
基于机器学习的回归模型预测对比
2022-12-16 01:38宋敬茹杨晓芜
农业与技术 2022年23期
宋敬茹 杨晓芜
(华北理工大学矿业工程学院,河北 唐山 063210)
引言
为了预测各种类型的数据,大量学者尝试建立相关的回归模型[1],并对研究数据采用回归方法进行分析,以节约获取数据的时间、经费和人物力。然而,大多数方法主要集中在传统线性回归模型,如线性回归和偏最小二乘回归[2],但这些方法更适合于具有线性相关的参数变量[3]。
因此,近年来,机器学习因其更强大的灵活性和对数据的高度适应性而不断发展和开始流行起来[4],在回归分析方法上选取机器学习也变得逐渐活跃,如支持向量回归(SVR)、随机森林回归(RFR)和增强回归树(BRT)。研究发现,SVR、RFR和BRT都能够尝试为各种类型的数据提供相当好的预测方法。Mountrakis等[5]通过研究发现,与传统的线性方法相比,使用SVR算法可以降低回归模型估计的误差。Wang等[6]探究发现,RFR可以将决策树与回归分析模型的套袋算法相结合,其样本选择策略可以避免回归的过拟合。同时,使用机器学习进行回归分析已广泛应用于许多数据预测相关领域,覆盖面甚广。因此,本文利用R软件,采用SVR、RFR和BRT 3种机器学习对数据进行回归建模的预测分析,并对回归模型结果进行比较分析,选择适合研究数据的最优机器学习回归模型。
1 数据与方法
1.1 数据
本实验采用数据来自中国国家气象数据网(http://data.cma.cn/),共计66个国家基础气象站点样本数据,并收集了对应所有气象站点的经度、纬度和高程海拔数据信息。因数据量较大,无法全部展开,故只展示前30个样本数据组,而全部66组数据均会作为本研究的实测值用以建立机器学习的回归模型。为充分体现机器学习回归模型的预测结果,建模数据基于新疆地区降雨量数据,因该地的特殊地理位置和气候现状使得降雨量数据存在明显的差异,见表1。
为进一步建模做准备,对表1数据进行统计描述,见表2各个参数数据大致呈正态分布。通过对表1的数据进行统计分析,其中经度、纬度因地理位置变异系数最小分别为0.06和0.07,又因为新疆维吾尔自治区同时具有高原和盆地导致海拔方差最大为350427.84,海拔数据较为不稳定。同时发现4个参数的均值均满足在95%置信区间内分布,因此本次回归分析中4个参数均在可利用范围内。
1.2 方法
1.2.1 相关分析
相关性分析是研究自变量和因变量之间关系程度的常用统计方法,以准确描述变量之间的相关性,相关系数大致包括3类,相关系数中皮尔逊系数[7]最常用于范围广泛的值,范围在[-1,1],值在[0.8,1]或[-1,-0.8]表明其高度紧密相关;值在[0.5,0.8]或[-0.5,-0.8]表现显著紧密关系;处于[0.3,0.5]或[-0.3,-0.5]的值表明两者关系为实相关性;值处于[0.0,0.3]或[-0.0,-0.3]表明参数两两之间呈现微相关性,见表3。本文选取经度、纬度和海拔为自变量,降雨量为因变量,其相关系数的计算公式[7]:
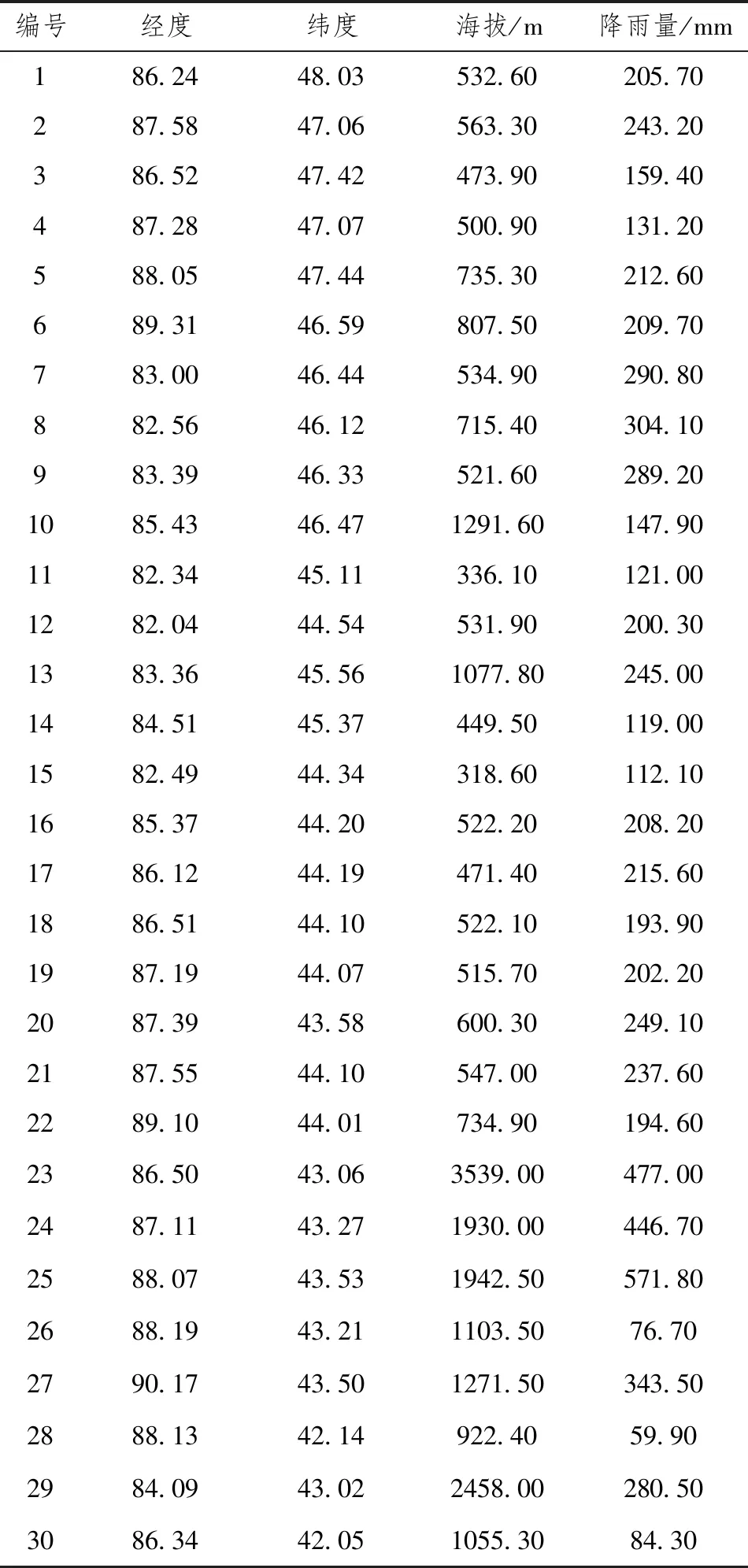
表1 回归分析数据
(1)

