
基于近似投影的水平分层调度译码算法
2022-11-01 06:33刘惠阳王新陈克寒夏巧桥
科学技术与工程 2022年26期
刘惠阳, 王新, 陈克寒, 夏巧桥*
(1.华中师范大学物理科学与技术学院, 武汉 430079; 2.上海航天电子技术研究所, 上海 201108)
低密度奇偶校验(low density parity check,LDPC)码是一种性能十分优良的线性分组码,因具有纠错性能高、结构复杂度低以及错误平层较低等优势,已被广泛运用于数字电视、光纤通信、加密通信[1]以及新一代无线网络协议等领域。
最大似然(maximum likelihood, ML)译码算法的复杂度会随着LDPC码的码长增长呈指数级增加,作为ML算法的次优解,基于消息传递思想的置信传播(belief propagation, BP)译码算法能随着LDPC码长的增加无限逼近于ML译码算法的性能,有效降低译码的复杂度[2-3]。但BP译码算法在高信噪比(signal-to-noise ratio, SNR)区域会出现错误平层(error floor, EF)现象,导致误码率不会随着信噪比的提升而进一步下降,因此BP译码算法无法满足性能较高的系统的需求,需设计一种在高信噪比区域仍然拥有较好译码性能的译码算法。Feldman等[4]提出了适用于LDPC码的线性规划(linear programming, LP)译码模型,和BP译码算法相比,LP译码算法拥有全零假设和最大似然译码的特性,能避免错误平层的出现,使高信噪比区域拥有良好的译码特性,但是LP译码算法的复杂度较高,其发展受到限制。
Barman等[5]将交替方向乘子法(alternating direction method of multiplier, ADMM)的框架与LP译码算法相结合,提出基于ADMM的LP译码模型(ADMM-LP),降低LP译码算法复杂度的同时保留了LP译码算法最大似然认证的优点,并且在高信噪比区域不会出现错误平层现象。但是其译码的复杂度仍然较高,且在低信噪比区域的译码性能不如BP译码算法。
为改善在低信噪比区域的译码性能,Liu等[6]提出了基于惩罚函数(penalty function, PF)的ADMM译码算法,通过惩罚伪码字,选择整数码字优先译出从而大幅提升了在低信噪比下的译码性能,该算法引起译码学者的关注。Wang等[7]提出了通过重新构造罚函数进一步提升算法的译码性能,但是该算法存在优化参数过多的问题;夏巧桥等[8]针对该问题进一步提出了基于均衡约束的ADMM-LDPC译码算法。Wei等[9]则提出校验节点惩罚的译码算法来提升低信噪比区域的译码性能,但是该算法的复杂度较高。校验多胞体投影是ADMM译码算法中最为复杂的部分,为降低ADMM译码算法的复杂度,Zhang等[10]提出割查找算法(cut search algorithm, CSA),该算法属于精确投影算法,涉及了复杂的排序计算。Jiao等[11]提出通过建立查找表(lookup tables,LUT)和量化输入来简化欧几里得投影,降低算法的复杂度。Xia等[12-13]则尝试探索校验多胞体的简化近似投影算法,提出线段投影算法(line segment projection algorithm,LSA)和混合投影算法(hybrid projection algorithm,HPA),在保证译码性能的同时可大幅降低译码算法的复杂度。采取合适的调度策略能加速译码收敛进而提升译码速度。Debbabi等[14-15]通过分析BP算法中消息调度的策略,提出了适用于ADMM算法的水平分层调度(horizontal layered, HL)算法,可降低译码迭代次数,提高译码的效率,然而,ADMM水平分层调度算法中的校验多胞体投影采用的为精确投影算法,使得译码的复杂度仍然较高。
