
智能情报分析中数据与算法风险识别模型构建研究
2022-08-31 15:35马海群
情报学报 2022年8期
张 涛,马海群
(1. 黑龙江大学信息管理学院,哈尔滨 150080;2. 黑龙江大学信息资源管理研究中心,哈尔滨 150080)
1 引 言
随着大数据、人工智能等技术深入发展,想充分发挥新时代国家情报工作的“先导”“引领”“耳目、尖兵、参谋”作用,就要使情报工作适应当前社会整体环境。情报工作在党和国家事业取得历史性成就过程中发挥了重要作用,作为服务于国家安全与发展的情报工作有了新的历史使命。在情报工作的众多环节中,情报分析处于核心地位,它是决策的前提与基础,高质量的情报分析是情报工作成果的体现,是衡量情报工作质量的重要标准。随着海量多源异构数据急剧增加,人工智能凭借其强大的数据分析优势,极大提升了数据收集、分析及生产新数据的能力,从而使情报分析上升到“高端智库”模式的情报服务、战略性服务层面,情报人员在复杂多变的决策环境中对海量、异构、多模的数据进行分析时,智能算法发挥了重要作用,它不但能大幅度提升情报分析的全面性与准确性,还能在短时间内为用户提供高水平、有价值的分析结果。虽然它可以辅助用户完成智能化的分析过程,提升情报分析效率,但数据与算法是一把双刃剑,在为管理决策带来便利的同时,会引发数据投毒、数据泄露、算法缺陷、算法操控等一系列安全风险,这也逐渐成为限制情报工作发展的主要因素之一[1]。党的十九届五中全会和六中全会公报中都对防范化解重大安全风险提出明确要求,可见国家对风险识别与防范的重视程度。当前数据与算法风险正是大数据与人工智能时代情报分析所特有的,我国在该领域研究相对薄弱。从制度层面看,并没有形成风险识别机制,尤其是在情报工作领域,若不及时防范与化解数据与算法风险,不仅会导致情报分析失准,甚至还会给社会稳定乃至国家安全造成灾难级影响。因此,进一步加强对情报分析中数据与算法风险前瞻识别、预防与治理的研究符合总体国家安全发展战略目标。早在2018 年,中国首个人工智能深度学习算法标准《人工智能深度学习算法评估规范》在中国人工智能开源软件发展联盟成立大会上正式发布;2019 年,中国信息通信研究院安全研究所发布《人工智能数据安全白皮书(2019 年)》;2021 年9 月,国家互联网信息办公室、中央宣传部等九部委印发《关于加强互联网信息服务算法综合治理的指导意见》;2021 年11 月,中共中央政治局召开会议审议《国家安全战略(2021—2025 年)》时提出,统筹做好新型领域安全,加快提升网络安全、数据安全、人工智能安全等领域的治理能力;2022 年3 月《互联网信息服务算法推荐管理规定》正式实施,国家在强化数据与算法安全风险事件防范的同时,不断通过法规制度完善数据与安全风险的顶层设计;2021 年12 月全国金融标准化技术委员会发布《金融数据安全数据安全评估规范(征求意见稿)》,该标准为第三方安全评估机构等单位开展金融数据安全检查与评估工作提供了参考。由此可见各领域也逐渐开始建立完善具有领域特色的数据与算法安全风险防范措施。
国内外学者围绕智能情报分析、数据与算法风险等主题展开了卓有成效的研究。第一,智能情报分析。智能情报理念源于1993 年钱学森先生提出的人机结合是智慧式情报的关键[2]。2015 年王飞跃[3]基于钱学森先生的智能情报理念提出平行智能情报,此后学界在人工智能与情报工作相结合方面形成了一系列理论层面及应用层面的研究成果。理论研究是智能情报分析的基础,如计算情报研究[4-6]、数据智能情报研究[7-9]、智能情报分析系统[10-11]、智能与情报融合研究[12-14]等,这些研究奠定了智能情报分析的理论基础。应用研究是智能情报分析的目标,近年来,很多学者将人工智能技术与不同领域情报工作相结合形成了一系列应用研究成果,如反恐情报[15]、金融情报[16]、军事情报[17]、安全情报[18]、竞争情报[19]、应急情报[20],这些研究成果使智能情报分析项目得以推广应用,并逐渐得到认可,其中中国科学院文献情报中心成立智能情报重点实验室是理论与应用研究相结合的重要支撑。第二,数据与算法风险。数据风险方面,国内学者从治理[21]、问题[22]、体系[23]、路径[24]、机制[25]等视角对数据安全风险进行研究;国外学者从模型[26]、标准[27]、维度[28]、成熟度模型[29]等视角进行数据风险治理研究。算法风险方面,国内学者从算法治理[30]、法律规制[31]、法律问责[32]、算法权力[33-34]等视角对算法风险进行深入研究;国外学者从法律决策责任[35-36]、伦理责任[37]、协同治理[38]等视角对算法风险治理进行研究。
