
基于GMBP 模型的图书馆借阅量非线性预测方法
2022-12-01 06:00高萍
电子设计工程 2022年23期
高萍
(宝鸡文理学院,陕西 宝鸡 721006)
图书馆借阅量是评估一个图书馆馆藏资源质量、数量、图书种类和用户群体阅读需求的重要指标。图书馆借阅量能较为直观地反映出纸质书籍与电子文献的借阅情况[1]。对图书馆借阅量进行预测可为图书馆的工作人员对图书和文献资源管理提供方便,并根据相关书籍的借阅情况及时作出部署与安排。图书馆借阅量会受到较多因素的制约,如借阅人数、借阅时间、馆藏数量及质量、冷门书籍的借阅氛围等,这些制约因素具有一定的周期性和规律性,不利于图书馆借阅量的精准预测[2]。
相关学者也提出比较有效的图书馆借阅量预测方法,杨英设计一种基于数据挖掘技术的图书馆借阅量估计模型,通过图书馆借阅数据构建借阅量估计模型,采用蚁群算法优化RBF 神经网络的权值、阈值,该方法能快速实现预测,但其预测精度较低,预测量与实际图书馆借阅量相差较大[3]。
为解决上述问题,实现图书馆借阅量的精准预测,该文提出以GMBP 模型为核心的图书馆借阅量非线性预测方法,根据图书馆借阅量进行建模,利用混沌分析法和数据挖掘法处理数据,对数据进行非线性预测,通过实验研究验证该文所提方法的性能。
1 GMBP模型建模
对图书馆借阅量进行预测时,采集图书馆借阅量样本数据(xi,yi),并将其输入到BP 神经网络模型中,通过采用ϕ(x) 将图书馆借阅量样本数据(xi,yi)映射到BP 神经网络模型中[4],以得到GMBP 模型,如式(1)所示:

式中,ωT表示图书馆借阅量的正则化参数;b表示图书馆借阅量的子数据集。通过结合后的GMBP模型对图书馆借阅量进行预测建模[5]。
图书馆借阅量数据包含大量的测试数据,为改善因数据处理技术不具备归一化处理能力导致的样本数据与测试数据混沌性较高的问题,建立GM 灰色模型以实现图书馆借阅量测试数据的准确预测。
将图书馆借阅量数据中的数据节点按照预测顺序进行划分,通过划分完的节点数据对图书馆一个周期的借阅量进行预测,并进行系统学习,建立的预测模型如图1 所示。
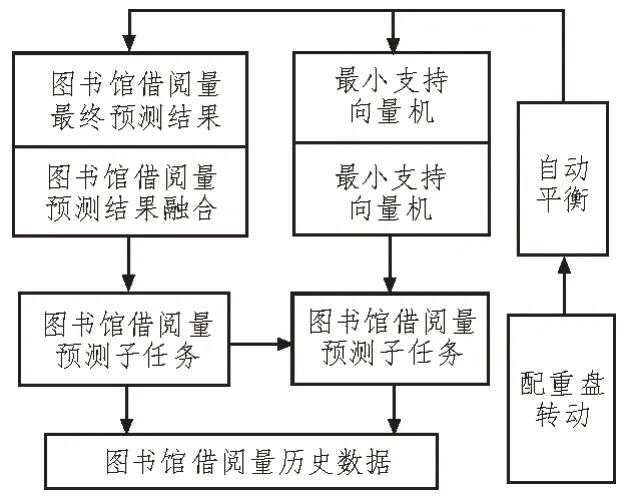
图1 图书馆借阅量预测模型
观察图1 可知,每种图书馆借阅量数据集中含有相同数量的子数据,将输入的图书馆借阅量数据通过GMBP 模型进行输出,收集输出的图书馆借阅量训练数据,并进行节点划分,划分完成后获得多种图书馆借阅量数据集,将图书馆借阅量子数据输入到GMBP 灰色神经网络模型对其进行统计与筛选。通过图书馆管理人员下发的图书馆借阅量预测子任务,筛选出符合图书馆预测要求的某一阶段的图书馆借阅量数据,再根据训练集与测试集进行划分,建立图书馆借阅量非线性预测模型[6]。在图书馆借阅量子数据输入并选择完成后,将其分别输入到GM 灰色模型与BP 神经网络模型中,输入到模型中的图书馆借阅量数据将存储在输入层与隐含层中[7]。输入层中的图书馆借阅量子数据可通过映射转换到多维空间之中,而存储在隐含层中的图书馆借阅量子数据由于数据属于多维数据,因此需通过隐含层节点将图书馆借阅量子数据变换到隐含层空间内,对得到的图书馆借阅量预测结果进行分析,将GM 灰色模型与BP 神经网络结合,完成GMBP 模型的建模[8]。
通过该图书馆借阅量预测模型可实现海量图书馆借阅量数据的输入与输出、映射与融合,将不同空间内的图书馆借阅量数据进行结合,使预测结果更具准确性与可靠性[9]。
2 图书馆借阅量非线性预测方法的构建
对图书馆借阅量的预测属于非线性预测,这是由于图书馆借阅量具有非线性变化的特点,受到借阅人数、时间、书籍种类等因素影响,其数据具有一定的混沌性[10]。因此在对图书馆借阅量进行非线性预测时,首先采用混沌分析法对图书馆借阅量进行初级预测,降低其混沌性。假设图书馆借阅量的原始数据为xi,i=0,1,2,……,为更精确地找出图书馆借阅量的原始数据随借阅时间与借阅图书种类变化的情况,将图书馆借阅量的原始数据按照数据隐藏特点分为图书馆借阅量样本数据与测试数据,通过混沌分析方法对图书馆借阅量样本数据与测试数据进行处理与映射,以此完成对图书馆借阅量原始数据的初级预测[11]。预测公式如下:

式中,m表示采用混沌分析方法对图书馆借阅量原始数据进行映射的次数;τ表示图书馆借阅量样本数据与测试数据的嵌入维数。将原始数据分为测试数据与样本数据,通过该预测公式,采用混沌分析方法对图书馆借阅量原始数据进行初级预测[12],并得出预测初级结果,该预测初级结果可提高图书馆借阅量最终预测结果的有效性和精确性[13]。
采用数据挖掘技术对图书馆借阅量测试数据与样本数据进行挖掘。首先提取学校图书馆30 天的图书馆借阅量,采用数据挖掘技术确定测试数据与样本数据的空间维数,如果定阶指数为6,则可通过数据挖掘技术得到图书馆第7 天的图书馆借阅量,对初级预测过程中的图书馆借阅量样本数据与测试数据进行分析,确定实验结果[14]。验证结束后,将图书馆借阅量预测初级结果与验证结果进行融合,对融合后的预测结果进行参数寻优和归一化处理[15],进行参数寻优的公式为:

式中,xmin和xmax分别表示预测结果的最小值和最大值,采用图书馆借阅量样本数据分别对预测融合结果、预测最大值、预测最小值进行参数寻优,对参数寻优后的三种预测结果进行训练,训练结束后就得到最终的图书馆借阅量预测结果[16]。
由于混沌分析方法具有非线性的特点,对数据的把控能力更强,可在短时间内收集大量数据,收集后分析数据特性,以不同的方式将数据排列,根据数据特点,确定图书馆借阅量。与传统的线性分析方法相比,非线性分析方法的分析范围更广,分析能力更强。图书馆书籍内容罗列方式不同,因此基于GMBP模型的图书馆借阅量非线性预测方法更适合于实际应用。
3 实验研究
为验证该文提出的以GMBP 模型为核心的图书馆借阅量非线性预测方法的实际工作效果,将基于数据挖掘技术的图书馆借阅量估计方法与该文方法进行对比实验。实验中的图书馆借阅量提取于某学校图书馆的管理系统,从某学校图书馆管理系统中采集某一时间段内的图书馆借阅量样本,采集到有效图书馆借阅量样本数量为600 个,样本数据示意图如图2 所示。
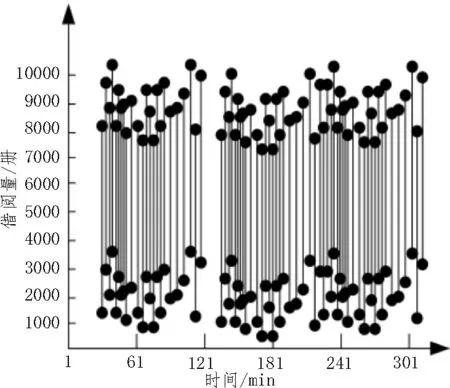
图2 样本数据示意图
根据图2 的样本数据,进行对比实验。
3.1 预测结果与实际结果的对比
实验中,对所采集的600 个图书馆借阅量样本数据进行处理和映射,然后将映射后的样本数据分为样本集与测试集,图书馆借阅量样本数据中的前400 个数据作为GMBP 灰色神经网络的样本集,对样本集进行归一化处理,剩下200 个数据作为灰色神经网络的测试集,利用混沌分析法分析图书馆借阅量的映射次数与嵌入维数,然后进行参数寻优,寻优后分别对样本集与测试集进行预测。采用该文方法与传统方法,即基于数据挖掘技术的图书馆借阅量估计方法对数据进行预测,预测结果如图3 所示。

