
基于深度学习的SDN 流量分类方法研究
2022-11-04 02:22池亚平刘怡龙许盛伟
北京电子科技学院学报 2022年2期
池亚平 刘怡龙,2 许盛伟
1.北京电子科技学院,北京市 100070
2.西安电子科技大学,西安市 710071
引言
随着网络技术的快速发展及数据流量的爆炸式增长,网络流量类型形式多样,而不同类型的网络流量对底层网络资源的需求不尽相同,因此为了实现高效的网络管理以及提高网络服务质量,则必须对网络流量进行有效的监控和分类。
相比于传统的分布式网络架构体系的结构复杂、控制困难和无法实现数据流的灵活控制的问题,软件定义网络(Software Defined Network,SDN)通过将控制平面和数据平面分离,实现了对网络的集中控制,降低了网络管控的难度[1]。SDN 网络的集中控制和可编程性使得网络流量分类变得更加简单有效,为提高网络服务质量奠定了基础。 近些年,随着深度学习在计算机视觉、自然语言处理等领域的快速发展,许多研究者开始尝试通过使用深度学习来解决网络流量分类问题,以实现对网络流量进行在线智能识别的目的。
本文将SDN 网络和深度学习技术结合起来,提出了一种基于SDN 网络和深度学习技术的智能流量分类方法,利用SDN 网络的全局控制能力和深度学习的智能分析能力,实现数据流量的在线智能识别。
1 相关工作
目前的流量分类方法主要分为三类[2]:基于端口的流量分类方法、基于有效载荷的流量分类方法和基于机器学习的流量分类方法。 随着动态端口的普遍使用,导致使用固定端口的分类方法的准确率越来越低[3];使用基于有效载荷检测的流量分类方法,由于对数据包进行深度检测时,算法的计算复杂度高、计算时间长,而且仅适用于未加密流量[4],因此以上两种都不适合进行在线流量分类。 为了克服上述方法的缺点,目前研究的流量分类方法主要都是使用机器学习基于统计特征进行流量分类。
流量分类中常见的传统机器学习算法主要有随机森林[5],SVM[6]和高斯混合模型[7]等,根据统计特征或时间序列特性,进行流量类型识别。 文献[8]提出了一种用来对SDN 架构下物联网中的流量进行分类的机器学习方法,利用随机森林算法使用SFS 算法选择的6 个特征进行流量分类。 文献[9]针对目前网络中无法有效的对在线视频流量和下载流量进行速率管控,提出了一种在SDN 中基于机器学习的在线视频流量和下载流量分类方案,利用随机森林算法对实时流量应用进行分类,其平均准确率达到91.5%。 以上文献均为利用传统的机器学习算法实现流量分类,但是由于传统的机器学习具有有限的特征学习能力,对非线性特征提取能力较弱,因此不适合处理海量网络流量,更适合处理小规模的数据问题[11]。 相反,深度学习包含多个隐藏层可以使其具有更强的非线性特征提取能力,可在分布式的特征中发现更高层次的特征表示,这一特性可以使其弥补传统机器学习在流量分类方面的缺点。
文献[10]提出了一种基于SDN 架构体系的混合深度神经网络的应用分类方法,该方法在获得高分类精度的情况下无需人工选择和提取特征。 在提出的应用分类框架中,通过SDN 控制器利用其逻辑集中控制能力和强大的计算能力收集和处理网络流量,用于训练混合深度神经网络。 混合深度神经网络包括堆叠式自动编码器和Softmax 回归层,其中堆叠式自动编码器可以利用非线性特征提取能力获取深度流特征,而不需要手动特征选择和提取;Softmax 回归层作为分类器,实现流量应用分类。 实验结果表明,该分类方法相比于基于SVM 的流量分类方法具有更高的分类精度。
本文借鉴文献[10]的思路,设计了一种基于SDN 体系架构和深度学习的在线智能流量分类方法,首先是利用SDN 架构的集中控制能力从每条数据流的前几个数据包中提取出少量具有代表性且易于得到的特征;然后利用格拉姆角场(Gramian Angular Field,GAF)将一维特征序列转化为二维图像,实现数据特征的扩展;最后将二维图像输入到卷积神经网络中,利用其非线性特征提取能力提取出深层次的数据特征,将提取得到的数据特征利用Softmax 分类函数,实现数据流量的在线分类。
2 基本原理
2.1 格拉姆角场
格拉姆角场[12](Gramian Angular Field,GAF)是一种将信号序列转变为图像的技术。 给定一个一维时间序列X={x1,x2, ...,xn},是由n 个实际观测值xi 构成,首先使用最小-最大定标器(Min-Max scaler)进行数值缩放,将输入的一维序列归一化到[-1,1]或者[0,1],如式(1)所示。

