
基于知识图谱的跨系统电网多维数据自动挖掘
2023-01-08 16:48毕艳冰于希永杜旭光朱春艳李明
电子设计工程 2023年1期
毕艳冰,于希永,杜旭光,朱春艳,李明
(北京国网信通埃森哲信息技术有限公司,北京 100052)
在电力系统中,电网必须实时保持发电量与电网之间的动态平衡,一旦超出需求范围,将影响电力系统的运行状态。这种情况一旦发生,不仅增加了用电成本,浪费了能源,同时也对电能质量造成了严重影响,无法保证电力系统的安全运行,合理分配电能是预测未来负荷变化的重要手段。目前,使用的基于关联分析算法的挖掘技术,通过处理跨系统的电网多维数据,构建相关性指标模型,并校验冗余数据。结合关联分析算法,挖掘跨系统电网数据[1];基于灰靶理论与云模型的挖掘技术,利用自适应高斯云变换算法,处理跨系统电网数据。构建实际场景与多维数据匹配模型,挖掘跨系统电网多维数据[2]。上述两种方法由于受到来源多、结构化程度复杂数据的影响,导致挖掘结果与理想结果不一致。为了解决以上存在的问题,该文提出了基于知识图谱的跨系统电网多维数据自动挖掘方法。
1 多维数据三维融合展示
为充分展示跨系统多维数据间的相互关系,更直观、有效地挖掘跨系统的多维数据,采用基于知识图谱的三维融合显示方法,使各种数据的相关特性可视化。
1.1 空域数据的显著可视化
为实现多维数据的知识图谱可视化,在系统电网上对多维数据进行投影,具体步骤如下:
第一步:选择最佳的低阶子空间,选取最大范数的行列向量,保证了稀疏矩阵的逼近性,确定低水平空间,并对子空间进行抽样和特征分析[3];
第二步:计算低层样本子空间中每一类物体的类别比例的概率;
第三步:在低水平空间内嵌入样本数据,保证输入样本与低水平空间的数据差异最小[4]。
通过这三个步骤,实现了低层空间大规模数据的可视化。
1.2 时空域数据的显著可视化
该方法融合了空间和时间可视化的重要性,在动态大数据领域具有以下独特的性能:
1)时间效率:该可视化方法的运行时间是线性的,与其他可视化方法相比,它的时间复杂度为O(n2)。另外,对于高精度可视化方法,时空域数据要比空域数据快。
2)空间效率:该可视化方法在空间复杂性方面具有很强的可视化能力,空间复杂度为O(n),而其他算法一般需要O(n2)存储单元。此外,对时空域数据有意义的可视化方法并没有分配所有的历史日历数据空间,因此在处理变化的数据和无法一次装载的大量数据时特别有用[5]。
3)稀疏性:在时空域数据可视化方法中,保留最低空间的稀疏数据。
4)解释性:分解特征子空间矩阵,形成三个子空间,并对子空间进行选择和更新,避免数据排列的混乱和重叠。
1.3 可视数据的分析与交互
基于空域和时空域显著可视化特征,进行了跨系统电网多维数据的分析与交互,基于知识图谱的三维融合显示结果如图1 所示。

