
基于异常识别与有损压缩的无线AP数仓构建方法
2022-10-19 13:02李明春刘世超
光通信研究 2022年5期
李 明,李明春,刘世超
(烽火通信科技股份有限公司,武汉 430074)
0 引 言
近年来,随着第五代移动通信技术(5th Generation Mobile Communication Technology,5G)的普及以及网络带宽的不断发展,无线访问接入点[1](Access Point,AP)设备产生的物联网[2](Internet of Things,IoT)数据呈现惊人的增长趋势,而传统的IoT管理平台数据分析模块面对如此大量的接入数据,相应数据分析时长的增加,成了当前必须要解决的首要任务,引入大数据[3]流式计算和离线计算后很好地解决了数据处理时数据量过大的难题,但是面对较高频率的上送数据持久化存储成本以及相关数据仓库[4]的建设成本也亟需解决。
IoT数据的一大特性就是数据重复,比如100万台设备5 min上送一次数据,每天即可产生几百Gbit的数据,而这些数据中包含了大量的重复数据,数据的全部收录将会增加企业的网络传输成本以及数据仓库构建成本,如果将所有数据收录至数据仓库,再构建不同层次的数仓,数据量又会呈现出翻倍增长的情况,庞大的数据量对于数据分析和异常识别[5]等造成计算资源的浪费以及数据处理时效性的降低。
基于原有IoT平台对于无线AP的设备接入、设备管理、数据流转以及数据分析,本文提出了基于异常识别与有损压缩的无线AP数仓构建方法,使用了一种有损压缩[6-7]方法,对于无线AP传输的IoT数据可以通过流式计算以及基于K-means聚类算法[8-9]的异常识别方式进行有损数据压缩,主要处理设备运行中存在的较多重复数据且数据存储精度要求不高,比如信号强度和带宽等。通过以信号强度为例的具体实验验证了本文所提方法的可行性,弥补了现有无线AP数据构建数仓解决方案中的数据量过大的问题。
1 AP数据接入处理数仓构建
IoT技术目前在各行各业已经逐渐落地实践,其产生的社会经济效益也越来越明显,IoT平台是一个集成了设备管理、数据安全通信和消息订阅等能力的一体化平台。向下支持连接海量设备。基于AP设备的IoT平台实现了对AP设备的管理、连接管理和数据分析等一系列功能,同时在大数据的支持下实现对海量数据的采集、处理、挖掘和展示。
数据仓库主要功能是将组织透过资讯系统之联机事务处理(On-Line Transaction Processing,OLTP)经年累月所累积的大量资料,透过数据仓库理论所特有的资料储存架构,系统地分析整理,以利于进行各种分析如联机分析处理(On-Line Analytical Processing,OLAP)和数据挖掘(Data Mining),帮助决策者能快速有效地从大量资料中分析出有价值的资讯,以利决策拟定及快速回应外在环境变动。