上式中,ti表示的时间戳,N 是调整极坐标系跨度的恒定因子。 将笛卡尔坐标下的一维时间序列转换成极坐标表示后,可以利用每个点之间的三角函数和差来识别不同时间间隔内的时间相关性,分别得到格拉姆求和角场(Gramian Summation Angular Field,GASF)和格拉姆差分角场(Gramian Difference Angular Field,GADF),定义如下:

2.2 卷积神经网络
卷积神经网络 ( Convolutional Neural Network,CNN)具有强大的表征学习能力,通过在隐含层引入参数共享和层间连接稀疏性机制来减少网络参数数量,使之适合在超大规模数据集进行运算[13],目前已被广泛应用于图像处理。CNN 的主要结构包括输入层、卷积层、池化层、全连接层及输出层,其中卷积层用于对输入图像进行特征提取,通过滑动固定大小的卷积核,在输入图像的不同区域与之进行卷积计算,提取出图像的某些隐藏特征及抽象信息,卷积计算公式如式(5)所示。

池化层通过利用最大池化或平均池化对卷积层中得到特征图进行数据缩放,缩减特征图尺寸,降低数据维数,池化的计算公式如式(6)所示。

其中f(·) 表示最大值函数或平均值函数。
通过卷积池化计算得到的二维特征数据经过flatten 函数转化成一维特征向量,输入到全连接层中,通过利用Softmax 分类函数实现输入图像到标签集的映射,完成数据分类,其计算公式如式(7)所示。

3 算法设计
3.1 总体框架设计
算法应用方案的总体框架及其组成部分如图1 所示,主要包括转发层和控制层,其中转发层主要由一系列可编程交换机组成;控制层包含SDN 控制器,比如Ryu 控制器、Opendaylight 控制器等,通过OpenFlow 协议发送PacketIn 或PacketOut 消息对转发层面的网络设备进行集中控制,转发层中的交换机通过接收流表中的控制命令生成数据转发表,进而控制数据的监测、处理及转发,因此可以避免使用复杂的网络协议进行数据转发,增加了网络控制的灵活性。

图1 总体架构
在控制器现有功能的基础上通过再添加信息收集模块、特征提取模块及数据分类模块实现数据流量的在线智能识别。
(1)信息收集模块:每条数据流会由其五元组信息,即源IP 地址、目的IP 地址、传输层协议、源端口及目的端口进行标识。 当交换机将数据包的相关信息通过PacketIn 消息上报到控制器后,信息收集模块会计算其五元组的哈希值,将哈希值相等的数据包汇聚成流,并将同一数据流发送给特征提取模块。
(2)特征提取模块:为了实现数据流量在线智能流量分类,特征提取模块将提取每条数据流中前几个数据包的某些特征发送给数据流分类模块,用于数据流的分类。 为了实现有效快速分类,这些特征需要简单易得到且具有代表性。Moore 等人[14]对Moore 数据集中包含的248 个特征,通过利用FCBF 算法计算其重要性后排序,最终筛选出12 个最具代表性的特征如表1所示。 本文为了验证是否可以只通过少量的统计特征实现快速有效的流量分类,同时也为了减少动态端口的使用对分类准确率的影响,所以本文选用了除端口以外的其余10 个统计特征用于实现流量数据的分类。

表1 数据特征及其描述
(3)数据流分类模块:本文在分类模块中设计了一种基于格拉姆角场和卷积神经网络的GAF_CNN 流量分类方法。 将特征提取模块提取到的一维统计特征利用格拉姆角场转化成二维图像后,可以使分类模块在获取的统计特征较少的情况下,仍然表现出较好的分类性能。
3.2 GAF_CNN 分类方法
本文提出的基于格拉姆角场和卷积神经网络的GAF_CNN 流量分类方法,首先将一维特征序列进行归一化处理、坐标转换和三角函数计算后,将其转变成二维图像并输入到卷积神经网络中,最后利用Softmax 分类函数,实现数据流量的在线分类。 本文采用的卷积神经网络的具体结构如图2 所示,包括输入输出层,三个卷积层C1、C2 和C3 以及两个池化层S1、S2。

