
一种端到端的加密流量多分类粗粒度融合算法*
2023-01-16 15:05程永新卜君健廖竣锴
通信技术 2022年11期
唐 晋,程永新,卜君健,廖竣锴
(1.中国电子科技集团公司第三十研究所,四川 成都 610041;2.电子科技大学,四川 成都 610054)
0 引言
随着信息社会的发展,互联网已经成为社会生活不可或缺的基础设施,网络对人们社会生活的影响愈发深刻,人们对于网络空间的安全也越来越重视。网络流量分类是网络行为分析、网络异常检测等重要任务的一个先决任务。近年来,为了保障网络通信的机密性和保密性,各种流量加密技术在网络应用中被广泛使用,经过加密的流量数据的特征被掩盖,给传统的流量分类方法带来了挑战[1]。
对于加密流量,使用传统的基于深度包检测和基于流量特征提取的机器学习算法等手段进行分类时,从解析后的加密流量数据中无法提取足够有效的信息,准确率大幅度下降[2]。深度学习采用端到端的学习技术,可在学习过程中自动提取数据特征,是表征学习领域的代表性技术。流量数据作为一种字节流数据能被深度学习技术很好地接收处理,如Wang 等人[3]通过将流量的字节流转化为可视化图像数据,利用卷积神经网络对加密流量数据实现了有效的分类。
本文在流量数据可视化的基础上,利用表征学习技术,针对加密流量多分类问题,提出了一种端到端的粗粒度融合算法。本文提出的方法能很好地与现有的基于表征学习的多分类算法相结合,在保证运行效率的情况下提升多分类效果。文章的其余部分组织如下:第1 节描述传统的流量分类方法和利用深度学习方法进行流量分类的相关工作;第2节详细介绍本文提出的端到端的加密流量多分类粗粒度融合算法;第3 节描述在ISCX VPN-nonVPN公开流量数据集上进行实验的细节,并对实验结果进行分析;第4 节对本文工作做出总结。
1 相关工作
1.1 基于传统方法的流量分类
传统的流量分类方法主要使用的是机器学习算法,这些算法通常使用网络流量的流特征和数据包特征,流特征包括流的持续时间、流的字节数等,数据包特征包含每个数据包的大小、数据包持续时间等。例如,Wang 等人[4]基于流特征使用C4.5 决策树分类器对流量进行了分类,Coull 等人[5]基于数据包特征利用朴素贝叶斯算法对流量进行了分类。
传统流量分类方法发展面临的一个问题是面对不断复杂化的网络流量数据,如何提取新的流量特征来对流量数据进行有效分类。Draper-Gil 等人[6]使用流量的时间特征来对加密流量进行了分类,并发布了ISCX VPN-nonVPN 数据集。Yamansavascilar等人[7]针对J48、随机森林、K 最近邻(K-Nearest Neighbour,KNN)和贝叶斯网络4 个算法,选用了111 个流量特征对加密流量进行了分类。Muliukha等人[8]对虚拟连接产生的流量和协议加密流进行了分类,具体考虑了流量的IP 地址、数据包总数、端口等特征,并使用随机森林算法进行了流量分类。Obaidy 等人[9]对Skype、WhatsApp 等社交媒体应用程序的流量进行了识别分类,使用Wireshark 从最终用户机器收集数据,以生成社交媒体应用程序的流量,然后基于Wireshark 工具的特征选择来选择14 个双向流量,以获得更好的分类精度。
然而,随着流量加密技术的广泛使用,加密流量特征提取越发困难,并且传统机器学习算法对于复杂模式的学习能力过分依赖于特征的提取,其分类性能逐渐无法满足需求。
1.2 基于深度学习的流量分类
