
农业在线学习资源知识图谱构建与推荐技术研究
2022-09-06 13:17赵继春孙素芬郭建鑫王洪彪
计算机应用与软件 2022年8期
赵继春 孙素芬 郭建鑫 钟 瑶 王洪彪 王 敏 秦 莹
(北京市农林科学院 北京 100097)(北京市农村远程信息服务工程技术研究中心 北京 100097)
0 引 言
信息传播从文字、声音、图像、视频等单一媒体形式向复合化融合发展,各种信息源之间存在着相互融合的多种形态,内容间存在着一定语义关联,不同信息从某种角度表达相同的语义。复合信息作为信息检索和组织研究在计算机科学、图书情报学等领域得到了高度重视,但如何将这些异构、关联的信息精确地挖掘并组织建构为知识成为新的挑战。知识图谱的出现为复合信息的有效组织和管理应用提供了技术支撑。
知识图谱(Knowledge Graph)概念最初由Google公司于2012年提出,初衷在于改善搜索引擎效率,使搜索结果智能化[1]。知识图谱由“实体-关系-实体”、实体及“属性-值”对组成,实体间通过关联关系相互结合,构成网状知识集合,具备从关联关系的角度分析解决问题的能力[2-3]。近年来,知识图谱被学术界广泛关注,通过推理实现概念检索,从语义方面理解用户意图[4],为用户提供完整、系统和清晰的知识体系结构,从而改进信息化系统服务质量[5]。具有代表性的知识图谱包括WordNet、OpenCyc、Freebase、DBpedia、YAGO2、Freebase、NELL、Probase[6-9],从大量的数据中抽取、组织、管理信息[10],广泛应用到智能问答[11]、信息推荐[12]、智能诊断[13]等领域,成为人工智能技术发展的重要推动力。
本文面向农业在线学习领域,首先基于LDA标签生成的领域知识图谱构建方法,针对北京市农业网络在线学习多媒体资源分散杂乱的现状,研究从学习资源标签中挖掘潜在主题信息并以此为基础进行扩展,构建涉农学习资源领域知识图谱,将分散、无序、海量的信息进行聚合、结构化处理,最终形成关联的知识体系。在此基础上,设计开发了基于知识图谱的协同过滤推荐系统,并通过实验验证,提高了学习资源推荐准确率和效率,为知识图谱构建及其应用研究提供新的视角。
1 相关研究
1.1 领域知识图谱构建方法
知识图谱构建主要包含数据提取、信息融合、数据加工和数据更新。数据提取是从大量数据库及文件中抽取构建知识图谱的元素,应用技术涉及实体、关系及其概念提取等自然语言处理技术,如马建红等[14]提出一种具有反馈机制的联合模型用以改进实体识别及关系提取的关联性。信息融合的主要作用是去除实体的歧义及其错误表述,确保知识图谱构建的质量,包含实体链接汲取数据合并。赵畅等[15]提出应用候选实体类别、关系及其邻近实体作为候选实体表示方法,解决数据库实体描述信息不充分的问题。数据加工是网状化和结构化知识图谱构建的重要步骤,包括知识推理及效率评估,如俞扬信[16]提出基于知识推理的信息检索方法,有效提升数据返回的效率和质量。知识图谱的实体和关系需要不断补充与扩展,因此知识图谱需要持续迭代更新。