从已有研究成果可见,智能情报分析理论与应用已经得到了学界的广泛关注,并且从责任、监管、治理等视角对数据与算法风险进行了较为充分的研究,但是针对智能情报分析领域风险识别的研究成果较少,尤其缺少对数据与算法风险识别模型构建与实证层面的研究。因此,本文以实现防范与化解情报分析中数据与算法带来的安全风险为目标,重在讨论智能情报分析领域数据与算法风险问题,基于风险社会理论[39]、监管沙盒理论[40]构建“数据-算法-流程”为一体的智能情报分析风险识别模型,通过实际智能情报分析项目验证模型的有效性,最终形成凸显情报特色、突出情报领域话语权、具有实践推广意义的创新性成果。
2 模型构建
技术不断进步所引发的不确定性、冲突、对抗和分歧导致社会各领域发展与风险叠加共生,我国社会转型呈现时空高度压缩的跨越式特征,人工智能技术应用于情报分析项目中恰恰符合贝克风险社会理论中所提到的复杂交互性、突出人为性、不确定性等特征[39]。《ISO 31000: 2018 风险管理指南》将识别方法、识别模型作为风险识别的核心要素[41]。因此,本文将识别方法和识别模型作为主要研究对象,以有效识别智能情报分析中数据与算法所导致的失实风险、决策风险、偏见风险、隐私风险等[42]。
2.1 识别方法
沙盒测试是在监管沙盒理论基础上形成的数据与算法风险识别方法,所谓的沙盒测试就是在项目上线前在内部环境下进行的测试,此时在正常线上环境是无法看到或查询到该项目的,只有项目通过测试上传到生产环境之后,用户才能使用该功能[43]。人工智能视域下情报分析涉及领域较广,不同于以往在某一空间范围内进行试点的方式,沙盒测试突破空间范围的限制,强调对智能情报分析项目的风险预警,测试机构通过参与智能情报分析项目的全过程,对数据与算法的风险点进行识别,并提出最优建议,同时,参与沙盒测试的项目在申请、测试、形成报告等方面都有详细的规定,这有助于将智能情报分析项目中数据与算法风险控制在一定范围内,并最大限度上保障情报分析的安全性。沙盒测试分为单向识别和双向识别两种模式:单项识别是基于数据描述与算法描述实现的,而双向识别是基于流程的数据与算法风险识别的,尤其是数据与算法相融合后,通过对项目流程的测试形成双向驱动,并相互识别存在的风险。
2.2 识别模型
智能情报分析中数据与算法是核心要素,对其风险识别是有效提升情报分析准确性的重要环节。常见的数据风险主要包括数据越界、数据质量、数据泄露、数据投毒、数据隐私等[44]。常见算法风险主要包括算法缺陷、算法偏见、算法歧视、算法操控、算法黑箱等[1]。正是基于以上对数据与算法风险的分析,本文将智能情报分析中数据与算法风险识别模型构建分为筛选审核—沙盒测试—输出结果三个阶段,如图1 所示。
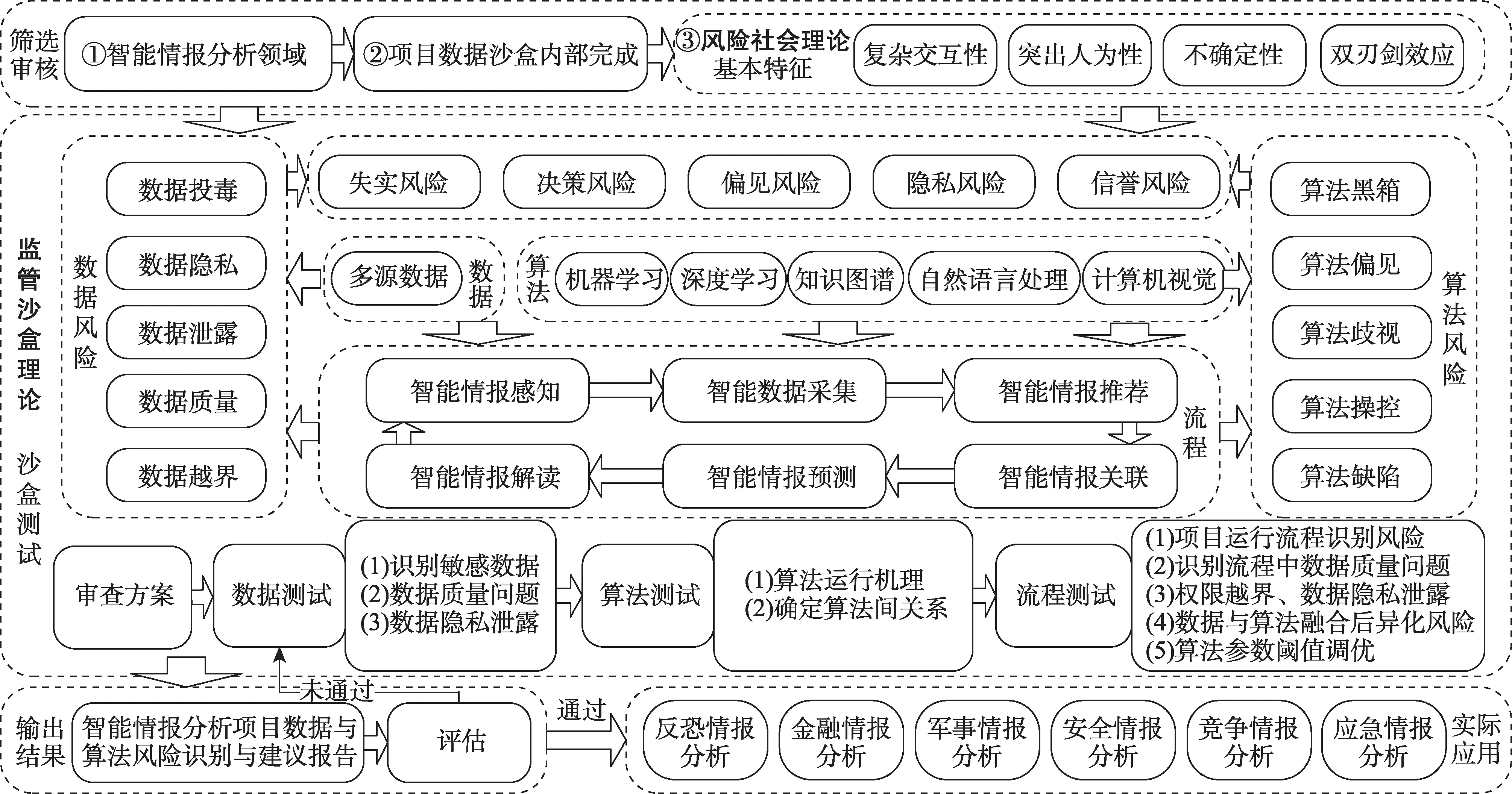
图1 智能情报分析中数据与算法风险识别模型
1)筛选审核
本课题团队向沙盒测试机构提出申请,在筛选审核过程中,应遵循以下基本原则:一是入盒项目归属于智能情报分析领域,所谓智能情报分析项目需要以大量的数据为基础,融合大数据与人工智能技术,是支持复杂业务问题的自动识别、判断并做出前瞻或实时决策的智能化项目[10,45];二是入盒项目所涉及的数据均应在沙盒内部完成,并不会对现实社会造成影响;三是入盒项目有数据与算法风险所具备的风险社会理论中复杂交互性、突出人为性、不确定性、双刃剑效应等特征[42]。基于此筛选出项目是否符合入盒标准。
2)沙盒测试
项目通过筛选审核后,参考监管沙盒中沙盒测试流程[46]和软件项目管理标准[47],入盒项目团队要从“数据-算法-流程”三个维度提交五份报告,具体报告详情如表1 所示。若审查所提供的相关报告准确无误,则沙盒测试机构将基于实际项目和相关文档对入盒项目进行全面测试。