深度学习是表征学习领域的代表性技术。随着流量加密技术的广泛使用,由于深度学习具有自动提取特征的特性,基于深度学习的加密流量分类技术逐渐成为研究热点。基于深度学习的流量分类技术可分为基于数据特征的深度学习分类算法和基于特征自学习的深度学习分类算法。
基于数据特征的方法在输入网络前仍需要手动提取特征,不是端到端的方法。Wang 等人[10]首次将深度学习技术应用于流量分类领域,他们设计了一种人工神经网络(Artificial Neural Network,ANN)模型,可识别25 种协议类型,并且精度和召回率都达到90%以上。Dong 等人[11]提出了基于流量分析和统计特征的综合分析方法,同时实现了高精度和鲁棒的泛化性能。
基于特征自学习的方法很好地利用了深度学习自动提取特征的特性,是一种端到端的流量分类方法,近年来成为研究热点。Wang 等人[3]第一次将端到端的方法应用到加密流量分类领域,具体是将流量数据可视化后输入卷积神经网络,无须手动提取特征,是特征自学习算法的典型代表。张晓航等人[12]在径向基函数(Radial Basis Function,RBF)神经网络的基础上进行改进,引入了一种梯度惩罚机制,在提高了分类的准确性的同时,能够对不可见流量数据进行有效的分类。Lotfollahi 等人[13]使用堆叠自编码器(Stacked Autoencoder,SAE)和卷积神经网络(Convolutional Neural Network,CNN)两种深度神经网络结构来对网络流量进行分类,在应用流量识别的任务中达到了98%的召回率,在流量分类任务中达到了94%的召回率。薛文龙等人[14]提出了一种用于端到端加密流量分类的轻量级网络,采用特征融合的方法,在显著提高分类结果准确性的同时,大大降低了网络计算复杂度。Izadi 等人[15]设计了一种一维卷积神经网络,通过隐层自动提取流量特征,使用蚁群优化实现高效特征选择,提高了分类精度,在ISCX VPN-nonVPN 数据集上达到了98%的准确率。
基于深度学习的流量分类方法在数据处理上不同于传统的流量分类方法,一般是将二进制可视化为图像输入CNN 卷积神经网络,或是将二进制数据流输入基于序列的循环神经网络(Recurrent Neural Network,RNN)模型中,也有将CNN 与RNN 模型结合的变种。但是,这种方法对输入数据的预处理依赖于经验化的处理,并且训练的可解释性较低,模型以及损失函数的选择差异也容易引起检测性能的不稳定,此外,模型的训练以及预测效率也值得进一步研究。
2 一种端到端的加密流量多分类粗粒度融合算法
2.1 算法设计
本文针对加密流量分类任务,针对多分类问题,结合深度学习技术,设计了一种粗粒度类别融合算法。该方法是受Chang 等人[16]的工作的启发,他们针对自然图像分类问题,设计了一种细粒度特征与粗粒度标签融合的方法。
在Chang 等人的方法中,针对每一种细粒度类别,如“火烈鸟”标签是粗粒度“鸟”类标签下的一种更细粒度的标签,他们同时利用粗粒度标签的分类损失和细粒度标签的分类损失监督深度神经网络学习自然图像分类问题。粗粒度标签预测加强了网络对于细粒度特征的学习能力,而细粒度特征则更好地学习了粗粒度分类器,获得了更好的分类精度。在他们的工作中,针对每一种细粒度类别,手工标注了粗粒度的类别。
针对本文研究的加密流量分类任务,流量间也会存在粗粒度类别特征,比如浏览网页产生的流量可能包含一部分与流媒体相关的流量,因此在它们更粗粒度一级的类别分类上有一部分流量是可以分为一类的,但是这个粗粒度类别的标签难以人为设定,因此本文使用了一个粗粒度类别融合层来自动提取6 种流量类别的类间特征,生成N组粗粒度的类别标签。本文所提算法的流程如图1 所示。