为充分有效利用无线AP数据,本文在IoT设备连接的基础上设计了数据采集[10]、数据处理和数仓实现数据整体架构,如图1所示,主要由消息中间件、HDFS、实时计算和离线计算等组件构成。本文中实现的无线AP数据数仓分层主要分为:数据缓存层、数据近源层、公共明细层、公共汇总层和数据应用层。无线AP IoT数据经由IoT平台的设备连接至消息队列,集成至缓存层进行数据压缩后进入操作数据 (Operation Data Store,ODS)层;明细数据 (Data Warehouse Details,DWD)层负责转码/清洗,异常&缺失值处理,计算加工逻辑,按业务过程分表;业务数据 (Data Warehouse Service,DWS)基于业务需求的原始粒度明细事实的整合汇总,采用一致性维度建模;应用数据服务 (Application Data Service,ADS)层面向业务需求的应用模型,基于应用进行数据组装,定制化,提供数据应用。
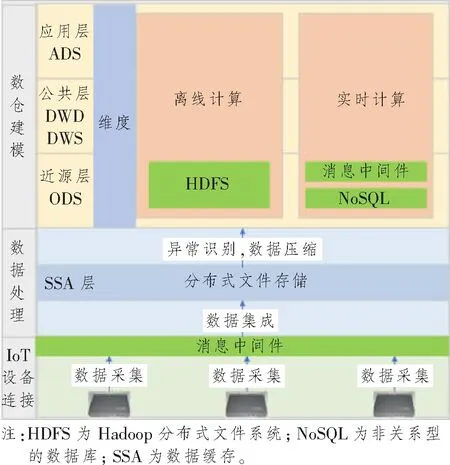
图1 数据采集处理和数仓实现整体架构图Figure 1 The overall architecture diagram of data acquisition and processing and data warehouse realization
2 数据处理策略
为提高处理AP设备上送数据的实时性,本文设计了基于flume的数据集成方式,采用Spark Streaming的window以及Spark Ml来实现数据的异常识别以及正常数据基于窗口数据均值的有损压缩技术,该过程主要包括数据集成、数据异常识别、数据压缩和持久化存储模块。
2.1 数据压缩
本方案在SSA中实现网络设备数据压缩;基于K-means算法与先验知识结合的方式, 基于数据是否异常制定数据下发方案。正常数据时,采集的设备数据处于平稳变化,取当前窗口平均值下发;异常数据时,异常数据点前后1 min数据根据媒体存取控制(Media Access Control,MAC)和时间字段去重后下发;该方案主要处理设备运行中存在较多重复数据的指标,且该指标数据存储精度要求不高,本文以信号强度数据为例。具体的实现过程如图2所示。
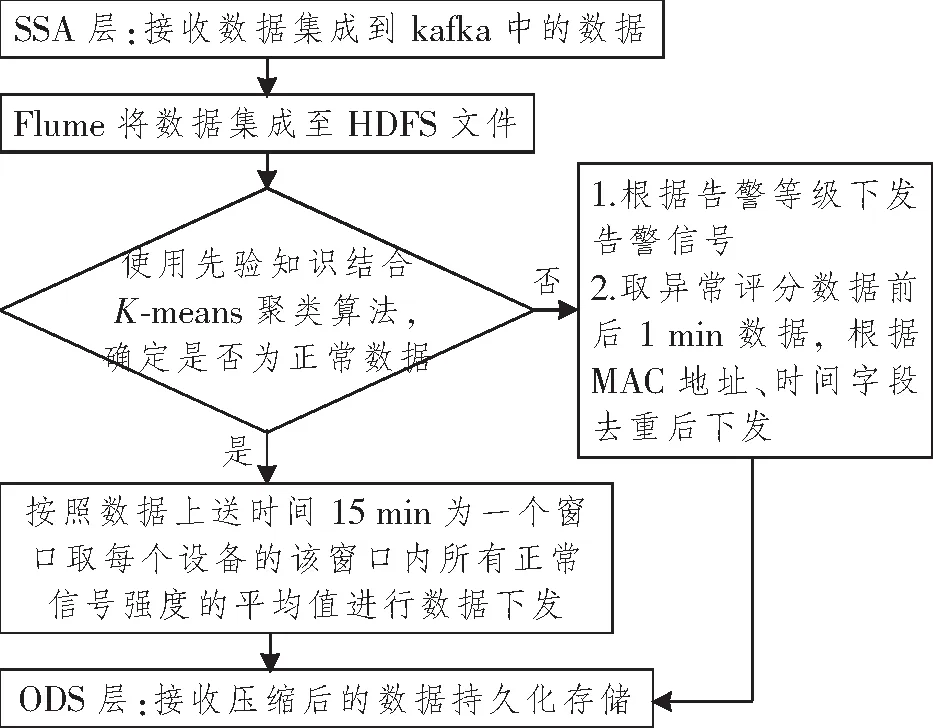
图2 信号强度RSSI数据处理过程Figure 2 The scheme of signal strength RSSI data processing
数据压缩过程主要包含4部分内容:
(1) 数据集成:在缓存层将终端设备上送数据集成至HDFS中,用于构建模型以及异常识别测试。数据集成使用flume组件实时采集kafka消息队列中的接收信号强度指示(Received Signal Strength Indicator,RSSI),同步至HDFS中。
(2) 异常数据识别:基于先验知识以及专家知识库中获得异常数据样本取样,使用Spark ML构建K-means模型对上送数据进行聚类分析,结合取样异常数据进行综合判断。
(3) 有损压缩:数据识别为异常后,取异常评分数据前后1 min的数据,根据MAC地址和时间字段去重后进行下发,同时将异常数据告警信号下发;正常数据取15 min窗口中每个设备正常值的平均值下发。
(4) 持久化存储:有损压缩后的数据持久化存储至近源层中,为后面的数据分析提供数据源。
2.2 先验知识结合K-means聚类算法识别异常
经由flume同步至HDFS中的数据,需要经过有损压缩后进入ODS层进行数据持久化存储以及数据规范管理。本文在异常识别中,为了使识别结果更加准确,通过参考异常生成器结合K-means聚类算法的方式构建了异常识别算法。上送信号强度RSSI字段经归一化处理后形成特征字段,K-means聚类算法将特征字段聚类后取异常数据在redis中进行缓存,通过与参考异常生成器数据进行比对,若异常数据超过参考异常生成器数据中的异常值,则认定该数据为异常,根据异常数据数值范围发送相应告警信号,截取数据前后1 min数据进行数据下发;若数据值不超过参考异常生成器中的最低异常值,则认定聚类中无异常数据,从redis中将该数据删除,同时取窗口数据平均值进行下发。
参考异常生成器:为了增加异常数据识别的准确度以及增加丢包判断标准,使用该模块生成参考异常值。设μR为参考异常,定义为l个正常样本异常分数{r1,r2,…,rl}的均值,采用先验方式获取此值:
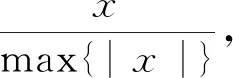
K-means异常识别模型:K-means算法的思想如下:对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密地连在一起,而让簇间距离尽量大。K-means算法使用距离来描述两个数据对象之间的相似度。距离函数有明式距离、欧氏距离、马式距离和兰氏距离,最常用的是欧氏距离。K-means算法是当准则函数达到最优或者达到最大的迭代次数时即可终止。当采用欧氏距离时,如果用数据表达式表示,假设簇划分为(c1,c2,…,ck),则我们的目标是最小化平方误差E,
式中:k为簇的个数;ci为第i个簇的中心点;dist(ci,x)为x到ci的距离。
3 实 验