图2 卷积神经网络结构
本文采用的卷积核大小为3*3,卷积层的卷积核数目分别32,64 和64,步长设置为1,为了提取边缘特征,在进行卷积计算时,会采用零填充的方式,在卷积计算完成后会利用激活函数relu,增加网络对非线性特征的学习能力。 池化层S1,S2 均采用平均值函数来降低数据维数,减少训练参数,步长设置为2。
本文特征提取模块提取的10 个特征经过GAF 转换后会得到10*10 的二维图像,将其输入到CNN 网络中,在经过卷积层C1 卷积计算后会得到10*10*32 的特征图,将该特征图进行池化计算后会得到5*5*32 的特征图,减少了数据维数。 然后将池化后的特征图输入到卷积层C2 中,经过第二次计算会得到5*5*64 的特征图,再次经过池化计算以及第三次卷积计算后,最终会得到3*3*64 的特征图,将最终得到的特征图经过Flatten 函数转换成一维特征序列输入到全连接层中,利用Softmax 分类函数实现数据流量的智能分类。 在模型训练时,会根据Softmax 分类函数的输出值yi与实际标签值y′i计算损失值L, 然后利用梯度下降法训练CNN模型参数。 损失函数计算公式如式(8)所示。

4 算法验证与分析
4.1 实验环境
实验采用的计算机处理器为2.6GHz Intel Core i7,内存为16GB 2400MHz DDR4,采用的操作系统为ubuntu 20.04。 使用TensorFlow 和Keras 作为机器学习的框架。
4.2 算法对比
为了验证本文所提分类算法的有效性,我们将与本文具有相同结构的CNN 算法以及文献[10]中所使用的堆叠式自编码器Stack_Auto-Coder,在不同数据集下对准确度、精确度、召回率和F1 分数进行对比。
(1)离线测试
为了验证本文提出的GAF_CNN 算法在流量分类方面的分类效果,本节选用常用的Moore数据集[15]进行测试。 该数据集包含了在不同时间段内收集的10 个TCP 流量子数据集,其中,每条数据样本包含了248 个流量特征与其流量类别。
图3 展示的是三种算法在不同子数据集上关于准确度、精确度、召回率和F1 分数方面的对比,其性能平均值如表2 所示。 总体来看,本文所提的GAF_CNN 分类算法在不同数据集的各个方面都明显优于CNN 算法和Stack_AutoCoder算法,而CNN 算法和Stack_AutoCoder 算法在不同数据集上的表现各有优劣。 具体来看,GAF_CNN 算法在各个子数据上的准确度、精确度、召回率和F1 分数表现的非常稳定,这表明,在通过GAF 方法实现特征扩展后的分类算法,相比于CNN 算法和Stack_AutoCoder 算法,GAF_CNN 算法具有较好的泛化能力和分类效果。 本文所提的GAF_CNN 算法在不同数据集上的准确率都达到了98%以上,尤其是在第五、第六子数据集上,相比于另外两种算法,准确率有明显的提升。

图3 三种算法在Moore 子数据集上的性能对比

表2 三种算法在Moore 子数据集上性能对比
图4 展示的是三种算法在不同流量类别上关于准确度、精确度、召回率和F1 分数方面的对比,其性能平均值如表3 所示。 总体来看,本文提出的GAF_CNN 算法在不同流量类别的各个方面,基本上也要优于CNN 算法和Stack_Auto-Coder 算法。 具体分析,在准确率方面,虽然在MultiMedia 类别上,本文所提出的GAF_CNN 算法的准确率要略低于Stack_AutoCoder 算法,但在其他流量类别上,GAF_CNN 算法的准确率都要优于另外两种算法,尤其是在ftp-control,ftppasv 和database,GAF_CNN 相比于另外两种算法的准确率有明显的提升。 在精确率方面,GAF_CNN 算法在ftp-pasv,database 等流量类别要略低于其他两种算法,其原因如下,从精确率的计算公式来看。

表3 三种算法在Moore 数据集中不同流量类别上的性能对比
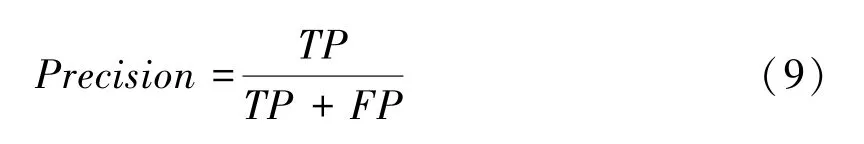
其中,在多分类过程中,以本节使用的Moore 数据集中的ftp-control 流量类别为例,TP表示的是正确分类为ftp-control 类别的样本数量,FP 表示的是分类器将其他类别错误分类为ftp-control 类别的样本数量。 从图4 中的精确率对比可以看出,本文提出的GAF_CNN 算法在精确率方面整体相比于CNN 算法和Stack _AutoCoder 算法波动较小,这表明使用GAF_CNN算法时,每个类别的FP 样本数量较为均衡,而使用CNN 算法时,分类器易倾向于将其他类别的样本错误分类为ftp-control 类别,使用Stack_AutoCoder 算法时,分类器易倾向于将其他类别的样本错误分类为p2p 和multimedia 等类别,导致其他类别上的FP 样本数量减少,从而使得尽管GAF_CNN 算法在ftp-pasv,database 等类别上的TP 样本数量高于其他两种算法,但在精确率方面还是略低于CNN 算法和Stack_AutoCoder算法,这从侧面也反映出了GAF_CNN 算法的稳定性要优于CNN 算法和Stack_AutoCoder 算法。