图1 基于知识图谱的三维融合展示
由图1 可知,图(a)、(b)分别为t-1 时刻的可视化和t时刻的可视化,其中每一点代表了视频中特征点的分布。图中显示记录数量递增的视觉分布变化很小,代表了一段时间的一致性。图(c)不仅增强了知识图谱的可视化程度,还可以更新数据。通过整合图(a)、(b)、(c),可确定完整的可视化区域,将该区域转换为放大视图来显示详细数据[6-7]。
2 多维数据挖掘模型构建
在计算机上挖掘多维数据时,如果将供电可靠性提高,并用0 到5 六个不同字符来表示,则可使用[1,0,0]表示改进。因此,当一个数据被映射到一个D维向量时,这个数据不对应向量矩阵L。这种表示方式存在两个潜在的问题:一是容易产生数据稀疏性,二是数据属性相似[8]。为此,提出了一种适用于计算机多维数据挖掘的方法,结合知识图谱,将电网多维数据中得到的原始数据进行变换,并对数据向量矩阵L进行优化[9]。构建基于知识图谱的多维数据挖掘模型,如图2所示。由图2 可知,对于确定的n元任意组,利用中心数据的向量f(αi)来预测跨系统电网多维数据中的第t个数据αt的概率,计算公式为:
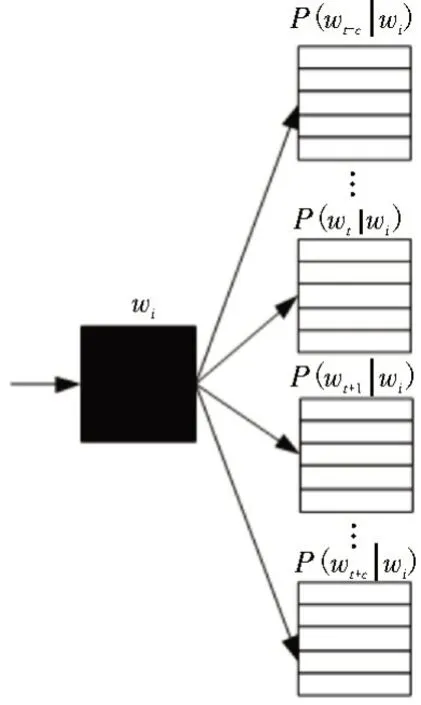
图2 基于知识图谱的多维数据挖掘模型

式中,αi表示中心数据;f(αi)∈Rn表示中心数据对应的n维数据向量,该向量可通过检索n维数据向量矩阵L可以获取[10-11]。
基于知识图谱的目标函数是一种n维数据向量矩阵,使全部数据的对数似然最大化,该过程可描述为:

式中,C表示挖掘背景窗口大小。
跨系统电网多维数据经过挖掘后,获取优化后的n维数据向量矩阵包含了所有挖掘目标的分布式向量[12]。
3 跨系统电网多维数据挖掘
结合构建的基于知识图谱的多维数据挖掘模型,详细设计了跨系统电网多维数据挖掘流程:
步骤一:初始化处理实时数据库、已知故障区域、未知故障区域。在已知的故障区域和实时数据库分别添加初始训练样本集,共有N个待测样本[13]。
步骤二:该算法以现有的实时数据库为样本,采用迭代优化方法,获得惩罚系数λ。在选定多维数据挖掘模型参数的基础上建立了新的多维数据挖掘模型参数[14]。
步骤三:提出了一个新的多维数据挖掘模型来检测第n个样本。设样本xi是n维数据,通过非线性映射ϕ将数据映射到高维空间中,结合SVDD 算法检索最小区间,保证所有非线性映射样本φ(xi)均包含在该区间,可将SVDD算法的求解转化为式(3)优化问题:

式中,R表示区间周长;λ表示惩罚系数;ξi表示变量系数;O表示区间中心[15]。如果计算结果大于0,则判断样本为已知的故障类型,并转移至已知的故障区域;反之则移入未知故障区域。
得到多维数据自动分类样本如式(4)所示:

步骤四:如果故障区中的样本数增量为numi,则执行步骤六;否则,继续执行步骤三。
步骤五:当未知故障区域样本数达到上限numuni时,利用知识图谱联合搜索未知分组故障,总搜索次数总计numuni-1 次。在第nuni(0 ≤nuni≤numuni-1)次搜索过程时,基于知识图谱聚类后,确定某一类未知故障的样本数目达到设定下限numunf。在第numi次聚类中,此类别中样本数目最大的组可被视为新故障,并把这组新故障的样本群从未知故障区域转移至实时数据库中,并更新未知故障区域[16]。
步骤六:对当前已知故障区域的样本集聚类后,判断每个样本的类别。更新群集结构(群集分布、群集中心)到实时数据库。如果已知故障区域中的样本数量等于N,则执行步骤七;如果已知的错误区域的样本量小于N,则执行步骤二。
步骤七:判断所有N个测试样本的故障类型,完成跨系统电网多维数据自动挖掘。
4 仿真实验
研究基于知识图谱的跨系统电网多维数据自动挖掘方法在某市公司试点进行仿真实验分析。其数据来源于110 kV 变电站工程,非结构化数据为该工程实验报告,实验数据为2 900 个字符串和35个长度为150 的列表,为了方便实验分析,需抽取实验数据。
4.1 数据库分析
对于来源多、结构化程度复杂的跨系统电网多维数据,获取设备名称、种类、材料和成本明细描述四类实体数据共500 个,属性关系489 条。其数据库的结构如图3 所示。
由图3 可知,过滤重复数据,完成数据库的开发。从word 文件和excel 文件中抽取四类实体数据共400 个。

