
基于数据挖掘的图书推荐系统的分析与设计
2022-11-22 09:08张佳佳章宜玉
信息记录材料 2022年9期
张佳佳,章宜玉
(湖南信息职业技术学院 湖南 长沙 410200)
0 引言
随着我国经济的快速发展和物质生活水平不断提高,人们的精神文化生活日益丰富,阅读已成为人们生活中不可或缺的一部分。得益于移动互联网的迅速发展,手机用户增长迅猛,用户不再只是网站内容消费者,同时也是内容生产者。人们不管在何时何地,都可借助移动终端在网络平台上发表自己的所思所想。现在越来越多的用户倾向于通过微博、豆瓣、博客等网络平台发表书评,进行图书评论。图书评论是读者对书籍质量的一种情感表达,如果能对海量的图书评论数据进行分析处理,从中找到对用户有用的信息,并将其用图形化方式展现出来,就能为用户提供直观有效的图书推荐[1]。
通过对基于数据挖掘的图书推荐系统进行分析与设计,不仅可以帮助读者选择他们感兴趣的图书,也可以帮助出版公司迅速获得读者对书籍的评价与反馈。
1 系统需求分析
目前图书市场上的图书数据量庞大、品种繁多,网络平台上的图书信息良莠不齐,而且存在恶意差评现象,让人难以分辨[2]。因此基于数据挖掘的图书推荐系统要设计爬虫模块,从网络平台抓取图书信息,并对其进行筛选整合。其次,图书评论信息是一个复杂的多模态数据集合,比如每本书都包含有名称、简介、作者、出版社等多维度信息,而作者可能又包含其出版过的其他书籍等信息。因此爬虫模块要通过多维度特征挖掘出更深层次、更全面的信息。微博作为一种新兴的社会化媒体发布平台,以其简短写作、便于发布、实时交互的特点深受大众欢迎,本系统使用爬取自微博平台的图书数据集。爬虫模块是获取系统所需要数据的重要方式,通过在微博网站搜索某个图书关键词,对搜索到的微言以及每条微言的用户评论进行抓取,经过数据筛选和清洗后,保存到本地数据库中[3]。
数据分析模块实现的功能有关键词提取、情感分析和属性关系网构建。采用多种机器学习算法对图书文本数据进行分析与挖掘,并将分析过程中的结果保存到数据库中。
可视化模块是对分析结果的可视化展示,用户可以输入某本图书名称,查看关于该书籍的分析信息,比如图书评分、类别等。
2 开发环境及关键技术
软件是基于Windows 10系统进行的设计。爬虫模块采用最新的Map Reduce分布式框架实现,使用爬虫引擎采集信息并存入MySQL数据库。集成开发环境采用Myeclipse 10.0,其功能强大、操作简便、可有效提高编程效率。可视化模块采用Apache+PHP框架,借助TagCloud和Echarts等插件,实现图形化展示界面。
2.1 爬虫技术
网络爬虫是指在海量的互联网信息中进行爬取,按照特定规则自动抓取有效信息的程序或脚本,目前在搜索引擎、数据挖掘、信息存档等方向应用十分广泛。网络爬虫按照实现的技术原理可以分为通用网络爬虫、主题网络爬虫、增量网络爬虫和深层网络爬虫。网络爬虫的实现过程主要由控制器、解析器和资源库三部分组成,控制器是负责给多线程中的各个爬虫线程分配工作任务,解析器是对爬取的网页进行解析,资源库即采用数据库进行数据存储[4]。
2.2 Map Reduce分布式框架
Map Reduce是一个并行计算与运行的软件框架。它将整个计算过程划为Map和Reduce两个并行运算任务,实现在集群节点上自动分配和执行任务并收集计算结果。用户在使用该框架时只要实现Map和Reduce两个接口,无需关心底层构架,大大减少了软件开发人员的负担[5]。
2.3 MySQL数据库
MySQL数据库是目前软件开发中被广泛应用的开源数据库,其具有稳定、高效、易于开发的优点。爬虫模块共设计三张数据库表,分别是微言信息表、评论信息表、图书信息表。数据分析模块也包含三张数据库表,分别为图书属性信息表、处理结果信息表、作者信息表。
3 系统功能结构设计
基于数据挖掘的图书推荐系统主要包括以下三个模块:爬虫模块、数据分析模块、可视化模块,系统总体设计如图1所示。本章将对各功能模块进行设计说明。
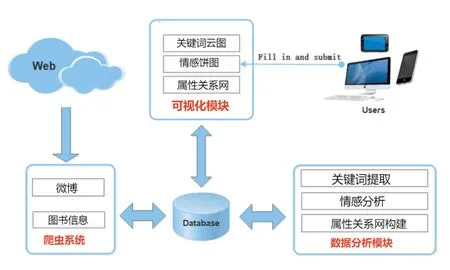
图1 系统总体设计图
3.1 爬虫模块
爬虫模块是一个抓取微博网站数据集的爬虫程序,主要对基于主题关键词搜索的博文以及其评论等信息进行数据采集。其主要实现流程如下,如图2所示。
(1)用户cookie的获取与模拟登录。我们在爬取网站信息时先要登录网站,一般可以通过cookie进行模拟登录来解决。第一步是通过对网页数据进行抓包与分析获取cookie信息,然后使用get方法传入cookie获取网页爬取信息。
(2)多线程抓取。网页上的评论数据过多,我们不能通过for循环一个一个地下载,所以必然要使用多线程,然后把数据队列放入线程池去处理。
(3)多用户切换防止反爬虫。限制爬虫程序访问服务器资源和获取数据的行为称为反爬虫。为了应对反爬虫机制,可采用动态设置User-Agent策略,即随机切换User-Agent的值,以模拟不同用户的浏览器信息。
(4)实现HTTP请求报文的生成。为了获取新浪微博平台的数据,必须向新浪微博服务器发送数据请求报文进行数据请求。可使用requests库的get方法进行HTTP请求,其使用requests方法的语法格式如下:rq=request.get(‘目标网址’)[6]。
(5)实现HTTP返回报文的接收和解压。每向open.weibo.com发送一个HTTP请求数据包后,都可以获得相应的返回数据包。分析HTTP响应报文中的Content-Length参数可以获取数据长度,读取响应报文头中的Content-Encoding值可获取压缩格式,调用对应的解压方法进行报文解压。当然,返回的数据也并不是每一次都正确,我们可通过数据格式判断其是否正确,当数据格式不正确或不完整时,则直接丢弃报文,并打印数据格式错误信息[7]。
(6)对解压后的json文件进行分析和信息提取,利用第三方函数库对得到的json字符串进行解析,提取我们需要的字段内容,并存入到数据库中。将爬虫获取的数据存入数据库,需要在pipeline里完成,pipeline的功能默认是关闭的,要在settings.py中开启数据入库命令。
(7)对待抓取和已抓取的URL建立缓存机制。对每个入库函数都开启一个独立的线程。当相应的缓存容器中的数据达到一定的数量时,对数据容器进行锁定,暂停相应的爬虫函数,开始对数据进行入库。入库后将该数据从缓存容器删除,然后解除容器锁定,继续爬虫[8]。