为进一步提升译码性能,在加速译码收敛速度的同时进一步降低译码的复杂度,使硬件实现更方便,现将Xia等[12-13]提出的LSA算法和HPA算法与Debbabi等[14-15]提出的HL算法结合,提出基于近似投影的ADMM水平分层调度译码算法,可用于对译码性能要求较高的领域。
1 ADMM水平分层调度算法和近似投影算法
1.1 ADMM-LP译码算法
LDPC码属于线性分组码,其编码的步骤为:将长度为k的信息元通过线性组合增加长度为m的校验位,形成长度为n的码字,校验信息可由奇偶校验矩阵H或者生成矩阵G表示。考虑码长为n,校验位为m的LDPC码,其通常可用m×n大小的稀疏校验矩阵H对其描述。校验矩阵H的行下标和列下标索引分别为j∈J={1,2,…,m},i∈I={1,2,…,n}。每行、每列非0元素的索引分别用Nc(j)={i|Hj,i=1}和Nv(i)={j|Hj,i=1}进行表示。记dcj=|Nc(j)|和dvi=|Nv(i)|为校验矩阵H的校验节点和变量节点的维度。
假设发送码字为x={x1,x2,…,xn-1,xn},使用BPSK调制,经过加性高斯白噪声信道后,在接收端接收到的向量为y={y1,y2,…,yn-1,yn},则对数似然比γi可表示为
(1)
式(1)中:Pr(y|x)为条件概率。
基于ADMM的LP译算法的本质是将最大似然译码问题进行松弛,并将其与ADMM的优化模型相结合,得到如下优化问题[4]:
(2)
式(2)中:Pj为dcj×n的转换矩阵;x为长度为n的码字;PPdj为第j个校验节点对应的校验多胞体;zj为引入的辅助变量,进一步得到其对应的增广型拉格朗日函数为

(3)
式(3)中:λ为与每个校验节点对应的拉格朗日乘子向量;μ为大于零的常数。进一步可得到迭代公式为
(4)
式(4)中:Π[0,1](v)为向量v在单位立方体上的投影;ΠPPdj(v)为向量在校验节点对应的校验多胞体上进行欧几里得投影;k为迭代次数。
1.2 ADMM译码水平分层调度算法
针对标准ADMM译码算法译码收敛速度较慢等问题,可以采用合适的消息调度算法来加快收敛速度。目前大多数ADMM译码算法采用的是泛洪消息调度策略(flooding, FL)[4],其先更新所有的变量节点,再更新所有的校验节点。虽然这种算法便于操作和理解,但会降低算法的收敛速度。为加速译码收敛速度,Debbabi等[14-15]提出了水平分层调度算法,并将其运用到ADMM译码算法中,取得了较好的译码结果。这种新的调度策略具有一定的针对性,即针对每次迭代过程,校验节点进行消息更新时,充分利用已经更新的相关校验节点和变量节点传递的信息,从而加速译码收敛进而提升译码速度。
1.3 校验多胞体近似投影算法
Xia等[12-13]在偶数顶点投影算法(even vertexes algorithm, EVA)的基础上提出了LSA算法和HPA算法。LSA算法的核心在于用点到线段的投影代替点到校验多胞体的投影。根据校验多胞体顶点的特性,找到离待投影向量最近的两个偶数顶点A和B,将A、B顶点的连线作为待投影的线段,根据点到线段的投影公式计算投影结果。顶点A和顶点B只有两个位置的元素不同,整个计算只涉及两个维度上的数学运算,算法的复杂度为线性复杂度。线段AB中仅有两个元素不为0,根据多胞体顶点的特性,计算得到的投影向量z中的元素大概率为0和1。
