
主动容错云存储系统的故障预警调度策略
2022-12-30 07:51曾婷婷曹卫东
计算机工程与设计 2022年12期
李 国,曾婷婷,曹卫东,李 静
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
大规模云存储系统作为主流数据中心的主要存储架构,需要数以百万计的硬盘来存储数据,硬盘故障会造成数据丢失,从而影响系统性能[1-3]。为了提高存储可靠性,以副本或纠删码为代表的被动容错技术和以硬盘故障预测为代表的主动容错技术被广泛应用于各大云存储系统[4-7]。硬盘故障预测模型能监控硬盘的运行情况,在发现即将故障的硬盘时发出预警,从而提醒操作人员尽快处理预警硬盘,降低数据丢失的概率。
然而,随着存储系统规模的不断扩大,硬盘故障预测模型发出的预警也在随之增加,由于网络带宽等资源的限制,系统无法一次性处理多个预警,否则会影响正常的用户服务。通常情况下,操作人员根据FIFO来处理预警事件,对于大规模云存储系统来说,无论是通过提前预测对故障硬盘中的数据进行迁移,还是通过被动容错方式进行重构,都需要几个小时甚至几天的时间[8]。同时,考虑到系统的冗余机制,大多数操作人员并不会及时地处理预警[9],而预警不能得到及时处理会导致数据丢失。因此,系统需要更合适的调度策略来避免该情况的发生。文献[10]通过构建递归神经网络模型来确定硬盘故障模型发出的预警的优先级,为预警调度提供了依据。优先级调度能够保证系统优先处理更紧急的预警事件,然而该方法有一定的缺陷:①低优先级的预警事件可能会“饥饿”;②无法保证响应时间,除非一个预警事件的优先级在优先级队列中最高,否则程序将无法立即处理该预警事件。
为解决以上问题,本文提出了一种调度策略,将优先级思想引入云存储系统并加以改进,使用非完全抢占式的动态优先级策略调度不同的预警事件。同时,该策略在保证系统性能的情况下分配带宽资源,并统计存储系统在一定运行周期内发生数据丢失事件的期望次数。利用本文的方法可以调度预测模型在一段时间内发出的多个预警,降低云存储系统中的数据丢失次数,提高云存储系统的性能。
1 相关研究
1.1 冗余机制
RAID-5和RAID-6冗余机制广泛应用于云存储系统中,是在故障发生后进行数据重构的被动容错技术。硬盘在系统中被划分为不同的校验组,若校验组内出现的故障超出限制,则会导致数据丢失。硬盘发生故障后,RAID会自动根据剩余硬盘中的数据和校验数据重建丢失的数据,如果重构过程能够及时完成,则可以避免数据丢失事件的发生。然而,RAID是以牺牲空间换取更高的可靠性和性能的冗余机制,这会减少全体硬盘的总可用存储空间[11]。此外,硬盘的容量不断增加,但其读写速度却增长得十分缓慢,这样就导致了硬盘故障之后RAID重构时间不断延长。在重构数据的过程中,校验组中其它硬盘发生故障的可能性增加[12],这无疑增加了数据丢失的风险,进而降低系统的服务质量。
1.2 主动容错技术