表1 智能情报分析项目相关报告
(1) 数据描述。要对项目中数据进行全面描述,基于数据越界、数据质量、数据泄露、数据投毒、数据隐私等风险按照如下步骤进行:一是明确数据收集范围,确定关键敏感字段;二是在实际测试过程中,重点观测每个环节的数据质量;三是识别是否存在数据泄露、数据投毒等风险,识别是否存在触犯《中华人民共和国网络安全法》《中华人民共和国数据安全法》《中华人民共和国个人信息保护法》《中华人民共和国保守国家秘密法》(以下分别简称《网络安全法》《数据安全法》《个人信息保护法》《保密法》)等法规的情况。
(2) 算法描述。要对项目中算法进行全面描述,基于算法黑箱、算法歧视、算法偏见、算法操控、算法缺陷等风险按照如下步骤进行:一是确定所使用的核心算法类型,明确使用算法运行机理;二是确定算法间使用关系,重点关注是否存在算法加权、算法改进后使算法运行机理发生变化的情况,尤其是深度学习算法的交叉使用,其评估标准可以参照2018 年中国电子技术标准化研究院等机构发布的《人工智能深度学习算法评估规范》。
(3)流程测试。沙盒测试以风险识别与防范为基本思路,流程测试重点参考数据描述和算法描述的内容。智能情报分析流程主要包括智能情报感知、智能数据采集、智能情报推荐、智能情报关联、智能情报预测、智能情报解读等[1],情报分析项目往往包括其中的一个或多个流程。流程测试是在数据测试和算法测试基础上进行的,要基于数据与算法风险特征通过实际数据识别风险,具体步骤如下:一是从项目运行流程视角发现数据与算法的运行风险;二是基于项目流程测试识别由bug 导致的数据质量问题;三是识别项目中越界存取、数据隐私泄露的情况;四是对算法中参数、阈值进行反复调试直至最优;五是重点核查数据与算法相融合后的异化风险。
3)输出结果
沙盒测试完成后,要基于沙盒测试结果最终形成智能情报分析数据与算法风险识别建议综合报告,并由测试团队对结果做出评估,综合参考《人工智能深度学习算法评估规范》《人工智能数据安全白皮书》等,将数据与算法风险按照严重程度、可控性和影响范围等因素[42]分为灾难级(I)、严重级(II)、一般级(III)和轻微级(IV)四级,如表2 所示。其中情报分析项目内容和数据与算法风险点是评估等级的重要标准,将评估等级线划定为轻微级(IV),若项目所有评估风险均低于轻微级(IV),则可将其投放市场;若高于轻微级(IV),则未通过评估,需要根据风险点进行整改,整改后重新入盒测试,直到通过评估。智能情报分析项目测试机构应持续跟踪入盒项目测试状况及产生的经验数据,以此提升智能情报分析风险识别的准确性;对智能情报分析项目中数据与算法的风险识别能够降低项目入市后的安全风险,以促使情报工作市场良性循环发展。

表2 数据与算法风险评估等级划定表
3 实证研究
为更好地验证风险识别模型的有效性,本文以本课题团队中“领域热点主题识别及演化分析项目”为例,基于风险识别模型识别该项目中数据与算法存在的风险。筛选审核作为风险识别初始环节,根据筛选原则,首先确定项目所采用的LDA(latent Dirichlet allocation) 主题聚类是人工智能领域无监督学习的重要算法之一,而对某领域热点主题识别及演化研究是情报学研究的重点内容[48],因此该项目归属于智能情报分析领域;其次,该项目以智能算法领域为例[49],其测试过程与结果属于全封闭状态;最后,该项目中数据与算法风险具有典型的风险社会基本特征,尤其是符合突出人为性和双刃剑效应。因此,判定该项目符合入盒测试条件,根据项目团队提供的5 份报告(见表1)和风险识别模型(见图1),对该智能情报分析项目中数据与算法风险进行识别。
3.1 核心数据描述
