
基于混合模型的利润驱动违约判别临界点研究
2022-10-20 12:42迟国泰董冰洁
运筹与管理 2022年9期
迟国泰, 董冰洁
(大连理工大学 经济管理学院,辽宁 大连 116024)
0 引言
违约判别临界点,即金融机构是否接受客户贷款申请并放款的决策参考。违约判别临界点C的取值不同会直接导致违约客户被错误的划分为非违约客户(第二类错误)[1]。第二类错误下的贷款成为金融机构不良贷款的重要来源。
根据央行公布的数据,2019年第二季度我国信用卡逾期未偿还金额达到的800亿元,相较2010年的76.86亿元,约增长10.4倍。互联网公开数据显示:平安金融机构财报显示2020年3月末个人贷款不良率1.52%,较去年末增长0.33个百分点,其中信用卡不良率增长幅度最大达2.32%,比2019年末增加0.66%。如何找到合适的违约判别临界点,最大限度减少第二类错误造成的损失,对实现贷款利润对于减少金融机构不良贷款损失实现稳健经营具有重要意义。
利润驱动违约判别临界点的研究涉及以下两个问题:
一是如何保证客户违约概率估算的整体准确性。如果估算出违约客户的违约概率和非违约客户的违约概率均是0.5,那么无论违约判别临界点取何值,金融机构都无法准确鉴别出违约客户和非违约客户。只有当计算出违约客户的违约概率尽可能大,非违约客户的违约概率尽可能小时,也即金融机构能保证估算客户违约概率准确性时,金融机构通过设置违约判别临界点来决定是否接收贷款申请的决策才具有意义。因此如何保证客户违约概率估算的准确性成为违约判别临界选择过程中需要解决的关键性问题。
二是如何找到利润驱动的违约判别临界点。在保证客户违约概率估算准确的前提下,如果违约临界点设置过高,意味着客户即使有很大的违约可能性,仍然会被判为非违约客户,被接受放款,金融机构此时极可能将一个违约的客户“错放”(第二类错误),此时金融机构面临利息和本金损失的可能性增加。在本研究中,假定违约的损失为利息核本金一起损失,即最坏情况下的损失。所以,第二类错误下的本金和利息损失对金融机构的影响远大于将非违约客户判断正确带来的利息收益。所以,如何找出实现贷款利润最大化的违约判别临界点是一个具有挑战性的问题。
因此想要研究利润驱动的违约判别临界点问题就一定会涉及到客户违约概率的估算问题和利润最大化临界点的选取问题。
本研究与已有研究的区别之处在于:
一是估算客户违约概率的方法不同。相较于当前流行的单一模型方法计算客户违约概率[2~9],本研究将多种不同类型的模型加权平均计算客户违约概率,避免使用单一模型计算违约概率准确性不高的弊端。
二是求解违约判别临界点的方法不同。与经验似然法和广义对称点估计[10~12]等以寻找整体判对率最大的违约判别临界点的方法不同,本文以贷款利润最大为目标,求解违约判别临界点。避免现有方法仅能得到总体准确率最大违约判别临界点而不是获取利润最大的违约判别临界点(总体准确率最大的违约判别临界点,并不能代表金融机构能从贷款中获利或者获得最大利润,因为判断正确带来的收入远小于判断错误带来的损失)的弊端。