硬盘故障预测模型可以在硬盘即将发生故障时发出预警,在故障发生之前进行处理,是典型的主动容错技术[13]。目前,大部分硬盘内部都具有S.M.A.R.T.配置,即“自我监测、分析及报告技术”,可以实时采集硬盘的参数信息[14]。硬盘故障预测模型就是根据S.M.A.R.T.参数信息,运用统计学和机器学习的相关算法建立的[15,16]。一般情况下,硬盘故障预测模型都是二分类模型,即一个硬盘的状态是“健康”或“即将故障”。在主动容错系统中,硬盘故障预测模型监测工作硬盘的状态并输出预警,但由于二进制结果既不能提供预警命令,也不能提供准确的值来指示预警的优先级,因此很难对预警调度提供有效的帮助。
1.3 调度策略
目前,部署有故障预测模型的存储系统默认的预警调度算法是先进先出算法(FIFO)。FIFO的特点是易于实现,并且系统的调度开销比较少,任务平均完成时间较短[17]。研究表明,硬盘故障预测模型可以提前几十甚至几百个小时的时间发出预警[7]。随着预测模型发出的预警的数量不断增加,对于被预测为短时间内即将发生故障的硬盘,如果仅遵循FIFO的顺序等待处理,则很有可能因为等待时间过长而造成数据丢失。
优先级调度是按照系统分配的优先级数值的大小来调度任务的一种调度策略[18]。在这种策略下,系统给每一个任务分配一个优先级数值来确定其优先级,优先级高的任务会被优先响应,而对于优先级相同的任务请求,则按照FIFO的顺序进行响应。
2 预警调度模型
2.1 模型框架
一个完整的调度机制应具有两方面的功能:一是主动容错,即能够提前预测出将要发生的故障并发出预警;二是调度,即能对系统发出的多个预警事件进行处理。本文提出的调度模型不仅可以利用硬盘监测数据训练预测模型,还可以对多个预警事件进行调度。
图1描述了调度模型的基本框架。模型首先解析硬盘在RAID校验组中的分布,然后将预处理后的硬盘监测数据传输到硬盘故障预测模型,接着根据硬盘的数据以及预测模型的结果发出预警事件,调度算法根据系统中的冗余布局将不同级别的预警事件按照一定的顺序加入优先级队列,在系统带宽允许的情况下将其依次加入工作队列并分配带宽资源,最后校验组进行故障重构。
2.2 主动容错RAID-5和RAID-6系统
对于一个RAID-5校验组,当有一个硬盘发生故障时,校验组会进入降级模式,如果故障盘能够得到及时有效的处理(故障盘被及时替换,并完成数据重构),则不会造成数据丢失;若不能及时处理,一旦校验组内发生并发故障则会造成数据永久丢失,不能再提供正常服务,即一个RAID-5校验组只能容许一个运行故障发生。
如图2所示,校验组DG3中已有一个硬盘处于故障状态,该校验组处于降级状态,此时硬盘D1发出预警,必须尽快进行处理,否则将会造成数据丢失,影响系统性能。对于校验组DG2来说,硬盘D2发出预警,但其所在校验组其余的硬盘是健康状态,故若硬盘D1和D2同时发出预警,则应优先处理D1硬盘,以最大程度地避免数据丢失事件的发生。

图2 RAID-5示例
