
面向强化学习的虚拟链路智能体仿真环境研究
2022-09-28 10:49戢泽民徐野哈乐
科技资讯 2022年19期
戢泽民 徐野 哈乐
(1.沈阳理工大学自动化与电气工程学院 辽宁沈阳 110159;2.北部战区总医院医学工程科 辽宁沈阳 110000)
1 研究意义
截至2019 年6 月,全国汽车保有量达2.5 亿辆,私家车达1.98 亿辆。对交通领域发展而言,当前交通安全事故已经成为最大的问题。使用车辆不断增多,引发的交通安全事故也在不断增多[1]。人们对于汽车各个方面的性能要求也在不断升高,自动驾驶汽车便成为了解决这一问题的有效手段,随着5G 时代的来临,自动驾驶汽车的发展备受关注[2]。国外著名的汽车公司和IT巨头正在竞相深入研究无人驾驶汽车技术,如IT 互联网企业、传统的汽车制造商企业[3]。国内早期自动驾驶汽车由各大高校和研究院所对智能车辆的技术的研究[4]。
强化学习就是研究每个状态应该以什么样的策略选择动作,使得整个序贯决策时最优的[5]。所谓强化学习是一种以环境反馈作为输入的、特殊的、适应环境的机器学习方法,它的主要思想是与环境交互和试错,利用评价性的反馈信号实现决策的优化[6]。2013 年,DeepMind 团队将Q-Learning 与深度学习相结合提出深度Q网络(Deep Q-Network,DQN)[7]。强化学习算法与理论的研究为人工智能的复杂问题求解开辟了一条新的途径,强化学习的基于多步序列决策的知识表示和基于尝试与失败的学习机制能够有效地解决知识的表示和获取的问题[8]。当前,为了提升模型的表征能力,研究者们将深度神经网络引入强化学习中,二者优势互补,形成了能在复杂环境中感知并决策的深度强化学习算法[9]。不同于深度学习侧重于感知和表达,强化学习侧重于寻找解决问题的策略,强化学习中的智能体在与环境交互的过程中,为了获取更大的累计奖励值而不断优化动作策略,当累计的奖赏值达到最大后且稳定,意味着学习到全局或局部最优策略[10]。