研究发现:(1)在估算客户违约概率的方法上,本文提出的混合模型计算的客户违约概率比单一模型计算的违约概率要准确,混合模型有更大的AUC值。(2)在人人贷数据集1和人人贷数据集2中计算的利润驱动违约判别临界点分别为0.1887和0.2219,实际利润分别为0.001283百万元和2.8228337百万元,高于广义对称点估计和经验似然法等方法计算的违约判别临界点所得的实际利润。(3)通过构造虚拟数据集进行对比分析表明,一个准确性高的模型有助于缓解违约判别临界点选取不合适造成的损失。
1 文献综述
1.1 计算违约概率的方法研究
计算客户违约概率分为两类:一类是统计模型:逻辑回归模型、有序逻辑回归模型、门限回归模型、生存分析模型。另一类是基于机器学习的模型,如神经网络、决策树、支持向量机等模型。如,Jabeur构造了成本敏感决策树模型信用评价模型[2]。新近的研究中,将多个机器学习模型的结果以投票的方式集成,如Xia、Monika通过多个决策树构建随机森林信用评价模型[3~4]。
综上,当前研究中估算客户违约概率的方法主要还是使用单一模型来估算客户的违约概率,已有研究表明当使用多个相同的模型构建集成模型时,集成模型的准确性高于单一模型的准确性[4]。本文借鉴集成模型的思想,使用多种不同类型的模型计算客户违约概率,通过先加权再平均的方法构成混合模型,以此来保证计算客户违约概率的准确性,避免使用单一模型计算客户违约概率不准确的弊端。
1.2 判别临界点的研究
判别临界点是判别客户违约状态的重要依据,求取判别临界点的方法有约登指数、广义对称点估计以及经验似然法等统计方法。约登指数(Lai)是找到一个临界点能最大区分违约客户和非违约客户,计算方法是第一类错误率和第二类错误率相加再减1[5],即为最优临界点;经验似然法(Molanes)和广义对称点估计(Lopezraton)通过参数估计的方法寻找能最大区分违约客户和非违约客户的临界点,但是两种方法适用的数据不同,经验似然法适用数据是正态分布的情况,广义对称点计估则对数据的分布没有要求[6,7]。此外,还有Zhang根据违约判别模型的准确性最大反推出区分违约客户和非违约客户的最佳分类临界点[8];Tomczak依据违约判别模型的G-means最大来找区分违约和非违约客户的临界点[9]。Perols基于最小化判错成本估算了最优临界点[10]。
综上,当前研究主要是以整体准确率最大来寻找违约判别临界点,即找到一个临界点,这个临界点能最大程度的鉴别违约客户和非违约客户。但少有研究关注到整体判别准确度最大的违约判别临界点带来的利润是否最大,因为无论临界点选取为什么值都会出现将违约客户错判为非违约的情况,此时造成的本金和利息的损失远大于将非违约客户判断正确带来利息收入,因此考虑利润驱动下的违约判别临界点更具有现实意义。