HPA算法的步骤为交替使用CSA算法和EVA算法,根据EVA算法的特点,由EVA算法得到的投影结果z中的元素为0和1,使当前待投影的向量大概率等于上次待投影的向量,从而增加无用投影的比例,缩短投影时间。偶数顶点投影相当于一种惩罚操作,使其远离伪码字,并且交替使用CSA算法和EVA算法可以使EVA算法中产生的投影误差通过CSA算法来纠正,起到自适应纠正的作用,提高译码算法的效率和性能。
2 基于近似投影的ADMM水平分层调度译码算法

算法1 基于近似投影的ADMM水平分层调度译码算法1:根据接收码字y,构建得到对应的LLR向量γ2:针对校验矩阵的每行,构建dj×n大小的选择矩阵Pj3:将λj初始设置为全0向量,zj初始设置为全0.5向量,最大迭代次数Iter4:repeat5: for all j∈J do6: 计算变量节点到校验节点的信息Li→j7: for all i∈Nc(j)do8: xi←Π[0,1]1Nv(i)∑j∈Nv(i)zij-1μλij -γiμ ▷更新xi9: end for10: 计算校验节点到变量节点的信息Lj→i11: vj=Pjx+λj/μ12: zj←ΠPPdj(vj)(使用LSA或HPA进行投影计算)▷更新zj13: λj←λj+μ(Pjx-zj)▷更新λj14: end for 15:until达到最大迭代次数Iter或者早停止成功16:硬判决17:∀i∈I:ci=[xi]>0.5
ADMM算法中最耗时的步骤为计算校验多胞体上的投影,使用近似投影的方法能有效降低译码算法的复杂度,提升译码的速率。采用不同的投影算法并不会改变ADMM水平分层调度算法的整体框架,使得可以采用近似投影算法计算ADMM水平分层调度算法中的校验多胞体的投影。此外,由于LSA和HPA这两种近似投影算法得到的投影结果z中的元素大多为0和1,使得最终得到的码字为合法整数码字的概率增大,可加速算法收敛。而水平分层调度策略本身也可提高算法收敛速度,因此可尝试将近似投影算法与水平分层调度算法相结合进一步提升译码收敛速度。受到这些方法的启发,本文提出一种改进思路,将近似投影算法与水平分层调度算法结合,设计基于近似投影的ADMM水平分层调度译码算法。实验结果表明,和已有算法相比,本文提出的算法不仅能降低译码复杂度,而且对译码性能有所提升。算法1给出了本文中提出的基于近似投影的ADMM水平分层调度译码算法的流程。
在算法1中,第1~3行首先设置译码参数和初始化相关变量。第5行设置遍历校验节点为外部大循环。第6~9行对变量节点进行更新,即计算变量节点传递给校验节点的信息Li→j。第10~14行对校验节点进行更新,即计算校验节点传递给变量节点的信息Lj→i,其中,第12行采用近似投影LSA算法或HPA算法进行投影计算。第15~17行分别判断译码是否停止以及对译出的码字进行硬判决。
从算法1中可以看出本文提出的基于近似投影的ADMM水平分层调度译码算法在每次迭代中需进行m×d次x更新计算,m次z更新计算以及m次λ更新计算。基于近似投影的ADMM水平分层调度译码算法投影操作采用的是LSA或HPA算法,其中LSA每次计算需涉及3d+4次比较运算,d+9次加法运行以及1次乘法运算,HPA具体计算中会交替使用CSA算法和EVA算法,其中CSA每次计算需涉及dlog2d+3d次比较运算,4d+2次加法运算以及次d次乘法运算,EVA每次计算需涉及d次比较运算,d次加法运算以及1次乘法运算。
3 实验结果
