
基于深度学习的医疗问句分类研究*
2022-11-10 06:39陈小强
计算机时代 2022年11期
陈小强,胡 翰
(吉安职业技术学院,江西 吉安 343000)
0 引言
医疗资源不均衡,会导致医患关系日益紧张,如何让偏远山区人民享受一线城市医疗资源已成为目前十分紧迫的问题。智能问诊系统的出现,为解决此类问题提供了途径,它可以整合医疗资源,为患者提供远程/便捷的人机交互模式[1]。在人机交互模式下,问句分类是智能问答系统的一个关键部分,分类的准确性决定患者能否获得最佳答案。文本分类做为机器学习非常重要的研究领域,已经在智能问答、情感分析[2]等方面有非常成熟的应用,然而与文本分类不同的是,问句分类[3]具有关键词少、书写不规范等特点,特别是对于医疗问句而言,患者提出的问句常常不够专业,因此,在采用特征向量空间表征问句时,易出现数据稀疏、维数过大等难题。此外,大量的真实语料库在特征向量构造时会引入噪声数据。针对以上难题,本文提出基于维基百科和深度学习相结合的词向量特征扩展模型,该模型利用中文维基百科语义结构和Word2vec构造特征词向量,从而提高医疗问句分类准确性。
1 相关工作
虽然中文问句大部分比较短小,只包含几个关键词,但是问句中蕴含着丰富的语义关系,它的结构复杂,形式多样,给研究者带来不少难题。目前大部分研究集中在分类模型准确性、性能提升等工作,并且取得不错的进展,近几年,众多学者开始着手研究问句关键词提取,本文结合医疗问句自身特点,重点研究问句关键词特征扩展,构建更准确的特征向量空间。
1.1 传统的关键词特征扩展
传统关键词特征扩展研究主要分为基于外部知识库和基于内部语义结构方法。Yang等[4]提出通过借助外部知识库,比如WordNet、HowNet 对短文本进行扩展,范云杰等[5]等[等提出基于中文维基百科扩展短文本。然而基于外部知识库的关键词特征扩展效果取决于知识库的全面性、准确性,并且无法反应中文问句内部语义特征,所以特征扩展效果并不好。
后来有研究者提出基于内部语义结构特征扩展方法,叶雪梅等[6]提出基于改进的TF-IDF 关键词特征扩展方法,胡江勇等[7]提出基于LDA 主题词扩展特征向量模型。但是基于内部语义结构特征方法需要专门语料库训练、训练速度慢,并且引入扩展构造主题词使得向量维度较大且改变原本语义信息,导致分类效果一般。
1.2 基于深度学习的词向量构建
为解决文本分类中关键词矩阵稀疏的特点,有研究者提出了词向量概念,通过文本语料训练,将文本关键词转换成多维特征向量。2006年Hinton 等[8]率先提出深度学习概念,它是一种非监督的逐层训练模型。深度学习模型不仅考虑了词语出现的频率,而且还考虑问句上下文语义关系,因此相比传统的方法训练结果更准确。目前主要有三种深度学习获取特征词向量的方法:①Bengio 等[9]在JMLR 上发表的三层深度学习模型,②Hinton 等[10]提出的训练语言模型和词向量,③Mikolov[11]团队提出的Word2vec。通过Word2vec工具训练得到关键词向量后,结合卷积神经网络模型TextCNN、快速文本分类模型FastText、长短期记忆网络(LSTM)、注意力机制(Attention)可得到较好的分类效果。在深度学习基础上,唐晓波等[12]提出先通过TF-IDF 和LDA 提取关键词,再使用Word2vec扩展词向量模型,虽然Word2vec 构造词向量会考虑上下文语义关系,但是Word2vec生成的词和向量一一对应,无法解决一词多义现象,并且对于问句中新词、网络流行词等频率较低的词效果较差,导致部分问句分类失真。