同样地,对于一个RAID-6校验组,当有一个故障发生故障时,校验组会进入降级模式,本文称之为降级1,当有两个硬盘发生故障时,称为降级2。当校验组处于降级2模式时,若故障盘能够得到及时有效地处理,则不会造成数据丢失;若不能及时处理,当第三个硬盘故障发生时就会造成数据永久丢失,不能再提供正常服务,即一个RAID-6校验组最多能容许两个运行故障发生。
如图3所示,校验组DG1中已有两个硬盘处于故障状态,该校验组处于降级2模式,此时硬盘D1发出预警,必须尽快进行处理,否则将会造成数据丢失,影响系统性能。而校验组DG3处于降级1模式,故若硬盘D1和D4同时发出预警,则应优先处理D1硬盘,以最大程度地避免数据丢失事件的发生。

图3 RAID-6示例
2.3 硬盘故障预测方法的选择
一个好的硬盘故障预测模型,应该实现较高的预测准确率和较低的误报率。为了更真实地反映大型云存储系统的硬盘运行状况,本文使用了Backblaze公司提供的公共数据集来构建硬盘故障预测模型,并将预测结果用于之后的实验。数据集中记录了超过10万个硬盘,覆盖了Seagate和West Digital的30多个不同的硬盘型号。为排除型号影响,本文选择了2019年数据量最大的型号为ST4000DM0007的Seagate硬盘进行实验。从这个硬盘型号中,本文收集了37 102个健康盘和1144个故障盘的属性信息。在本文的实验中,从健康盘中随机选出70%作为训练集,剩余30%作为测试集;从故障盘中随机选出70%作为训练集,剩余30%作为测试集。
本文使用了决策树和BP神经网络两种方法来构建硬盘故障预测模型。此外,考虑原始值属性对预测结果的影响[15],基于是否增加原始值属性分别进行了两次实验。其中,对于决策树预测模型,设置复杂性CP为0.01,划分前最小样本数Min Split为20,叶子节点最小样本数Min Bucket为7;对于BP神经网络预测模型,设置隐藏层个数为4个,每层神经元个数分别设为1000、500、200、100,输出层为3个,激活函数选择tanh。其结果见表1。

表1 预测结果分析/%
由表1可以看出,选择12个属性并通过决策树模型训练可以实现更高的准确率和更低的误报率,故本文选用决策树预测模型作为实验的基本预测模型,模型的预测结果显示在图4中。由图4可以看出,超过半数的预警可以在硬盘发生故障前两周以上发出预警,而对于提前预警时间较短的硬盘,系统应尽快处理。图4中提前预警时间的概率分布将用于后续的实验中。
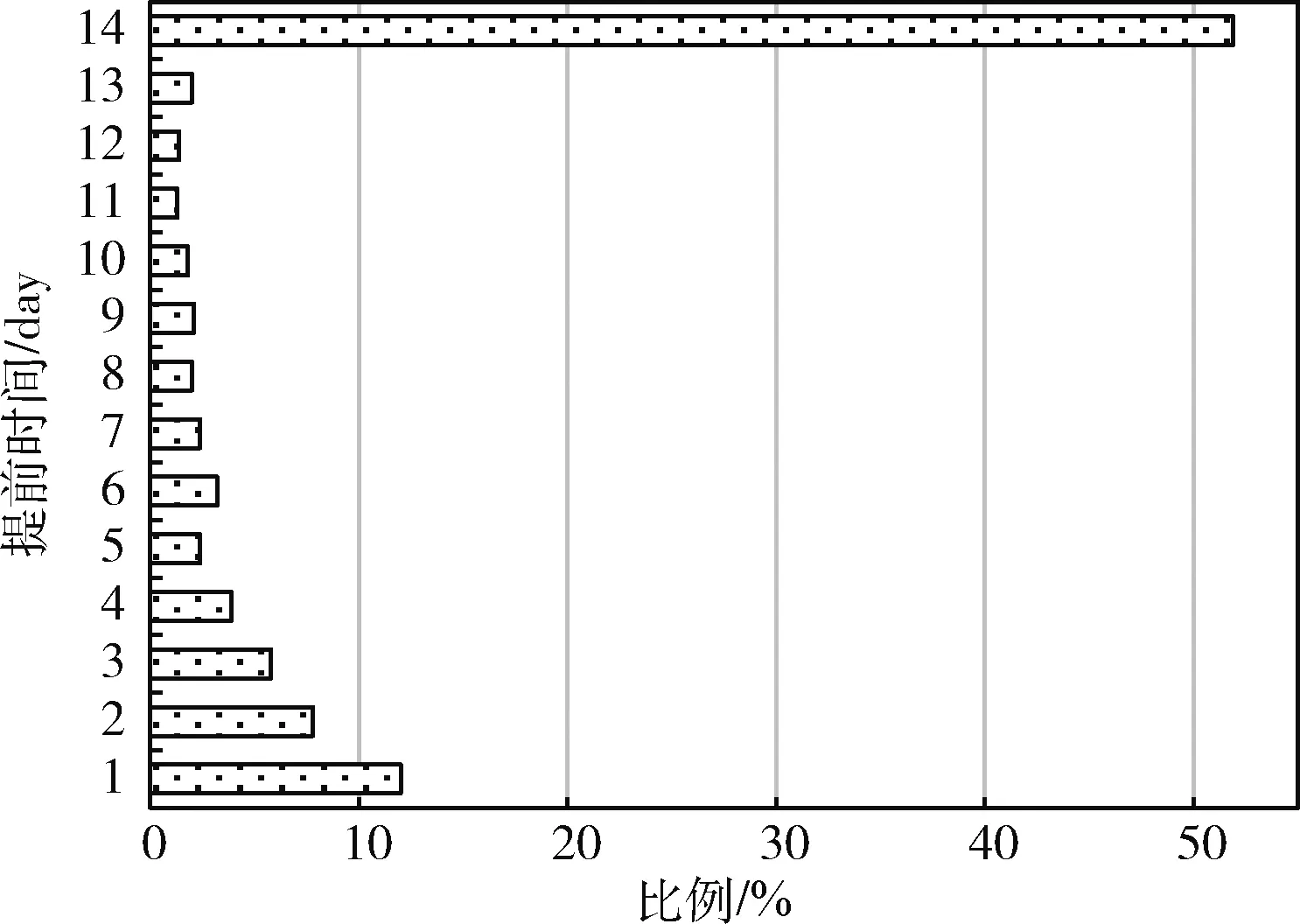
图4 提前预警时间分布
2.4 预警优先级定义
2.4.1 硬盘健康度
以往的研究大多以提高预测性能为目的,提出的预测模型大都是二分类模型,其产生的结果只有两种:健康或预警。在一般情况下,硬盘故障并不是突然发生的,它往往是一个渐变的过程,而简单的二分类预测结果并不能指导如何进行预警调度。本文使用具体的值来描述预警硬盘的危险程度,称为健康度,其计算过程如式(1)
(1)
