
一种基于禁忌搜索优化的全比较数据分发策略
2022-11-18 05:56李雷孝杨艳艳王永生
小型微型计算机系统 2022年11期
邓 丹,李雷孝,高 静,杨艳艳,王永生
1(内蒙古工业大学 数据科学与应用学院,呼和浩特 010080)2(内蒙古农业大学 计算机与信息工程学院,呼和浩特 010011)
1 引 言
全比较问题(All-To-All Comparison,ATAC)源于在分布式系统中求解多序列比对任务时的数据分发和任务调度工作.通过求解全比较问题,能够得到一个数据分发策略,该策略包含一个数据分发方案和一个任务调度方案.求解全比较问题的分布式系统根据得到的数据分发方案进行文件分发,一对一的比对任务依据任务调度方案在节点间进行调度.之所以说一对一的比对任务是因为多序列比对工作的原子性操作是两个不相同文件间的比对.全比较计算频繁出现在众多学科领域,如生物信息学、自然语言处理、网络工程等.在生物信息学中,典型的全比较计算应用如基因序列比对[1]、组装[2]和蛋白质序列比对[3]时数据文件的分发.自然语言处理领域的语义相似度的计算[4]的数据分发同样是全比较计算的应用场景.点对点网络作为当前研究热点,其数据发送问题同样是全比较计算的应用之一[5].
在生物信息学领域全比较计算数据分发工作的研究在此之前主要分为3类.分别是全量分发、使用Hadoop的分布式文件系统(Hadoop Distributed File System,HDFS)进行分发以及基于全比较数据分发算法进行分发.
Fumihik等人在研究利用空闲GPU来加速生物序列比对时,将需要比对的数据往每个计算节点上都发送一份[6].这种分发方式适合于数据量较小的场景,当面对海量数据时,将造成严重的存储资源浪费.全量分发的方式没有专门的负载均衡调度器,使得任务的调度需要第三方框架的支持.
邹全等人在构建系统发育树时,使用了HDFS来进行分布式存储[7].HDFS默认采用副本数为3的分布式存储方案,这种存储方式能节约存储空间.能够随着节点数量的增加,不断提高存储节约率.HDFS存储有两个问题.一个是副本数为3的存储方案,不一定是最佳的,有时需要调整副本数量以适应任务的计算速度.官方没有给出调整方案,因此用户无法进行有效的调整.另一个问题是,节点数量通常是大于副本数的,无法实现完全数据本地化.HDFS是一个块存储的分布式存储系统,当文件小于块大小时将占用整个块,从而造成存储浪费.当文件大于块时,将被拆分成多个块进行存储.在这种情况下,同样无法实现数据文件的完全本地化.Eun-Kyu等人使用Lustre软件平台对HDFS进行了优化,消除了HDFS数据传输产生的开销,但还是存在数据不能完全本地化的问题[8].
针对全量分发和使用HDFS存储存在的问题,自2014年就有学者专门研究全比较计算的数据分发问题.表1对现有的全比较数据分发算法的优点与不足做了分析.

表1 现有的全比较计算数据分发算法分析
针对全量分发方式存在的存储空间浪费问题,使用HDFS存储无法实现完全数据本地化.使用启发式解决方案、分支定界法存在的解空间较大以及计算耗时等问题.提出了基于禁忌搜索优化[15]的全比较计算数据分发模型(Data Distribution model of All-to-All comparison computation Based on Tabu Search optimization,DDBTS),为求解DDBTS模型设计了基于禁忌搜索优化的负载均衡全比较数据分发算法(All-to-all Comparison Data Distribution for Load Balancing Based on Tabu Search optimization,DDLBBTS)和基于禁忌搜索优化的最小化存储全比较数据分发算法(All-to-all Comparison Data Distribution for Minimum Storage Based on Tabu Search optimization,DDMSBTS).其中,DDMSBTS算法依赖DDLBBTS算法的计算结果.在实验部分将对DDBTS模型的负载均衡、存储节约能力、数据本地化率、计算速度以及存储优化效果进行验证,并与现有的主流全比较数据分发策略进行比较.
2 全比较计算数据分发模型构建
2.1 形式化描述
现有m个数据文件,文件大小完全相等或近似相等.使用具有n个节点的分布式系统来计算任意两个文件的相似度.则全比较计算的形式化表述如公式(1)所示.