实验平台处理器为I5-10300H,主频为2.5GHz,内存为8GB,操作系统为WIN10 64位,软件为VS2019。仿真实验采用的信道为加性高斯白噪声信道,调制方式为BPSK调制,实验选择的码字分别为码率为1/2,度为{6,7}的(576,288)不规则码C1;度为20的(576,480)规则码C2,这两个码字均来自IEEE802.16e标准[16];以及码率为1/2,度为6的(2 640,1 320)Margulis码C3。仿真实验中使用了l1惩罚函数g(x)=-α|x-0.5|。FL-PD-CSA算法表示采用惩罚函数和CSA投影的泛洪调度ADMM译码算法,HL-PD-CSA算法表示采用惩罚函数和CSA投影的水平分层调度ADMM译码算法,HL-HPA算法表示采用HPA投影的水平分层调度ADMM译码算法,HL-PD-LSA算法表示采用惩罚函数和LSA投影的水平分层调度ADMM译码算法。采用差分优化[17]的方法对各码字的参数μ和α进行优化,三种码字的HL-HPA译码算法均无惩罚系数α。本文所有的实验均采用了基于HTx=0的早停技术,最大迭代次数为200,误帧率曲线中每个数据点均至少收集100帧错误帧。
3.1 不同迭代次数下各算法的误帧率对比
图1为C1、C2、C3码字在不同迭代次数下各个算法的译码性能。由图1可知,对于校验节点度相对较小的C1、C3码字,HL-PD-LSA算法收敛速度优于FL-PD-CSA算法、HL-PD-CSA算法以及HL-HPA算法,在计算校验多胞体投影时, HPA算法交替使用了CSA算法和EVA算法,当迭代次数较少时,对于校验节点度较小的这两个码字而言,HL-HPA算法的译码性能略差于HL-PD-CSA算法,当迭代次数在70次以上时,HL-HPA算法的译码性能相对于HL-PD-CSA算法而言有所提升。对于校验节点度相对较高的C2码字,HL-HPA算法收敛速度优于FL-PD-CSA算法和HL-PD-CSA算法以及HL-PD-LSA算法。
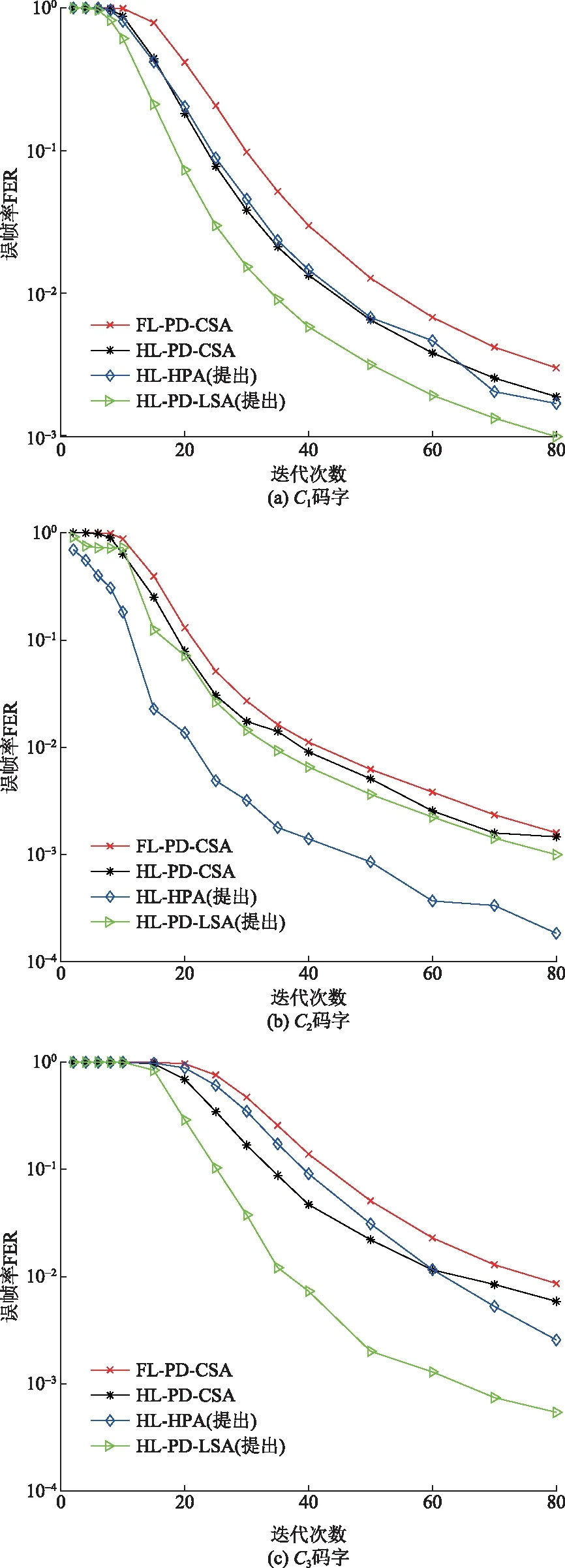
图1 C1、C2、C3码字不同迭代次数下误帧率Fig.1 The FER performance of C1, C2, C3 codes at different maximum number of iteration
3.2 不同信噪比下各算法的误帧率对比
图2为各算法在最大200次迭代下C1、C2、C3码字的误帧率。从图2中可以看出,本文中所提出的HL-HPA算法和HL-PD-LSA算法在各个信噪比下的译码性能均优于FL-PD-CSA算法和HL-PD-CSA

图2 C1、C2、C3码字各算法误帧率Fig.2 The FER performance of C1, C2, C3 codes with different algorithms
算法,这是由于本文所提出的HL-HPA算法和HL-PD-LSA算法可加速译码收敛速度,因此在相同最大迭代次数下译码性能更优。例如,对C1码字,在FER=1×10-3下,HL-PD-LSA算法的译码性能和HL-PD-CSA算法相比有0.2 dB的提升,HL-HPA算法的译码性能和HL-PD-LSA算法相比有0.1 dB的提升;对C2码字,在FER=1×10-2时,HL-PD-LSA算法相对于HL-PD-CSA算法有0.1 dB的提升,HL-HPA算法相对于HL-PD-CSA算法有0.3 dB的提升;对C3码字,当FER=1×10-2时,HL-HPA算法的性能和HL-PD-CSA算法相比有0.2 dB的提升,HL-PD-LSA算法的译码性能和HL-PD-CSA算法相比有0.3 dB的提升。此外,从图2可以看出,针对校验节点度较高的码字C2, HL-HPA算法的性能优于HL-PD-LSA算法。对于校验节点度较低的码字,HP-PD-LSA算法的性能优于HL-HPA算法。