知识图谱构建方法通常有自下而上、自上而下及两者结合方法。自下而上是从底层数据中抽取实体与关系并逐层向上汇聚概念,自上而下是从最顶层开始定义领域的实体和关系,两者相结合的方法是先在底层数据抽取基础上构建模式层,然后对新生成的数据进行梳理并更新模式层,再重新对实体进行填充[17]。自下而上的知识图谱构建方法速度快,对大量的底层数据支持好,缺点是知识的准确程度不高。自上而下构建方法的概念和关系准确,缺点是需要人为干预工作量大。混合方法灵活性强,但模式层构建难度大。
1.2 知识图谱与推荐系统相结合
知识图谱应用于智能推荐系统主要优势在于能够对多源异构的信息资源进行整合与提取[18],可以获得细粒度的用户与项目之间的特征数据,能够精确计算用户与项目的关联性,从而获得更加好的推荐效果[19]。知识图谱具有较好的语义支持,CoLResg[20]构建音乐知识图谱并应用推荐系统,采用链接数据库方式得到较好的语义信息。王冬青等[21]针对学习者的学习条件差异,结合学习内容知识点、难易程度、用户学习历史记录,构建基于知识图谱的用户学习试题推荐系统,为用户推荐准确的学习内容。王一成等[22]在农业电子商务领域,通过构建多语言商品知识图谱库,以多源数据关联实现电子商务的数据分析和内容推荐。
以上研究表明,将知识图谱技术运用到个性化推荐系统,在语义支持下可提高推荐系统效率,显著提升个性化服务水平。目前,在涉农网络学习领域知识图谱构建及信息推荐方面的研究还比较少,本文可以为网络在线个性化学习应用研究提供有益的补充。
2 方法流程
本文提出一种基于LDA标签生成的领域知识图谱构建方法,采用机器学习方法为主、人工修正为辅,构建步骤包括实体抽取、关系提取、标签生成、图谱迁移、图谱可视化与维护等步骤,实现过程如图1所示。

图1 领域知识图谱构建流程
(1) 实体抽取。采用N-gram方法对领域资源进行分词,利用TF-IDF计算关键词与文档联系及相应权重。运用机器分类和人工校准相结合,进行标准词库实体提取与确认。
(2) 关系提取。通过LSTM神经网络特征提取模型,减少人工标注句子关系的工作量,能够得到较好的次序语义支持。
(3) 标签生成。通过LDA模型和实体间的关联关系表达资源特征,从全局所有关键词中自动抽取出有概括性的关键词作为标签。
(4) 图谱迁移。将通用知识图谱中实体迁移到领域知识图谱,并对领域的实体、概念、属性、关系等关键知识识别,从通用知识图谱中模糊匹配出领域三元组知识。