基于《智能情报分析项目需求分析报告》《智能情报分析项目数据设计报告》《智能情报分析项目测试报告》对项目中核心数据进行如下描述:①数据采集:该项目中核心数据选择Web of Science(WoS)中以“智能算法”为关键词的48734 条文本数据;②数据处理:提取篇名及摘要形成预处理语料,筛选无效数据、不完整数据,剩余47896 条数据;③构建数据词典:提取关键词形成该项目的领域词典,共50565 条;④主题数据抽取:此部分分别对全局数据与阶段数据进行LDA 主题聚类,全局数据进行主题抽取后共形成46 个主题,阶段数据按照时间划分为12 个阶段,分别形成了每个阶段的最优主题;⑤主题数据过滤:将全局主题与阶段主题进行相似度计算,按照一定规则进行主题过滤,去除无效主题,有效主题数分别为(13,17,16,24,28,29,29,25,27,30,27,42);⑥热点主题识别:依据新颖度和支持度对热点主题进行识别[50],识别热点主题82 个;⑦主题演化路径:通过计算不同阶段热点主题相似度形成主题演化路径[51];⑧输出智能情报分析结果:基于实际数据输出可视化的情报分析结果。
3.2 核心算法描述
基于《智能情报分析项目需求分析报告》《智能情报分析项目核心算法解释性文档》《智能情报分析项目测试报告》分析发现,该项目中核心算法为LDA 主题模型和余弦相似度。
(1)LDA 主题模型。LDA 主题模型的联合概率具体表示[52]为
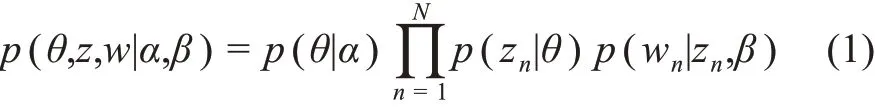
为了使算法描述得更为清晰,测试团队用图模型的表示方式来分解公式(1)。把公式(1)抽象为语料层、文本层、词语层,利用图模型的方式把LDA模型表示出来,如图2 所示。①语料层:α和β是文本语料集的超参数,这两个参数是模型训练的关键,α是p(θ)分布的向量参数,用于生成主题分布θ;β是主题对应词语的概率分布矩阵p(w|z)。②文本层:文本和主题分布θ是对应的,每个文本产生的主题z的概率是不同的。③词语层:z是由主题分布θ生 成的,w是由z和β共 同生成 的,w和z是 相对应的;w为观察变量,θ和z为隐藏变量,可以通过EM(expectation maximization)学习出α和β,由于后验概率p(θ,z|w)无法直接计算,因此要用似然函数下界来近似推理出估计值,计算最大似然函数,得出α和β,不断迭代直到收敛,最终完成主题聚类过程。在该项目中,通过perplexity 方法来确定LDA 模型最优主题数[53]。
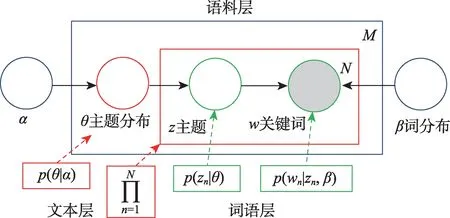
图2 LDA生成过程图模型
(2)余弦相似度。该项目采用余弦相似度计算的方法来衡量相邻较近时间片的热点主题关系,从而确定相关主题间的演化关系与演化路径。对任意两个主题z1和z2,利用余弦相似度计算主题相似性[54],即
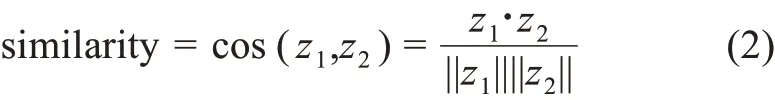
其夹角余弦值表示距离,通过计算两个向量的余弦值来表示两个主题相似度,其取值范围从0 到1,数值越大则相似度越高。
3.3 基于流程的数据与算法风险识别
依据智能情报分析整体流程,基于《智能情报分析项目需求分析报告》《智能情报分析项目流程设计方案》《智能情报分析项目测试报告》,形成该项目的数据与算法风险识别图,识别出10 个风险点,如图3 所示。在沙盒测试后形成的《智能情报分析数据与算法风险识别及建议综合报告》中将围绕这些风险点提出综合建议。
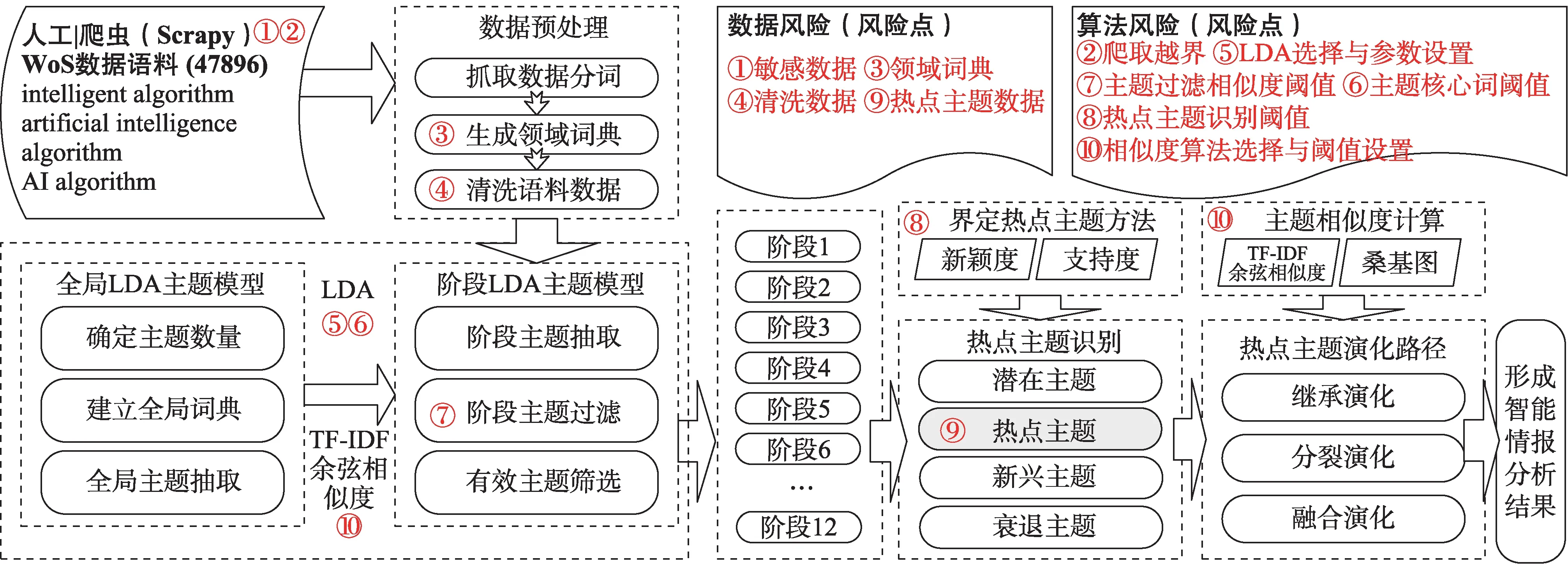
图3 基于项目流程的数据与算法风险识别
1)数据采集
①敏感数据:包括保密数据、隐私数据等。在数据获取或爬取过程中,按照《网络安全法》《数据安全法》《个人信息保护法》《保密法》中对数据获取的明确要求,严格审查数据获取规则、数据获取主题、数据获取范围,如果发现处于争议的数据需要通过建立敏感数据字典的方式进行预警与过滤,采集敏感数据的数量会直接影响机器学习的深化程度及算法操控风险发生。在本项目中由于选择主题为智能算法,获取途径为直接下载,因此该部分数据源并未涉及敏感数据。
②爬取越界:《数据安全法》第三十二条提出,任何组织、个人收集数据,应当采取合法、正当的方式,不得窃取或者以其他非法方式获取数据;《数据安全管理办法(征求意见稿)》第十六条和第十七条规定了爬虫获取数据的界限,尤其是对收集重要数据或敏感数据,应特别重视并严格审查,该环节极易造成数据隐私风险、数据泄露风险。该项目利用人工采集数据,因此并未涉及此类风险。
2)数据处理
③领域词典:由于该项目需要引入领域词典,因此该环节容易出现带有污染、偏见与歧视性的数据词典,需要详细核查领域词典数据获取途径,并对词典内容进行反复检验。该项目是将WoS 文献中的关键词叠加去噪后作为领域词典,因此该部分数据质量相对较好。