2 环境分析
2.1 基本要素分析
道路的环境包括天气、道路等级、道路类型、路况、汽车数据、行驶环境。其中天气包括晴/阴/多云、雨、雪、雾。道路等级及各道路限速情况如表1所示。
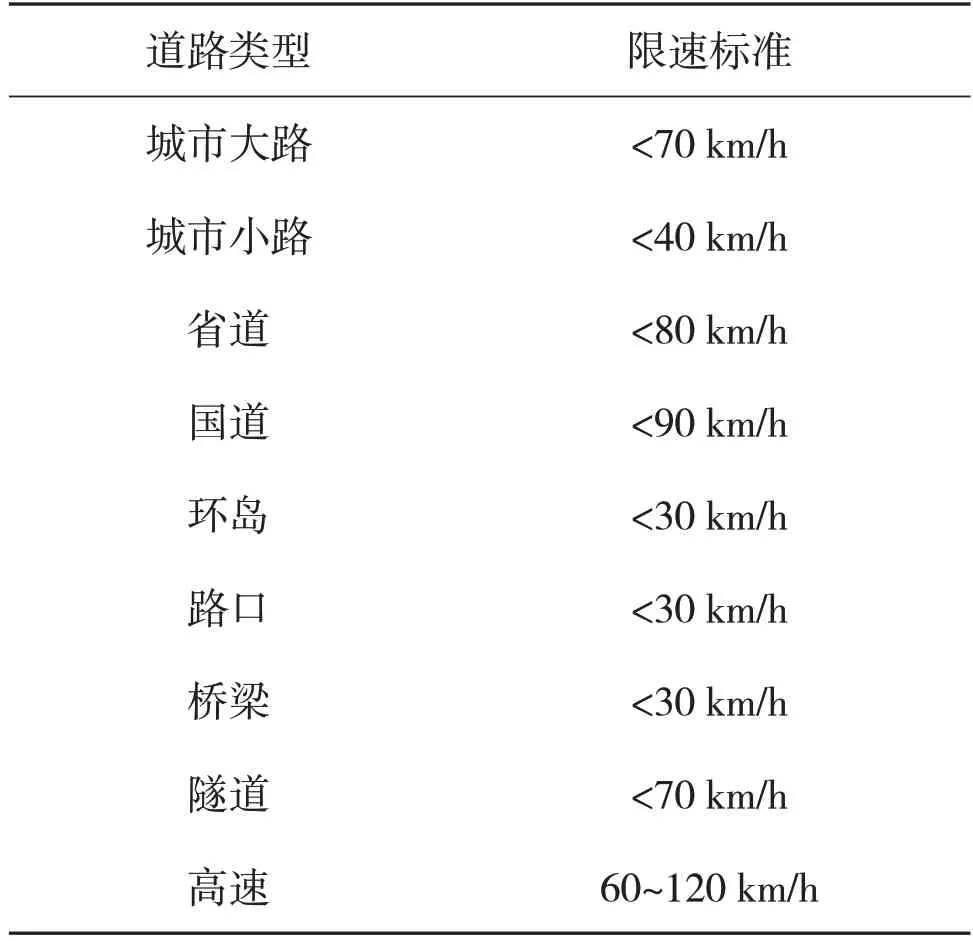
表1 我国各道路类型的限速标准
考虑行驶动作更加直观,将行驶动作包括加速、减速、急加速、急减速和匀速。拥堵情况的设置考虑真实世界的复杂性与随机性,将拥堵情况设置为1 000 m之内随机产生车辆拥堵和红灯拥堵,汽车数据中的行驶里程按照百分制的方式记录,速度表示小车行驶的真实速度。速度公式为

2.2 奖励设置
该文分别设置行驶动作本身所产生的奖励,行驶动作导致车辆状态的改变所产生的奖励,以及小车在行驶途中产生撞车或者到达目的地游戏结束所产生的奖励,具体如表2所示。
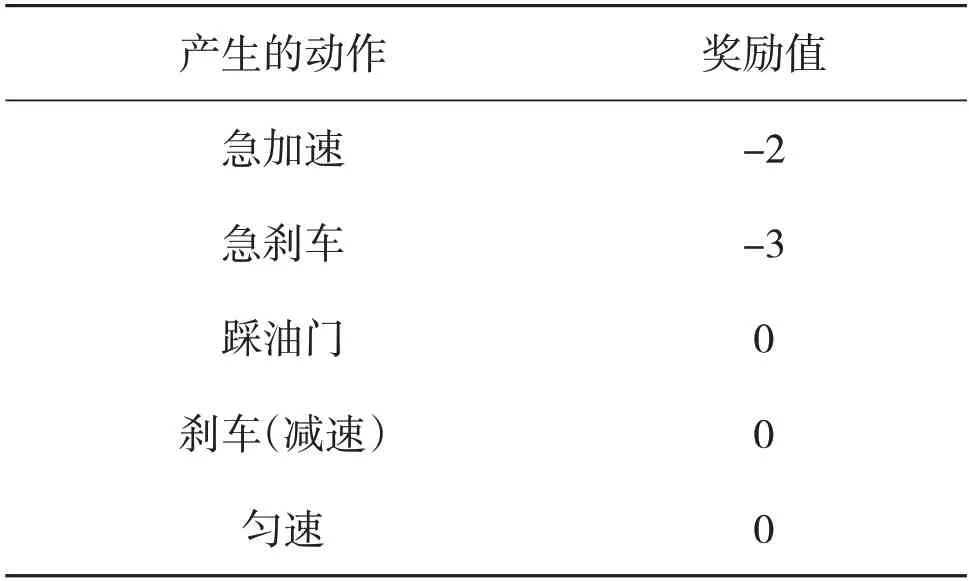
表2 动作本身所产生的奖励
2.3 其他要素
考虑汽车在行驶途中会进行加速、减速,急加速、急减速等一系列的操作所带来动作本身的影响和动作导致状态改变的影响,必须要给出一定的界限来区分。再参考汽车之家的数据,该文对正常加速、正常减速、急加速、急减速的判定:加速度a=-1.11 m/s2为正常减速,加速度a=-3.09 m/s2为急减速。加速、急加速的判定:加速度a=1.11 m/s2为正常加速,加速度a=3.09 m/s2为急加速。