3.1 实验环境与评价指标
实验用通用路由器一台,通用智能手机一部,实验代码在Spark集群中运行,集群配置为3台Intel(R) Xeon(R) Gold 5120 CPU @ 2.20 GHzcpu,16 G内存服务器,操作系统为CentOS7.9。对于K-means聚类算法,K值选取采用误差平方和 (Sum of Squares due to Error,SSE)评价指标进行评价。采用压缩后的文件大小与原文件大小比值的形式来进行压缩率的评价。
3.2 实验数据集
为验证本文算法的有效性,将连接有一台终端设备的无线AP接入IoT平台进行实际验证,终端上送数据为每秒1条,通过IoT平台收集终端上送数据,其中正常样本为设备在无线AP附近获取,通过移动设备增加设备与无线AP的距离,实现异常样本的采集。采集3 h数据,每小时数据为一组,将数据分为3组进行实验,每组数据样本总数均为3 600条,保证每小时数据中都包含了异常数据以及正常上送数据。如表1所示,其中第1小时数据异常样本数为23条,正常样本数为3 577条;第2小时数据异常样本数为106条,正常样本数为3 494条;第3小时(训练数据集)异常样本数为129条,正常样本数为3 471条。

表1 终端上送数据集
3.3 K值实验
在Spark集群中对训练数据进行归一化处理后运行K-means聚类程序,对K值采用实验的方式获取,通过不断调整K值大小,得到在不同K值下的最小化平方误差E,E越小说明聚类效果越好,实验结果如图3所示。
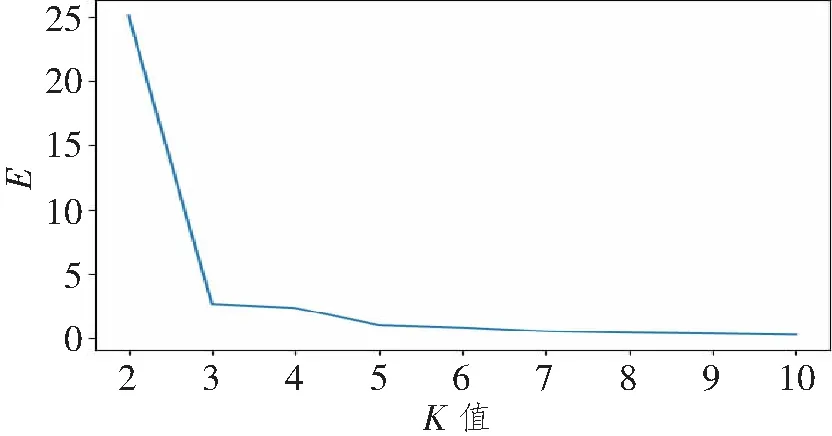
图3 K值大小与E的趋势图Figure 3 The value of K and the trend chart of E
结果表明,K=3时,E逐渐平滑,根据拐点法确认K=3时,可以作为聚类时的参数,聚类中心的选择使用“K-means||”方式。
3.4 综合判断
经参考异常生成器获得差信号强度为-80 dBm,很差信号强度为-90 dBm。基于聚类结果与参考异常生成器综合判断逻辑如图4所示。经过K-means模型与参考异常生成器综合判断训练数据集中的异常检测结果如表2所示。
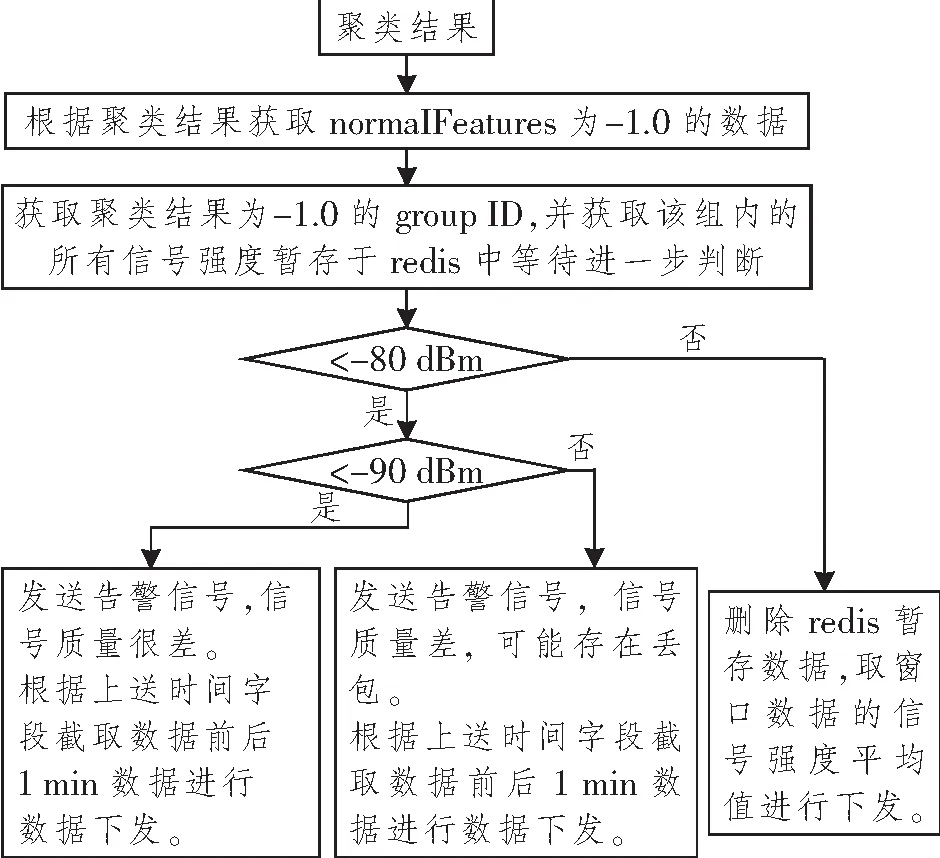
图4 基于聚类结果与参考异常生成器综合判断逻辑Figure 4 Comprehensive judgment logic based on clustering results and reference exception generator

表2 异常检测结果
其中划分为异常数据组,但是不满足信号强度≤-80 dBm的数据有6条,基于K=3的K-means聚类算法实现的判断准确率为95.6%。同样对另外两个测试数据集进行相同处理,异常检测结果如表3所示。