式中:wd(i) 表示i时刻硬盘d的剩余寿命,即从发出预警到真实的故障发生所间隔的时间,wd(i) 可由决策树预测模型获得,由于本文使用的故障硬盘样本均被预测为14天以内发生故障,故设wc(i) 为336 h。
若硬盘为健康硬盘或在短时间内不会发生故障,设hd(i) 为0;若硬盘被预测为将在336 h之内发生故障,则hd(i)∈(-1,0); 若硬盘已经发生故障,设hd(i) 为-1。hd(i) 既可以衡量硬盘d在i时刻的运行状况,又可以作为设定预警事件优先级的一个重要指标。
2.4.2 校验组
对预警事件的处理不仅需要考虑单个硬盘,还要结合云存储系统的特点,考虑冗余机制的影响。对于配置了RAID-5或RAID-6的云存储系统,除了将硬盘的健康度作为一个评价指标,还要考虑硬盘所在校验组的所有硬盘的健康状况,对于已经处于降级模式的校验组,该组中的预警硬盘应获得更高的分数,其组中的预警硬盘应得到优先处理。每个校验组的严重程度分数的计算公式为
(2)
式中:hk(i) 表示校验组k中硬盘i的健康度。算法1对校验组的严重程度分数的计算进行了详细描述。
算法1:校验组严重程度分数算法
输入:硬盘信息及其预测结果集D={d11,d12,…,d1n,d21,d22,…,d2n,…,dmn} 和校验组集R={r1,r2,r3,…,rm}
输出:校验组的严重程度分数集S={s1,s2,s3,…,sm}
(1)Begin
(2)/* 初始化健康度集 */
(3)H={h11,h12,…,h1n,h21,h22,…,h2n,…,hmn}
(4)For each ri∈R
(5)/* 校验组分布 */
(6) ri={di1,…,di2,di3,…,din}
(7) For each dij∈ri
(8)/* 使用式(1)计算硬盘dij的健康度hij*/
(9) hij←dij
(10)/* 更新健康度集 */
(11) H←hij
(12) End for
(13)/* 使用式(2)计算每个校验组的严重程度分数 */
(14) sj←ri
(15)/* 更新严重程度分数集ri*/
(16) S←si
(17)End for
(18)End
2.4.3 预警优先级
本文依据硬盘的健康度以及存储系统的冗余机制为每个预警事件设置优先级,优先处理较高优先级的预警事件。每个预警事件的严重程度的计算公式为
pd(i)=α×hd(i)+β×scorek(i)
(3)
式中:hd(i) 和scorek(i) 由式(1)和式(2)分别给出,α和β为动态因数权值,满足条件α+β=1。
预警事件严重程度值的大小代表该事件的紧急程度,可以用该值来划分预警事件的优先级。在划分优先级时,对于严重程度相差不多的预警事件,处理顺序的先后不会对系统的性能造成很大的影响,故本文将预警事件严重程度的值映射为k个离散的值,它们代表不同的优先级。结合预测模型的预测结果以及存储系统中的冗余机制,本文设置k值为6。预警事件的严重程度与其优先级的映射关系见表2。

表2 优先级映射
2.5 非完全抢占式的动态优先级调度
