
基于伴随式数据采集和决策树算法的智库人才信息处理技术
2022-12-01 06:00韦冬妮车彬张泽龙唐梦媛齐彩娟
电子设计工程 2022年23期
韦冬妮,车彬,张泽龙,唐梦媛,齐彩娟
(国网宁夏电力有限公司经济技术研究院,宁夏 银川 750002)
智库是企业战略研究以及拥有强大竞争力的关键,企业智库信息的管理覆盖面广、涉及数据量大,需要应用的技术手段众多[1-3]。目前,企业智库通常缺乏系统、高效的数据管理模式,且在利用智库数据进行培养结果评价和人员岗位匹配等方面不够深入,海量的数据管理难以产生边际效益[4-7]。企业智库蕴含着大量关于人才培养过程的数据信息,如何结合先进的信息处理技术,深入挖掘出它的价值,推动企业人才队伍建设,是值得重点研究的问题。
针对此问题,该文将伴随式数据采集和决策树技术应用于智库信息处理,实现了人才评价分类与精准岗位匹配,优化了企业人才资源的配置。
1 伴随式数据采集技术
数据采集是实现智库信息流动、人才评价的基本前提。智库人才评价的实现是以动态学习、数据分析为基础,通过存储、访问、处理相关学习数据,在智库人才信息管理的同时实现伴随式评价[8]。
该文构建的基于伴随式智库信息系统架构,如图1 所示。其包括系统层、服务层、数据层和应用层[9],从课程面授、实践操作、案例示范、岗位指导这四类不同的培养场景出发,实时获取人才素质数据信息,并动态分析人才素质特征,从而实现人才素质特征的准确智能分类[10]。
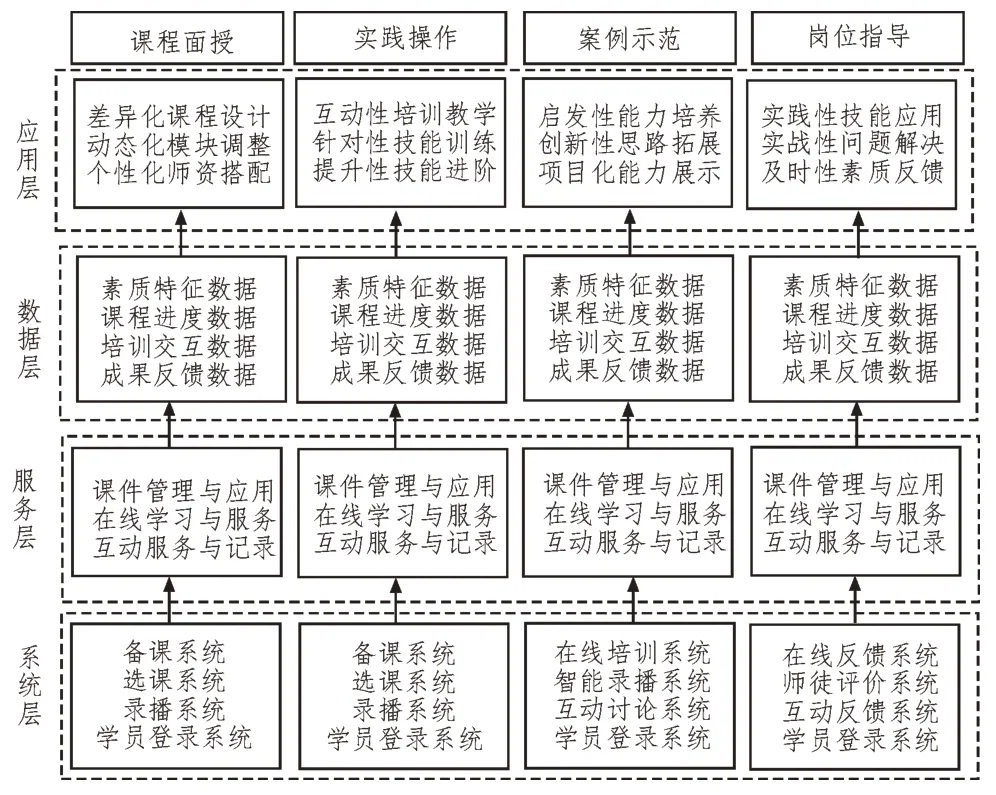
图1 基于伴随式数据采集的智库信息系统架构
1.1 数据存储
数据存储技术主要用于实现学员个人信息、曾参与的项目成果、工作学习经历等人才素质数据的大规模存储。该文采用了Hadoop 分布式文件系统(HDFS),该系统是当前的主流大数据存储框架方案之一。HDFS 适用于海量数据结构场景,融合元数据与数据块技术实现数据信息的集中管控和分布式储存,不但具有高度容错的性能,而且适用于智库海量数据的存储,同时,也可以兼顾数据使用过程中的准确抽取。
1.2 数据访问
数据访问技术能够支持学员根据自身情况随时获取智库信息系统的教学内容等课程数据,采用的核心技术主要有Pig、Hive、Sqoop 等。Pig 是一种适用于HDFS 系统的高级编程语言,能够实现将数据查询请求分解为快速优化的MapReduce 运算,且支持并行处理;Hive 是一种数据库管理工具,能够实现HDFS 系统中海量数据的快速检索与获取;Sqoop 是一种开放性的数据处理工具,能够实现HDFS 系统与常规数据库的数据信息传输。
