
高维生存分析数据在带有测量误差情形下的变量选择方法*
2023-01-11 13:07张家睿吴耀华
中国科学院大学学报 2023年1期
张家睿,吴耀华
(1 中国科学技术大学管理学院, 合肥 230026; 2 香港大学浙江科学技术研究院, 杭州 310000)
在过去10年里分子生物学试验技术的进展给我们带来了丰富的生物医学数据,举例来说,DNA显微序列可以用来测量一个细胞中成千上万的基因。这种类型的数据中样本维度p比样本量n要大得多,对于传统的统计推断方法来说是一个巨大的挑战,有很多经典的推断方法在这种情况下变得不适用。这种情形下有效的变量选择方法就变得尤为重要。比较著名的高维数据变量选择方法有Lasso[1],SCAD[2]和MCP[3]等。
当研究关于患者生存状态的医疗数据时,将高维的生物医疗数据和患者的生存状态数据结合起来分析是一个很有效的方法。因此近些年来也有很多关于高维生存分析模型的变量选择方法,比如Bradic等[4]关于高维Cox模型的正则化方法,Gorst-Rasmussen和Scheike[5]关于高维单指数模型的筛选方法,Lin和Lyu[6]关于高维可加模型的正则化方法等等。高维生存分析模型还广泛地应用到信用风险分析,比如Fan等[7]。
由于在实际生活中,我们经常会遇到带有测量误差的数据,所以对于带有测量误差数据的分析方法也是一个重要的研究方向,对于高维线性模型有Loh和Wainwright[8]以及Datta和Zou[9]的相关工作;对于变系数模型,有刘智凡等[10]的工作。对于带有测量误差的生存分析数据的变量选择方法,代表文章有Song和Wang[11]关于工具变量的工作,Chen和Yi[12]关于Cox模型左截断右删失数据的工作。高维生存分析模型由于其计算复杂度较高以及理论性质较为复杂,所以对于带有测量误差的高维生存分析数据的工作随着近些年大数据的迅速发展才逐步出现在视野之中。具有代表性的文章有Chen和Yi[13]关于高维生存分析图模型的工作以及Chen等[14]关于高维Cox模型利用纠正似然函数的工作。本文选择同样具有重要应用的可加风险模型作为基础,结合处理高维线性模型的正则化方法对带有测量误差的生存分析数据进行分析。
1 研究背景
本文所采用的模型为高维可加风险模型,结合高维线性模型测量误差处理办法对带有测量误差的生存分析数据进行分析。下面对高维可加风险模型和高维线性模型测量误差处理方法分别进行介绍。
1.1 高维可加风险模型
对于生存分析数据的变量选择技术的发展已经不拘泥于Cox模型,可加风险模型便是除Cox模型以外的一种重要替代方式。可加风险模型假设失效时间为T的风险函数和p维的协变量X(·)有如下形式的关系
(1)
其中:λ0(·)是一个不确定的基线风险函数,β0是一个p维的回归系数。令C为删失时间,则定义删失失效时间为CFT=C∧T,令CFT=t1,…,tn,失效指数定义为δ=I(T≤C),其中I(·)为指示函数,令X(t)=(X1(t),…,Xp(t))并且假设给定X观察到的数据为(CFT,δ,X(·)),风险函数由式(1)给出。
采用常用的计数手段,定义观察到的失效计数序列为Ni(t)=I(ti≤t,δi=1),风险中指数为Yi(t)=I(ti≥t),计数过程鞅为
(2)
后文也将用N(t),Y(t)和M(t)来代表这些计数过程的广义形式。
Lin和Ying[15]采用一种有如下形式的伪得分方程来对可加风险模型进行分析:
{dNi(t)-Yi(t)βTXi(t)dt},
(3)
其中β∈p,并且
(4)
τ是最大的跟踪时间(生存时间和删失时间的最大值)。这个估计函数关于回归系数是线性的,令
(5)
和
(6)
其中v⊗2=vvT,通过一些代数变换,可以写出如下等式
U0(β)=b0-V0β.
(7)
在没有测量误差的情况下,V0是半正定的,式(7)两边关于β积分就可以得到损失函数
(8)
Leng和Ma[16]以及Martinussen和Scheike[17]都建议用上述损失函数配合正则化方法对可加风险模型(1)进行变量选择。本文的相关工作也是在此基础上进行。
1.2 高维线性模型测量误差数据的处理方法
为了进一步构建更深层次的讨论,假设观察到的是被污染的协变量矩阵
Z(·)=(zij(·))1≤i≤n,1≤j≤p,
(9)
而不是真实的协变量矩阵X(·)。有很多种造成测量误差的途径,在加法测量误差设定中,zi,j(·)=xi,j(·)+ai,j,其中A(·)=(ai,j)是加法测量误差。在乘法测量误差设定中,zi,j(·)=xi,j(·)mi,j,其中mi,j就是乘法测量误差。缺失数据可以看作乘法测量误差的一个特殊形式,mi,j=I(xi,j(·)没缺失)。
不失一般性,用Lasso算法来举例说明测量误差的影响,对于线性模型y=Xβ+来说,Lasso算法是最小化
(10)
这等价于最小化
(11)