3.3 各算法平均迭代次数对比
图3展示了C1、C2、C3码字在各算法下的平均迭代次数。从图3中可以看出,对于C1和C2码字,本文提出的HL-HPA算法和HL-PD-LSA算法的迭代次数均少于HL-PD-CSA算法。例如,对于C1码字,HL-HPA算法相对于HL-PD-CSA算法的平均迭代次数减少19%,HL-PD-LSA算法的平均迭代次数比HL-PD-CSA算法少32%。对于C2码字,HL-HPA算法的平均迭代次数比HL-PD-CSA算法少40%,HL-PD-LSA算法的平均迭代次数比HL-PD-CSA算法少25%。对于C3码字,虽然HL-HPA算法在低信噪比区域的平均迭代次数仍然较高,但是随着信噪比的增加,其平均迭代次数快速降低,HL-PD-LSA算法的平均迭代次数在各个信噪比下均低于HL-PD-CSA算法,可减少27%的平均迭代次数。
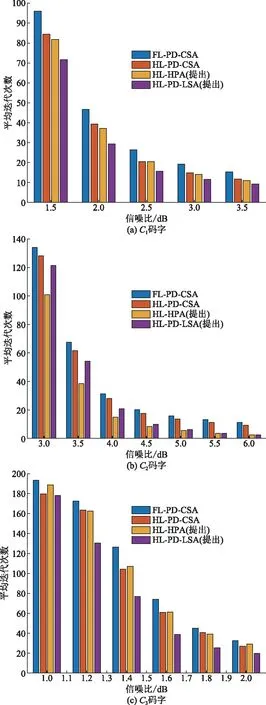
图3 C1、C2、C3码字各算法平均迭代次数Fig.3 The average decoding iterations of C1, C2, C3 codes with different algorithms
3.4 各算法平均译码时间对比
图4展示了C1、C2、C3码字在各个算法下的平均译码时间。针对三种码字,HL-HPA算法由于可以大幅增加无用投影比例使得其译码耗时最短,HL-PD-LSA算法其次,HL-PD-CSA算法耗时最长。对于C1码字,相对于HL-PD-CSA算法而言,HL-HPA算法能节省43%的译码时间,HL-PD-LSA算法能节省27%的译码时间。对于C2码字,HL-HPA算法相对于HL-PD-CSA算法而言能节省65%的译码时间,HL-PD-LSA算法相对于HL-PD-CSA算法而言能节省35%的译码时间。对于C3码字,相对于HL-PD-CSA算法而言, HL-HPA算法能节省57%的译码时间,HL-PD-LSA算法能节省21%的译码时间。

图4 C1、C2、C3码字各算法平均译码时间Fig.4 The average decoding time of C1, C2, C3 codes with different algorithms
4 结论
在近似投影和水平分层调度的基础上,提出了基于近似投影的ADMM水平分层调度译码算法。相对于其他算法,本文提出的算法在加速译码收敛速度的同时可降低译码复杂度,并能进一步提升译码的性能。该译码算法使用了水平调度算法的框架,其单次迭代计算复杂度高于泛洪调度算法,但是其平均迭代次数相对于泛洪调度的译码算法而言较少,更有利于硬件实现。实验结果表明,本文提出的算法可使译码性能提升0.1~0.3 dB,迭代次数可减少19%~40%。平均译码时间可节省21%~65%。但该译码算法仍然并非最优的译码算法,可继续对其进行优化,如寻找复杂度更低的投影算法或者更高效的调度策略等。
猜你喜欢
北京大学学报(自然科学版)(2022年4期)2022-08-18
闽南师范大学学报(自然科学版)(2022年1期)2022-03-28
社会科学战线(2022年2期)2022-03-16
软件导刊(2021年9期)2021-09-28
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
东坡赤壁诗词(2020年3期)2020-07-04
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
扬子江诗刊(2018年1期)2018-11-13