(5) 图谱可视化与管理更新。通过软件工程方法,研发知识图谱可视化展示与管理更新工具,实现实体、概念、属性、关系等知识图谱元素的可视化展示、关联查询和更新维护。
3 涉农学习资源领域知识图谱构建
北京农业在线学习涉农资源内容丰富、形式多样,包含1.6万余部视频、0.5万余音频和5万余条图文。对于视频和音频数据主要提取描述属性信息,将离散分布的学习素材数据归一化处理,基于LDA标签生成的领域知识图谱构建方法,按照实体抽取、关系提取、标签生成、图谱迁移、可视化与维护管理等步骤,最终形成具有属性的实体和概念并通过关系链接成网状知识图谱,为智能推荐提供应用支撑。知识图谱构建框架如图2所示。

图2 农业在线学习资源知识图谱构建框架
3.1 实体提取
首先构建涉农学习资源特征词库,结合现有的涉农资源标签库,运用人工校准与机器分类相结合,进行标准词库的提取与确认。从学习素材信息中提炼主题词库,如种植技术、养殖技术、病虫害防治、休闲农业、乡村振兴等。初期的特征词库根据现有的涉农资源类别归纳、总结,再根据关键词解析、标题解析、描述解析、评论解析得到特征词集,后期随着解析词汇增加,特征词库集不断丰富,具体实现步骤如下。
(1) 采用N-gram方法实现分词(式(1)),为避免将“中央一号文”长词切分,保证这类长词能被正确采集,将农业资源特定关键词加入特定词典再进行分词。
P(T)=P(W1W2…Wn)=
P(W1)P(W2|W1)P(W3|W1W2)…
P(Wn|W1W2…Wn-1)
(1)
设T由词序列W1,W2,…,Wn构成,整个句子出现概率为各个词出现概率之积。
(2) 应用停用词表去除噪声关键词,通过条件随机场对文本词性标注,提高中文分词效果准确性。
(3) 利用现有词库进行检验,去除无意义的词,如“国辣椒”。
(4) 利用TF-IDF计算关键词与文档联系和相应的权重。
(2)

(3)
式中:IDF为逆向文件频率;|D|为文档的数量和;|{j:ti∈dj}|为含有关键词ti文档数量。
TF-IDF=TF×IDF
(4)
式中:TF-IDF为词频TF和逆向文件频率IDF之积。
以文档学习资源《辣椒春季保护地栽培技术》为例,从文档中解析出“辣椒、春季、保护地、栽培技术、辣椒、幼苗越冬、大棚管理、施肥、浇水、病虫害防治、疮痂病、炭疽病”等实体。
3.2 关系抽取