2 利润驱动的违约判别临界点计算
2.1 混合模型的构建
构建本文混合模型的子模型有逻辑回归模型、朴素贝叶斯模型和支持向量机模型。选用这三个模型的原因是,逻辑回归模型作为经典的统计模型在信贷决策领域得到广泛的应用,朴素贝叶斯模型和线性支持向量机模型作为常见的机器学习模型在分类预测方面具有良好的性能。
本文构建的混合均值是由多个不同类型的子模型先加权集成,再取平均集成得到。第一次多模型加权,设:f(yi)为3个子模型加权后的概率,Pij表示第i个子模型计算的客户j的违约概率,aij是子模型的加权系数,第一次集成的客户j的违约概率如式(1)所示:
(1)
加权系数aij可以在训练集数据中通过子模型计算的违约概率与客户真实违约状态构建线性方程使用极大似然估计法求取,β是常数项。
第二次多模型取平均。pmix(j)是混合模型计算的第j个客户违约的概率,n取值分别1,2,3表示逻辑回归子模型、朴素贝叶斯子模型和线性支持向量机子模型,f(yi)为子模型加权后的概率,混合模型计算的第j个客户的违约概率如式(2)所示:
(2)
式子(2)含义是通过多模型的加权概率来修正不同违约判别子模型计算的同一个客户违约概率的偏差。
本文混合模型与已有研究[8]的不同之处在于,将多种不同类的模型结果进行加权再平均的方式,来获得一个准确性更高的模型,以此来保证计算客户违约概率的准确性,避免单一模型计算客户违约概率不准确的弊端。
2.2 利润驱动的违约判别临界点求取
2.2.1 计算特定违约判别临界点C1下金融机构的贷款利润
在特定违约判别临界点C1下,金融机构把违约客户判为非违约予以放款时,金融机构有实际损失(记为AL),即本金和利息。由于不同客户的真实贷款损失难以结算,在本研究中,违约的损失为利息核本金一起损失,即最坏情况下的损失。当金融机构能把非违约客户鉴别出来并予以放款时,金融机构获得实际收入(记为AI),即贷款利息。w表示在特定违约判别临界点C1下的实际利润。当金融机构为某一数量群体(N个客户的群体)贷款时,在某个特定的违约判别临界点C1下,金融机构面临的收入、损失和利润计算如式(3)、式(4)、式(5)所示:
(3)
(4)
w=AI-AL
(5)
其中,客户向金融机构申请贷款时提供贷款金额(记为M,单位元)和贷款期限(记为T,单位月)数据,利息率 (记为r)。在特定违约判别临界点C1下,实际非违约客户被正确判定为非违约的个数(记为n1)、实际违约客户被错误判定为非违约的个数(记为n2)。
与现有研究的区别:本节给出了金融机构在特定违约判别临界点C1下所面临的收入、损失和利润的计算方法。本节与已有研究的区别在于,当前研究仅仅关注到第二类错误的大小,而本文不仅关注到第二类错误的大小,同时量化了第二类错误下的成本,以及在特定违约判别临界点下的收益。
