
基于双网络及多尺度判决器的图像修复算法
2022-10-13 09:52李海燕吴自莹李海江李红松
工程科学与技术 2022年5期
李海燕,吴自莹,吴 俊*,李海江,李红松
(1.云南大学 信息学院,云南 昆明 650050;2.云南交通投资建设有限公司,云南 昆明 650050)
现有的图像修复方法主要有两类,基于低级特征的传统修复方法[1]和基于学习的图像修复方法。传统算法通常使用变分算法[2]或补丁相似度[3]将信息从未损坏区域传播到破损区域,这类方法对单一纹理图像的修复效果很好[4],但是修复背景复杂图像时性能急剧下降[5]。为提高对复杂背景图像的修复效果,Simakov等[6]提出了双向补丁相似度修复算法建模背景复杂图像,进而获得较好的修复效果,但该方法需密集计算补丁相似度,因此无法修复高分辨率图像。为了有效修复高分辨率图像,Barnes等[7]提出了Patch-Match快速最邻域算法,当破损区域较小时,该方法能够结合未破损区域的图像信息完成修复,但破损区域增大时,其修复效果急剧下降。Darabi等[8]使用图像梯度集改善高分辨率图像的修复质量,然而该方法依赖于图像的低级特征,修复效果难以令人满意。总之,现有传统方法在处理背景复杂,如色彩多样、人物或风景丰富,或相邻像素间差值较大的图像时,性能急剧下降。
为了解决传统修复方法的不足,学者们探索基于深度学习的修复方法。基于CNN的图像修复方法[9]只能修复破损区域较小的图像,于是Pathak等[10]以重构损失和生成对抗损失为目标函数,训练修复大破损区域的深度神经网络,但是该方法只能修复单一形状的破损区域,修复自然背景、纹理复杂的真实图像时效果不佳。于是Lizuka等[11]在其基础上引入两个GAN损失判决器,用空洞卷积层[12]代替常规的卷积层,使得修复网络捕获更多的图像信息,该方法可以修复任意形状的破损图像,而且能够生成新颖的结构,整体修复效果较好,但是,其修复结果包含细节失真,需后期进行色彩处理,而且该方法修复高分辨率图像时效果较差。随后,Yeh等[13]提出在破损图像的潜在空间中搜索最接近的编码及解码的修复算法,该方法修复高分辨率图像中的小破损区域时效果比文献[11]改善很多,但是,随着破损区域的增大,其修复性能急剧下降。Yang等[14]提出了一种基于图像内容和纹理约束的联合优化多尺度神经补丁合成方法,通过匹配与深度分类中最相似的中层特征相关的补丁来产生高频细节,在修复高分辨率图像时,可得到满意的视觉效果,但是,其优化网络在训练过程中不稳定,容易导致模型崩溃。
综上所述,现有修复复杂背景图像和高分辨率图像的算法面临一些急需解决的问题:首先,修复背景复杂、纹理精细图像时,生成的结构模糊,破损区域边缘会产生重叠或伪影;其次,修复高分辨率图像的细节时,虽然能生成纹理像素,但是整体的语义一致性差,修复图像不贴近真实图像;最后,当数据集采用高分辨率图像训练时,网络不稳定,训练模型容易崩溃。
针对上述问题,本文提出基于双网络及多尺度判决器的图像修复算法。提出内容预测网络和细节修复网络相结合的双生成对抗网络修复结构,破损图像经过内容预测网络进行粗修复,粗修复网络以重构损失和生成对抗损失为标准,比单一以重构损失为修复标准的算法(Generative算法[15]、HR算法[16])生成的结构更清晰合理,修复结果的整体语义一致性更好。双网络将内容预测网络的结果作为细节修复网络的输入,有效减少了需处理的图像信息点,保证了网络训练的稳定性。细节修复网络的3个生成对抗损失基于3个不同尺度的判决器,可以从3个不同尺度区域捕获破损区域的边缘信息,确保修复背景复杂和高分辨率图像时,能生成合理、逼真的纹理细节,提高了修复精确度。
1 基于双网络及多尺度判决器图像修复模型
图1是本文提出算法的修复网络结构图。由图1可知,算法流程为:首先,破损图像经内容预测网络以重构损失和生成对抗损失为标准,进行粗修复;然后,将粗修复结果输入细节修复网络,细节网络中两条平行的卷积路径通过同一解码器和反卷积得到修复结果;最后,将细节网络的结果输入3个不同尺度生成对抗损失的判决器,完善修复细节,提高修复的精度。