表3 异常检测结果
在测试数据集中,两个数据集的识别率分别为99%和85%。根据综合判断,将该异常识别错误的数据从redis中剔除,在本窗口中,根据综合判断的异常数据取时间字段,对异常数据前后1 min的数据进行抽取,同时根据MAC以及时间字段去重后下发。
3.5 数据压缩率
实验测试过程中,测试数据集1的数据时间区间为2022-02-20 15∶33∶00~ 2022-02-20 16∶32∶59,测试数据集2的数据时间区间为2022-02-20 16∶33∶00~ 2022-02-20 17∶32∶59。其中测试数据集1的异常数据起始点为2022-02-20 16∶05∶02~ 2022-02-20 16∶06∶47,测试数据集2的异常数据起始点为2022-02-20 17∶23∶37~ 2022-02-20 17∶23∶59。程序基于图4的一场判别有损压缩逻辑,最终取得测试数据集1和测试数据集2的有损压缩数据总条数分别为229和149条。详细数据比对如表4所示。
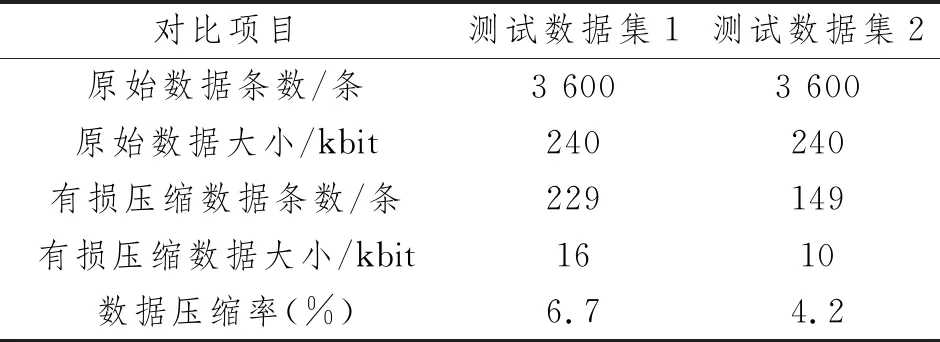
表4 数据压缩对比
通过两组测试数据与原始数据的对比,表明本文方案可以在保证识别异常数据、保留异常数据细节动作的同时,很好地降低无线AP重复性上送数据的存储占用空间,可以大大降低用户的存储成本。
4 结束语
为了降低无线AP数据的数仓实现成本,本文提出了基于缓存层实现网络设备数据压缩的方法,设计了结合流式计算和异常识别决策数据下发框架,根据无线AP上送数据的特点,结合机器学习和流式计算,通过对信号强度的实际实验,验证了本文方法的可行性以及经济性。本文所提方法同样可以用于其他IoT领域,如电力终端、智慧家庭和智慧工业等领域,以降低IoT设备的数仓构建和数据存储成本,同时对于异常数据的识别提供了一种很好的办法。当然,对于方法中单一特征值也可以进行相应的扩充,比如信号强度字段与丢包率和网速结合形成多特征的聚类能够更好地识别异常。
猜你喜欢
中华眼视光学与视觉科学杂志(2022年8期)2022-08-17
电子科技大学学报(2022年4期)2022-07-15
中成药(2022年1期)2022-01-27
湖南林业科技(2021年3期)2021-12-02
甘蔗糖业(2021年4期)2021-09-26
土壤(2020年2期)2020-06-15
科学与财富(2018年30期)2018-12-28
计算机应用(2016年9期)2016-11-01
体育科技(2016年2期)2016-02-28
科技资讯(2015年19期)2015-10-09