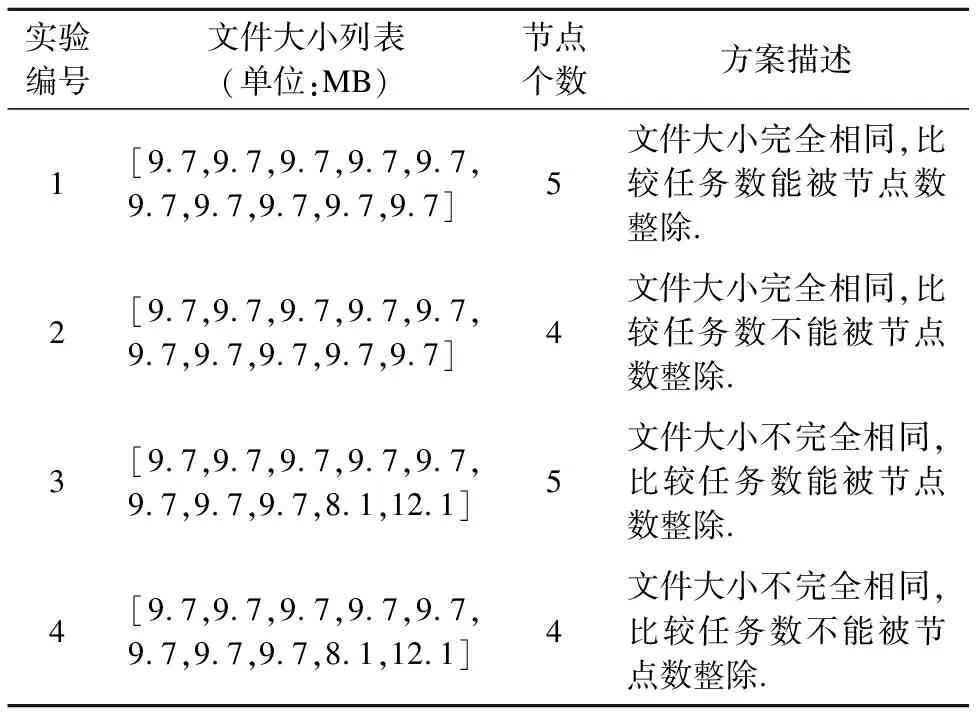
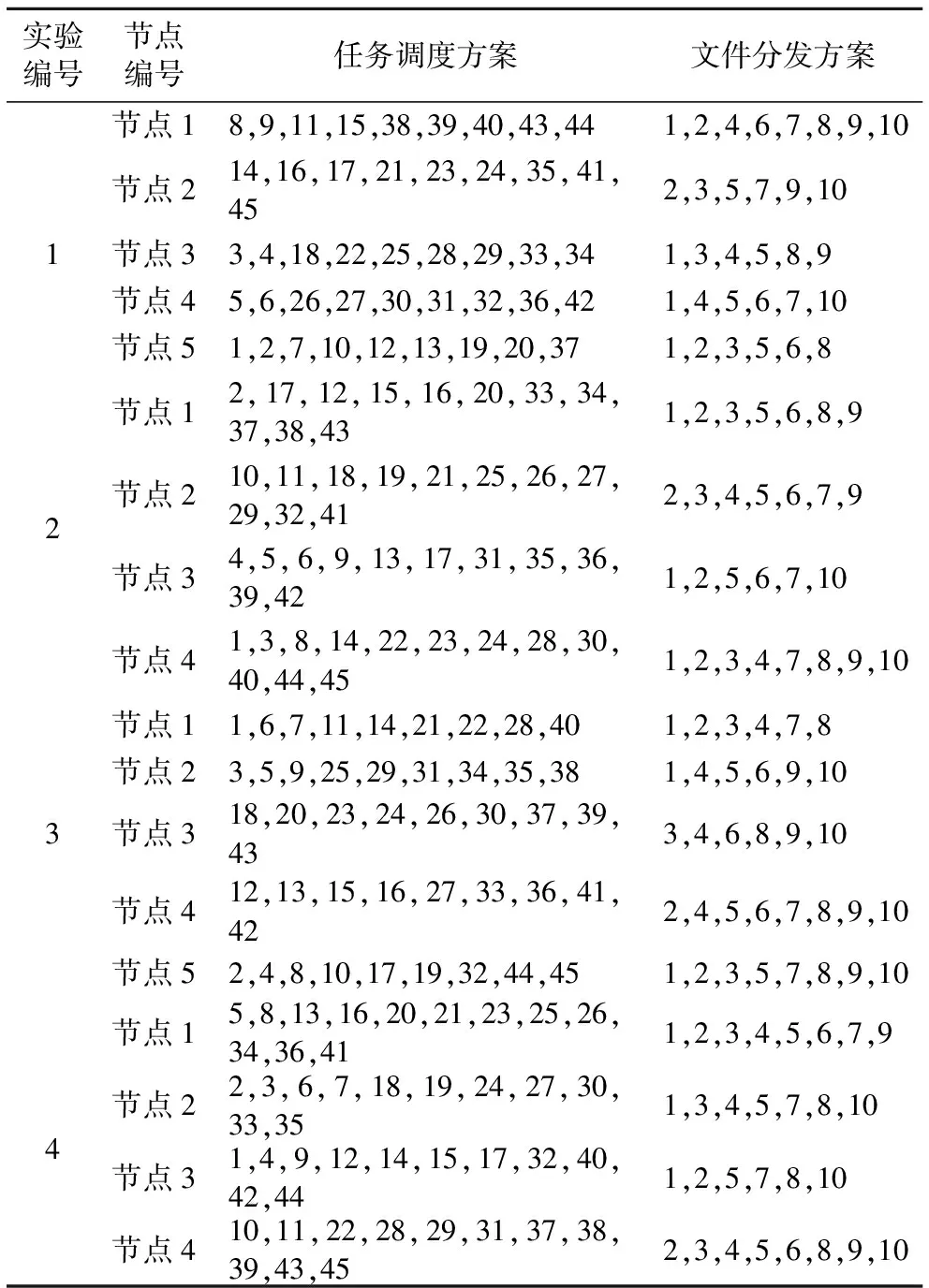
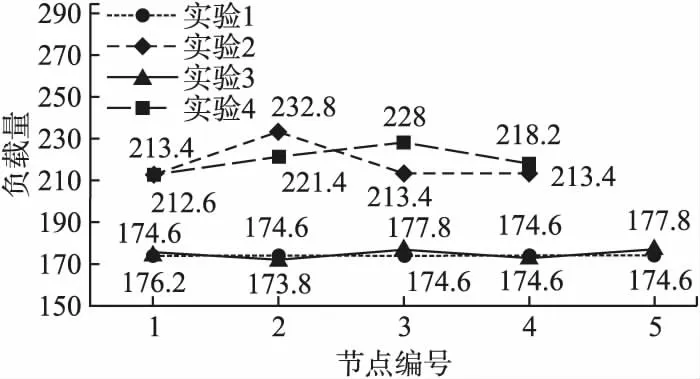
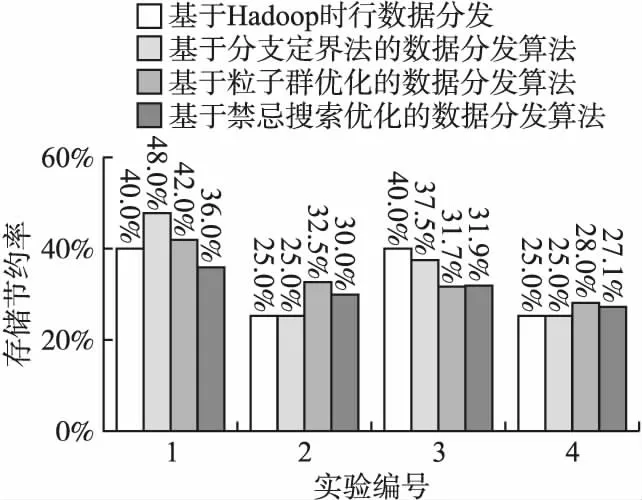
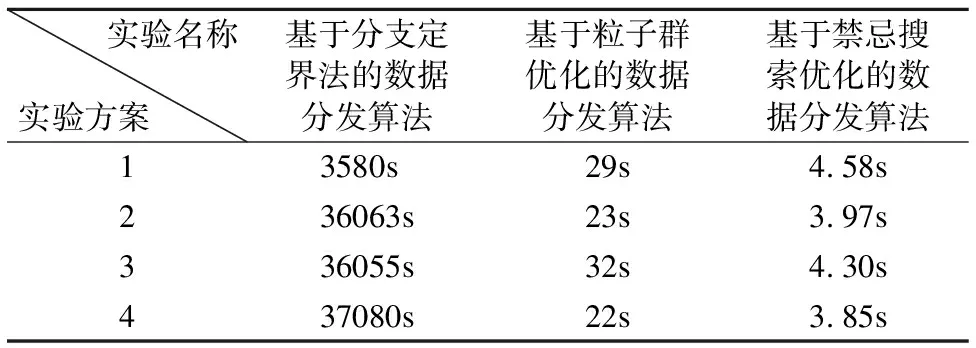
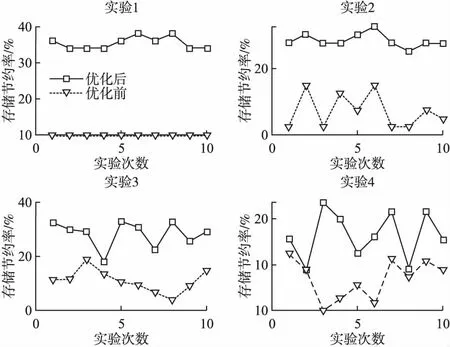
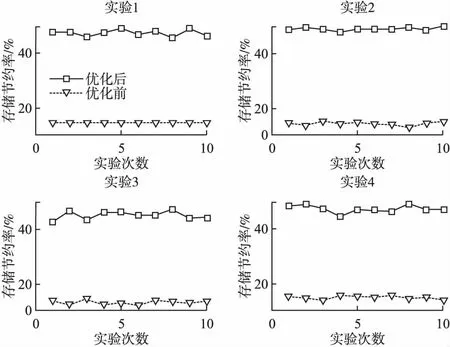
Mi,j={C(i,j)|i (1) 其中Mi,j为任务C(i,j)的计算结果,i与j是文件编号,所有的Mi,j组成了全比较计算的解.在构建全比较数据分发模型之前,先提出两个基本假设. 假设1.全比较计算任务的执行环境为同构分布式系统.本文研究的是在同构分布式系统[16]中进行的全比较计算数据分发方案,节点具有相同的计算速度与存储能力. 假设2.数据文件大小完全相等或近似相等.全比较计算涉及的数据文件的存储单位均为MB,文件大小数值差异不超过2. 有一组基因序列文件S={s1,s2,…,sm},S中的m个文件的大小近似相等.现要将这m个基因序列文件在分布式系统中进行两两文件的比对,令比对的总任务数为k,根据组合数计算公式可得k的数学表达形式如公式(2)所示[17]. (2) 某个序列比对任务的任务量和参与比对的数据文件大小成正比.令ct表示由文件i与文件j组成的任务t的任务量,第i个文件的大小用si来表示.则ct为: ct=si+sj,t={1,2,…,k},i i=1,2,…,m-1,j=2,3,…,m (3) (4) (5) 要获得全比较计算在分布式系统下负载均衡的数据分发方案,先要得到节点p所需承担的计算量wp,wp的形式化描述如公式(6)所示. (6) 使用wavg来表示在进行本次全比较计算时,分布式系统中的节点平均计算量.由于wp是在寻优的过程中动态生成的,因此不能通过公式(6)来进行求解.但是能够通过公式(2)与公式(3)以及节点个数n来获取wavg.计算方法如公式(7)所示. (7) 本文所述的负载均衡是指分布式系统中各个节点上的计算量负载要尽可能相同.负载均衡状态能通过累加wp与wavg差值的绝对值来表征.完全负载均衡时,该绝对值为0.但初始值一般是大于零的值,寻优过程实质上是不断缩小这个绝对值,使得这个绝对值的右极限为0.由公式(2)、公式(6)、公式(7)能求出负载均衡模型目标函数的形式化描述如公式(8). (8) 硬盘资源是计算机的重要资源之一,是DDBTS模型中必须要考虑的一个因素.为了保证全比较计算的性能,需要让所有节点都能存储全部的数据文件.令同构分布式系统中节点的硬盘剩余容量为U,则负载均衡模型的存储约束能够形式化地描述为: (9) 公式(2)-公式(9)能得出m个序列数据文件在由n个节点组成的同构分布式系统中的全比较计算负载均衡模型如公式(10)所示. (10) 根据负载均衡模型,能求出在分布式系统下进行全比较计算的任务调度方案.