从文本中提取关系是构建三元组重要部分。传统的关系抽取需要人工标注大量数据来训练关系抽取模型,成本太高无法实现大数据量关系抽取。本文通过LSTM(Long Short Term Memory network)神经网络端到端模型实现实体关系抽取[23],为每个关系独立训练双向LSTM抽取模型(图3)。采用弱监督标注方法为每个关系自动构造标注数据,模型将文本中的离散词语映射成特定维度向量,实现层次化向量表达,LSTM引入神经网络记忆单元概念,某一时刻信息输出与当前次特征输入和之前的词输出共同决定,有效解决提取序列特征问题,适合句子的词序语义表示。
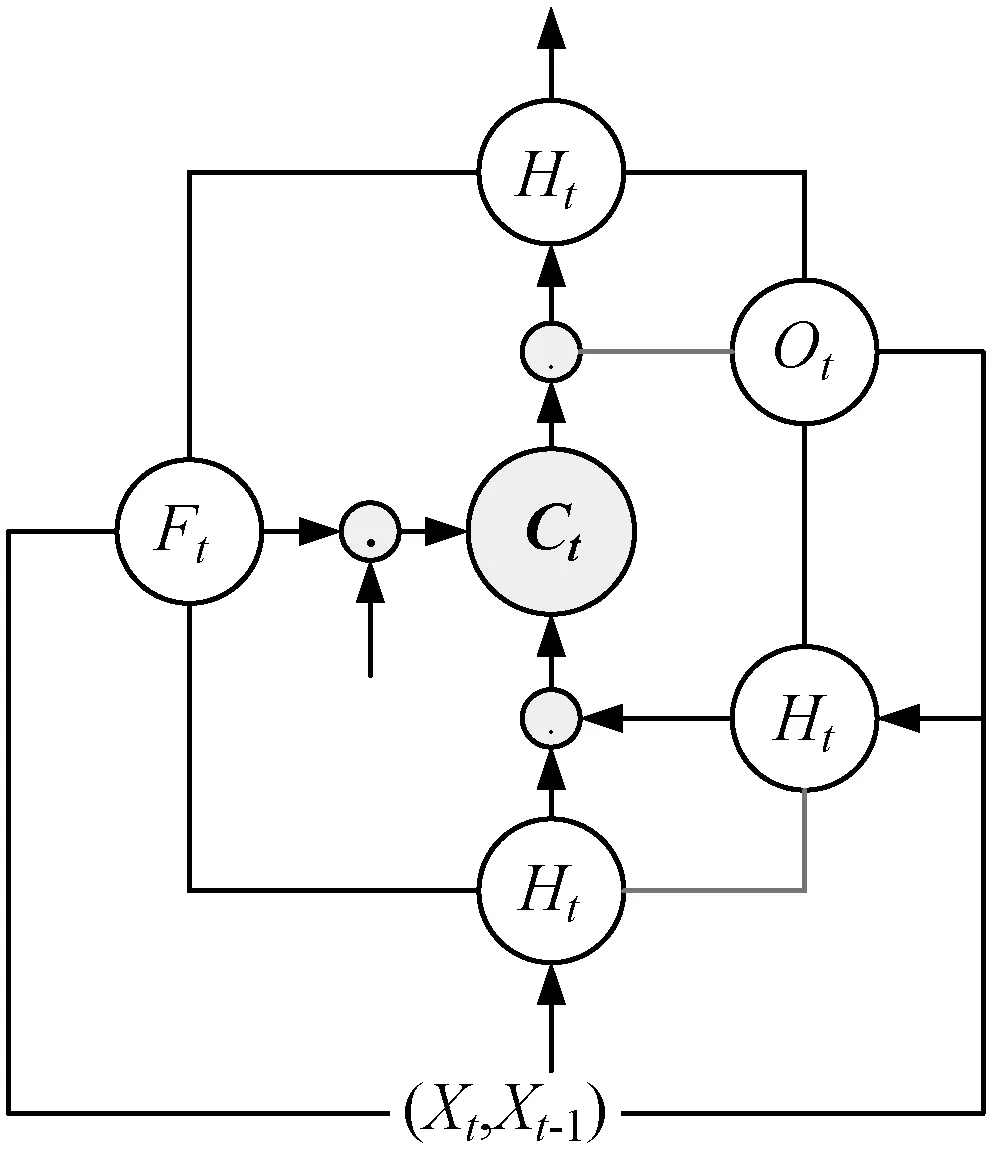
图3 基于LSTM的端到端抽取模型
结合词性、句法树结构等语义特征,构建实体之间关系,通过关系对事件描述有助于分析事件演变过程,关系属性示例如表1所示。

表1 实体关系属性示例
3.3 标签生成
采用LDA(Latent Dirichlet Allocation)模型对学习资源标签化,将资源库中的文档主题以概率分布的形式给出,通过抽取主题分布实现主题聚类和文本分类,同时也是词袋模型,一篇文档由一系列词语组成,词语之间无先后顺序。从全局所有关键词中自动抽取具有概括性的关键词作为标签,每个标签下包含一个关键词袋,并且标签具有层级关系,标签树与关键词袋如图4所示。
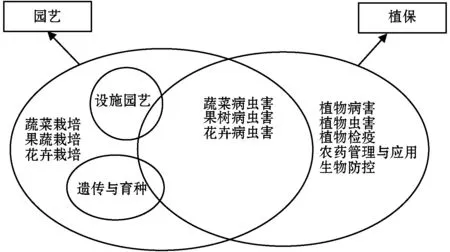
图4 标签树与关键词袋示例
涉农学习资源标签化本质是一个多标签文本分类任务,根据语义将学习资源分类到一组预先定义好的类别标签中并多个维度分析标签的覆盖度和精细度,得到有效支撑知识库的标签集。通过建标签链接和扩展,实现对标签集中的每一个标签映射在知识库中对应的实体。标签生成过程中,下层标签含义上包含上层标签,每个标签的关键词袋中所有关键词都可激活该标签;最底层的标签能包含所有的文档。标签初步生成仅依赖于文档,文档数量越多,标签质量越高,并引入图谱中的实体补充标签信息。当涉农学习资源素材发生改变时,系统的关键词也会发生变化。当添加一篇新文档时,标签系统自动分析并生成标签,每个标签都有一个权重值,仅输出分数在一定阈值内的标签。自动生成的标签可人工干预,提高系统的灵活性。如针对《着力提高国家粮食和物资储备安全保障水平》资源,提取的标签和权重为{粮食,0.249 57}、{储备,0.227 08}、{粮食安全,0.140 81}、{坚持,0.077 38}、{国家,0.076 05}、{物资,0.068 34}、{优粮,0.056 81}。
3.4 图谱迁移
本文构建的知识图谱实体与CN-DBPedia关联,将CN-DBPedia通用知识图谱中实体迁移到领域知识图谱,对领域的实体、概念、属性、关系等关键知识进行识别,并以此为标准从通用知识图谱中模糊匹配出领域三元组知识,实现实体迁移,完善领域知识图谱内容。知识图谱储存采用Mongodb内置的分布式储存机制,设置一定量的Replica作为备份,具有快速查询、自动分片、支持云级扩展性、内置MapReduce等优点,适合作为知识图谱存储数据库。