图3 预测实验结果
由图3 可知,该文提出以GMBP 模型为核心的图书馆借阅量非线性预测方法预测结果与真实结果相差较小,而基于数据挖掘技术的图书馆借阅量估计方法的预测结果与真实结果相差较大,由此证明了该文方法预测的图书馆借阅量更符合实际图书馆的借阅量。
3.2 预测精度对比实验
基于以上设置的实验参数,针对不同预测方法进行预测精度的对比实验。在预测精度对比实验中,对图书馆借阅量样本数据和测试数据分别进行映射实验,实验进行5 次,统计每次实验结果,两种预测方法的预测精度对比结果如图4 所示。

图4 预测精度实验结果
分析预测精度实验结果可知,该文方法的预测精度较高,传统预测方法的预测精度较低。造成这种情况的原因是,该文研究的预测方法引用了GMBP模型,可实现非线性预测,得到GMBP 灰色神经网络模型的最优参数,提升预测精度。而基于数据挖掘技术的图书馆借阅量估计方法的模型属于线性回归模型,无法识别图书馆借阅量的非线性特点,并且该方法对样本集进行测试时泛化能力较差,很难通过灰色模型找出图书馆借阅量的全局最优值,预测精度较低。
3.3 预测方法稳定性对比实验
采用该文方法与基于数据挖掘技术的图书馆借阅量估计方法对图书馆借阅量样本数据进行5 次实验,实验中每次预测结果的稳定性结果如图5 所示。

图5 预测稳定性实验结果
由实验结果可知,基于数据挖掘技术的图书馆借阅量估计方法的5次预测结果的干扰值在-10~10 mm之间波动,主要集中在-3~5 mm 之间,说明基于数据挖掘技术的图书馆借阅量估计方法的波动范围较大,稳定性较差,不适合实际应用。而该文方法的5次预测结果的干扰值在-2.5~2.5 mm 之间波动,主要集中在-1.5~1 mm 之间,说明该文方法的抗干扰性较强,波动范围较小,稳定性较好,适合实际应用,由此可证明该文方法的稳定性要优于数据挖掘技术的图书馆借阅量估计方法。
经过以上对比实验可验证,该文预测方法预测精度较高,稳定性较高,预测结果与实际结果误差小,整体性能优于传统预测方法,实用性强。
4 结束语
图书馆借阅量在图书馆业务统计中是一个非常关键的评估指标,通过精准阅读提高图书馆服务质量,完善图书馆的日常管理。该文利用GMBP 模型设计一种新的图书馆借阅量非线性预测方法,对预测方法的数据量进行建模,根据建模结果分析数据精度,实现数据预测。通过实验可知,研究的预测方法稳定性高、预测精度高,值得大力推荐和使用,有助于图书馆的资源管理。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
中学生数理化·高一版(2021年2期)2021-03-19
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
科学与财富(2018年30期)2018-12-28
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
电子技术与软件工程(2016年24期)2017-02-23
计算机应用(2016年9期)2016-11-01
体育科技(2016年2期)2016-02-28