1.2.2 机器学习回归分析
1.2.2.1 支持向量回归分析
近年来,支持向量机(SVM)在各种分类和回归问题中的应用越来越多,在分类和回归问题中均能得到较好的应用。支持向量回归(SVR)是由支持向量分类(SVM)方法演变而来[8],SVR使用条带来进行参数回归拟合,其优点在于可以处理复杂参数关系,以高精度来不断靠近呈现较为复杂非线性关系的数据[9]。通过调节超参数以期找到一个超平面,同时满足从所有数据到此超平面的距离最小[10],且满足于各个参数数据之间关系存在为非线性的情况。因SVR所具有的长处,其用于回归分析获得的结果显著优于其它普通线性模型。
1.2.2.2 随机森林回归分析
随机森林回归(RFR)是一种统计算法理论,其是利用Bootsrap重抽样方法从原始样本中抽取多个样本,对每个Bootsrap样本进行决策树建模,组合多棵决策树的预测,并通过投票得出最终预测结果[11]。其中每个决策树的建立都是一个随机抽样的过程[12]。在研究中采用自举法,即通过抽样获得的样本集中可能存在重复的样本,可以有效避免过拟合,且具有较高的精度和泛化能力[13],RFR分析可以通过降低OBB error误差值以获取更优回归结果。