为了减少主动容错机制对系统性能的影响,当故障发生后,RAID只使用系统总带宽的一小部分用于重构数据,以此来保证系统的正常服务质量。由于带宽资源的限制,优先级队列中的预警事件不能无限增加,否则将集体陷入“饥饿”状态。因此,设置优先级队列中的预警事件总数上限为5,在不超过上限的情况下,优先级队列中的所有任务都可以获取带宽资源用于数据重构,而不是等待前一个预警事件处理完成,此为非完全抢占式的优先级调度。此外,未加入优先级队列的预警事件由于等待时间的不断延长,其严重程度会越来越高,系统定时更新处于等待状态的预警事件的优先级,以保证带宽资源允许时优先处理更紧急的预警事件。本文设置了一个阈值,系统为校验组重构数据所分配的带宽之和不超过该值,否则调度任务将会被延后执行。为了保证更危险的硬盘或校验组被快速处理,系统按照式(4)为每个预警事件分配带宽,在这样的分配方式下,优先级高的预警事件将会获得更多的带宽资源。
(4)
式中:pd(i) 为硬盘d在i时刻对应预警事件的优先级,由式(3)得出。MAX为系统分配的总带宽,∂为一个动态因数,可根据系统的负载情况来调整∂值的大小。
3 DPS的设计
DPS(dynamic priority-incorporated scheduling)的设计过程如下所述:
步骤1 根据硬盘故障预测模型得出的结果,将云存储系统中的硬盘分为健康盘和预警盘,健康盘为被预测为近期不会出现故障的硬盘,预警盘为被预测为近期即将发生故障的硬盘。
步骤2 启动硬盘预警进程,更新本地信息。
步骤3 根据预测结果按照式(1)计算出硬盘的健康度。
步骤4 定位硬盘所在的RAID校验组,根据式(2)计算出其所在校验组的严重程度分数。
步骤5 根据以下两种情况调整预警事件的优先级。
情况1:若系统配置RAID-5被动容错机制,首先判断预警盘所在的校验组是否已处于降级模式。若校验组中已处于降级模式,则该预警事件的优先级设为最高,即Level 6。若校验组没有处于降级模式,则基于步骤2和步骤3的结果,根据式(3)设置预警事件的优先级。
情况2:若系统配置RAID-6被动容错机制,首先判断预警盘所在的校验组是否处于降级模式。若校验组处于降级2模式,则该预警事件的优先级设为最高,即Level 6。若校验组处于降级1模式或没有处于降级模式,则基于步骤2和步骤3的结果,根据式(3)设置预警事件的优先级。
步骤6 建立优先级队列。将预警事件按照优先级的大小先后加入到优先级队列中。
步骤7 建立工作队列。将优先级队列中的预警事件按照优先级的大小依次加入到工作队列中,并更新优先级队列中预警事件的优先级。
步骤8 分配带宽。根据式(4)为工作队列中的预警事件分配带宽。
步骤9 移除工作队列中已完成的任务,并更新工作队列。
步骤10 判断是否达到指定条件,达到则结束程序,否则重复步骤3~步骤10。
其中,硬盘预警进程的流程如图5所示。

图5 硬盘预警进程流程
4 仿真程序