综上所述,本文综合维基百科和深度学习的优点,在保留中文问句语义信息的前提下,引入Word2vec和维基百科相结合的词向量构造方法,既能最大限度地保留原始问句语义,又能提高中文问句分类效果。
2 基于维基百科和深度学习词向量特征扩展模型
2.1 总体框架
⑴输入层。导入医疗问句原始数据集medical.txt。
⑵预处理层。数据清洗,引入jieba 分词工具对原始数据集分词得到数据集train.txt。
⑶ 词向量构造层。首先采用Word2vec 工具CBOW 和Skip-gram 模型分别构造医疗问句关键词向量vector.txt(对于医疗问句关键词词频低于5 次即舍弃)。然后对train.txt 问句中关键词进行判断,如果在vector.txt 中,则直接获取关键词向量,否则,利用维基百科ESA 算法构建扩展关键词向量。最后将扩展关键词向量合并构成medical_vector.txt。
⑷ 分类输出层。采用TextCNN 对问句分类,总体框架如图1所示。
2.2 词向量构建模型
2.2.1 基于CBOW模型构造词向量
CBOW语言模型是根据词语上下文的联合概率来判断,比如,字符串S 包含一连串词语单词w1,w2,…wT组成,求字符串S是自然语言的概率,公式如下:
其中,Contexti表示该单词的上下文,即它的前后c 个单词。p(wi|Contexti)表示前后c个单词出现的情况下,再出现该单词的概率。例如,问句S=“小孩咳嗽应该怎么治疗?”,对问句S分词后为“小孩/咳嗽/应该/怎么/治疗”得到6个单词,如图2所示。
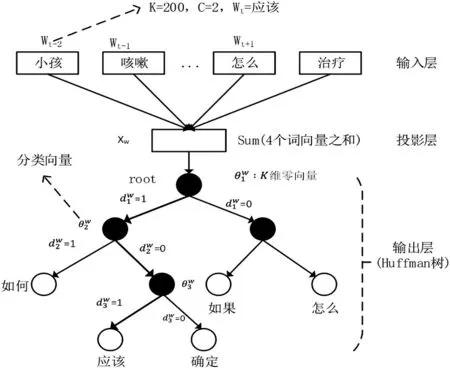
图2 基于CBOW模型构造词向量
除了上述的CBOW 语言模型外,Word2vec 还有Skip-gram语言模型,Skip-gram模型和CBOW模型不同的是,已知当前词w,需要推测出它的上下文。
2.2.2 基于中文维基语义相似度词向量构建
维基百科相似度算法ESA 主要是将文本关键词映射到维基百科概念中,采用向量矩阵表示文本向量,TF-IDF表示文本向量的权重,通过余弦相似度来计算文本之间的相关度。以下是ESA算法实现过程。
Step1:对维基百科所有页面分词预处理,统计各个词语wi在某个维基概念页面的TF-IDF值为kj。
Step2:建立词语wi和维基百科概念cj倒排索引,用kj表示它们之间的权重。词语wi有多个维基百科概念cj,按照TF-IDF的值即kj大小排序。
Step3:对目标文档分词预处理,分别用词语集合Ta={wi}、Tb={wi}表示,词语wi的TF-IDF 值用向量{vi}表示,vi表示wi的权重。
Step4:文本Ta中词语wi通过倒排索引,映射到维基百科概念cj,因为一个词语wi有多个维基百科概念cj,所以对它们求和得到cj的权重,文本Ta 用向量空间{qj,q2,q3,q4,…,qn}表示,n 表示维基百科概念数目,同理求得Tb。
Step5:用余弦值求两文本向量的相关度Red(Ta,Tb)。
Step6:最后根据相关度大小获得词语K 维扩展向量空间。
ESA 算法有效地利用了维基百科巨大的概念库,基本上可以处所有的词语,相比于知网的词典计算,它覆盖面更广,而且对于网络新词、专有名词处理也有较好的效果。但是ESA 也有自己的缺点,ESA 只是简单的概念映射,容易引入噪声数据。此外,ESA 需要考虑维基百科页面所有数据,预处理阶段花费更多时间和资源,表示文本向量时包括所有的维基百科概念,计算量过大。