将任务调度方案与任务列表进行联合解析,可得到全比较计算的数据分发方案.负载均衡模型求得的数据分发方案只能满足全比较计算的计算量负载均衡目标,在下一节中将在公式(10)的基础上进行存储优化. 通过公式(10)求得的任务调度方案可以计算出全部节点的计算量,将节点的最大计算量记为Nmax.在存储优化过程中,要保证每个节点所承担的任务量都不超过Nmax.即: (11) (12) 综上所述,可得在n个节点的分布式系统下进行m个文件的全比较计算,同时满足负载均衡和最小化存储的数据分发模型为: (13) 通过对公式(13)进行解析,即可得到计算量负载均衡的全比较计算任务调度方案和实现分布式系统下的最小化存储数据文件分发方案. DDBTS模型分为两个阶段进行计算,第1阶段根据公式(10)求出负载均衡状态的任务调度方案.第2阶段根据公式(13)求得基于禁忌搜索优化的全比较计算数据分发方案.任务调度方案和数据分发方案共同组成全比较数据分发策略,该策略满足负载均衡、最小化存储和数据完全本地化. 禁忌搜索算法是Glover教授于1986年提出来的,显著的优点之一是能基于禁忌表实现记忆式搜索[18].禁忌搜索算法的算子包括:适应度方程、编码方案、邻域结构、邻域长度、候选解、禁忌表、禁忌长度和藐视准则.禁忌搜索算法因具有快速收敛的特性而被选作与全比较计算数据分发模型进行融合.在算法的设计与实现过程中,对禁忌搜索算法的算子进行了定制化实现. 1)初始化参数 DDLBBTS算法涉及的一些参数的描述和初始化取值如表2所示. 表2 DDLBBTS算法参数设置 2)n进制编码 DDLBBTS算法的编码方案采用n进制编码,n为节点数量,编码长度表征任务个数.在DDLBBTS算法中,n进制编码的现实意义为某个任务应该被分派到某一个节点上. 3)负载偏离程度计算函数 DDLBBTS算法的适配值函数f1须满足公式(10)中的目标函数,即求出编码方案对应的负载均衡偏离程度loadtotal.在求解过程中,能够得到每个节点的计算量负载情况,用loadi表示节点i的计算量负载情况.loadi的取值覆盖整个实数域,大于0时表示节点负载超标,小于0表示节点负载过少,节点的计算量负载等于计算量负载的均值时loadi为0.使用offset存储所有的loadi并将loadtotal和offset作为f1的返回值,称该适配值函数为负载偏离程度计算函数. 4)正向任务调度规则 邻域结构是禁忌搜索算法中的一个关键算子,常用的邻域结构设计方法包括互换、插值、逆序等[19].这些常用的邻域设计方法通常需要随机选取编码的位置,随机选取编码的位置在DDLBBTS算法中是不适用的.故本文提出使用正向任务调度规则作为DDLBBTS算法的邻域结构,其核心思想为找出待分配的任务和待指派的节点,并将任务随机分派到待指派的节点上.从负载超标的节点上选取一个任务调度到负载过少的节点上进行计算.使用正向任务调度规则作为邻域设计方案,能动态调整节点之间的负载,让节点的计算量负载朝着均分的方向优化.