3.5 图谱可视化与管理
应用Python集成开发环境,研发了涉农领域知识图谱可视化展示与管理系统,实现实体、概念、属性、关系等图谱元素的可视化展示与查询管理。运用标签树展示整个标签系统,进入实体关系首页,界面展示画圆效果如图5所示。标签权重可以直观展示出不同实体之间的关系,实体之间的距离反映实体与标签间的紧密程度。点击实体标签可自动连接到CN-dbpedia的相关页面(图6),例如点击“经济发展”实体,链接到CN-dbpedia的经济发展实体。

图5 知识图谱可视化效果
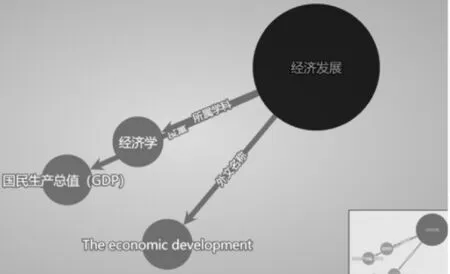
图6 标签链接到CN-dbpedia的示例
知识图谱后端管理系统实现了资源素材管理、关键词生成和标签的处理,具体功能包括:学习资源检测、生成关键词、关键词解析;修改自动生成标签以及关键词权重、属性、关联关系等;支持自动添加关键词、关联关系。管理界面如图7所示。
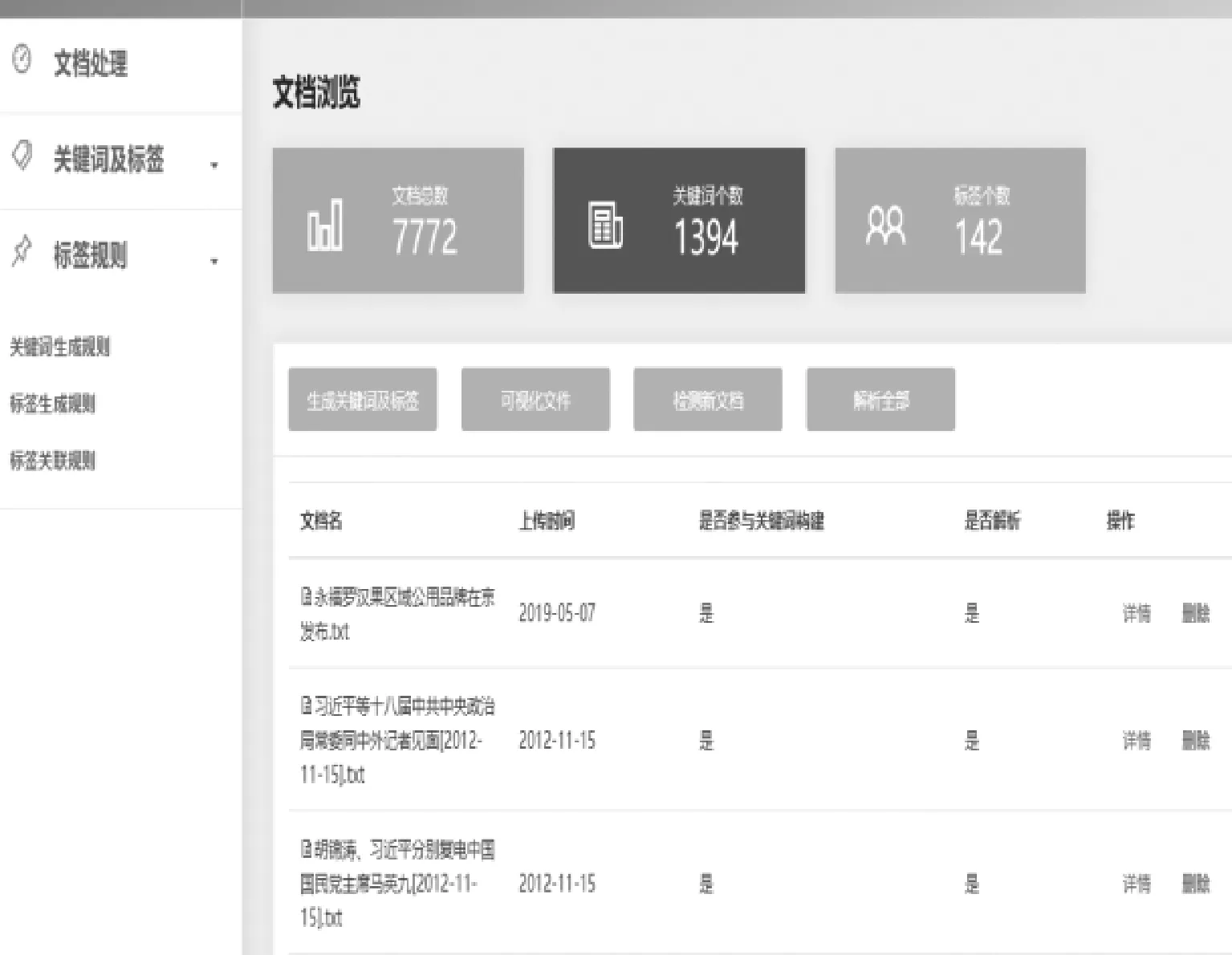
图7 知识图谱后台管理原型
4 基于知识图谱语义相似度的协同过滤推荐
4.1 标签语义查询
在涉农学习资源知识图谱构建基础上,实现基于语义理解的描述信息的解析。本文将用户查询语句分为两类:(1) 给定一个类型或概念,返回该类型的实体列表;(2) 给定实体集合,返回与输入相关的实体列表。
对于类型查询,给定类型或概念,根据查询长度分两种情况:(1) 查询类型为名词或者一个名词加上一个修饰词组成,如“病虫害”和“番茄病虫害”。系统直接返回在知识图谱中该查询类型下的实体。(2) 查询类型由一个名词加上多个修饰词组成,如“农村社会公共事业建设”,直接从知识图谱中获取结果不现实,通过对查询语句进行解析,将其拆解为三个简单类型,即{“农村建设”,“社会建设”,“公共事业建设”},这些类型在知识图谱中具有较高的覆盖率,通过查询这些类型实体,并通过交集操作方式作为返回结果。
对于特定实体集查询,返回的实体要符合用户潜在查询的类型,满足用户的查询意图。如用户输入{“作物生产技术”,“林业生产技术”,“畜禽养殖技术”},用户意图可能是“农村先进适用技术”数据类型,因此,返回结果应是知识图谱中“实用技术”及其邻近节点的实体。对于实体集的查询,返回与查询实体经常出现的实体,使用共现次数作为返回结果。同时利用知识图谱中已有关联关系(如上下位词)对输入的实体进行概念化语义匹配,理解用户查询意图,并返回该语义下相关实体。
为减少查询图操作的复杂度,系统对查询的文本信息进行预先过滤,主要策略是基于实体、类型、属性、关系过滤并建立典型路径和频度模式分类索引,从而加快查询算法速度。