④清洗数据:该项目通过NLTK (natural lan‐guage toolkit)进行预处理,包括tokenize 分词、词性标注、归一化等,随后导入领域词典,去除副词、形容词、助词等无实际意义的词(只保留名词、动词等)等操作,通过反复测试识别无效词进而形成无效词表并导入,直至实现数据最优。一旦无实际意义的数据充实到LDA 主题聚类中,就会造成数据污染,这将会对有价值的情报构成直接影响。
3)主题抽取
⑤LDA 选择与参数设置:算法选择与参数设置都会影响最终情报输出的结果,基于3.2 节核心算法描述了解LDA 模型、运行机理及影响其稳定性的关键因素后,做如下风险分析。一是LDA 采用的是词袋模型,语义分析层面较为欠缺,因此在数据集较小或数据内容欠规范的情况下会直接影响结果输出的精准性。鉴于该项目数据集合较大,且数据内容相对规范,因此选择该算法风险较低。二是参数设置对算法稳定性起到重要作用。对LDA 算法超参数、迭代次数、主题数量等进行合理推测,通过沙盒测试观察实验运行结果,反复调整最终确定合理数值为:(a)超参数:α=0.01,β=0.001。如果超参数设置越小,主题聚类后就越集中。由于最优主题数和词典数较大,因此参数α和β要选择较小的数值,这样会使文档—主题、主题—词分布聚集到部分特征维度上。(b)迭代次数:迭代次数多容易导致消耗性能,迭代次数少会使模型不收敛,为了保证足够的Gibbs 采样次数,经反复测试后,数值为500 输出数据较为合理。(c)主题数量:引入perplexity 困惑度方法对LDA 模型多次测试后,随着迭代的进行,LDA 模型的perplexity 曲线会逐渐收敛,因此根据perplexity 曲线收敛性可验证LDA 主题数据的准确性。
4)主题过滤
⑥主题核心词阈值:此阈值比例设置较高时,会导致许多概率较低的词参与到相似度计算;阈值比例较低时,会导致与主题相关的主题词被过滤掉,使主题相似度计算数值出现虚高,这会对情报结果产生严重失实风险。在该项目中主题内容通过词分布进行向量化,将每个主题视为向量,每个词视为主题向量的一个属性维度,其对主题的贡献概率是向量在这个方向上的强度,将LDA 聚类后的全局主题和阶段主题都视为向量,向量的维数理论上是全局词典中词的数量,因此计算主题向量之间的余弦值可以衡量主题之间的距离,这个距离反映了两个主题内容的相关程度,该项目选取传统的
TF-IDF (term frequency-inverse document frequency)生成词向量,测试过程中建议选用word2vec 和BERT(bidirectional encoder representation from transformers)训练词向量模型。在计算两个主题向量的内积时,每个向量都有156545 维,经过反复测试,选取概率小于1/156545 约为6.39×10-6(接近0)的数值,而该数值恰好约占总主题词数量的5%,因此阈值按照5%选取,通过随机抽样方法观测主题内容确定该阈值置信度较高,所带来的情报失实风险较小。
⑦主题过滤相似度阈值:此部分阈值设置较高会导致有价值主题被排除,阈值设置较低会使部分无效主题进入。通常来说,只要算出阶段主题对任意一个全局主题的余弦相似度大于阈值,就认为阶段主题和全局主题关联较大,这就实现了对有效主题的识别。此部分阈值计算公式为
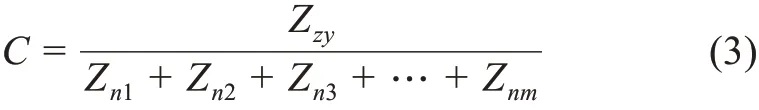
其中,Zzy为全局最优主题数;Znm为阶段主题数。根据公式(3)计算阈值C为0.1009。在测试过程中出现了阶段主题和全局主题之间所有主题词的概率平均且很小,余弦相似度接近1 的情况,这是LDA 主题聚类时主题计算崩溃造成的,因此还要选取大于阈值C且小于95%的阶段主题。通过数据与算法的双向驱动识别风险,若此部分数据被识别为有效主题,则输出的情报将会出现失实风险。
5)热点主题识别
⑧热点主题识别阈值:按照《智能情报分析项目核心算法解释性文档》中热点主题识别所提出的新颖度和支持度计算方法[50],对热点主题识别过程分析如下。