而采用深度学习Word2vec 工具对问句进行词向量训练,不仅速度快,而且效率高,但是对于一些同义词、网络流行词的处理效果不太好。因此本文采用中文维基百科与深度学习相结合的词向量特征扩展模型,既能保持医疗问句词向量的语义结构,又能构造网络流行词、同义词特征向量空间。
3 实验结果分析
3.1 实验数据集
本文对中文医疗问句进行分类,其中训练语料有两大来源,一是通过网络爬虫从好大夫网站(https://www.haodf.com/)爬取63992 条医疗问句。二是从中文维基百科知识库抽取医疗关键词信息。
3.2 实验环境
实验运行环境为Windows 10,内存配置16GB,CPU 配置Intel i7 9700,编译环境为Anconda3,编程语言Python 3.9,深度学习框架TensorFlow 1.14,分词器采用jieba,使用Gensim包构建Word2vec词向量。
3.3 实验设计
3.3.1 数据预处理
从“好大夫”网获取的医疗问句数据,我们对其做以下预处理操作:
⑴数据清洗,清除原始医疗问句中错误数据、无效数据、重复数据;
⑵将医疗问句数据分成包括内科、外科、儿科、耳鼻喉科、眼科、妇科、男科、皮肤科、中医科、传染病科10大类;
⑶使用jieba 分词器进行分词,结合中文维基百科提高医学类专有名词提高分词准确率;
⑷将预处理的医疗问句数据集分成10 份,按照8:1:1的比例确定训练集、测试集、验证集三大类。
3.3.2 构建词向量
本文采用Gensim 包构建Word2vec 词向量,词向量维度设置300,训练窗口大小默认设置5,训练算法模型为CBOW和Skip-gram。采用准确率(P)、召回率(R)、均衡参数(F)对实验结果评价,相关公式如下:

3.4 实验结果分析
本实验对医疗问句分类采用TextCNN 模型,分别对传统的词袋模型(BOW),CBOW 直接训练词向量模型(CBOW)、Skip-gram 直接训练词向量模型(SG)、CBOW+维基百科模型(WCBOW)、Skip-gram+维基百科模型(WSG)进行比较,这五种不同方法的分类效果对比如表1所示。
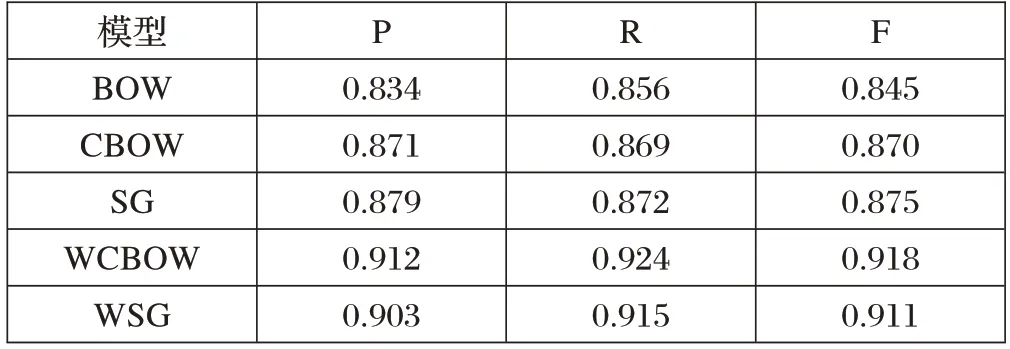
表1 不同模型分类效果对比
由表1可知,CBOW+维基百科模型(WCBOW)分类效果最佳,P值、R 值、F值均为最高,达到0.912、0.924、0.918,相对于传统的SG 方法分别提升了3.6%、5.9%、4.9%。由此可见,基于CBOW+维基百科(WCBOW)模型相比BOW、CBOW、SG、WSG有效可行。
4 结束语
由于医疗问句关键词较少、向量稀疏,对其分类存在困难,因此本文提出了基于深度维基学习的词向量扩展模型。核心思想是通过CBOW 方法对问句关键词训练生成词向量,对稀有特征词采用维基百科语义结构生成词向量,合并后构成问句关键词特征向量空间,实验表明本文方法由于传统的Skip-gram、CBOW、BOW模型。
本文方法提升了医疗问句分类效果,改善了智能问诊系统的效率,同时,也为其他短文分类提供依据。但本文中基于维基百科和深度学习词向量构造方法也存在一定局限,它忽略了问句关键词前后之间的语义关系,后续研究可尝试从卷积神经网络扩展关键词向量。
猜你喜欢
英语世界(2023年10期)2023-11-17
新高考·高一数学(2022年3期)2022-04-28
英语文摘(2021年8期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
读者·原创版(2015年11期)2015-03-01
大连民族大学学报(2015年2期)2015-02-27