在定位负载超标节点时,如果出现了负载超标节点数量为0的情况,则说明该编码方案是最优状态,应立即终止寻优迭代并将当前最优状态对应的编码bestsoforlb输出.否则,构建一个待选择任务的集合x并找出所有负载过少的节点集合Y.从X选出一个任务xi调度到Y中的节点yi上,组成DDLBBTS算法的邻域结构A. 5)负载均衡邻域解与候选解 6)负载均衡藐视准则 DDLBBTS算法采用n进制编码、正向任务调度等定制化规则与公式(10)进行融合.最终设计出DDLBBTS算法如算法1所示.第5行-第11行对全比较数据分发的一种特殊情况进行了优化.当文件大小完全相同且比较任务能够被均匀分发到节点时,只需为每个节点指派等量的任务即可让分布式系统达到完全负载均衡状态.第16行-第32行是正向任务调度规则的实现.第33行通过对邻域解的负载偏离程度进行升序排序得到Cabest.第34行-第42行是负载均衡藐视准则的实现. 算法1.基于禁忌搜索优化的负载均衡全比较数据分发算法 输入:文件大小列表files、节点数量n、剩余存储capacity 1. 根据公式(9)对files,capacity进行计算; 2. 计算文件个数m←size(files,2); 3. 根据公式(3)构建任务矩阵tasks; 4. 计算任务个数tc←size(tasks,1); 5.ifsize(unique(files),2)=1andmod(tc,n)=0then 6.fori1totcby1 do 7.bestsofarlb(i)←mod(i,n)+1; 8.endfor 10. return; 11.endif 16. 找出能够提供任务的节点编号: [~,nodes]←find(offset>0); 17. 计算能够提供待指派任务的节点个数 num←size(nodes,2); 18.ifnum← 0then 19. break; 20.endif 21. 令邻解个数LCa←0;令待调度任务集合X←[]; 22.fori1tonumby1do 25.endfor 26. 找出待指派的节点编号Y←find(offset<0); 27. 初始化邻域结构A←[],迭代变量i←1; 28.whilei≤LCado 29.if[xi,yi]∉Athen 30.A=[A;[xi,yi]]; 31.endif 32.endwhile 33. 计算邻域解并求出候选解Cabest; 36.else 37.fori1tosize(tabu1,1)by1do 38.loadtotal←从Cabest找出第一个优于tabu1(i)的候选解; 39. 更新相关参数; 40.endfor 42.endif 43.p←p+1; 44.endwhile 1)初始化参数 表3 DDMSBTS算法参数设置 2)存储优化适配值函数 DDMSBTS算法的适配值函数f2旨在根据公式(12)求出分布式系统所需提供的存储空间,同时得到公式(11)左边表示的所有节点计算量负载nodeLoads并求出最大的节点计算量负载nodeLoadmax.为了保证在寻优过程中负载均衡情况不变坏,全部节点计算量负载的极差不能超过任务列表中的最大任务量taskmax,否则要对当前编码方案对应的nodeLoadmax进行惩罚.