图1 端到端的粗粒度融合算法流程
本文使用的粗粒度类别融合层由一个多层感知机(Multilayer Perceptron,MLP)构成。训练时经过反向传播,粗粒度类别融合层学习到6 种类别的类间特征,将6 种细粒度类别划分为N个粗粒度类别。预测时,粗粒度类别融合层聚合每一个基本分类器的粗粒度分类结果,得到最终预测的每一个类别的概率。
本文算法模型结构如图2 所示,图中N表示粗粒度类别数,是一个人为设定的超参数。

图2 端到端的粗粒度融合算法模型
模型接收一张28×28 大小的流量可视化图作为输入,首先经过一个细粒度特征提取层,该层针对每一个对应的粗粒度类别,提取各个分类网络所需的细粒度特征。该层由一个卷积块构成,能够将28×28 大小的输入转化成64×N个通道的28×28大小的特征图。其次将这组特征图按顺序64 个通道一组,分别输入基础分类网络,每个基础分类网络针对各自的粗粒度类别进行分类,得到每个粗粒度类别的类别概率。此处的基础分类网络,在本文中选择的是ResNet18。每个粗粒度类别包含的类别数设定为6,实际情况可能更为复杂,由于深度学习自动提取特征的特性,该6 类隐含了更少的类别数的情况。
每个基础分类网络输出的是一个1×6 的概率向量,将N个1×6 的概率向量经过concat 操作后输入粗粒度类别融合层,最终输出目标分类的类别概率是一个1×6 的概率向量,取概率最大的类别作为预测的类别,该过程表述如下:
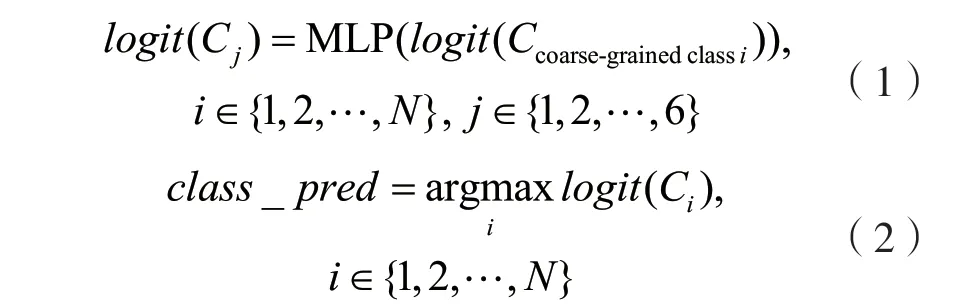
式中:logit(Ccoarse-grainedclassi)为每个基础分类网络预测的粗粒度类别概率;logit(Cj)为最终6 个类别中每一类的预测概率,由所有粗粒度类别概率堆叠在一起输入作为粗粒度类别融合层的MLP 层得到;class_pred为最终的预测类别。
关于训练时的损失函数,本文使用的是常规的交叉熵损失,仅在最终的6 个类别概率上计算交叉熵损失。
2.2 流量数据处理
本文方法接收28×28 大小的流量可视化图作为输入,因此需要对二进制流量数据字节流进行预处理,步骤如下:
(1)根据不同的粒度对网络流量进行划分,网络流量的粒度包括传输控制协议(Transmission Control Protocol,TCP)连接、session、flow。其中,flow 是按照相同的五元组进行划分,即源网际互联协议(Internet Protocol,IP)地址、源端口、目的IP 地址、目的端口、传输层协议,而session 则被定义为双向的flow。
(2)对于每种会话类型的流量数据包,其中的字节数据可以划分为多个协议层。选取流量数据时可以有两种选择:一是选取TCP/IP 模型最顶层应用层的流量数据,二是选取所有层的流量数据。直观地说,应用层的流量数据能很直接地表示出流量的数据特征,例如传输邮件所使用的简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)、流媒体使用的实时传输协议(Real-time Transport Protocol,RTP)、超文本传输协议(Hyper Text Transfer Protocol,HTTP)、Bittorrent 对等协议等,都是应用层协议的一部分,会在应用层流量数据中有明显的体现。但有时候其他层的流量数据也包含了有用的特征信息,最典型的就是应用广泛的传输层安全(Transport Layer Security,TLS)协议,它工作在传输层为上层应用层提供支撑。文献[10]只使用了应用层流量数据进行了实验,但文献[3]针对单独应用层和所有层数据分别进行了实验,表明所有层的流量数据包含更多的可用信息,对提高分类精度有显著的影响。因此,在本文针对加密流量进行分类的实验中,使用到了所有层的流量数据。
(3)对于二进制字节流大于784 字节的单个session,将其修剪为784 字节;如果单个session 的二进制字节流小于784 字节,则在末尾添加0x00以将其补充到784 字节。然后将784 字节大小的结果文件转换为28×28 的灰度图像。最后将图像转换为研究领域常用的idx 格式文件。这是一种研究时常见的处理方法,如文献[12]和文献[17]均采用了类似的处理方法。
本文使用Wang 等人提出的USTC-TL2016 工具[3]对原始流量数据进行处理,基于session 的形式处理了数据包,并提取了所有层的流量数据,将原始的二进制pcap 流量数据处理为能够输入CNN网络的图像格式数据。在ISCX VPN-nonVPN 公开流量数据集[18]上,针对流量数据预处理后生成的图像,如图3 所示,各类选取两例分两行展示,每一列为同一类别,底部标注了类别名称,包括使用若干即时聊天应用程序产生的流量(Chat-VPN)、接收邮件产生的流量(Email-VPN)、文件传输产生的流量(File Transfer-VPN)、使用点对点文件共享协议产生的流量(P2P-VPN)、流式多媒体服务产生的流量(Streaming-VPN)、使用语音应用程序进行IP 通话产生的流量(VOIP-VPN)。
根据图3 中的可视化结果进行定性分析,各类流量之间差异性很大,不同类别的流量之间有明显的区别,而同一类别的流量具有高度的一致性,尤其是协议加密后的流媒体流量数据和网络通话流量数据,这对于卷积神经网络来说很容易区分。
3 实验分析
3.1 实验细节及数据
实验的环境和配置如表1 所示。训练方面使用了权重衰减为1e-5 的Adam 优化器,学习率设置为1e-4,学习率衰减策略设置为每10 个epoch 学习率衰减为0.1,总共训练20 个epoch。

