
基于语义分割的芒果表皮缺陷识别
2023-01-08 08:06刘小刚李荣梅杨启良
华南农业大学学报 2023年1期
刘小刚,李荣梅,范 诚,杨启良,赵 璐
(1 昆明理工大学 现代农业工程学院, 云南 昆明 650000; 2 中联重科智能技术有限公司,湖南 长沙 410013; 3 四川大学 水利水电学院, 四川 成都 610065)
芒果具有良好的食用价值[1],市场需求不断增加。市场对芒果的外部品质进行分级的主要指标是形状、颜色、大小以及表皮缺陷,其中,芒果的表皮缺陷对其能否在市场上的销售起决定性的作用。目前市场水果的大小和质量分选主要依靠机械工程技术[2-3],而形状、颜色、表皮缺陷的检测大多由人工完成,劳动强度大、效率低、成本高。如果采用智能机器在自然环境下对果实进行采摘,将表皮缺陷的芒果与表皮完好的芒果分开,完成初步的分级,可避免对完好果实的污染及浪费。因此,对芒果果实进行表皮缺陷检测是目前需要解决的关键问题。
随着人工智能的发展,越来越多的算法应用在农产品加工领域,主要应用于果实的分类[4-6]、成熟度检测[7]、病虫害检测[8-9]及缺陷检测[10]。刘平等[11]采用Chan-Vese模型对贴叠葡萄串进行识别,识别准确率达89.71%;李江波等[12]采用分水岭算法对桃子表皮缺陷进行识别,取得了较高的准确率。然而面对复杂的自然环境,如遮挡、密集、光照等因素影响,传统的模型算法精度不能满足实际需求。更多的研究表明基于深度学习的模型较传统机器学习模型在速度和准确率方面表现更好[13-14],运用神经网络算法对农产品进行识别[15-16]已成为热点。Jhuria等[17]运用神经网络对图像进行训练来识别苹果的表皮缺陷,实现了在线实时检测,Basavaraj等[18]运用神经网络对香蕉病害进行识别,实现了端到端的自动化识别。
目前已经提出了许多芒果表皮缺陷的识别算法。Sahu等[19]通过将RGB图转换为灰度图和二值图像,再执行滤波操作以去除背景和噪声来识别图像中的缺陷,能有效地识别出芒果表皮缺陷;但该方法只能进行单幅图像的识别操作,效率低。Huang等[20]采用支持向量机的方法进行芒果识别,并结合比色传感器阵列对芒果进行质量分级,在测试集的精度达到97.5%,具有无损、省时的特点。Sudarjat等[21]采用近红外光谱法能够准确检测芒果表皮的病害,但没有进行自然环境下的检测。Kestur等[22]采用基于语义分割的算法MangoNet对自然环境下的芒果进行检测,取得了比FCN网络[23]更好的结果,较机器学习模型有了更好的性能。然而,实际自然环境复杂多变,存在逆光、顺光、果实密集、遮挡与粘黏等现象,降低了以上模型检测的准确率。为此,本研究基于改进的DeepLabV3+语义分割算法[24],识别自然环境下芒果的表皮缺陷,以期获得更好的识别精度,进而为芒果缺陷识别提供参考。
1 材料与方法
1.1 试验材料
芒果图像采集于中国西南地区云南省玉溪市元江县,4个品种分别为‘鹰嘴芒’、‘金煌芒’、‘苹果芒’和‘贵妃芒’。图像采集时间分为白天和夜晚,在自然环境下共采集芒果图像820张,经过图像翻转、平移、镜像、缩放等几何变换后扩增数据集为 1 340张图像,图像的分辨率为 1 440 像素×1 080像素。按照6∶2∶2的比例划分训练集、验证集和测试集,训练集图像为804张,验证集、测试集的图像均为268张。将数据集类别划分为芒果、缺陷、茎梗、背景4种,图像的分辨率缩放为512像素×512像素。
1.2 图像预处理
由于数据集是在自然环境下采集的,存在果实相互遮挡的情况,为了使模型具有更好的泛化性,本文对图像进行随机遮挡处理。在试验数据集中发现芒果表皮存在细小的斑点,这些斑点是正常的生理现象,不影响芒果的质量,然而过于密集的斑点会导致模型将其误判为表皮缺陷。
针对表皮具有密集斑点的芒果,对图像进行闭运算(图1),即依次进行膨胀、腐蚀处理,可以有效地去除表皮细小的斑点。首先进行膨胀处理,将图像与核进行卷积运算,取每个局部的最大值;图像的腐蚀处理是求取每个局部的最小值。本研究采用的核形态为矩形,大小为(1,1),处理1次。采用闭运算去除芒果表皮颜色较浅的斑点,保留颜色较深的区域,具体计算如下:

图1 图像形态学处理Fig. 1 Image morphological processing


式中,I为图像矩阵,S为结构单元,E为腐蚀后得到的图像,D为膨胀后得到的图像。
1.3 模型结构
1.3.1 联合上采样金字塔模块采用 DeepLabV3+算法对芒果表皮缺陷进行分割,并作出如下改进:使用联合金字塔上采样模块(Joint pyramid upsampling,JPU)[25]替换空洞空间卷积池化金字塔(Atrous spatial pyramid pooling,ASPP)模块,降低计算复杂度、提升运行速度。其次,采用扩张卷积(Atrous conv)[26]替换主干网络ResNet中部分常规卷积(Regular conv),扩张卷积的在增大特征图感受野的同时,能够保持特征图尺寸,避免空间位置信息的损失,使模型收敛得更快,并提高其精度。
JPU模块:不同于ASPP只利用1个特征图(f5)中的信息,该模块将主干网络最后3个特征图(f3~f5)作为输入,使用多尺度上、下文模块产生最终的预测。首先,对每个输入特征图进行卷积使其通道数一样,然后进行上采样操作使其分辨率一致(图 2a),并行使用不同膨胀率 (1、2、4、8)和 4个可分离卷积提取特征(图2b),膨胀率为2、4、8的卷积用于学习映射h,将ym转化为ys,较小的膨胀率有利于小目标的识别,较大的膨胀率能够增大感受野,对较大目标更敏感,从而在特征图中提取到多尺度信息。最后对其进行卷积生成最终的预测(图2c),计算见下式:

图2 联合上采样金字塔结构Fig. 2 The structure of joint pyramid upsampling

式中,h表示输入与输出的映射关系,ys表示输出的特征,ym表示输入的特征。
1.3.2 编码器与解码器在编码器中对 ResNet50网络进行修改,替换conv5 阶段的部分常规卷积为扩张卷积,得到Atrous-ResNet作为主干网络。Atrous-ResNet中不存在可分离卷积,并且除扩张卷积层之外,所有网络层均能加载ImageNet预训练模型参数,进行有效的初始化,大幅提升模型的精度和收敛速度。但是,主干网络中加入扩张卷积,会增加模型后续阶段的计算成本,因此只研究在ResNet网络的conv5 阶段加入扩张卷积的情况。主干网络各个阶段输出的图像为原图尺寸的1/2、1/4、1/8、1/16和 1/32。在DeepLabV3+基础上引入了更多来自Encode模块的特征图(图 3),将f3~f5层特征图连接到Decoder模块,得到更多语义信息的同时具有更多的空间信息,使高层特征图对分割结果起到更大的作用。

图3 改进的算法架构图Fig. 3 Structure chart of improved algorithm
1.3.3 评价指标模型评价指标是衡量模型训练结果优劣的重要因素,能够直接反映出模型在训练集的学习效果及验证集的测试效果。采用的评价指标为类别像素准确率 (Class pixel accuracy,CPA)、平均像素准确率 (Mean pixel accuracy,MPA、平均交并比 (Mean intersection over union,MIoU)。其中,MPA反映总体的多类别预测准确率,MIoU是语义分割模型的标准度量指标。评价指标的值越大,模型的效果越好。每种类别像素的准确率计算如下式。
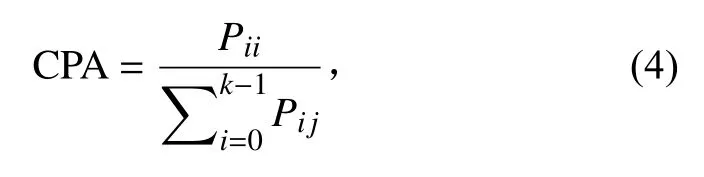

式中,Pii表示第i个类别预测准确的数量,Pij表示将第i 类别物体预测为第类别的数量,Pji表示第j类别物体预测为第i类别的数量,i 表示真实类别,表示预测类别。为类别的数量,不考虑背景类别,因此 k为 3。

通过计算每一类真实值及预测值像素集合的交集和并集的比值,得到每一类别的交并比后,计算所有类别的平均值即为平均交并比,该指标在试验中能够较好地反映模型在不同类别区域分割的准确性和完整性。
2 结果与分析
2.1 主干模型的训练与测试
试验环境:本研究采用Pytorch1.5深度学习框架,Python3.6语言,CPU:Intel i9-9900KF,GPU:NVIDIA RTX 2070。所有模型训练及测试都在同一硬件环境下进行,模型初始学习率为1×10-4,采用Adam优化器,对数据集训练了120次迭代,并且在线对数据进行随机裁剪、缩放、翻转、镜像等几何变换操作,采用基于ImageNet数据集的预训练模型。
为了比较模型在训练集的效果,将本文改进的模型Atrous-ResNet与DeepLabV3+算法Xception模型的损失值与平均像素准确率进行比较,结果如图4所示。Atrous-ResNet模型训练集的准确率达到97.30%,模型的损失值较Xception模型下降0.263,说明改进后模型的预测值与真实值的差异更小,预测结果与真实结果更接近;且平均交并比较原模型均有提升,本研究所作改进具有可行性。