上述描述能够形式化表示成公式(14). (14) 3)异节点任务互换 由公式(1)可知全比较计算的任务需要两个不同的文件,在一次全比较计算中,任务具有原子性和唯一性.因此,通过交换不同节点上的两个任务能够对节点上的文件分发方案进行扰动.不断选择存储空间减小的编码方案,从而达到寻优目标.基于以上思想,能够得到一个邻域结构B. 4)负载约束邻域解与最优存储候选解 5)最优存储藐视准则 6)自适应迭代次数 算法2.基于禁忌搜索优化的最小化存储全比较数据分发算法 输入:files、n、bestsofarlb、最大节点计算量maxLoad 1. 计算文件个数m←size(files,2); 2. 根据公式(3)构建任务矩阵tasks; 3. 计算任务个数tc←size(tasks,1); 8. 初始化邻域结构B←zeros(LCa,2),当前迭代次数i←1; 9.whilei≤LCado 10.task1← 随机取出一个任务; 12.task2←从other中随机取出第二个任务; 13.B(i,1)←max(task1,task2),B(i,2)←min(task1,task2); 14. 保证B(i,j)的唯一性; 15.endwhile 16. 设置邻域长度LCabest←round(LCa/2); 17. 设置邻域集合Cabest←Inf×ones(LCabest,4); 18. 设置适配值集合F←zeros(1,LCa); 19.fori1toLCaby1do 22. [nodeLoadmax,F(i)]←f2(SetCa(i,:),task,n,files); 23.ifnodeLoadmax>maxLoadthen 24.F(i)←Inf; 25.endif 26. 更新Cabest; 27.endfor 28.ifCabest(1,2)≤Rmsthen 30.else 31.fori1toLCabestby1do 32.iftabu2(Cabest(i,3),Cabest(i,4))=0then 34.endif 35.endfor 36.endif 41.endif 42.endif 43.p←p+1; 45.endwhile 实验环境的配置不仅要能支撑本文提出的数据分发算法的运行,同时要支持运行现有的主流数据分发算法以便于实验对比工作的开展.详细配置情况如表4所示.实验数据选用从NCBI下载的基因序列数据,数据扩充采用文件切分的方式进行. 表4 实验环境 本文将基于MATLAB对全比较计算数据分发模型进行实现,并完成评价指标验证和对比实验.在VMWare上构建Hadoop平台,使用Java编写全比较计算模拟程序对基因序列数据文件进行分发,以及调度全比较任务. 为了验证DDBTS模型的性能,进行了负载均衡、存储节约率与数据本地化、求解效率、存储优化等实验.前3个实验将对比DDBTS模型求得数据分发策略与现有主流数据分发策略的性能差异.存储优化实验将对DDMSBTS算法的存储空间优化效果进行验证. 对DDBTS模型进行求解,能够得到一套分布式系统下的任务调度方案和数据分发方案.