表2 数据统计
1.2.2.3 增强回归树分析
增强回归树(BRT)是由众多较短的决策树(百棵以上)建立的,通过在梯度上减少残差的模型,能够在回归分析法中不间断的以递归形式分裂来消除众多影响因子之间相互作用[14]。Boosting法用较短的回归树(tree)集合来表明与影响因子之间存在的非线性关系,BRT为解决单一决策树面临的缺陷,其随机抽取并采用“梯度下降法”以降低回归分析残差,提升模型整体性能。在“梯度下降法”过程中tree的棵数逐渐递增,模型的稳定能力和预测精度呈现显著提升[15]。

表3 相关系数与相关程度关系
1.2.3 回归分析评定指标
本文采用适合小样本数据的留一交叉验证法(LOOCV),从3个角度出发进行回归分析评定,3个指标分别是拟合程度,即调整型决定系数(Adjusted-R2)、回归误差;均方根误差(RMSE)和回归模型稳定程度;相对分析误差(RPD)。Adjusted-R2值高低表明拟合程度得优劣,RMSE值大小则阐明建立回归分析的误差的大小,RPD值所对应的稳定程度水平如表4。

表4 RPD值对应的稳定程度
(2)
(3)
(4)
(5)
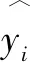
1.2.4 回归分析框架
为了清晰直观地说明研究过程,本文建立了一个基于机器学习进行研究的回归分析框架,结合上述所有分析方法,系统化、全面化的对基于机器学习的回归分析过程进行描述,见图1。

图1 回归分析框架图
2 结果
2.1 相关性分析
根据表1中样本参数进行相关性分析,在表5各参数与降雨量相关程度分析结果中可以看出经度、纬度和海拔均满足了p≤0.05的显著水平,分析得出经度数据与降雨量数据的相关性较高为0.533*且呈现为显著相关程度,而纬度数据与降雨量数据的相关性最低为0.377*,但也满足了实相关,海拔数据与降雨量数据相关性为0.471*。

表5 参数与降雨量相关性分析
2.2 机器学习的回归分析结果
基于3种机器学习算法并结合经、纬度和海拔等参数数据信息对降雨量进行回归分析预测,产生的预测值的结果各有不同,3种算法回归结果如图2。通过观察图2可明显发现,基于RFR算法的回归分析能够使得降水量的真实值和预测值更加接近1∶1线,即回归结果较SVR和BRT的结果更优。
仅凭观察图2无法深切探究出3种机器学习回归分析的最优预测结果,为更具清晰化地对比3种机器学习,故基于式(2)~(5)共3个指标全方位的对3种机学器习的回归分析结果进行详细对比,结果见表6。

表6 机器学习的回归分析对比

图2 3种机器学习的回归分析结果图
依据SVR算法回归结果计算出的Adjusted-R2值为0.67,RMSE值为65.08,RPD值为1.80;RFR算法回归结果中的Adjusted-R2值为0.92,RMSE值为32.35,RPD值为3.61;BRT算法回归结果中的Adjusted-R2值为0.87,RMSE值为41.03,RPD值为2.85。综上,RFR算法回归结果的Adjusted-R2值最大,RMSE值最小,RPD值最高。由此可知,相较于SVR和BRT机器学习回归结果,RFR算法回归拟合效果最好、误差最低以及稳定性最优,故3种机器学习对比而言,利用RFR算法进行回归分析能取得更好结果。
3 结论
本文采取SVR、RFR和BRT 3种机器学习回归模型对降雨量数据分别进行了预测分析,并对回归分析结果进行全面评定对比。结果显示,使用机器学习算法可以有效提高数据预测结果的准确性。就整体观察而言,基于SVR、RFR和BRT 3种机器学习对降雨量数据进行回归分析预测都取得了较好的结果,但利用回归结果图和Adjusted-R2值、RMSE值及RPD值进行综合评定,发现RFR算法回归结果明显优于SVR和BRT结果,故最终选定基于RFR算法的回归分析,且认为利用该算法能够较好地对降雨量数据进行预测。RFR模型为数据量预测复杂等问题提供合理解决方法,达到高效预测数据的目的,与此同时对进一步深入探究回归分析算法具有一定的参考价值。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
数学小灵通·3-4年级(2021年6期)2021-07-16
电影(2018年8期)2018-09-21
知识经济·中国直销(2018年8期)2018-08-23
中国老区建设(2016年1期)2016-02-28
湖南水利水电(2015年2期)2015-12-24
新疆农垦科技(2014年7期)2014-02-28
中国科技术语(2011年3期)2011-12-31