图1 修复网络结构图Fig. 1 Inpainting network structure
1.1 空洞卷积网络
图像修复中,因普通卷积层信息感受野有限,因此,研究者们提出了在卷积层中间加入池化层,以增大信息感受野区域[17]。但池化层在降维过程中会丢失图像信息。针对池化层的缺点,本文使用空洞卷积层[18]代替池化层,以期增大修复网络的信息感受野且尽量减少图像信息的丢失,如图2所示。
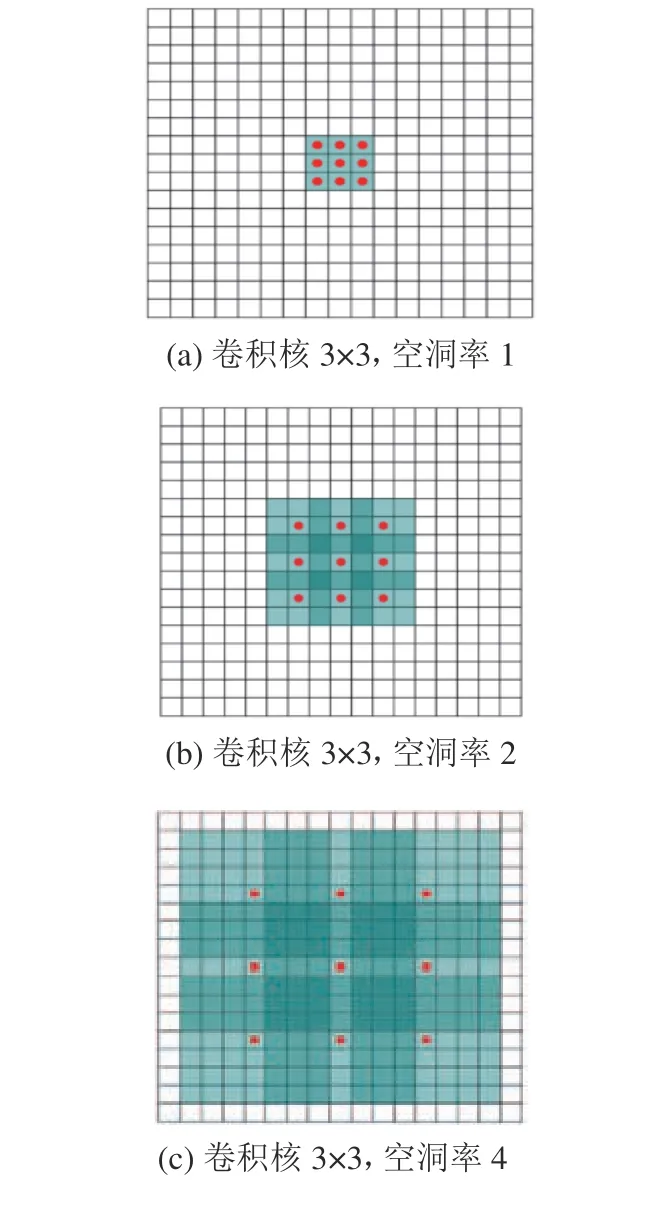
图2 空洞卷积增大信息感受野示意图Fig. 2 Illustration of the enlarged information receptive field of the dilated convolution
图2(a)是卷积核为3×3、空洞率为1的空洞卷积,红色的9个点表示与核卷积的点。图2(b)是卷积核为3×3、空洞率为2的空洞卷积,绿色7×7区域是信息感受野区域。图2(c)是卷积核为3×3、空洞率为4的空洞卷积,其信息感受野达到15×15。相对于传统卷积操作,信息感受野和卷积层数成线性关系,空洞卷积的信息感受野呈指数级增长。因此,用空洞卷积层代替池化层不仅能增加修复网络的信息感受野,还会减少修复过程中图像信息的丢失。
内容预测网络的输入为破损图像,在训练和测试中,用原图加掩码获得。卷积网络用空洞卷积层代替常规卷积层,以捕获更多的图像信息。本文提出算法的创新在于:内容预测网络以重构损失[19]和生成对抗损失[20]为标准进行修复,生成对抗损失基于全局判决器判定内容预测网络的修复结果,若修复结果的语义和纹理结构具有全局一致性,则输出内容预测网络的修复结果至细节修复网络;否则,将信息返回生成器进一步改善结果。学习过程中,生成器G和判决器D相辅相成,判决器D接受G的修复图像和学习样本,试图区分二者;G尝试生成尽可能“真实”的样本混淆D。生成对抗损失表示为:

1.2 内容预测网络
内容预测网络的架构如表1所示,一共5层。

表1 内容预测网络的整体架构Tab. 1 Overall architecture of the content prediction network
内容预测网络中判决器的输入为整幅图像,判决器由6个卷积层和1个完整的连接层组成,可输出单个1 024维向量。所有卷积层采用不大于2×2像素的步幅,降低图像分辨率,同时增加输出滤波器的数量,判决器卷积核为5×5。此外,在内容预测网络中加入了一个全局判决器,用来优化内容预测网络的修复结果,其内部架构如表2所示。全局判决器识别内容预测网络的修复是否完成,以生成对抗损失为标准对全局判别器进行优化。这样既可提高内容预测网络的修复结果,也减小了后续的细节修复网络的修复压力,提高整体的修复质量。
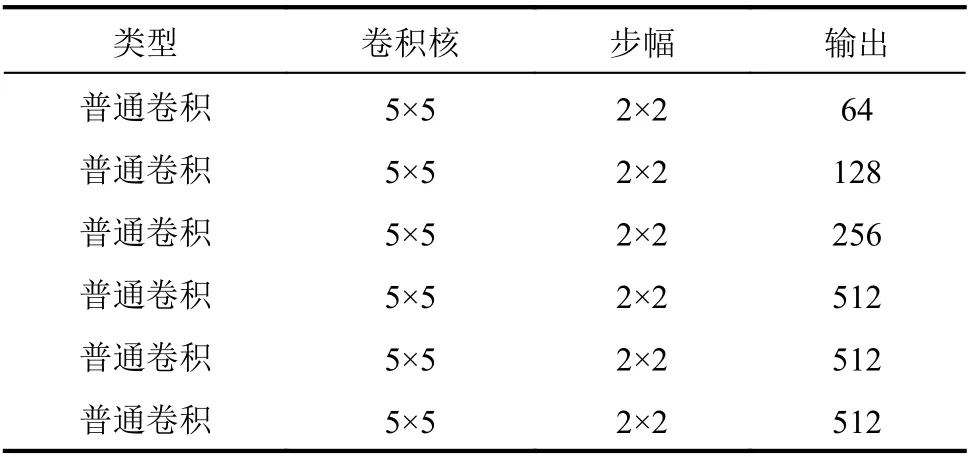
表2 全局判决器的架构Tab. 2 Architecture of the global discriminator
1.3 细节修复网络
细节修复网络的输入是内容预测网络的修复结果,因此细节修复网络卷积层信息感受野比内容预测网络大很多。常规的卷积修复网络,在修复过程中以单一的重构损失作为修复标准,训练时,如果图像信息点复杂,训练迭代次数多,容易因过拟合导致修复效果不理想,甚至会导致整个训练模型的崩溃[10]。本文提出的算法结合重构损失和对抗损失作为修复标准,不仅可提高修复质量,还增加了修复网络的稳定性。为避免修复高分辨率图像时,由于过拟合、梯度爆炸等问题导致崩溃,本文提出的算法用双网络模型,有效减少细节修复网络需要处理的图像信息点,从而减少了网络崩溃的风险,增加了网络的稳定性。细节修复网络以重构损失和3个不同尺度的生成对抗损失为标准进行修复。3个不同尺度的大、中、小尺度判决器的输入分别是以破损区域为中心的128×128、64×64和32×32像素图像块。3个不同尺度判决器的作用与内容预测网络的判决器一样。全局判决器的输入是整张图像,因为输入像素块的大小不同,因此能捕获的图像信息点多,但在训练的过程中,无法处理好每个信息点的语义连贯性,在处理高分辨率图像及图像的细节时该缺点尤为致命。而本文提出的算法可以很好地解决全局判决器的缺陷。其中,虽然小尺度判决器捕获的图像信息少,但能更精准地处理每个信息点的结构及语义信息,从而保证在修复高分辨率图像及图像细节时,有效避免失真。细节修复网络的重构损失定义为:

在细节修复网络中,3个判决器的输出最终由单个完全连接层处理,以输出连续值。使用Sigmoid函数对其进行优化。
1.4 算法流程
本文基于双生成对抗网络及多尺度判决器的图像修复算法的流程为:
1)设置初始参数: β1= 0.001 5, β2=0.001, λ2=λ3=λ4=0.001 5,批量大小为32,内容预测网络迭代次数T1=10 000,细节修复网络迭代次数T2=3 000,共同训练迭代次数T3=100 000。
2)当迭代次数<T1+T2+T3时,进行如下循环:输入图像,并为图像添加随机掩膜生成残缺图像。
3)如果迭代次数<T1,那么使用内容预测网络损失LN更新网络修复参数。
4)否则,使用细节修复网络损失LX更新修复网络参数和各判决器网络参数。
5)如果迭代次数>T1+T2,则使用整个网络损失LSum更新整个修复网络和所有判决器的网络参数。
6)迭代次数加1,并回到2)。
现有单网络结构训练时,训练判决器区分修复图像的“真假”,同时训练修复网络欺骗判决器。由于判决器是基于生成对抗网络的,网络在训练过程中需要同时优化生成器和判决器两个冲突目标,导致训练不太稳定,在处理复杂背景和高分辨率图像时易导致训练模型崩溃。因此,本文提出双网络架构,将内容预测网络的修复结果作为细节修复网络的输入,在内容预测网络引入基于生成对抗网络的全局判决器,减少细节修复网络3个不同尺度的判决器需要处理的图像信息点,从而使训练时模型更加的稳定。与其他的图像修复方法不同,本文提出的方法并不从噪声中生成图像,这也使得训练过程从一开始就更加稳定。
2 实验结果与分析
从公开数据集CelebA[21]、Places2[22]和ImageNet[23]中分别选取300 000张图像训练修复网络,其中,280 000张用于训练,20 000张用于测试。CelebA、Places2和ImageNet数据集分别包括各式各样的人脸图像、风景图像、人物及风景图像,图像分辨率为512×512。训练过程中,批量大小设置为32。对于判决器系数,参考相关文献[24],先确定基本范围,再使用二分法逐步选取最优,设置 β1= 0.001 5, β2=0.001, λ1= 0.001, λ2=λ3= λ4=0.001 5。内容预测和细节修复网络分别迭代10 000次和30 000次后共同训练整个网络100 000次。训练设备参数为:CPU为Intel i7-9700K,GPU为RTX2080Ti-16G,内存为 DDR4-3000-32G,代码在Pytorch深度学习框架下运行。
设计了6组实验验证提出算法的有效性:1)在CelebA和ImageNet数据集上,对比本文提出算法与GLCIC算法[11]、Generative算法[16]、Shift-Net算法[24]和FGC算法[25]的修复效果;2)本文提出算法与现有的双网络结构算法(Generatives算法[16]和HR算法[13])对比第1网络修复结果和第2网络修复结果;3)对比本文提出算法与GLCIC算法[11]、Generative算法[16]、Shift-Net算法[24]和FGC算法[25]的细节修复效果;4)本文算法的目标物移除实验;5)本文算法的消融实验;6)客观对比实验;为保证对比的公平性,在本文的6组实验中所有算法的迭代次数相同。
2.1 不同数据集上各算法的修复结果
图3是在CelebA数据集上将本文提出算法与GLCIC算法[11]、Generative算法[16]、Shift-Net算法[24]和FGC算法[25]对背景简单的人脸图像修复的结果对比,掩膜覆盖了眼睛的大部分区域。从图3中可看出:GLCIC算法的修复结果,两个判决器保证了图像整体语义的一致性,但眉毛处的修复出现扭曲,部分像素点重叠。Generative算法的修复结果生成的图像结构纹理清晰合理,但眼球处的细节修复差。Shift-Net算法的修复结果在眼睛与眉毛的连接处,出现了纹理错乱,无法生成合理的眼球结构。FGC算法的修复结果能生成合理的结构,纹理较清晰。本文提出算法的修复结果的结构纹理与原图相似度高,眼球处的修复较对比算法更加符合语义,纹理更清晰。
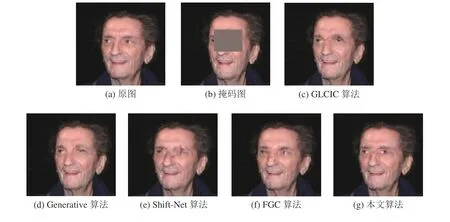
图3 CelebA 人脸数据集上各算法的修复结果Fig. 3 Repair results of each algorithm on the CelebA face dataset
图4是在ImageNet数据集上将本文提出算法与GLCIC算法[11]、Generative算法[16]、Shift-Net算法[24]和FGC算法[25]对背景复杂且包含较多纹理细节的风景图像修复的对比结果,缺失区域包含背景及前景的较多纹理细节。从图4可看出:GLCIC算法生成的结构无法与周围未破损区域保持视觉连贯性,部分像素点发生重叠。Generative算法在屋顶处的修复结构纹理较GLCIC算法有一定的改善,但由于判决器尺度过大,结合未破损区域生成了多余结构。Shift-Net算法修复背景复杂图片时很难生成合理的结构。FGC算法生成的结构较合理,但细节纹理模糊。本文提出算法能生成合理的结构和纹理,无边缘模糊和重影,语义与原图相符,修复效果较好。