根据任务调度方案能分析出分布式系统下全比较计算的负载均衡程度,对数据分发方案按节点进行存储空间统计并结合全量分发的存储使用情况能得出分布式系统下全比较计算的存储节约率.对各个节点完成指定计算任务所需的数据分发情况和对应节点上的数据分发方案进行计算,能算出数据分发策略在分布式系统下的数据本地化率.对DDBTS模型中两个算法的执行时间进行记录,即可得到模型的计算时间. 负载均衡程度.对节点i的任务量进行统计可得li,所有的li组成集合L.由任务列表可得最大的任务量为tmax.若L中的元素完全相等,则当前全比较计算任务调度方案实现了完全负载均衡.若L中的元素不完全相等,但L中的最大值和最小值之差未超过tmax,称这种状态是近似负载均衡状态.其它情况均为非负载均衡状态. 存储节约率.存储节约率是DDBTS模型重要评价指标之一,也是DDMSBTS算法的优化目标.将全量分发情况下分布式系统所需提供的存储空间作为分母,分子为DDBTS模型计算所得的数据分发方案对应的存储空间.这个分数能够表征分布式系统的存储空间利用率,故存储节约率为1减去存储空间利用率. 数据本地化率.若计算节点执行全部比较任务所需的文件都在某个节点上,则该节点的数据本地化率为1,对应的状态称为完全数据本地化.否则,取在该节点上有效文件的总大小与所需文件的总大小的比值来描述计算节点的数据本地化率. 计算时间.计算时间表示全比较数据分发策略的求解时间,在DDBTS模型中,该评价指标主要包括DDLBBTS算法和DDMSBTS算法的执行时间,由驱动模块进行统计. 在这个实验中,对DDBTS模型进行了若干次实验.其中的一组实验数据及相关描述如表5所示. 表5 实验数据 根据表5对DDBTS模型进行多次实验,求出各组实验方案对应的全比较计算的任务调度方案与文件分发方案.随机选取一次实验的结果,如表6所示. 表6 任务调度与文件分发情况 4.3.1 负载均衡 将表5中的实验数据放入基于禁忌搜索优化实现的全比较数据分发模型,得到模型的负载均衡情况如图1所示.各组实验的负载均衡情况,与基于分支定界法求解的全比较数据分发模型和基于粒子群优化的全比较数据分发模型的负载均衡情况表现基本一致.即当文件大小完全相同且比较任务数能被节点数整除时,分布式集群中各个节点的负载量能够实现完全均衡.其余情况下,均能让分布式集群中的各个节点实现近似负载均衡状态. 图1 负载均衡情况 4.3.2 存储节约率与数据本地化率 为了与现有的数据分发算法对比存储节约率和数据本地化率,我们得到了如图2所示的存储节约情况和图3所示的数据本地化情况. 图2 不同数据分发算法的存储节约情况 图3 不同数据分发算法的数据本地化情况 由图2可知,基于禁忌搜索优化的全比较数据分发模型获得的数据分发方案能够有效地降低分布式集群中节点的存储空间使用.在实验2和实验4中,基于禁忌搜索优化的全比较数据分发模型的存储节约率均优于基于Hadoop进行数据分发的方式和基于分支定界法求解的数据分发算法.在实验1和实验3中,基于禁忌搜索优化的全比较数据分发模型的存储节约情况比基于Hadoop进行数据分发的方式要略差.