首先,计算不同阶段中主题平均概率Rn,只要某一阶段的某一文档对主题分布的概率大于Rn,就认为该文档对这个主题构成了支撑,Zxn为阶段有效主题数量,计算公式为

其次,计算支撑度ZCn,定义文档支撑数量为DZn,阶段文档总数为Dn,计算公式为

再次,计算平均支撑度ZCP,计算公式为
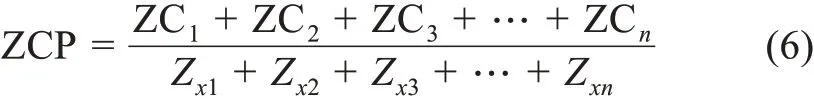
最后,进行热点主题识别,在阶段主题支撑度矩阵中筛选出大于文档平均支撑度的主题作为热点主题,Rn阈值设置直接影响热点主题识别结果,经过反复测试证实当前阈值相对合理,热点主题识别相对较为准确。
⑨热点主题数据:基于以上方法确定第二象限数据为热点主题区域,但实际测试发现,在新兴主题区域中部分主题是热点主题的延续,只要新兴阶段的主题和热点阶段的主题具有相似性,就说明它们是同一演化路径热点主题的延续,这类主题属于持续热点主题。最终得到热点主题82 个,如图4 所示,如果忽略新兴主题区域圆圈部分数据,就会使有效数据缺失并直接导致出现情报分析结果失准或带有偏差等风险。
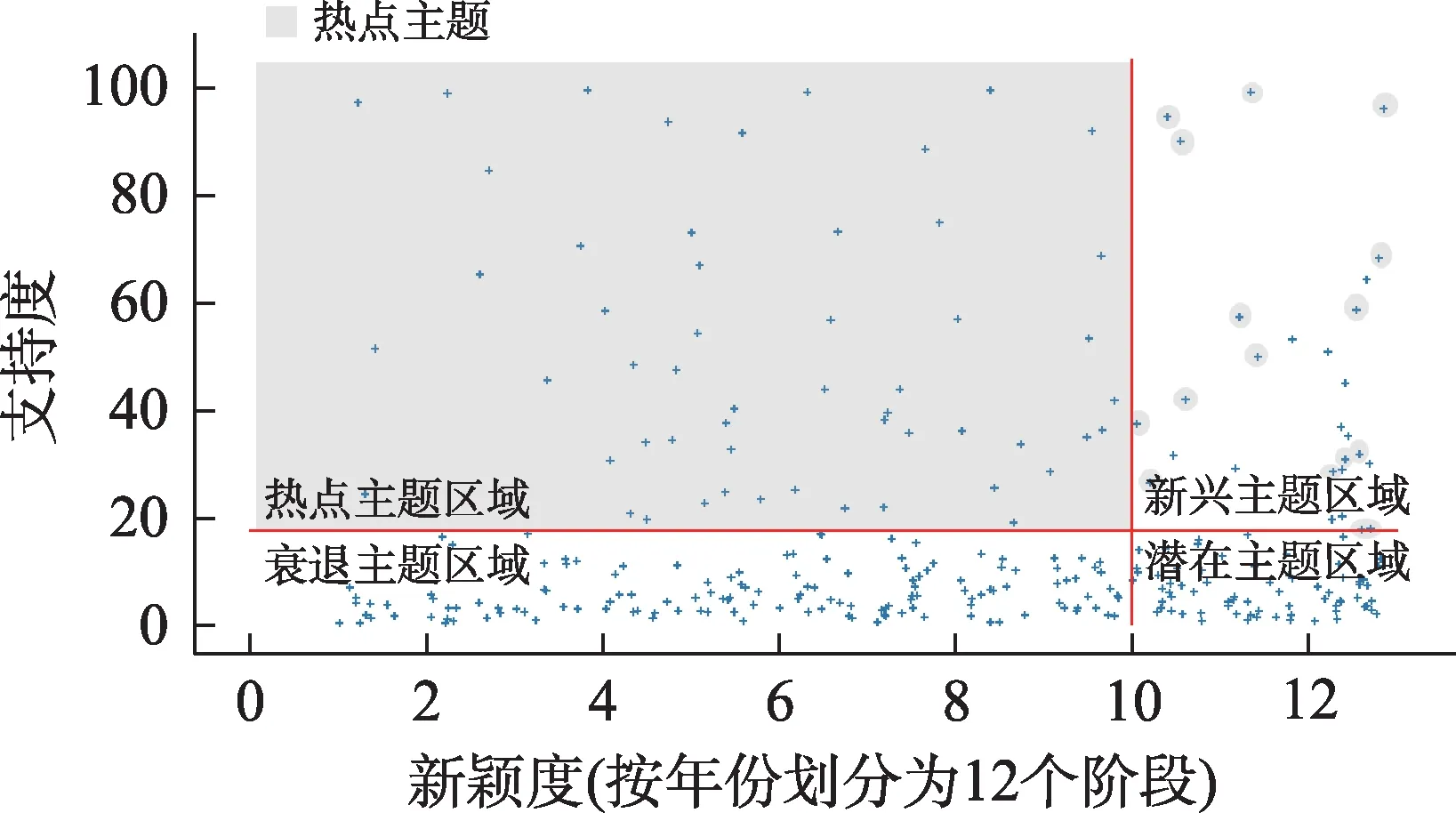
图4 智能情报分析项目热点主题分布散点图
6)主题演化路径
⑩相似度算法选择与阈值设置:相似度计算是机器学习领域基础而重要的算法,余弦相似度计算是常用相似度算法之一,其应用于众多领域。在该项目中,主要利用此算法计算相邻阶段热点主题之间的余弦相似度。在算法选择层面,由于余弦相似度是基于词语的方法,并未考虑语义层面的内容,因此应尽量考虑基于知识库与语料库的方法[55];该算法可能会过滤掉一些语义相似的数据,进而使情报结果准确度降低,在测试结果中建议选择更多的相似度算法以提升情报分析的准确度,进而挖掘更精准的情报。在阈值设置层面,测试发现在相邻热点主题相似度矩阵中,大于20%的共有68 个相邻主题,大于30%的共有26 个相邻主题,为了将更多相关主题纳入演化路径中,因此测试选取20%作为阈值,最终形成如图5 所示的热点主题演化路径。
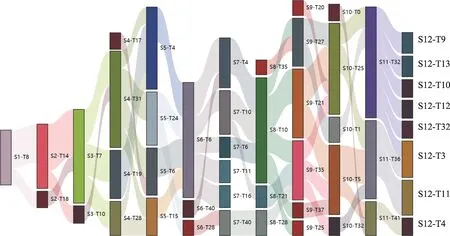
图5 不同阶段的主题演化路径
7)形成情报分析结果
针对所形成的部分继承演化、融合演化和分裂演化路径做如下分析。其中S1~S12 代表了阶段,T代表了某阶段的主题。
(1) 继承演化:选取从S6-T28 到S7-T40 再到S8-T28 所形成的继承演化路径,如图6 所示。其中S6-T28 到S7-T40 相似度为0.211,再到S8-T28 相似度为0.347,从2008—2009 年genetic algorithms、con‐troller 的提出开始,演化到2010—2011 年的robot、controller,在智能机器人运动控制领域进行全局最优解搜索,再演化到2012—2013 年的robot、con‐troller、simulated annealing,在运动控制系统中逐渐使用模拟退火算法(simulated annealing)取代遗传算法(genetic algorithms)。遗传算法和模拟退火算法的作用都是多目标优化找到全局最优的近似解,解决传统的穷举法获得全局最优解运算量大的问题,但遗传算法存在局部搜索能力差、容易陷入过早收敛等缺陷,模拟退火算法的出现解决了当时存在的问题,因此从时间上符合演化规律。
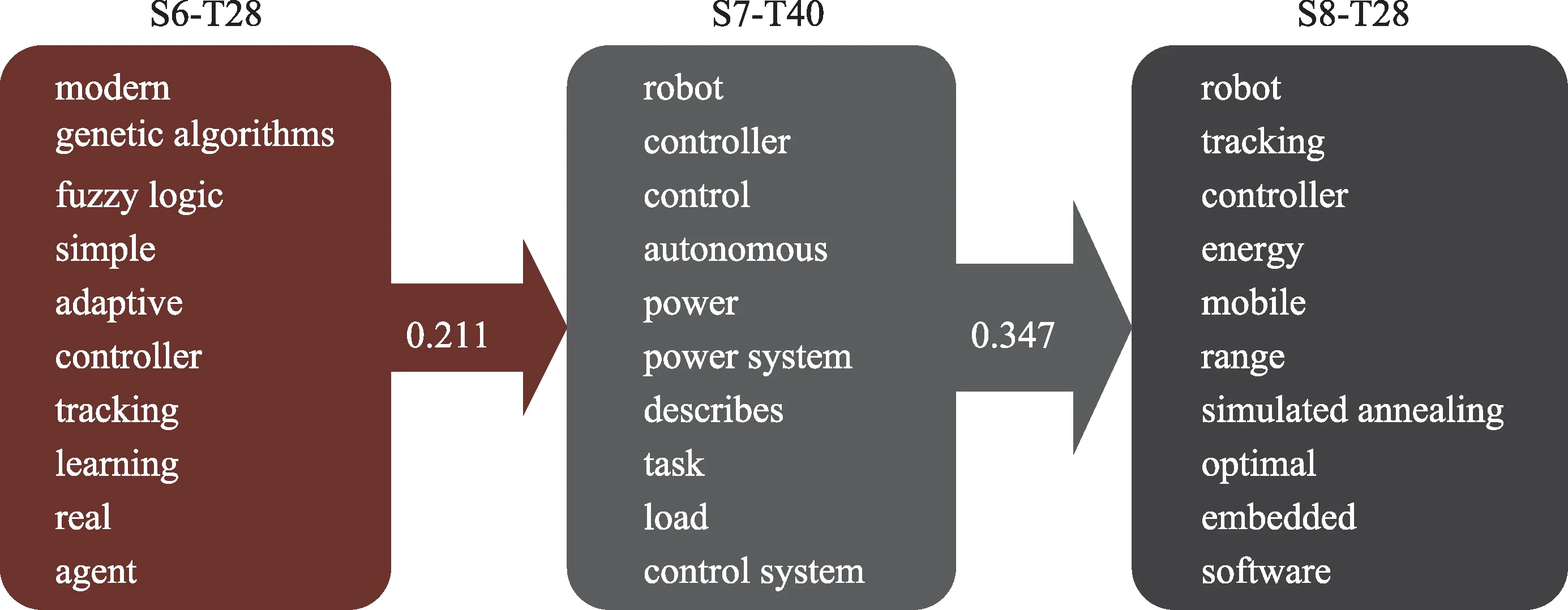
图6 继承演化路径及主题词(Top 10)
(2) 融合演化:选取从S9-T20、S9-T21、S9-T27、S9-T35 主题融合为S10-T25 的路径,如图7 所示。2014—2015 年在技术领域出现了learning、method、optimization、optimized、genetic algorithm、local、complexity 等,主要探讨各种优化参数技巧训练复杂的智能算法模型,在应用领域vehicle、mobile、wireless sensor network 也开始广泛应用智能算法。2016—2017 年主题融合形成了model、recog‐nition、detection、support vector machine 等,在该阶段文字识别、语音技术识别、图像识别等领域不断兴起,并取得了不错的结果,该阶段多数研究从技术上支持向量机(support vector machine) 进行分类。事实上在以神经网络为主的深度学习出现以前,支持向量机是一种非常有效的分类算法。