图4 ImageNet 数据集上各算法的修复结果Fig. 4 Repair results of each algorithm on the ImageNet data set
从图3、4对不同数据集的修复结果对比看出:本文提出算法不仅能生成合理的结构纹理,细节的结构、纹理、像素也清晰合理,优于对比算法。
2.2 双网络结构算法修复对比
图5是本文提出算法与现有的双转移网络结构算法Generatives算法[16]和HR算法[13]在Places2数据集上修复背景复杂的自然图像的对比,图5中,给出了每种算法第1、2网络修复结果。从图5中可看出:对于第1网络修复结果,Generative算法的修复结果无明显结构信息,HR算法生成了部分内容,本文提出算法生成了基本的结构信息。对于第2阶段网络的修复结果,Generative算法和HR算法的修复结果部分结构错乱,纹理扭曲,像素点重叠。相对而言,本文提出算法的修复结果整体结构及纹理与原图基本一致,细节纹理无明显错乱,图像的整体语义一致性高。

图5 各算法双网络的修复结果Fig. 5 Repair results of the double network of each algorithm
2.3 高分辨率图像细节修复对比
图6是在ImageNet数据集上将本文提出算法与GLCIC算法[11]、Generative算法[16]、Shift-Net算法[24]和FGC算法[25]对纹理细节丰富的高分辨率图像修复的结果对比。从图6中可看出:GLICIC算法能生成基本合理的结构,全局判决器保证了图像整体语义的一致性,但其局部判决器无法修复桥上绳索的细节。Generative算法能生成合理结构和清晰纹理,但由于绳索缺失信息多,部分绳索区域只能结合周围像素错误地生成为水域结构。Shift-Net算法能生成基本合理的结构,但绳索的修复结构出现扭曲。FGC算法生成的结构错乱,纹理模糊。本文提出算法由于使用了3个不同尺度的判决器,能够很好地结合破损区域周围的语义,有效避免修复过程中出现的细节失真,因此生成的结构纹理合理清晰,而且细节语义与原图高度一致。

图6 各算法的高分辨率图像修复结果Fig. 6 Results of high-resolution image restoration of each algorithm
2.4 目标物移除
图7为本文提出算法ImageNet数据集上目标物移除的实验结果。从图7中可看出:本文提出算法可在移除的目标物处生成与周围语义一致的结构信息,3个不同尺度的判决器保证修复的细节纹理一致性。

图7 本文算法的目标移除结果Fig. 7 Results of target removal by the proposed algorithm in this paper
2.5 消融实验
图8是本文提出算法在ImageNet数据集上的消融实验的效果图。从图8的修复效果可以看出:本文提出算法的内容预测网络增加了全局判决器,能改善内容预测网络的修复结果;本文提出算法的细节修复网络增加3个不同尺度的判决器,使修复图像的细节更清晰合理。消融实验验证了本文提出算法的有效性和优越性。

图8 本文算法的消融实验结果Fig. 8 Ablation experiment results of the proposed algorithm in this paper
2.6 客观实验对比
由表3的实验结果可知:本文提出算法的4种定量客观指标优于对比的其他算法,说明本文提出算法能很好地结合图像的整体语义,增强图像细节的修复精度,有效避免结构纹理错乱、像素重叠、边界扭曲等问题。

表3 峰值信噪比、结构相似度等客观指标的定量实验对比Tab. 3 Objective indices comparison of PSNR and structure similarity
3 结 论
提出了一种基于双生成对抗网络及多尺度判决器图像修复算法。内容预测网络引入基于生成对抗损失的全局判决器,保证修复图像整体语义的一致性。将内容预测网络的修复结果作为细节修复网络的输入,扩大了细节修复网络的信息感受野。3个不同尺度的判决器保证细节修复的精度,有效避免结构纹理错乱以及色彩像素重叠等缺陷。修复实验、双网络修复对比、高分辨率修复对比、目标移除实验、消融实验及客观实验结果表明:本文算法能很好地结合图像的整体语义,增强图像细节的修复精度,有效避免结构纹理错乱、像素重叠、边界扭曲等问题。当然,由于使用多个基于生成对抗损失的判决器,因此训练时间较长,需5天左右,这是后续需要改进之处。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
天津医科大学学报(2021年2期)2021-03-29
健康体检与管理(2021年10期)2021-01-03
软件(2020年3期)2020-04-20
保健与生活(2019年7期)2019-07-31
电子制作(2019年11期)2019-07-04
Coco薇(2017年8期)2017-08-03
计算机应用(2016年10期)2017-05-12
