息增益是:
Gain(A)=I(s1,s2,…,sm)-E(A)
(3)
信息增益最大的属性可作为决策树根节点的测试属性。
2 决策树归纳分类应用举例
以某高校思想政治类课程分层教学[4]为例,说明决策树归纳分类方法的应用。判定树算法的基本策略如下:
步骤一:树以代表训练样本的单个节点开始;
步骤二:如果所有样本都在同一个类,则该节点成为树叶,并用该类标记;
步骤三:如果所有样本不都在同一个类,则基于信息增益选择能够最好地将样本分类的属性,该属性成为该节点的测试属性;
步骤四:对测试属性的每个已知的值,创建一个分枝,并据此划分样本;
步骤五:使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个节点上,就不必考虑该节点的任何后代上。
当下列条件有一条成立时,以上的递归划分步骤停止:
(1)给定节点的所有样本属于同一类;
(2)没有剩余属性可以用来进一步划分样本,用样本集中的多数所在的类标记它;
(3)分枝中没有样本,以训练样本中的多数类创建一个树叶。
表1给出了学生数据训练集,类标号有两个值:高层用C1表示;底层用C2表示。C1类有9个样本,C2类有5个样本。训练样本集用于生成决策树,训练样本量不能少于10,决策树多生长一层,对训练样本量的需求会增加一倍。如果往届教学已有过分层教学,则可以从往届分好层的学生集中选取具有代表性的学生样本,由于其测试属性和类标号都是已知的,直接即可作为训练样本集。如果没有进行过分层教学,缺少现成分好类的学生样本,则需要授课教师构建出训练样本集。授课教师需要选取部分学生样本,根据学生的实际情况,再结合自身的经验,对选取的学生样本进行类标号的赋值。学习能力和课程兴趣度则可以根据学习专注力、学习成就感、自信心、思维灵活度、独立性和反思力、课堂表现、课堂参与度等进行度量。初次构建出的训练样本集可能会出现数量较少、部分学生分类不合理等问题,但这些问题通过大量测试样本的测试和学习是可以得到纠正的。
首先,计算该样本分类所需的期望信息如下:
=0.940

表1 某高校学生数据训练样本集
其次,计算每个属性划分样本的信息增益。以成绩为例,计算过程如下:
对于成绩=“<70”:s11=2,s21=3,I(s11,s21)=0.971
对于成绩=“70~85”:s12=3,s22=2,I(s12,s22)=0.971
对于成绩=“>85”:s13=4,s23=0,I(s13,s23)=0
根据公式(2),按照成绩划分子集的熵信息为:
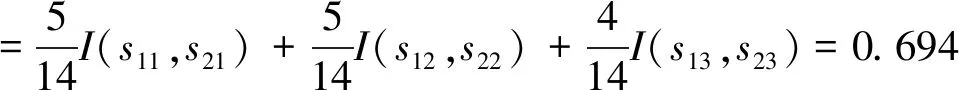
根据公式(3),属性成绩的信息增益是:
Gain(成绩)=I(s1,s2)-E(成绩)=0.246
按照上述同样的过程,依次可以计算出其他属性的信息增益,为Gain(学习能力)=0.048,Gain(课程兴趣度)=0.151和Gain(专业)=0.021。由此,属性成绩具有最高的信息增益,被选为测试属性,作为根节点,并对每一个属性值,引出分枝,样本集据此进行划分。其中:落在成绩=“>85”的样本为同一类,该分枝的端点创建一个叶节点,用高层表示。在分枝成绩=“<70”和成绩=“70~85”内,重复上述过程,再次计算剩余属性的信息增益,直到所有的划分都属于同一类为止。最终形成的决策树如图2所示。
沿着决策树的根节点到叶节点的路径,可以得到IF—THEN分类规则,例如:
分类规则1:IF成绩=“>85”,
THEN学生类别=“高层”
分类规则2:IF成绩=“70~85”AND学习能力=“强”
THEN 学生类别=“高层”
分类规则3:IF成绩=“<70”AND课程兴趣度=“弱”
THEN 学生类别=“低层”
例如:有一测试样本,数据为:成绩为“80”,学习能力“强”, 课程兴趣度“高”,专业“理科”,则根据分类规则2,可以将其分类为=“高层”。这样根据决策树提取的分类规则,就可以对思想政治类学生进行分层划分。当判定树创建时,由于训练样本集可能存在错误分类或者奇异点数据等问题,树结构的分枝反映的异常数据,导致在分类过程中,出现不符合分类规则的数据,此时,可以对决策树采用剪枝处理,重新对决策树进行修正。因此,基于决策树归纳分类进行分层具有有效性和可行性。
3 结语
决策树归纳是数据挖掘中的一种非常有效的分类方法。初始只需要较少数量的训练样本即可生成决策树;然后,基于决策树,归纳提取出IF-THEN分类规则;基于分类规则,则可以对测试样本进行分类。在分类过程中,还可以对决策树进行剪枝、加强等修正工作,使决策树归纳分类越来越科学,越来越合理,越来越符合实际情况。将决策树归纳用于某高校思想政治类课程分层教学中,详细说明了训练样本集的构建、决策树的生成和分类规则的提取,因此,基于决策树归纳分类进行分层具有有效性和可行性,为分层教学提供了新的思路和途径。
教育教学中,没有哪一种教学方法和教学模式最好,只有根据学生实际情况,采用具有针对性的教学方法,才能调动学生学习的积极性和主动性,取得好的教学效果。分层教学能够针对学生个体差异,寻求最合理的教学形式和方法,实现教学效果的最优化。[5]采用决策树归纳分类方法可以综合考虑学生的各个方面,科学地将学生进行分层,让学有余力的学生接受更多更大挑战,同时,也不要破坏稍微落后学生的自信心和意志力,尽可能做到宋代著名教育家朱熹在《四书集注》中所说的“圣贤施教,各因其材。小以小成,大以大成,无弃人也”[6]。
猜你喜欢
军事文摘(2020年18期)2020-10-27
科技创新与应用(2020年6期)2020-02-29
成都信息工程大学学报(2019年3期)2019-09-25
动漫星空(兴趣百科)(2018年4期)2018-10-26
电子制作(2018年16期)2018-09-26
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
中央民族大学学报(自然科学版)(2016年4期)2016-06-27

- 淮北职业技术学院学报的其它文章
- 郑漯高速公路漯河复合式立交设计方案的比选