图2 爬虫模块实现流程
3.2 数据分析模块
数据分析模块主要包含关键词提取、情感分析、属性关系网构建三个子功能模块。
(1)关键词提取:该功能块使用基于语义的中文文本关键词提取(SKE)算法[9]从每条微博中提取关键词。基于关键词的出现频率进行统计,我们从中选择出频率最高的50个关键词,将其存入数据库中用于后续的情感分析,其实现流程如图3所示。

图3 关键词提取实现流程
(2)情感分析:在该模块中,对微博中的每条信息进行分词处理后,利用情感分析算法将其归类为积极情绪和消极情绪,并计算每种情绪所占百分比,将其保存到数据库中[10]。其实现流程如图4所示。

图4 情感分析实现流程
(3)属性关系网构建:通过构建属性关系网,用户可以点击该网络中的任何节点并查看与其相关联的信息。例如,某个作者还出版了哪些图书。其实现流程如图5所示[11]。

图5 属性关系网实现流程
3.3 可视化模块
可视化模块是系统的展示模块,当用户在系统首页输入一个图书名称时,界面将会呈现出来三个功能,包括关键词3D云图、情感分析饼图、图书属性关系网。其实现过程如图6所示。
关键词云图:可将系统中关于该图书出现频率较高的关键词以可视化形式展现出来,它能过滤掉大量低频低质的文本信息,让用户在短时间内对某本图书的评价信息能一目了然。
情感分析饼图:心理学研究发现人们普遍有从众心理,人们对某个物品的喜好或情感状态会受到大多数人的情感影响。比如当你搜索一本未阅读过的图书时,网友们对该书籍的评分高低会影响你是否阅读该书。用户根据数据分析模块得到情感分析结果,可以了解大众对某本图书的偏好与评价,有利于用户进行决策或选择[12-13]。
图书属性关系网:网络上的图书数据是一个多模态数据,比如一本图书的作者又包含还出版过其他哪些书等信息[14]。关系网为各个属性提供了联动交互,使用户可以探索不同维度数据之间的关系。用户单击该关系网中任意节点可查看与之关联的信息。
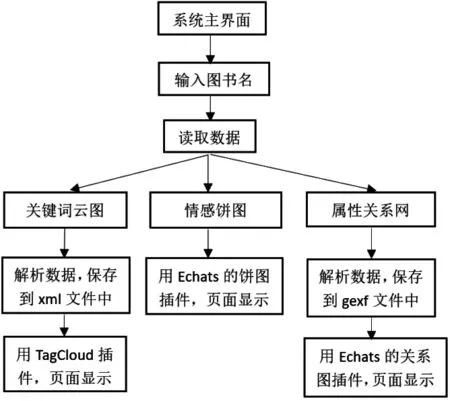
图6 可视化模块实现流程
4 结语
本文分析了基于数据挖掘的图书推荐系统的实际需求,并对系统的设计展开描述。对图书信息进行数据挖掘,获取图书信息,然后对数据进行清洗和处理。并在此基础上进行情感分类研究,为读者提供可视化结果。本系统不仅能节约读者寻找图书资源的时间,为读者提供更加有效的图书推荐,同时也能使出版社与编辑及时了解大众对图书的评价与反馈,并对后续的图书内容与经营策略等方面起到辅助作用。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
南风(2020年22期)2020-09-15
小学生优秀作文(低年级)(2019年5期)2019-04-25
电子制作(2018年2期)2018-04-18
小学阅读指南·低年级版(2017年12期)2017-12-26