本文根据第2.1节提出的预警调度模型设计了仿真程序,仿真程序通过事件转换模拟主动容错系统中各个事件的发生过程。程序通过4种仿真事件向前推进模拟时间:
(1)运行故障事件,系统中的每一块硬盘均有几率触发,事件发生后系统将增加一个新的硬盘;
(2)故障预警事件,在故障预测模型检测到某块硬盘即将发生故障时触发;
(3)数据重构完成事件,在校验组重构数据完成后触发;
(4)预警处理完成事件,在所有预警硬盘所在的校验组完成数据重构后触发。
仿真程序使用一个最小堆来保存即将发生的事件,这些事件根据时间的先后顺序插入最小堆。程序在开始时基于硬盘的属性信息和决策树预测模型的结果生成一些预警事件,并将预警事件的信息保存在预警信息表中,然后按照时间的先后顺序将预警事件依次插入最小堆。
仿真程序引入了一种值守进程,它按时从最小堆的顶部弹出预警事件,调度算法根据事件弹出的时间及其信息来进行调度。在程序运行期间,每个事件发生的时间将会被累积,直到达到指定条件或者超过设定的仿真时间,程序才会停止运行。在本文中,重复执行仿真程序,直到数据丢失次数达到十次以上才停止运行,并在最后统计运行周期内发生数据丢失事件的期望次数,并以此作为仿真程序的结果。
5 实验及结果分析
5.1 实验准备
对于仿真程序中的故障预警事件,根据2.3节的预测结果确定提前预警时间的概率分布。预警事件弹出后,系统会启动硬盘预警进程。表3列出了仿真程序使用的参数,参数对应的数据为默认值。仿真程序执行环境为Intel Core i7 CPU 3.0 G,内存4 G,64位微软操作系统windows 10,集成开发环境为JetBrains PyCharm Professional 2020.1.2。

表3 参数设置
5.2 带宽分配过程
在主动容错云存储系统中,出现多个故障预警是十分常见的,而系统用于重构数据的带宽资源十分有限。在本节中,实验使用了一组不同优先级的预警事件来说明调度算法如何调度多个预警事件并为其分配合适的带宽。在不考虑系统性能影响的情况下,设置∂=0.3,先后触发3个不同优先级的预警事件,它们的优先级分别为Level 1、Level 3和Level 5。为了验证算法的效果好坏,先触发优先级较低的预警事件,一段时间后再触发优先级更高的预警事件。图6显示了3个不同优先级的预警事件的带宽分配情况。

图6 不同优先级的预警事件的带宽
实验在开始时触发了Level 1的预警事件,当系统中只有一个任务时,它获得了全部的带宽资源。10 h之后,触发级别为Level 3的预警事件,由于该任务级别较高,因此它会获得更多的带宽资源;24 h之后,再次触发级别为Level 5的预警事件,系统再次重新分配带宽。由图6可以看出,系统会优先处理优先级更高的预警事件,当队列中加入了更高优先级的预警事件后,系统会重新分配带宽,优先级高的事件将会获得更多的带宽资源。
5.3 效果分析
根据本文提出的调度模型,操作人员可以更高效率地处理多个预警事件,本节实验将对比分析本文提出的DPS与系统默认的FIFO在不同情境下的应用效果。