状态改变所产生的奖励见表3,天气对速度影响的奖励见表4。考虑现实世界中极端天气对汽车速度的影响,这里也会在加速度后乘以一个折扣因子b,这里的折扣因子会因天气的改变而改变。在由于折扣因子的影响,此时智能体得到的实际加速度a'=动作本身产生的加速度ax折扣因子b。规定晴天时折扣因子b=1,雾天时b=0.95,雨天时b=0.85,雪天时b=0.6。智能体产生其他动作时与其类似。综上所述,方案流程图如图1所示。
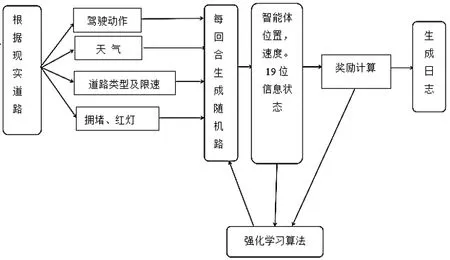
图1 训练环境搭建流程图
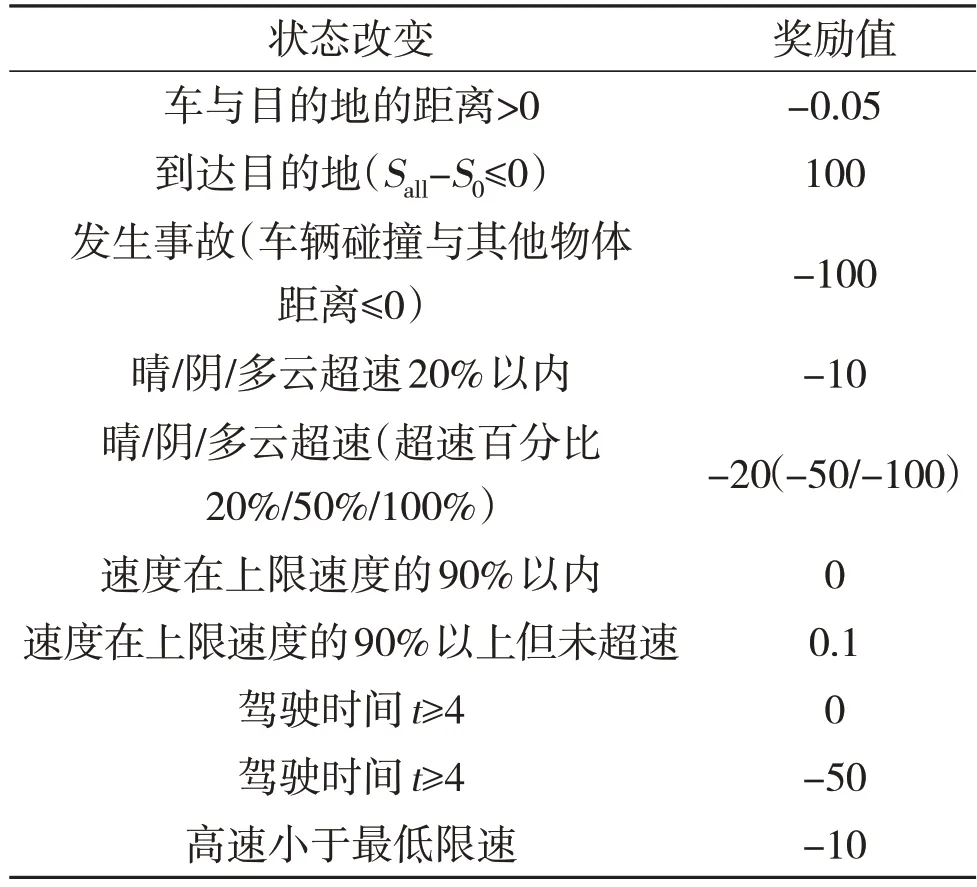
表3 状态改变所产生的奖励
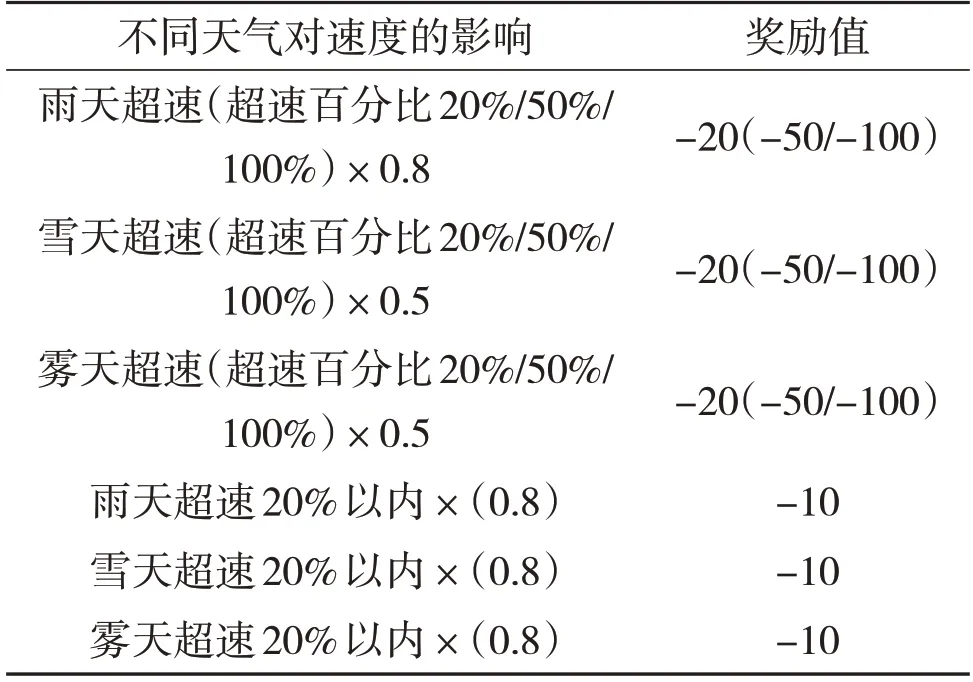
表4 天气对速度影响的奖励
3 环境实现
3.1 基本文件配置
该文在pycharm 中通过python 来实现环境道路天气动作奖励等。建立配置文件,例如道路类型/天气状况/堵车位置/行驶动作等。建立用来随机的产生一种道路类型。生成一个19位的向量,其中天气4位,道路类型9位,红绿灯拥堵1位,总时长1位,疲劳驾驶时长1 位,汽车位置1 位,汽车速度1 位,日夜行驶1 位。该文采用0 或1 来表示无或有,多位向量中其中一位为1,其余则为0来表示。建立一个step,游戏世界的1秒为一帧,计算状态、奖励等。
3.2 奖励的实现
首先要判断智能体是否达到终点,若没到达终点,则给予智能体一个负奖励,其中设置每帧判断智能体是否到达终点,每帧的奖励都进行累加。流程图如图2所示。
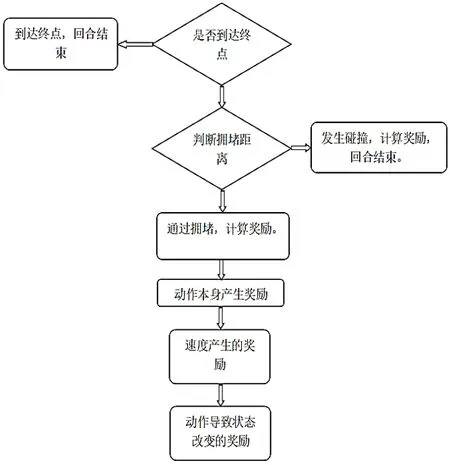
图2 产生奖励的顺序
3.3 环境与智能体的交互
智能体根据当前状态和动作,以每秒为一帧,计算奖励,选出下一动作,作用于环境。环境反馈新的道路、天气、拥堵、日夜等状态。每一帧的动作奖励和动作导致状态奖励都在进行累加。每帧过程不断地重复,直到游戏结束。