4.2 推荐算法设计
提出基于知识图谱语义相似度的协同过滤推荐算法,对涉农领域知识图谱标签权重进行相似度计算,并对标签的权重聚合,通过矩阵分解得到一个包含一系列语义相关标签基的标签子空间,使得同义及相关的标签聚合于同一标签基,且一词多义的标签归类到语义不同的标签基,从而实现标签语义的近义归类和多义辨析。
针对不同学习资源设定的不同专题,对于具有描述文本的资源采用TF-IDF方法提取资源描述关键词作为特征词。对于设定类别目录的资源,将目录路径上出现的名称都作为特征词,层级越细的目录名赋予更高的权值。用户标注标签的资源,直接将标签作为特征词,标注频率作为标签的权值。根据涉农学习资源领域知识图谱中存在大量的上下位词关系,计算两个标签的相似性时,通过计算两个节点的共享父概念和子概念的频数,构建相应的概念向量,根据相似度的大小为用户推荐学习资源。
在领域知识图谱相似度计算时,用户感兴趣的特定标签具有相应权重值,结合知识图谱及其用户对标签的评分信息计算相似度。用户感兴趣标签数据集ID={D1,D2,…,Dn},ND(Dm,Dn)为两个感兴趣标签Dm与Dn在涉农学习资源知识图谱中关于同一类别节点最近一个,兴趣标签Dm与Dn在知识图谱中的语义相似度计算公式如下:
(5)
式中:IDsim(Dm,Dn)为兴趣标签Dm和Dn的语义相似度;Depth(Dm)为从图谱中同类资源根节点到用户标签Dm路径深度;Depth(Dn)为从图谱中同类资源根节点到用户标签Dn路径深度;Depth(ND(Dm,Dn))是图谱中同类资源根节点到Dm和Dn最临近共祖先节点路径长度。IDsim(Dm,Dn)数据范围[0,1],Dm=Dn时,即两个标签相同,IDsim(Dm,Dn)=1。兴趣标签相似度数值随着共祖先节点深度增加而变大。
5 实验与分析
5.1 实验数据与设置
从北京农业在线学习平台中提取数据:总计5 000条用户学习应用数据,其中包含423个用户及832个学习资源,用户对学习资源评分分为3个等级,评分等级的数值反映用户对学习内容的喜好程度。
将实验数据划分为训练集和测试集,在数据集中随机抽取一定的比例作为实验训练集,我们按照数据总量的20%、40%、60%和80%抽取,剩下数据是测试集,采用用户对学习资源的打分值和相似度分析预测测试数据的学习资源评分数据,分别采用基于涉农资源知识图谱的协同过滤推荐与传统系统过滤方法推荐。同时计算稀疏度SPA(式(6))、准确率MAE(式(7))和覆盖率COV(式(8))。
(6)
式中:SPA为稀疏度;M为用户已经评分资源梳理;U是用户数量;N是学习资源数量。
(7)