5.3.1 RAID重构时间
本节实验分析了两种调度方式在RAID-5和RAID-6系统中统计的运行周期内的数据丢失事件的期望次数,通过调节参数Rc改变RAID重构时间,其余参数参照表3中的默认值,结果显示在图7中。
图7(a)和图7(b)分别给出了两种调度方式在RAID-5和RAID-6系统中运行的结果,可以看出随着重构时间的增加,发生数据丢失事件的期望次数不断增多。其中,在RAID-5云存储系统中,DPS相比于FIFO的调度方式,其数据丢失事件的期望次数降低约14.5%~35.8%;在RAID-6云存储系统中,其数据丢失事件的期望次数降低约12.5%~29.5%。
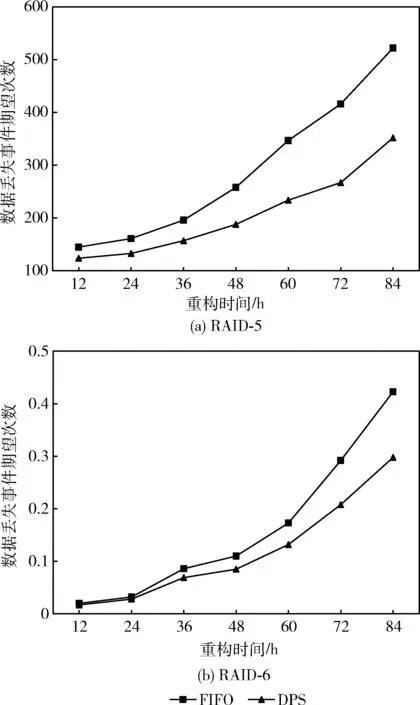
图7 不同重构时间下的数据丢失事件期望次数
5.3.2 操作人员反应时间
在大型的数据中心中,操作人员往往不能及时对预测模型发出的预警进行处理,从而增加了并发故障发生的概率,造成数据丢失。在不同的数据中心中,操作人员处理预警事件的间隔时间不同,本文将从系统发出预警到操作人员处理预警事件的时间称为反应时间。本节实验对比了不同反应时间下在一定运行周期内云存储系统中发生数据丢失事件的期望次数,通过调节参数Rt改变反应时间,其余参数参照表3中的默认值,结果显示在图8中。
图8(a)和图8(b)分别给出了两种调度方式在RAID-5和RAID-6系统中运行的结果,随着操作人员反应时间的增加,发生数据丢失事件的期望次数增多。其中,在RAID-5云存储系统中,DPS相比于FIFO的调度方式,其数据丢失事件的期望次数降低约27.1%~34.1%;在RAID-6云存储系统中,其数据丢失事件的期望次数降低约27.2%~36.1%。

图8 不同反应时间下的数据丢失事件期望次数
6 结束语
本文将硬盘故障预测技术与调度算法结合起来,并提出了一种改进的动态优先级调度策略,更高效地处理主动容错云存储中的硬盘故障预测模型发出的多个预警。该策略综合考虑了RAID-5和RAID-6云存储系统中的冗余机制和主动容错技术,合理分配系统中的用于RAID重构的带宽资源,降低了云存储系统中的数据丢失次数。
本文的调度策略仅考虑了RAID云存储系统,未来的一个研究方向是将调度策略推广到配置了其它被动容错及主动容错技术的存储系统中,并针对不同存储系统的结构对调度策略进行改进。
猜你喜欢
中学生学习报(2022年15期)2022-04-17
家庭影院技术(2020年7期)2020-08-24
家庭影院技术(2020年1期)2020-06-24
网络安全和信息化(2019年7期)2019-07-10
发明与创新·大科技(2019年12期)2019-03-17
电子制作(2017年13期)2017-12-15
电子制作(2017年1期)2017-05-17
电子制作(2017年19期)2017-02-02
弹箭与制导学报(2015年1期)2015-03-11
创新科技(2014年14期)2014-07-27