2.2.2 求解利润驱动的违约判别临界点
根据3.2.1中,实际收入(AI)、实际损失(AL)以及贷款实际利润w计算公式。设:基于混合模型的利润最大违约判别临界点规划模型如式(6)所示:
(6)
需要说明的是,首先使用训练集数据建立混合模型,并使用混合模型计算训练集中客户的违约概率,并求取训练集中利润最大化的临界点C*。在利润最大的临界点C*下预测新客户(测试集中客户)的违约状态并决定是否给新客户贷款。
与现有研究的区别:已有研究只关注到在特定违约判别临界点下第二类错误的大小,而本文不仅关注到第二类错误的大小,同时以利润最大为目标求解最优违约判别临界点,同时避免现有方法,如经验似然法和广义对称点估计等方法计算的临界点不是贷款利润最大化违约判别临界点的弊端。
2.3 违约判别模型的评价指标
本文涉及到的模型评价指标主要有第二类错误(Type-II Error)、负元覆盖率(NCR),AUC值。原因在于贷款损失主要来自第二类错误,贷款收入主要来自于金融机构能准确判别多少非违约的客户,因此使用第二类错误(Type-II Error)和负元覆盖率(NCR)来衡量模型的预测能力。此外选用AUC来衡量模型的整体准确性,因为AUC值不受临界点取值的影响,能客观的反映模型整体的准确性。
3 实证分析
3.1 数据说明
本文实证数据为人人贷贷款数据,每笔贷款数据包括学历、婚姻状况、收入水平、贷款金额、贷款利率、贷款时间、是否违约等36个维度的数据。本文使用的数据集从人人贷贷款数据中抽样获得。由于后文中要计算实际收入、实际损失和贷款实际利润,因此需要保证数据集中的客户借款金额大致相等。
数据集1的抽样方式如下:首先抽取借款金额在1万元(不包含)以下的全部违约样本608个样本;其次,再从借款金额在1万元(不包含)以下的非违约样本中随机抽取608个样本,组成一个共1216个样本的平衡数据集,记为数据集1。
数据集2的抽样方式如下:首先抽取借款金额在1~5万元(包含1万和5万)的全部违约样本2827个样本;其次,再从借款金额在1~5万元(包含1万和5万)的非违约样本中随机抽取2827个样本,组成一个共5654个样本的平衡数据集,记为数据集2。
借鉴柳向东和陈林的研究,本研究选择年龄、性别、学历、婚姻状况、收入水平、房产情况、房贷情况、车产情况、车贷情况、工作性质、工作时间、手机认证、学历认证、居住地认证、信用报告、职称认证和投资人数等17个变量建立模型[11,12]。本文使用的17个变量中有年龄和投资人数两个变量是连续型变量,剩余15个变量为分类变量。分类变量使用了独热编码处理,将分类变量转换成数值变量,并对数据数据进行了01标准化处理。
3.2 使用混合模型计算训练集客户违约概率