(12)
然后解决下面的优化问题来得到β的估计:
(13)

(14)
其中R是一个跟稀疏度有关的常数。Datta和Zou[9]提出一种最近邻正定投影矩阵的算法来解决上述问题,对于任意方阵K:
(15)

(16)
(17)
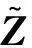
2 带有测量误差的高维可加风险模型的变量选择方法
2.1 简化伪得分方程
在第1节中已经介绍了Lin和Ying[15]的伪得分方程的具体形式,下面将在协变量X期望值为0的前提下简化该伪得分方程,提出一种全新的更加容易计算且符合实际情况的损失函数。首先定义
(18)
以及
(19)
则有
(20)
接着定义
(21)
由于X的期望为0,所以容易得到E(U(β))=0,在如上定义的基础上,类似于式(7),有
U(β)=b-Vβ,
(22)
式(22)对β积分即可得到期望为0时的损失函数
(23)
综上所述即为简化版本的损失函数,我们将基于这个损失函数进行变量选择。
2.2 两种测量误差数据的变量选择方法
2.2.1 加法测量误差
假设观测到的设计矩阵Z(·)被加法测量误差污染,即zi,j(·)=xi,j(·)+ai,j,其中A(·)=(ai,j)。同时假设A的行是独立同分布的,均值是0,协方差矩阵是ΣA,次高斯参数是τ2。假设ΣA是已知的,则V和b的无偏估计分别为
(24)
和
(25)

(26)

2.2.2 乘法测量误差

(27)
以及
(28)
其中∥代表向量或者矩阵对应元素相除。和加法测量误差模型类似,乘法测量误差下无偏估计矩阵也有可能不是正定的,所以基于Datta和Zou[9]的方法,可以得到相应的凸损失函数:

(29)

3 理论性质
在这一节中给出并推导估计量的l1和l2误差界。记我们的估计量为CoCo估计量。首先定义近邻条件:


(30)

(31)
对所有1≤i,j≤p成立。其中集合S={1,2,…,s}是回归系数β的支撑集。
同样也需要和线性模型下一样的特征值限制条件:
条件3.2协方差阵特征值限制条件
(32)
条件3.2是一个在高维线性模型变量选择中比较常见的假设。下面给出CoCo估计量的统计误差界:
定理3.1在式(30)、式(31)和式(32)成立的前提下,对于λ≤min(ε0,12ε0‖βS‖∞)和ε≤min(ε0,Ω/64s),下式至少以概率

(33)
其中
(34)

引理3.1说明加法测量误差的计算方法满足近邻条件。下面将对乘法测量误差进行说明。为了保证乘法测量误差的计算方法也满足近邻条件,需要添加额外的正则化条件如下:
(35)
则接下来有
引理3.2说明了乘法测量误差的计算方法满足近邻条件。将引理3.1,引理3.2和定理3.1结合有

推论3.1给出了加法测量误差估计方法和乘法测量误差估计方法的理论保证,确定了估计量l1和l2的误差界,下面将通过随机模拟实验和实际数据分析来验证我们的理论结果。
4 实验及结果分析
本文的方法简记为CoCo,Loh和Wainwright[8]的方法记为NCL,在随机模拟实验和实际数据分析中将对两种方法进行比较。
4.1 随机模拟
4.1.1 加法测量误差模型
从可加风险模型中产生数据,设定λ0=5,回归系数为
β=(3,1.5,0,0,2,…,0).
(36)
样本量n=100,样本维度p=200,X的行独立同分布,均值为0,协方差矩阵为ΣX,考虑两种情形下的ΣX:自回归(ΣX,ij=0.5|i-j|)和复合对称(ΣX,ij=0.5+I(i=j)*0.5),删失时间服从U(0,2)的均匀分布使得删失率维持在20%左右。首先生成3n×p的X,然后从中选出n个满足λ0+βTX>0的样本作为实验数据。加法测量误差为矩阵A,观测数据由Z=X+A生成,A的行是服从N(0,τ2I)的独立同分布变量,其中τ=0.25、0.5和0.75。