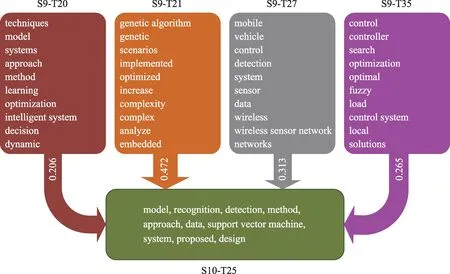
图7 融合演化路径及主题词(Top 10)
(3)分裂演化:选取从S11-T32 主题分裂为S12-T3、 S12-T9、 S12-T10、 S12-T12、 S12-T13、 S12-T32 的路径,如图8 所示。该阶段分裂主题数量最多,自2018—2019 年machine learning、neural net‐work、deep learning 的出现,到2020—2021 年主题分裂 为objective、detection、recognition、CNN (con‐volutional neural network)、 ANN (artificial neural network)、deep learning、congestion、city、machine learning、 decision tree、 prediction、 real-time、 big data 等。分裂主题为三类:(a)目标探测和识别:包括objective、detection、recognition 等,该阶段语音识别、文字识别、图像识别得到更广泛的应用;(b)应用于不同领域:在the internet of things、de‐vices、congestion、city 等领域都发挥重要作用,如物联网、智慧城市等;(c)算法更为细化:包括CNN、ANN、decision tree、real-time、big data 等,其中CNN、ANN 等深度学习算法在该阶段得到了快速发展。
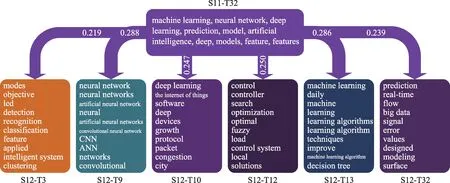
图8 分裂演化路径及主题词(Top 10)
通过对以上演化路径的分析完成了情报分析过程并得出了与实际相符的分析结果,但从主题词上来看,确实存在一些无实际意义的词语,因此需要进行反复测试才能使分析结果更准确。
3.4 测试结果
沙盒测试是对智能情报分析项目中数据与算法风险进行识别的主要方法,并从全流程视角识别风险。对该项目10 个风险点进行评估,根据表2 中的风险等级对数据与算法中每项风险进行风险描述、风险等级类别和等级划分,如表3 所示,虽然该项目不存在较为严重的失实风险、决策风险、偏见风险、隐私风险等,但尚存在4 个轻微级(IV)和6个一般级(III)风险点,因此项目团队要针对6 个一般级(III)风险点进行逐一确认并整改,提交整改说明报告,再次测试无误后方可入市。本文所提出的风险识别模型不但能有效识别智能情报分析项目中数据与算法风险,还能最大限度降低项目入市后所带来的安全隐患。
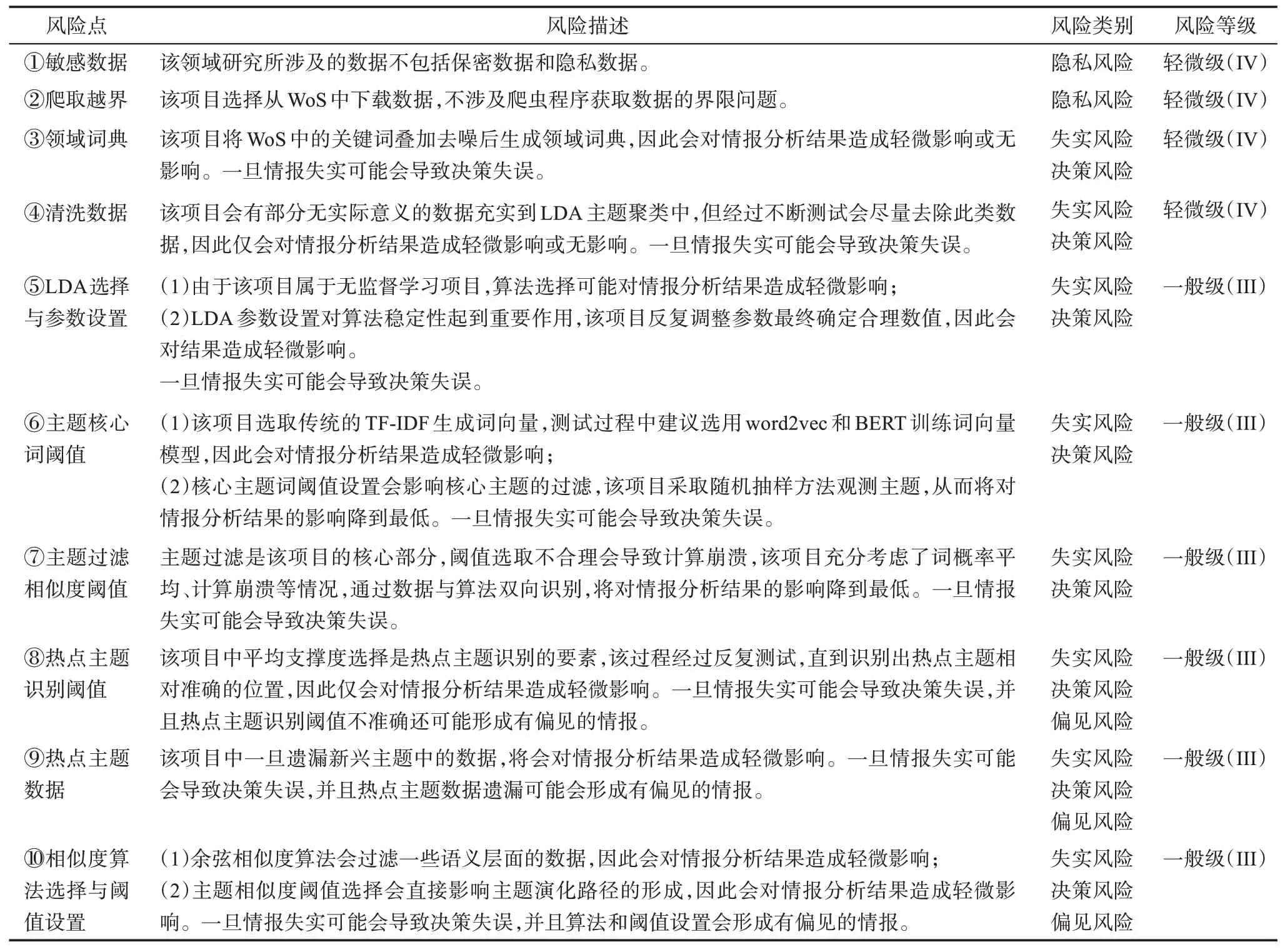
表3 智能情报分析项目中数据与算法风险定级
4 结论与建议
在新兴技术推动社会进步的同时,越来越多的情报分析项目基于大数据与智能算法来实现,但它们在为人类社会提供便捷与高效的同时,也带来了种种难以预测的风险,而且这些风险在金融情报、军事情报、反恐情报、应急情报等领域更具危害性,影响范围更大,甚至会危及社会稳定与国家安全。2021 年7 月“滴滴出行”等接受网络安全审查,被发现其严重违法违规收集使用用户隐私数据,给社会乃至国家安全带来风险,该事件将数据与算法风险识别推上了前台。实际上,《中华人民共和国国民经济和社会发展第十四个五年规划和2035 年远景目标纲要》中明确提出了防范化解重大风险体制机制应不断健全[56],因此该事件的及时处理也充分体现了国家对防范化解重大风险的决心。基于此,本文以风险社会理论、监管沙盒理论为依托,构建“数据-算法-流程”的智能情报分析安全风险识别模型,并以本课题团队的“领域热点主题识别及演化分析项目”为例,详细分析了其数据与算法风险识别的过程,同时也验证了风险识别模型的有效性。最后,通过模型构建与实证提出如下对策建议,期望形成凸显情报学学科特色、突出情报领域话语权、具有实践推广意义的研究成果。