以数据集2为例说明混合模型的建立过程。从数据集2中随机抽取80%的数据作为训练集,根据3.1中方法分别建立分别建立逻辑回归、朴素贝叶斯和支持向量机3个违约判别子模型。客户真实状态为y,子模型计算的违约概率为x,建立逻辑回归方程,使用极大似然估计法估计式(1)中3个子模型的混合权重系数。再根据式(2)计算训练集中各客户的违约概率,结果如表1所示。
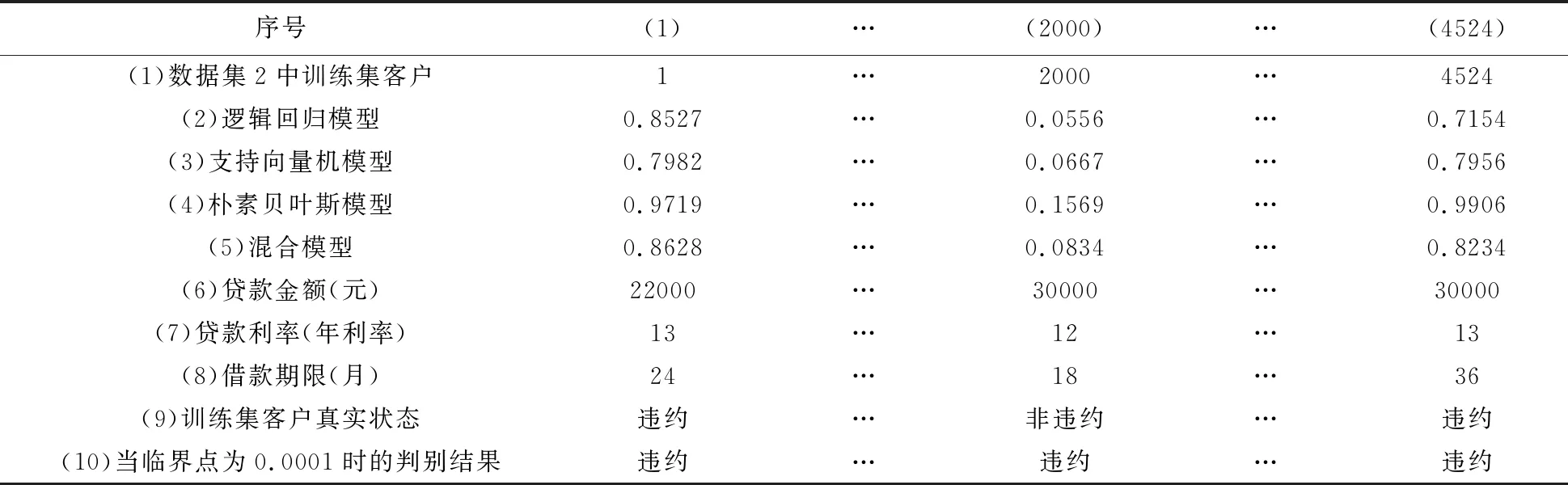
表1 混合模型计算的数据集2中训练集客户违约概率
3.4 求取利润驱动的违约判别临界点
以3.2中预测的客户违约概率为例(见表1),当选取违约判别临界点为0.0001的情况说明实际收入、实际损失以及实际利润的计算。在特定违约判别临界点C1下计算实际收入(AI)、实际损失(AL),当改变违约判别临界点C的取值时,金融机构在所有可能的违约临界点取值下实际利润和经济利润的结果如表2所示,当违约判别临界点的取值为0.5000时,负元覆盖率为0.7439表明测试样本中74%的非违约客户被识别出来,第二类错误为0.0844表明测试样本中只有约8%的违约样本没有被识别出来,此时识别出非违约客户带来的实际收入为14.8871百万元,没有识别出违约客户带来的实际损失为5.6033百万元,实际利润为9.2838百万元。
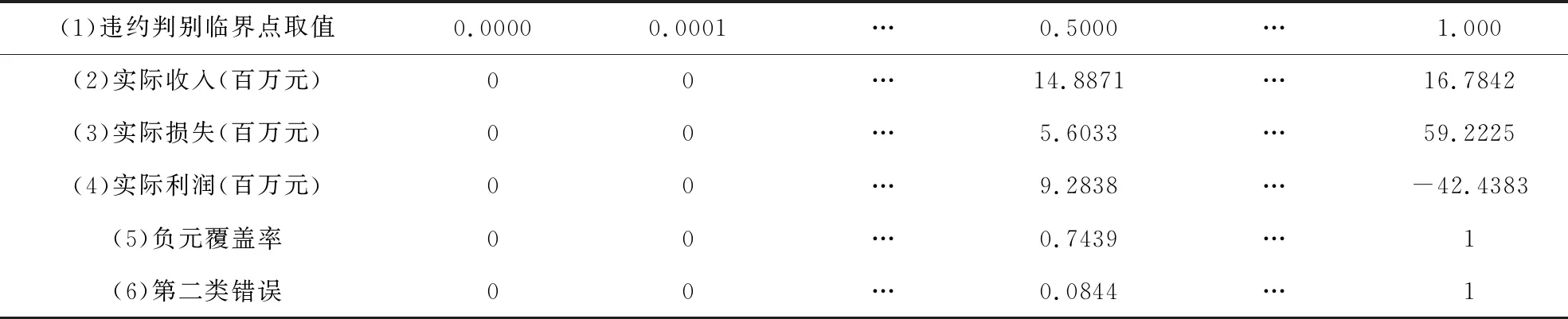
表2 数据集2训练集中不同违约判别临界点下实际利润
在数据集1和数据集2的训练集数据中求得的利润最大化的临界点分别为0.1887和0.2219,在预测测试集中客户时以此临界点作为判别客户违约状态的参考。
3.5 对比分析
3.5.1 子模型和混合模型准确性差异性检验
使用10折交叉检验的方法检验子模型和混合集成模型的稳健性,检验混合模型与3个子模型在计算违约概率的准确性上是否具有显著差异。使用T检验来检验两组数据均值是否均有显著差异,结果如表4所示。在数据集1中,混合模型比3个子模型的AUC值大约高0.01%。在数据集2中混合模型比3个子模型的AUC值大约高0.005到0.045(即0.9%~4.7%)。这说明本文建立得混合模型得违约概率准确性显著优于单一模型得违约概率。

表3 子模型AUC值与混合模型AUC对比分析(差异性检验)
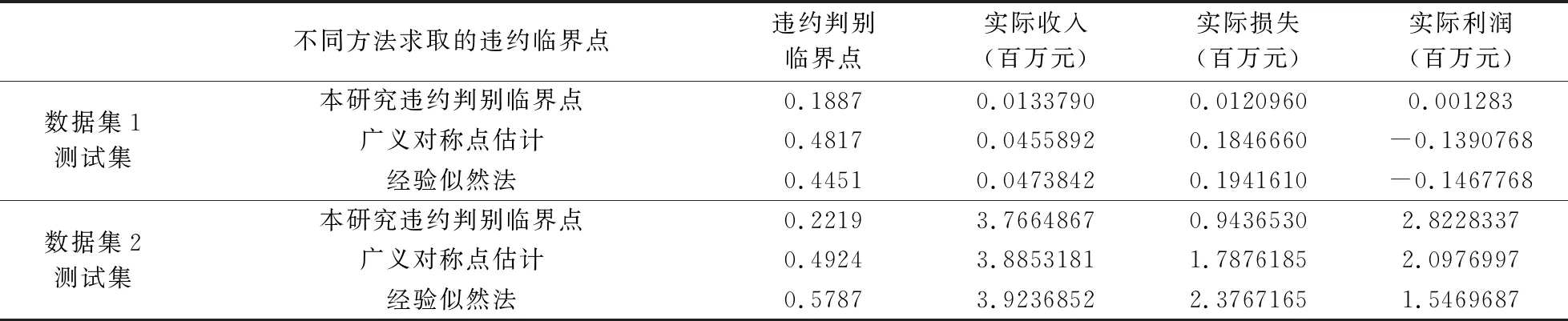
表4 不同临界点求取方法下的测试集中获利比较
3.5.2 不同临界点求取方法的利润比较