表1展示了CoCo和NCL两种方法分别在自回归和复合对称条件下的100次重复实验的结果,可以看出在两种情形下本文方法的选对数量和估计的均方误差方面都比NCL方法要好。

表1 加法测量误差两种方法的结果Table 1 The results of two methods under additive error-in-variable data
4.1.2 乘法测量误差模型
与加法测量误差模拟类似,依旧从可加风险模型中产生数据,λ0=5,回归系数,样本量和样本维度都保持不变,X的行独立同分布,均值为0,协方差矩阵为ΣX,依旧考虑ΣX在自回归和复合对称两种条件下的情形,并且与加法测量误差中的设定保持一致。删失时间服从U(0,2)的均匀分布使得删失率维持在20%左右,首先生成3n×p的X,然后从中选出n个满足λ0+βTX的作为实验数据。乘法测量误差矩阵为M=((mi,j)),观测数据由Z(·)=X(·)⊙M生成,log(mi,j)是服从N(0,τ2I)的独立同分布变量,其中τ=0.25、0.5和0.75。与上一个随机模拟实验一样,依旧采用5折的交叉验证方法来估计CoCo估计量和NCL的参数R。同样记录C和IC分别代表选对的系数数量和错误的数量,还记录均方误差(MSE)以及其标准差(se)。总共进行100次实验取平均数作为最后的结果,在表2中展示。
表2展示了乘法测量误差中,CoCo和NCL两种方法分别在自回归和复合对称条件下的100次重复实验结果,可以看出在两种情形下本文方法的选对数量和估计的均方误差都比NCL方法要好。但是随着测量误差变大,CoCo和NCL方法的估计精确度都会有明显下降。

表2 乘法测量误差两种方法的结果Table 2 The results of two methods under multiplicative error-in-variable data
4.2 实际数据分析

为了检验我们方法的有效性,将295个样本随机分成包含235个样本的训练集和60个样本的验证集并重复100次,在每一次实验中,都采用随机模拟实验中的两种方法,即CoCo和NCL,用训练集训练模型参数并用验证集来筛选表现最好的估计量。计算
(37)
作为检验两种方法效果的指标。具体的结果展示在表3中。从表3中可以看出我们的方法依旧有比较高的预测精确度,这也和随机模拟实验的结果相符。我们方法的指标相比NCL方法要好一些,并且变量选择的数量上也比较相近。

表3 加法测量误差情形下两种方法应用在乳腺癌数据中的结果Table 3 The results of two methods in breast cancer data under additive measurement error
5 结论
本文提出一种针对高维可加风险模型中带有测量误差情况下的变量选择方法。在已知的生存分析数据相关文献中,尚未有针对测量误差数据的变量选择方法。本文基于高维线性模型测量误差数据的估计方法,重构了高维可加风险模型,并给出了加法和乘法两种测量误差模型的变量选择算法。简化伪得分方程的形式更加简洁且实用性强。随机模拟实验和实际数据分析的相关结果证实了本文方法的有效性和精确性。
在未来的工作中,我们将致力于将简化伪得分方程应用于高维可加风险模型的变量选择中。同时也会对Cox模型,加速失效模型等其他生存分析模型中的测量误差数据利用最近邻半正定投影的方法进行变量选择方面的探索。
猜你喜欢
小学生学习指导(低年级)(2022年10期)2022-11-05
数学杂志(2022年4期)2022-09-27
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
数学小灵通(1-2年级)(2021年10期)2021-11-05
语数外学习·初中版(2020年11期)2020-09-10
应用数学(2020年2期)2020-06-24
小学生学习指导(低年级)(2019年9期)2019-09-25
测控技术(2018年4期)2018-11-25
电测与仪表(2015年18期)2015-04-12
应用数学与计算数学学报(2014年3期)2014-09-26