表1 实验环境及配置
为了验证本文提出的方法,在ISCX VPN-non VPN 公开流量数据集[18]上进行了实验验证。ISCX VPN-nonVPN 数据集包含了7 种常规会话类型流量数据和相应的通过协议封装加密的7 种会话类型的流量数据。这7 种会话类型包括用户通过浏览器上网产生的流量(Browsing-VPN)、使用SMTP 发送或使用邮局协议(Post Office Protocol -Version 3,POP3)和互联网消息访问协议(Internet Message Access Protocol,IMAP)接收邮件产生的流量(Email-VPN)、使用若干即时聊天应用程序产生的流量(Chat-VPN)、流式多媒体服务产生的流量(Streaming-VPN)、多种协议下文件传输产生的流量(File Transfer-VPN)、使用语音应用程序进行IP 通话产生的流量(VOIP-VPN)、基于Bittorrent 等点对点(peer-to-peer,P2P)文件共享协议产生的流量(P2P-VPN)。由于第一类浏览器流量(Browsing-VPN)与其他类别流量存在分类边界模糊的问题,根据文献[3]的做法,本文舍弃了第一类流量,仅使用剩下的6 种会话类型流量,并在这6 种类型的协议封装加密后的流量上进行了实验。每个类别包含的样本数如表2 所示,其中,1/10 的数据被随机选为测试集兼验证集,其余作为训练集,训练时的batch 大小设置为128。

表2 每个类别包含的样本数
在进行数据预处理时,如第2 节中所述,使用了Wang 等人提出的USTC-TL2016 工具[3]对原始流量数据进行了处理,即基于session 的形式处理了数据包,并提取了所有层的流量数据,将原始的二进制pcap 流量数据处理为idx 格式的28×28 大小的灰度图像包,部分可视化图像的示例如图3 所示。


图3 各类别流量可视化示例
3.2 评价指标
针对二分类问题,有4 种常用的指标来对模型性能进行评估,分别是准确率Accuracy、精确率Precision、召回率Recall、F1 分数F1_score,各指标计算如下:
式中:TP为真正例的数量;FP为假正例的数量;TN为真反例的数量;FN为假反例的数量。准确率Accuracy是衡量正确分类的样本数与总样本数的比例,但容易受到类别数量不平衡的影响。精确率Precision又称查准率,衡量模型预测为正的样本中真实的正样本所占的比例。召回率Recall又称查全率,衡量所有正样本中被模型预测为正的样本数所占的比例。通常,一个模型无法同时满足高精确率和高召回率,而F1 分数F1_score是精确率和召回率的调和平均数,是一种同时兼顾了分类模型的精确率和召回率的评估指标,对模型的识别准确率作出综合评价。
在多分类问题中,准确率Accuracy同样适用,但精确率Precision、召回率Recall、F1 分数F1_score仅适用于二分类问题。因此,本文的实验使用的均为宏精确率macro-Precision、宏召回率macro-Recall、宏F1 分数macro-F1_score对模型性能进行评估,即针对多分类中的每一个类别,计算各自类别的精确率Precision、召回率Recall、F1分数F1_score指标,对其取均值,得到整体的宏精确率、宏召回率、宏F1 分数。
3.3 实验结果与分析
为了验证本文提出的方法的有效性,将本文所提的方法与LeNet、ResNet18、ResNet50、DenseNet121[19]、SENet[20]、ShuffleNet[21]、MobileNet[22]这些基于表征学习的深度学习分类模型在同样的数据上进行了对比实验,实验结果如表3所示。
表3 显示了各模型对加密流量数据分类的准确率Accuracy、精确率Precision、召回率Recall和F1 分数F1_score。表中结果反映出各类模型均能对加密后的流量数据进行有效的分类,其中本文所提方法在准确率和召回率以及F1 分数上都达到了最优,在精确率上仅次于原始的ResNet18。这是因为如表2 所示,原始数据存在类别不平衡的问题,Chat-VPN 类和VOIP-VPN 类的样本数远超其他 4 类的样本数,计算宏精确率容易受到类别不平衡问题的影响。就网络深度而言,ResNet50 采用了和ResNet18 一样的网络结构,不同的是加深了网络的深度,但是分类效果并没有随着网络深度的增加、参数量的提升而提升,因此堆砌网络深度和参数量并不一定能带来效果的提升。本文提出的方法仅在精确率上与ResNet18 相差0.07%,远小于与其他模型的差距,且在另外3 个指标上都达到了最优,因此本文的方法仍旧是最有效的。