式中:{L1,L2,…,Li}为预测评分数据集;{M1,M2,…,Mi}为用户实际打分数据集;N为集合的数量。
(8)
式中:Md是测试数据集合中预测评分数据的数量;M为测试数据集合中的预测评分数据的总量。
5.2 实验结果及分析
通过不同测试训练集划分,计算基于涉农学习资源知识图谱语义相似度的协同过滤推荐(方法一)与基于传统资源库推荐方法(方法二)的稀疏度SPA、准确率MAE和覆盖率COV,数据见表2。

表2 不同训练集占比条件的SPA、MAE和COV
训练集所占比例由20%提高到40%过程中,方法一和方法二的MAE都有所下降,也表明SPA数值增加,推荐MAE数值下降,推荐COV数值在增加;在SPA数值相对较大时,MAE和COV数值变化趋向于平缓。方法一的平均MAE高于方法二,方法一的平均COV接近方法二。基于知识图谱语义相似度的协同过滤推荐与基于传统资源库推荐方法相比,推荐的准确率MAE大幅提升,推荐覆盖率COV基本保持一致。变化趋势如图8所示。因此,通过知识图谱的底层数据支持,与传统的资源库推荐方式相比具有更好的推荐准确率。
6 结 语
本文是在北京市农业网络在线学习平台的学习资源基础上,通过对学习资源系统化和体系化梳理,采用LDA标签提取方法构建了北京市涉农学习资源领域知识图谱,通过软件和数据库技术,研发构建了涉农领域知识图谱可视化与管理维护系统,实现知识图谱的实体、概念和关系的可视化展示及查询管理。本文知识图谱构建及其特征标签提取方法具有一般性,研发知识图谱可视化及维护管理工具,在信息资源的实体关系抽取、标签管理和特征提取方面具有灵活性,可以扩展应用到其他领域。
在涉农领域知识图谱构建基础上,设计研发基于知识图谱语义相似度的协同过滤推荐系统,实验结果表明,推荐准确率达到84.27%,与基于传统的资源库推荐方式相比,大幅提升了推荐准确率,经过北京市涉农地区用户的应用反馈与迭代更新,证实该系统具有较好的易用性、安全性、稳定性和可靠性,具有广阔的市场应用前景。然而作为农业在线学习背景下的涉农领域知识图谱构建与应用探索,仍有很多需要改进的方面,仅为知识图谱的构建和应用研究提供新的视角。知识图谱的实体及关系在涉农学习领域覆盖还不全面,部分实体和关系抽取信息的准确率还需进一步提升,构建知识图谱过程中还需大量人为干预工作,期望后续进一步探索完善这些方面的研究。
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
新城乡(2018年6期)2018-07-09
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
长江学术(2015年1期)2015-02-27
中国报道(2009年12期)2009-01-15