使用广义对称点估计和经验似然法求解训练集中违约判别临界点,并根据求解的违约判别临界点,计算数据集1和数据集2测试集中金融机构的收入、损失和利润,结果见表4。在数据集1和数据集2中,本研究计算的训练集中违约判别临界点临分别为0.1887和0.2219(见3.4节),在此违约判别临界点下测试集中实际利润为0.001283百万元和2.8228337百万元,远大于其他违约判别临界点的获利。数据集1和数据集2的违约判别临界点经济含义是:在保证计算客户违约概率准确的前提下,由于客户违约时给金融机构造成的损失远大于客户不违约时给金融机构带来收入,因此为了获得最大利润,金融机构面对贷款客户时应该提高贷款门槛,以此降低第二类错误带来的本金和利息的损失。
3.5.3 不同预测准确性模型所能获取利润的比较
本文从数据集1的训练数据中构造虚拟数据集3,从数据集2的训练数据中构造虚拟数据集4。应该指出,本文之所以选择从训练集数据中构造虚拟数据原因在于:在训练集中模型都无法获取准确鉴别违约客户和非违约客户,并获取正的利润,那么模型在测试集数据中也同样无法获得鉴别违约客户和非违约客户,当然也就无法取得最大利润。
虚拟数据集与真实数据集的唯一区别在于,虚拟数据集计算的违约概率为随机生成的0到1之间的任意数,即虚拟数据集中的违约概率无法鉴别出客户的违约状态。本文构造的虚拟数据集3的AUC值为0.5079,远小于混合模型在数据1训练集中0.7987的AUC值。虚拟数据集4的AUC值为0.5516,远小于混合模型在数据2训练集中0.8822的AUC值。
从虚拟数据集3和虚拟数据集4的临界点取值和实际利润变化曲线来看(限于篇幅这里未展示),虚线所代表的低准确度模型,在临界点所有可能取值的范围内利润均为负值,且随着临界点的增大利润不断下降。这说明,在一个准确率低的模型中,无论违约判别临界点的取值如何变化,此时金融机构无法鉴别违约客户和非违约客户。
4 结论
4.1 主要结论
混合模型计算的客户违约概率值较单一模型计算的违约概率值更准确。整体准确度高的违约判别临界点并不一定是利润最大化的违约判别临界点,本研究寻找的违约临界判别点比使用保证整体准确率最大的广义对称点估计和经验似然法挖掘的违约判别临界点获取的利润高。
4.2 主要创新
使用混合模型来计算客户违约概率,即使用不同模型计算客户违约概率,通过加权平均的方式对不同子模型计算出的违约概率进行了修正,从而保证计算客户违约概率的整体准确性。
通过定义从贷款中获得收入、损失和利润的计算方法,以利润最大为目标反推,最优判别临界点,以此找到利润最大的违约判别临界点,避免现有临界点方法计算的违约判别临界点不是贷款利润最大化违约判别临界点的弊端。
猜你喜欢
今日农业(2022年15期)2022-09-20
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化·高三版(2021年3期)2021-05-14
中学生数理化·高三版(2021年3期)2021-05-14
小天使·二年级语数英综合(2019年10期)2019-11-08
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