图4 三种算法在Moore 数据集中不同流量类别上的性能对比
综上所述,无论是从不同子数据集的各个方面来分析,还是从不同流量类别的不同方面来看,在得到的分类特征较少的情况下,本文提出的GAF_CNN 算法是要优于CNN 算法和Stack_AutoCoder 算法的。 通过在离线Moore 数据集上的验证,本文提出的GAF_CNN 算法在通过GAF方法实现特征的扩展,将一维特征序列转化为二维图像,并将其输入到CNN 网络中,经过训练,也可以使得CNN 神经网络在特征较少的情况下具有更好地泛化能力和分类表现。
(2)在线测试
上述实验结果可以表明在分类特征较少的情况下,本文提出的算法在流量分类方面仍然具有良好的表现,但是Moore 数据集中每个样本的特征,都是在采集每条数据流的所有数据包后统计计算得出的,而本文的目标是实现数据流量的在线智能分类,分类方法需要满足实时性的要求,因此分类所需的特征就必须在每条数据流的前几个数据包统计计算得出。 为了进一步验证本文提出的算法在在线情况下的分类效果,本节采用Li 等人收集的数据集[16],该数据集中每条样本所包含的特征是从数据流的前5 个数据包统计得到的。
首先观察三种算法在不同子数据集上关于准确度、精确度、召回率和F1 分数方面的对比,如图5 所示。 表4 展示的是三种算法在不同方面的平均值。 总的来看,在不同子数据集上的各个方面,本文提出的GAF_CNN 算法要略优于其他两种算法,GAF_CNN 算法在各个子数据集上的准确率都超过了98%。 三种对比算法中,在不同子数据集的各个方面表现最差的是Stack_AutoCoder 算法,而CNN 算法在SiteB 和Day3 两个子数据集上的表现与GAF_CNN 算法基本一致,但是在Day1 和Day2 两个子数据集上,GAF_CNN 算法相对于CNN 算法和Stack_AutoCoder算法,在准确率、精确度、召回率和F1 分数都有明显的提升。

表4 三种算法在Li 子数据集上的性能对比

图5 三种算法在Li 子TCP 数据集上的性能对比
图6 展示的是三种算法在不同流量类别上关于准确度、精确度、召回率和F1 分数方面的对比,其性能平均值如表5 所示。 从图中可以看出,本文提出的GAF_CNN 算法在不同流量类别的各个方面的表现是要优于其他两种算法的,尤其是在小样本流量类别上的分类表现,比如Services 和Attack,GAF_CNN 算法在准确率、精确度、召回率和F1 分数相比于CNN 算法和Stack_AutoCoder 算法有明显的提升。 从GAF_CNN 算法在不同子数据集和不同流量类别上的准确度、精确度、召回率和F1 分数等方面的表现来看,GAF_CNN 算法在通过GAF 方法实现特征的扩展后,相比与另外两种算法,展现出的在线分类效果更为稳定。

图6 三种算法在Li 数据集不同流量类别的性能对比

表5 三种算法在Li 数据集中不同流量类别上的性能对比
5 结语
本文提出的算法在经过GAF 方法实现特征扩展后,将一维特征序列转化成图像输入到CNN 网络中,经过训练学习后,CNN 可以实现特征的自动提取和流量类别的自动分类,而且经过训练后的神经网络具有良好的泛化能力和分类效果。 本文通过采用不同数据集对所提算法在流量分类方面进行离线和在线测试,实验结果表明,相比于其他分类方法,本文提出的算法在分类准确率、精确度、召回率和F1 分数方面具有更好的性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
少儿画王(3-6岁)(2020年4期)2020-09-13
上海师范大学学报·自然科学版(2019年5期)2019-12-13
东方教育(2018年20期)2018-08-22
中国新通信(2017年9期)2017-05-27
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
微型计算机(2009年4期)2009-12-23
中学数学研究(2008年3期)2008-12-09