图4 不同模型评价指标的比较Fig. 4 Comparison of evaluation indexes for different models
2.2 多场景的识别效果比较
本研究采集了多种场景下的芒果图像,时间有白天和夜晚,数量分布情况分为果实密集、稀疏,位置上为果实遮挡与粘黏。在测试集中挑选白天及夜晚的芒果图像均为20幅,随机挑选果实密集及稀疏的图像均为15幅,随机挑选果实遮挡与粘黏的图像10幅,使用改进的模型Atrous-ResNet与DeepLabV3+模型分别进行检测,结果见图5。由图5可知,侧光照射下,芒果图像表皮纹理、缺陷清晰,是理想的光线环境;顺光照射下芒果表皮会有一定的反光现象,光线强的部分纹理不清晰,易造成漏识别;逆光照射下,芒果背景较暗,表皮纹理不清晰、缺陷边界模糊,增加了缺陷定位的难度。白天不同光照且果实稀疏时,DeepLabV3+模型与改进模型识别效果相近,但是改进模型在类别边界定位上更加平滑。在夜晚使用LED灯照明时,芒果的表皮纹理较清晰,但背景颜色暗,只能识别光线照射良好的芒果。芒果分布密集时,靠近镜头的芒果表皮较清晰,体型较大,模型易识别;远离镜头的芒果表皮不清晰且体型较小,导致模型难以识别缺陷。在芒果、茎梗密集且相互遮挡时,模型对于细小的缺陷部位难以定位。
2种模型在不同场景的测试集中进行测试(表1),Atrous-ResNet模型对芒果识别的准确率较DeepLabV3+模型高,CPA上升3.79个百分点,MIoU上升4.57个百分点。总体来看,Atrous-ResNet模型在测试集的表现均优于DeepLabV3+模型,但在自然复杂场景下,芒果表皮较小的缺陷难以检测,模型的性能仍需要提升,特别是针对小目标的检测。

表1 DeepLabV3+与Atrous-ResNet模型的评价指标比较Table 1 Comparison of evaluation indexes between DeepLabV3+ and Atrous-ResNet model%
2.3 多种算法在芒果表皮缺陷数据集的检测效果
为了进一步评价不同模型的优劣,探究多种算法对芒果表皮缺陷数据集的检测效果,选择有代表性的实时网络LinkNet[27]、标准网络SegNet[28]与Atrous-ResNet进行比较。
由图6可知,不同光照下,侧光照射下识别效果相对较好;不同密集程度下,果实稀疏的识别效果优于果实密集;不同时间段下,白天的情况复杂,识别效果多样,夜晚只有在光线良好的条件下才能有效识别;果实遮挡与粘黏条件下的识别效果较差。总体来说,Atrous-ResNet模型在不同场景下的识别效果均优于其他模型。

图6 LinkNet、SegNet及Atrous-ResNet模型在不同场景下的识别效果对比Fig. 6 Comparison of recognition performance among LinkNe, SegNet and Atrous-ResNet model in multi-scenarios
表2为3种不同的算法对测试集评价指标的结果,Atrous-ResNet模型较LinkNet与SegNet算法有显著的提升,CPA上均高于LinkNet与SegNet,MPA较LinkNet算法提升13.02个百分点,较SegNet算法提升16.19个百分点;MIoU较LinkNet算法提升15.28个百分点,较SegNet算法提升19.96个百分点。同时发现,实时语义分割算法LinkNet在识别效果上优于SegNet算法。

表2 不同算法的评价指标的比较Table 2 Comparison of evaluation indexes of different algorithms%
3 结论
本研究以芒果为研究对象,采用图像处理及语义分割相结合的方法对多场景下芒果表皮缺陷进行检测,主要结论如下。
1) 改进 DeepLabV3+模型,主要在 ResNet网络中添加Atrous卷积,有利于增大模型的感受野,其次采用JPU模块替换ASPP模块,能提取到更多的尺度特征,使模型预测的边界更加平滑,对细小缺陷的识别更准确。
2) Atrous-ResNet模型较原始 DeepLabV3+模型,类别像素准确率有所提升,MPA为94.48%,MIoU为94.13%,满足自然复杂场景下芒果表皮缺陷识别的要求。
3) Atrous-ResNet模型的 CPA、MPA 及 MIoU均优于LinkNet和SegNet模型。
猜你喜欢
建材发展导向(2021年14期)2021-08-23
动漫界·幼教365(中班)(2020年3期)2020-04-20
祝您健康·文摘版(2019年4期)2019-06-11
民族古籍研究(2018年1期)2018-05-21
动漫界·幼教365(小班)(2018年10期)2018-05-14
动漫界·幼教365(大班)(2018年10期)2018-05-14
西夏学(2016年2期)2016-10-26
中国中西医结合皮肤性病学杂志(2016年4期)2016-07-18
中国房地产业(2016年9期)2016-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