表3 实验结果 %
训练集中总计有11 272 条数据样本,训练时的batch 大小设置为128,总训练步数为1 731 步。训练时的分类损失与训练步数的关系如图4 所示。从图4 可以看出,从初始状态经过同样的训练步骤不同方法的收敛速度有较大差别。LeNet 在训练1 200 步之后趋于收敛,ResNet18 在1 200 步之后趋于收敛,ResNet50 在1 000 步之后趋于收敛,DenseNet121 在1 000 步之后趋于收敛,SENet 在 1 100 步之后趋于收敛,ShuffleNet 在1 300 步之后趋于收敛,MobileNet 在1 100 步之后趋于收敛,而本文提出的方法在训练880 步之后分类损失就很稳定已经趋于收敛,相较于其他模型,本文的方法有更快的收敛速度。

图4 各模型收敛步数

各模型的运行效率如表4 所示,包含总训练时间、训练到收敛的时间以及在测试集上测试完所有测试数据使用的时间。所有训练与测试均在GPU上完成,收敛时间根据训练完每个epoch 后模型在验证集上的预测结果趋于稳定的时间得出。

表4 各模型运行效率 s
从表4 中可以看出,LeNet 由于网络规模小、结构简单,训练完20 个epoch 的时间最快,但同时实际性能表现却不佳,并且训练到收敛的时间慢于本文提出的方法。本文提出的方法在6 类加密流量上训练20 个epoch 需要的时间为292.23 s,但是本文提出的方法收敛速度很快,实际在训练经过128.57 s 时模型就已经收敛,因此虽然本文方法在测试时的效率低于LeNet 和SENet,但本文方法的效果远好于二者。
对于本文提出的粗粒度类别融合模块,针对不同的粗粒度类别数,进行了消融实验,实验结果如表5 所示。
如表5 所示,当粗粒度类别数仅为1 类时,本文所提方法的网络会退化为一般的基干分类网络,效果仅为在ResNet18 前后分别加了一个卷积层和一个MLP 层。由于网络结构的改变和层数的加深,此时网络的学习效果相比于原始的ResNet18 有一定的退化。当粗粒度类别数为2 时,也能到达不错的分类效果,但是仍有提升空间。有趣的是,当粗粒度类别数选择3 类和6 类时,分类效果反而下降,分析认为这是在设置为3 类和6 类时,现有数据隐含的粗粒度类别数量特征不能很好地匹配设置的类别数量,导致粗粒度分类融合模块未能有效地提取到粗粒度的类别信息。当选择的粗粒度类别数为4类和5 类时,能够达到最好的分类效果,在本文的对比实验中,权衡了效果和效率,选用的粗粒度类别数均为4 类。

表5 粗粒度类别数消融实验
4 结语
本文在将流量数据可视化进行表征学习的基础上,利用网络自动学习到各类别间更粗粒度下的类别关系,并根据提取到的粗粒度下的分类结果,利用多个网络分别去拟合不同粗粒度分类下不同的分类结果,通过融合多个粗粒度标签下的分类结果得到了最终的多分类标签。本文所提方法是端到端的,无须手动提取特征,也无须人工标注粗粒度类别标签。该方法不仅利用了流量数据可视化之后的特征,也利用了不同类别标签之间可能存在的粗粒度类别关系,在保证模型运行效率的情况下,提高了分类的准确率。在未来的工作中,将结合深度学习技术继续探究类别间粗细粒度融合的分类方法,提高分类的准确率。
猜你喜欢
玩具世界(2022年2期)2022-06-15
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
陶瓷学报(2021年4期)2021-10-14
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
少儿画王(3-6岁)(2020年4期)2020-09-13
太原科技大学学报(2019年3期)2019-08-05
课堂内外(小学版)(2017年5期)2017-06-07
电子制作(2017年23期)2017-02-02
微型计算机(2009年4期)2009-12-23