根据图3可知,尽管在存储节约情况方面基于Hadoop的数据分发方式能够实现较优于基于禁忌搜索优化的全比较数据分发模型,但是基于Hadoop数据分发方式的数据本地化情况较差.在进行全比较计算的过程中,需要从其它节点或数据中心获取文件,极有可能造成网络拥堵. 4.3.3 求解效率 通过记录每组实验的计算时间,我们得到了如表7所示的3种数据分发算法的执行时间.显然,DDBTS模型在各个实验方案的计算速度上都是领先的.尽管在图2中,基于禁忌搜索优化的全比较数据分发模型的存储节约率不如基于分支定界法的数据分发算法和基于粒子群优化的数据分发算法,但其计算速度远比这两种算法快,更适合于实际的工程应用场景. 表7 不同数据分发算法的计算时间 4.3.4 存储优化实验 分别针对不同任务规模量、计算节点数量的输入数据进行了实验.对DDBTS模型优化前后的负载均衡情况与存储节约率进行了分析.实验设置和相关实验结果及分析如下所示. 1)小规模数据量实验 随机选取10个大小近似相等的基因序列文件,分布式集群的规模分别选取5个计算节点或4个计算节点.设计了4组小规模数据量实验,实验的输入数据如表8所示. 表8 小规模数据量实验输入数据 本文对实验5-实验8依次进行了10次实验,实验结果如图4所示.在小规模数据量的情况下,DDBTS模型在存储优化之后的存储节约率基本有改善.实验5表现得尤为明显,由DDLBBTS算法获得的文件分发方案对应的存储节约率仅为10%,而DDMSBTS算法输出的文件分发方案对应的存储节约率达到了34%~38%.实验6-实验8虽然节约了一些存储空间,但是存储节约率波动较大.其中,实验8的波动最为严重,优化后的存储节约率的极差为14.7%.这种波动可能是数据量过小导致的,该猜想能够通过大规模数据量实验进行验证. 图4 小规模数据量的存储优化效果 2)大规模数据量实验 在大规模数据量实验中,增加了进行全比较计算的节点,同时增加了全比较计算涉及的文件数量.大规模数据量实验的实验数据如表9所示. 表9 大规模数据量实验输入数据 图5所示的是实验9-实验12的存储优化情况.在存储优化后,实验9-实验12的存储节约率达到了40%-50%.与图4所示的实验5-实验8的存储节约情况进行比较可知,大规模数据量实验的存储优化效果更佳.存储优化后,实验9-实验12的存储节约率极差分别为3.6%、2.23%、4.42%、4.7%,相比于小规模数据实验的存储节约效果要稳定很多.根据DDBTS模型求得的数据分发策略在大规模数据量的情况下,存储节约的效果稳定. 图5 大规模数据量的存储优化效果 本文研究了ATAC的数据分发问题,对主流的全比较数据算法进行了总结.构建了全比较数据分发模型,并提出了DDBTS模型.基于禁忌搜索算法设计了DDLBBTS算法与DDMSBTS算法,最后在MATLAB平台上实现了相关算法.通过实验证明了DDBTS模型求得的数据分发策略能够让分布式系统实现负载均衡,比较任务涉及的数据文件具有完全的数据本地性.尽管在存储节约率方面稍逊于其它ATAC数据分发算法,但是其计算速度却远快于其它ATAC数据分发算法.