1.3 数据处理
数据处理技术用于实现培训指导过程中教学互动数据的处理分析,具体的技术解决方案为HBase和Flume。HBase 是一种针对列存储应用的非关系型数据库,其综合性能优异,可以实现大规模数据集的实时读写;Flume 是由Cloudera 开发的日志收集系统,提供分布式数据流收集服务。
1.4 数据分析
数据分析技术利用智库信息系统中学员参与课程的数据,为学员提供岗位匹配、课程评价、课程改进等相关数据服务。其中,通常使用的数据分析技术有Mahout 和Hama 技术。Mahout 是开放性的代码库,支持分散式人工智能学习,能够实现应用服务程序的快捷创建;Hama 可以支持海量数据并行计算,在矩阵分析、图谱计算等方面应用广泛。
2 基于决策树的人才岗位匹配算法
人才岗位匹配是利用智库信息系统中的相关数据,通过决策树算法实现素质分析和岗位匹配的过程。在智库信息系统中,学员的相关数据信息是海量、无序的。为了从大规模数据中提取学员素质特征,通常利用信息处理技术来实现[11]。目前在信息处理技术方面,经常使用的有聚类算法和决策树算法[12]。决策树算法是一种利用树状结构实现数据分类的人工智能算法,其关键技术在于构建决策树。在决策树生成的过程中已实现数据样本的分类,对于后续待分类的样本,仅需依据已生成的决策树由上至下搜索,即可实现快速、精准地分类[13]。
2.1 决策树算法
2.1.1 信息熵
信息熵表征的是一个随机变量的不确定性,在现实世界中,随机变量的特征只能通过有限次数的样本进行模拟。对于有限的样本集合,信息熵表征该样本集合的混乱程度,其值越高说明样本集合的不确定度越强。对于样本集合D,其信息熵定义为:
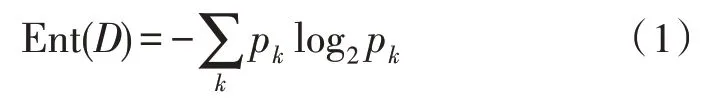
式中,Ent(D)为样本集合D的信息熵;pk为样本集合D中第k个样本所占的比例。
以属性A对样本集合进行划分,属性A可能取值的集合为{a1,a2,…,aV},其中V为属性A可能取值的种类数量,记DV为属性A上取值为av的样本集合,即有:

则根据属性A进行分类,降低样本集合D的不确定度收益,其信息增益为:

式中,Gain(D,A)为根据属性A进行分类时,样本集合D的信息增益。
2.1.2 决策树的生成与计算流程
决策树算法的关键在于生成决策树,决策树生成的过程主要为:以数据样本的信息增益最大为分类依据,从初始节点开始直至末端节点,不断重复地寻找最优的划分数据样本的属性特征[14-16]。具体实现过程描述如下:
1)构建训练集合。训练集合由描述性属性元素和目标属性元素构成,构建训练集的过程,其本质是将学员的素质特征数据从智库信息系统的海量数据中抽取出来,为构建决策树提供数据分析基础。
2)根据目标属性元素计算训练集原本的信息熵,计算方法如式(1)所示。
3)搜索初始节点。首先,对于每一个描述性的属性进行分类;然后,根据式(3)计算训练集合的信息增益;最后,选取信息增益最大的描述性属性作为初始节点。
4)对于每个节点,根据所有其他描述性属性进行分类,计算训练集合的信息熵增益,选取信息增益最大的描述性属性作为分支节点。
5)重复步骤4),直至满足以下条件之一,结束循环:①所有末端节点的元素均属于目标属性;②所有描述性属性均已划分完毕;③描述性属性的某个取值未有样本。
决策树算法流程如图2 所示。
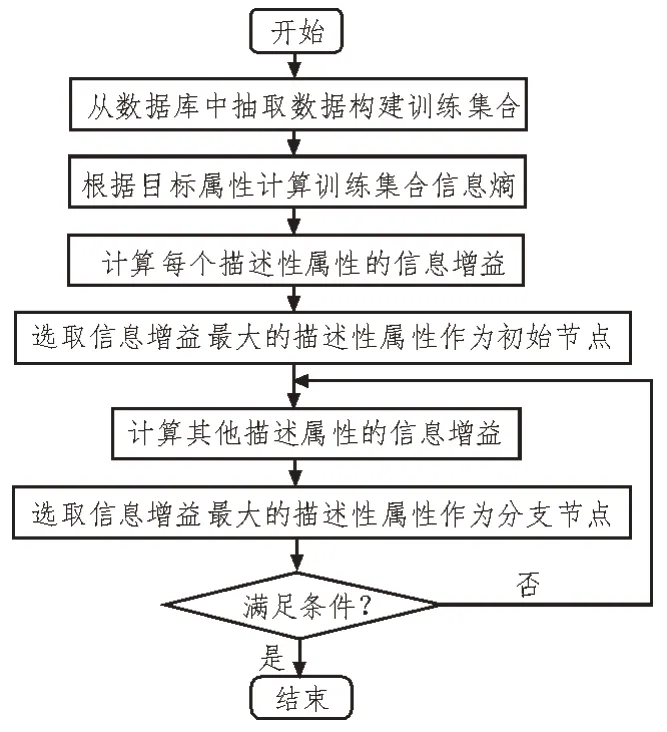
图2 决策树算法流程
2.2 基于决策树算法的智库信息处理
该文将伴随式数据采集和决策树算法应用于智库信息处理,提出了基于决策树算法的人才分类方法,如图3 所示。首先,基于在伴随式数据收集过程中获取的学员信息数据构建训练集。通过决策树算法生成决策树,对于待分类的学员将其数据信息输入已生成的决策树,再输出人才分类结果。
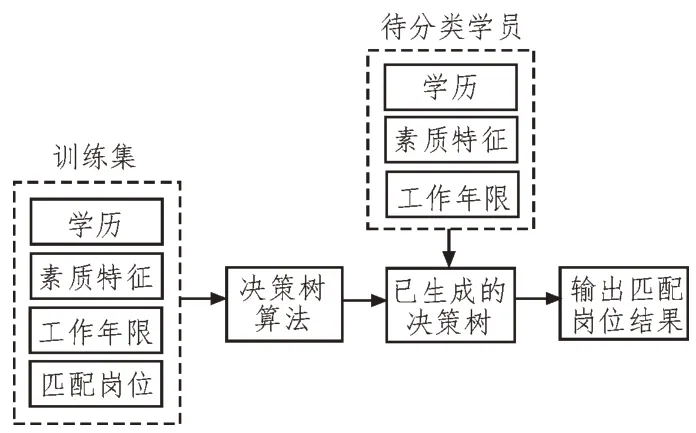
图3 基于伴随式数据采集和决策树算法的智库信息处理方法
1)分类属性
如表1 所示,智库人才分类即决策树算法中的目标属性为可能匹配的岗位,元素值包括:一般研究员、骨干研究员和项目管理员。智库人才的特征信息即决策树算法中的描述性属性为学历、工作年限和素质特征,其中学历属性元素值包括本科和硕士,工作年限包括小于3 和大于或等于3,素质特征包括显性、综合和隐性。
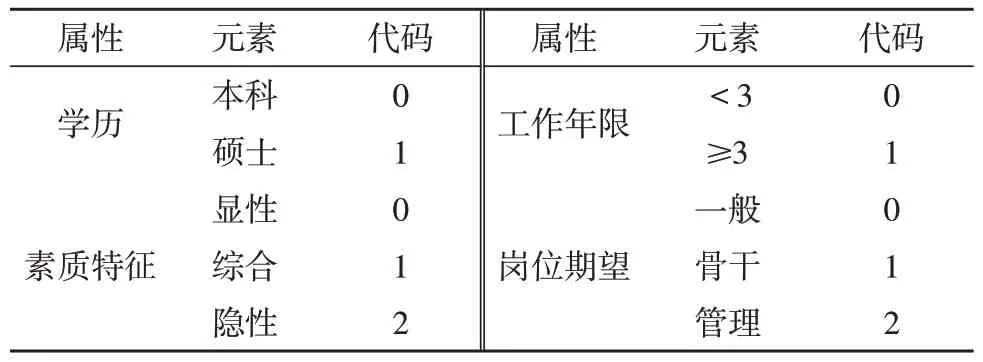
表1 基于智库的人才属性元素
2)构造训练集
从智库中随机抽取学员信息构成训练集,训练集由目标属性元素和描述性属性元素构成。
3 算例分析
为了验证该文所提基于伴随式数据采集和决策树算法的智库信息处理方法的正确性和有效性,以宁夏电力智库为例,随机抽取10 名学员构成训练集。训练集中的学员信息数据如表2 所示。

表2 宁夏电力智库构建的训练集
3.1 决策树的生成
目标属性为匹配岗位,首先计算训练集的信息熵:

1)以学历为初始节点的信息增益:
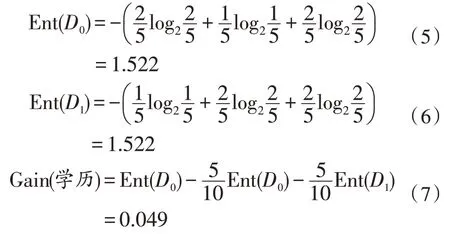
2)以工作年限为初始节点的信息增益:
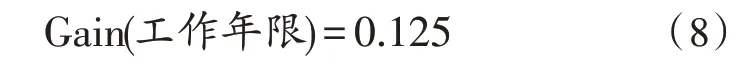
3)以素质特征为初始节点的信息增益为:
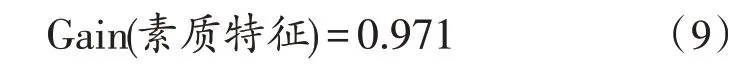
根据上述计算结果,选择信息增益最大的描述性属性素质特征作为决策树的初始节点。
后续对于素质特征的每个分支,计算以其他描述性属性为分支节点的信息增益,选择信息增益值最大的节点作为分支节点。重复上述步骤直至生成决策树,如图4 所示。

图4 生成的决策分析树
3.2 决策树的应用
从智库中随机抽取5 名学员的信息,根据上节中生成的决策树,将学历、工作年限和素质特征的信息数据作为输入,输出匹配岗位结果。
分析匹配岗位过程为:首先从决策树的初始节点出发,根据素质特征的取值搜索至该分支;然后依据其他描述性属性,从上至下依次搜索,直至末端节点即可得到该学员的匹配岗位结果。
利用200 名学员对已生成的决策树进行测试,并验证其准确性,部分学员的岗位匹配结果,如表3所示。

表3 岗位匹配结果
在测试结果数据中,最终有198 名学员匹配岗位与实际相同,匹配准确率为99%,表明所提算法能够实现人才的智能分类。
4 结束语
该文开展了伴随式数据采集和决策树算法在智库信息处理中的应用研究,构建基于伴随式数据采集的智库信息系统架构。利用智库信息数据,通过决策树算法实现人才素质特征与岗位的准确匹配。经算例分析表明,文中所提方法能够简单、高效地实现人才的评价与岗位配置,匹配准确率达99%,对提升人才的岗位匹配度和工作效率具有现实意义。但人才岗位匹配只是智库信息数据应用的一个方面,因此有必要进一步挖掘其在人才业绩考核、岗位晋升等方面的应用,这将在下一步研究中展开。
猜你喜欢
大江南北(2022年6期)2022-06-16
少先队活动(2021年4期)2021-07-23
中华民居(2020年4期)2020-09-21
领导决策信息(2018年20期)2018-10-16
领导决策信息(2018年23期)2018-09-27
电子制作(2018年16期)2018-09-26
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
中华儿女(2016年14期)2016-12-20
现代企业(2015年4期)2015-02-28