4 仿真结果
在该文中,配置了text.py 用来进行测试本环境的搭建是否可用。如图3所示,第一行运行时间为1 s,第三行路长为567 100,进行归一化的位置=智能体当前位置/路总长。速度为9.455 4 km/h。19个状态对应参考该文第3.1节。图4为新一回合的智能体的信息,这里可以看到相较于图1 有较多的改变。图5 为使用强化学习算法DDQN 对该环境进行150 回合训练的结果。在进行了20回合左右,智能体已经能够得到较高的奖励,说明智能体在面对该静态虚拟链路时效果有所提高。

图3 运行1秒时的智能体信息

图4 新一回合的智能体信息
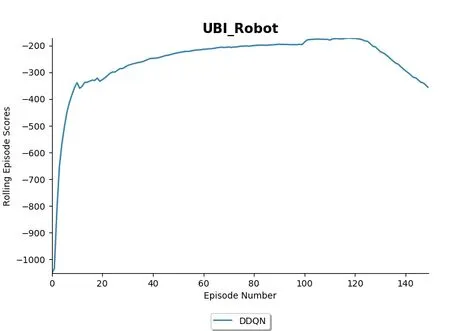
图5 使用DDQN进行训练
5 结语
基于强化学习静态虚拟道路用户驾驶行为的智能体训练环境研究。将现实世界汽车行驶的道路、天气、路况等对用户驾驶的影响考虑到虚拟环境中。使用DDQN 算法对其进行测试,智能体每回合得到的奖励逐步提高,说明搭建的环境以及设置的奖励值可靠有效。
猜你喜欢
当代水产(2022年6期)2022-06-29
当代陕西(2022年4期)2022-04-19
小猕猴学习画刊(2022年3期)2022-03-28
中老年保健(2021年11期)2021-08-22
青年歌声(2020年12期)2020-12-23
小哥白尼·趣味科学画报(2020年4期)2020-10-20
文苑(2020年7期)2020-08-12
汽车观察(2018年12期)2018-12-26
动漫星空(兴趣英语)(2018年9期)2018-10-30
金桥(2018年4期)2018-09-26