在存储优化实验中,验证了DDBTS模型中存储优化过程的有效性以及DDBTS模型输出的文件分发方案在大规模数据量下存储效果稳定,存储节约率达到了40%-50%.DDBTS模型有效解决了大规模ATAC的数据分发问题,提高了计算速度,对生物信息学等学科ATAC任务的计算将产生较好的推动效果. DDBTS模型是一个数据预分发模型,在开始ATAC之前即完成任务在分布式节点上的安排.如果出现节点故障,将需要重新进行数据分发方案和任务调度方案的计算.尽管DDBTS模型具备较快的计算速度,如果能够提高任务调度方案的容错能力,模型将更具实用性.因此,提高ATAC数据分发模型的容错性是我们下一步模型优化工作中的重点.本文仅对同构分布式系统下ATAC的数据分发工作进行了研究,在未来的工作中,我们将对异构分布式系统下的数据分发工作进行研究.2.2 负载均衡
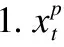
2.3 存储优化
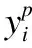
3 DDBTS模型相关算法设计与实现
3.1 DDLBBTS算法设计

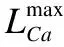
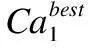
3.2 DDLBBTS算法实现
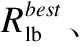
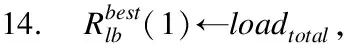

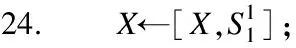
3.3 DDMSBTS算法设计
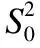

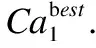
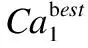
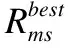
3.4 DDMSBTS算法实现
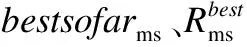
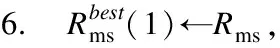
4 实验部分
4.1 实验设置

4.2 评价指标
4.3 相关实验



5 总 结
猜你喜欢
吉林大学学报(信息科学版)(2022年2期)2022-08-15计算机测量与控制(2022年2期)2022-03-30计算机应用与软件(2021年10期)2021-10-15小型微型计算机系统(2020年5期)2020-05-14计算机与生活(2020年5期)2020-05-13火力与指挥控制(2020年1期)2020-03-27作文评点报·低幼版(2019年42期)2019-12-30小学生作文(低年级适用)(2018年10期)2018-10-27小天使·二年级语数英综合(2018年5期)2018-06-29科技与管理(2014年5期)2015-01-06