1)培养情报学领域人才的风险识别意识
基于以上实证研究发现,该项目中所存在的风险和当前社会“重创新、轻风险”的思想相吻合,而这正是风险识别意识淡薄所导致的;如果该思想在情报人才培养中蔓延,所带来的潜在危害是无法估量的。因此要培养具有风险识别意识的耳目、尖兵、参谋、引领式情报人才[57],提出以下三点建议:一是在情报学科中增加最新信息技术课程,尤其要重点介绍技术运行原理及应用场景,如人工智能技术、大数据技术等课程;二是增加项目管理中风险识别相关课程,尤其是对技术算法与核心数据中的风险识别及风险预测等;三是增加智能情报分析应用实践项目,增加情报人才的实践能力,有意识培养情报学人才在应用实践过程中的风险识别经验。
2)情报工作机构中设立监管沙盒职能
在风险识别模型中,沙盒测试是基于监管沙盒理论形成的,监管沙盒是指由监管机构提供一个“安全空间”,创新企业在符合特定条件的前提下,可申请突破一定的规则限制在该空间内进行项目测试[58]。监管沙盒强调的是多元共治的监管理念,注重监管机构、被监管者以及消费者多元主体共同参与治理,通过多元共治,将事前预防与事中、事后监管相结合,有效改善了监管信息不对称问题,由此实现对风险的识别及监管。目前越来越多的情报分析项目应用智能技术,而其带来的风险问题容易被忽略,因此情报工作机构应担负起智能情报分析项目中数据与算法风险识别的重任。建议以情报工作机构或行业协会牵头,融合高校、企业的科研力量,在机构内部设立监管沙盒职能,实现对智能情报分析项目中数据与算法风险识别的理论与应用研究,以协助智能情报分析项目团队对项目的完善与创新,降低项目运行的风险。
3)数智环境下实现国家情报工作制度创新
在情报工作机构中,构建风险识别模型需要完善的规则设计,而规则是制度的重要体现形式,因此我们将沙盒测试视作一项平衡科技创新与风险的制度设计,它一旦在情报工作机构内部运行,将是国家情报工作制度重要的创新点之一。当前数智环境下,数据与算法风险识别后急需通过制度建设进行治理,因此情报工作机构要从制度建设层面关注智能情报分析领域所应用到的数据与算法,从以下两个方面提出建议:一是建立具有情报特色的算法监管和算法问责制度,例如,国家适时考虑制定《算法法》,国家情报机构针对已有法规制定适用于情报领域的《人工智能算法审查规范》《算法责任框架》等,在强化监管与问责法律效应的同时,对各领域情报工作起到指导作用。二是构建具有情报特色的数据监管制度。《数据安全法》第二十二条提出,“国家建立集中统一、高效权威的数据安全风险评估、报告、信息共享、监测预警机制。国家数据安全工作机制统筹协调有关部门加强数据安全风险信息的获取、分析、研判、预警工作”。这主要说明国家会加强数据风险情报的共享机制,从制度层面实现智能情报分析中对数据的有效监管。
情报分析有别于其他数据分析项目,其知识性、保密性、价值性、时效性等特点均较为突出。由于“领域热点主题识别及演化分析项目”属于团队内部测试项目,其本身并不会对国家安全及社会稳定造成严重影响,因此项目选择上不具有高风险特征。本文所选取的LDA 主题聚类是无监督学习算法,在风险识别层面并不存在如随机森林、神经网络等算法带来的黑箱风险问题,针对部分具有黑箱特征的风险识别不完全适用,但本文旨在尝试开拓全新应用研究领域,通过构建智能情报分析项目数据与算法风险识别模型来为更多研究者提供参考与借鉴。未来,本团队将继续针对智能情报分析项目对有监督学习算法进行实证,尤其是对具有黑箱属性的智能算法进行深入研究。
猜你喜欢
现代装饰(2022年5期)2022-10-13
现代装饰(2022年3期)2022-07-05
学苑创造·A版(2022年6期)2022-06-20
现代装饰(2022年2期)2022-05-23
科学与财富(2020年28期)2020-12-14
电脑爱好者(2020年9期)2020-07-05
网络安全和信息化(2019年5期)2019-06-04
摄影之友(影像视觉)(2019年3期)2019-03-30
摄影之友(影像视觉)(2019年2期)2019-03-05
摄影之友(影像视觉)(2018年12期)2019-01-28