图3 数据库结构
4.2 实验结果与分析
将准确率、召回率和F 值作为指标,对比分析基于关联分析算法、灰靶理论与云模型的基于知识图谱的挖掘技术字符串抽取结果。其三个指标计算公式,如下所示:

式中,Recall 表示准确率;Precision 表示召回率;f表示正确划分数据种类数;M表示实际划分数据种类数;G表示划分数据种类数。
三种方法在1 000 个测试字符串上,共划分为150 种类别,对应的三个指标计算结果如表1 所示。
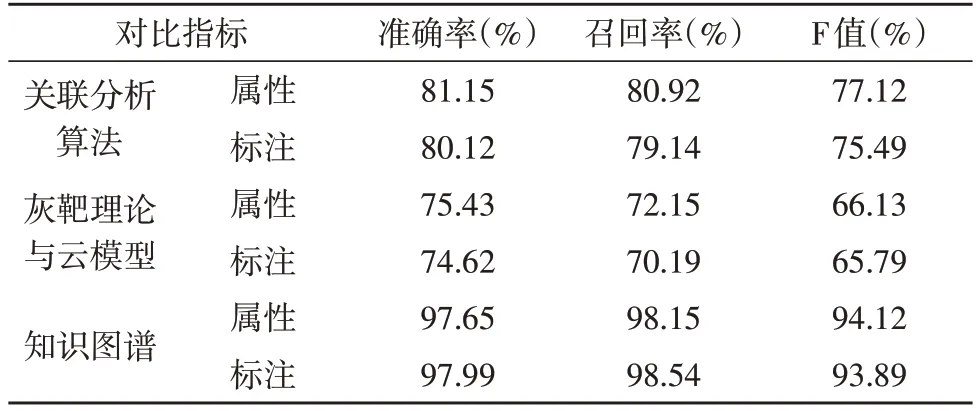
表1 三种方法三个指标计算结果对比分析
由表1 可知,使用基于知识图谱的挖掘技术表现明显优于关联分析算法和灰靶理论与云模型挖掘方法。抽取数据间的属性关系,确定考虑依存关系指标和不考虑依存关系指标,如下所示:

式中,U表示考虑依存关系指标;L′表示不考虑依存关系指标;r表示核心数据正确的数量;r′表示核心数据正确且依存关系也正确的数据量;R′表示总数据量。使用三种方法对比分析不同数据字符串间的依存关系,对比结果如表2 所示。

表2 三种方法不同数据字符串间依存关系对比结果
由表2 可知,使用的基于知识图谱的挖掘技术可以取得比基于关联分析算法、灰靶理论与云模型挖掘技术更加精确的结果。
5 结束语
利用知识图谱实现跨系统电网多维数据的自动挖掘方法,既能满足不同用户的自动检索需求又能解决基础设施项目间数据跨系统交换的障碍。随着现代化智能电网的不断建设与发展,知识图谱的构建也需要不断更新和完善。未来应考虑数据一致性和ETL 技术,以研究知识库的自动更新,确保知识库的有效性。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
师道·教研(2022年1期)2022-03-12
大众投资指南(2021年35期)2021-02-16
少先队活动(2020年12期)2021-01-14
中国交通信息化(2020年1期)2020-07-27
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
智能系统学报(2013年1期)2013-01-28
