
机器学习中集成模型的应用问题研究
2023-01-16 06:00焦嘉,刘婷
无线互联科技 2022年21期
焦 嘉,刘 婷
(湖南信息职业技术学院,湖南 长沙 410203)
0 引言
机器学习的本质是学习计算机智能,并赋予计算机与人类相同的学习能力。利用糖尿病患者数据与机器学习的结合[1-2],能够达到对专业数据进行处理提供定制医疗咨询的能力。

图1 集成模型总体流程
1 集成模型定义及流程
将Logistic回归得到的结果按照概率值划分为3个区间,分别是[0-0.4][0.4-0.6][0.6-1]。然后根据概率值区间将样本训练集也划分为3个区间,求出每个区间内样本预测的准确率。将划分的3个区间分别使用C4.5决策树算法进行训练,分别求出其预测准确率,然后分别比较两种模型在3个区间的预测准确率,选择准确率较高的作为最终判别标准。
如图1所示为集成模型的总体流程,步骤包括原始数据收集、数据预处理、单因素分析、多因素Logistic回归分析、样本数据集划分与处理、决策树模型的形成、模型的集成比较、最终形成集成模型等。
2 模型及目标函数
2.1 单因素分析
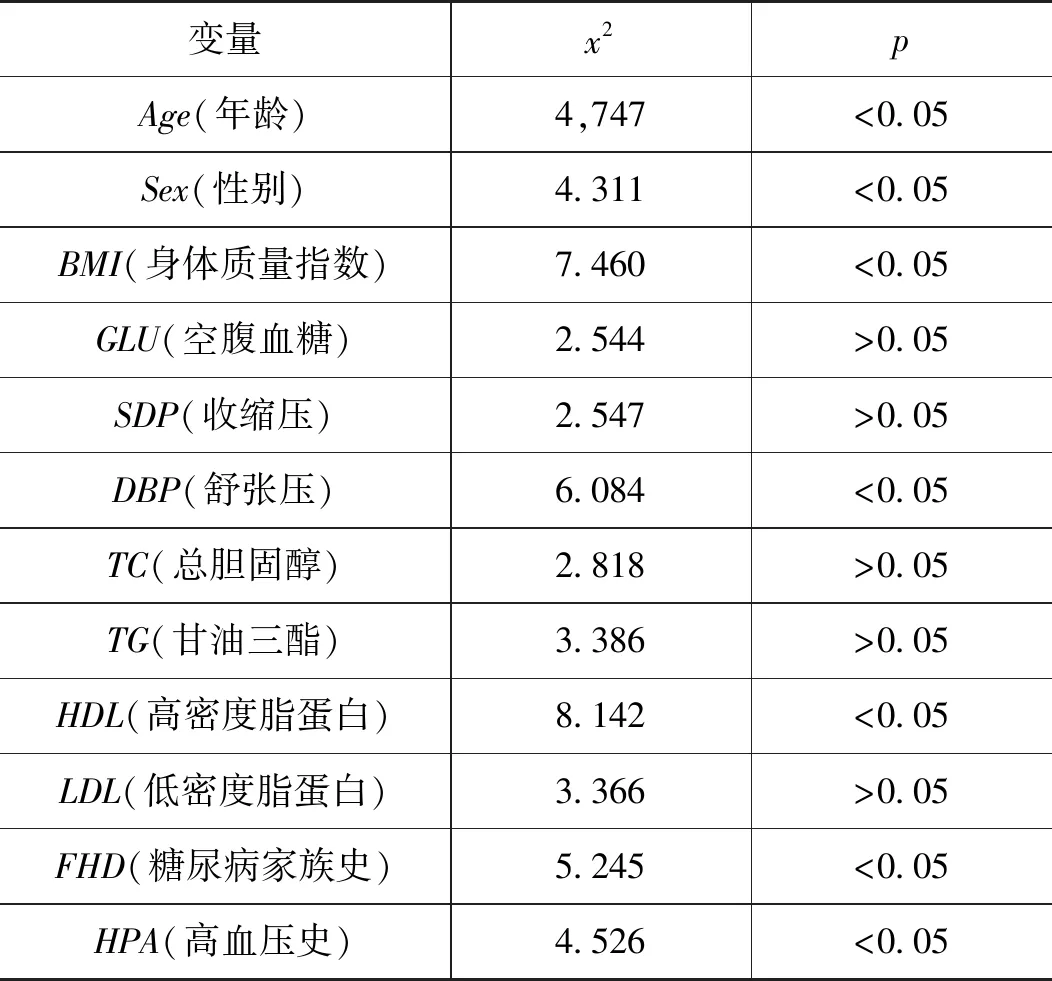
单因素分析使用SPSS软件进行,采用的是列链表x2检验,用于探讨各因素与糖尿病的关系。糖尿病危险因素单因素分析结果如表1所示。
2.2 多因素Logistic回归
多因素Logistic回归分析根据表1中单因素分析的结果选择出来的影响因素进行,Logistic回归分析使用的是sigmoid函数,将线性回归的结果变换后输出到[0-1]区间,表达式如下:

(1)
其中,β和X为向量,Xi(i=1,2,…,7) 分别表示经过单因素分析的影响因素,而βi则表示每个Xi所对应的参数,也就是所要求解的回归系数,β0为常数,而最终要求的是βi(i=0,1,2,…,7)值。
2.3 样本数据集划分与处理
将所有样本按照sigmoid函数得到的概率进行区间划分,其划分标准如下:
H1=[0,0.4],H2=[0.4,0.6] ,H3=[0.6,1]
将样本数据集划分区间后,发现数据集H1,H3的数据不平衡,为了解决这个问题方便下面的模型构建,本文采用的方法是Easy Ensemble:这是集成算法中最简单的算法之一[3],具体做法是从0类中(样本多的类)中取出1类等量样本,并且不重复地取多次,用于构建多个训练集,最终使得0类样本大部分都参与训练一次。之后,根据得到的多个模型选择其中预测准确率最好的模型作为最终模型。
2.4 决策树生成
决策树先选择根节点属性,只要有一个可能的属性值,就产生一个分支。本文以收集到的医疗数据为例,以Y(是否患病)作为输出变量,输入变量以Ti(i=1,2,……13)表示,决策树输出变量Y的信息熵为:
(2)
其中,P(y2)代表不患糖尿病的概率,P(y1)代表患糖尿病的概率。
2.5 决策树减枝
在决策树生成的过程中,由于数据可能存在噪声和决策树算法本身存在的问题,也就是常说的过拟合现象。本文采用的是PEP (Pessimistic Error Pruning)(悲观剪枝)[3]。其剪枝过程如下所示:
(1)计算剪枝前错误率e。
(2)计算剪之前误判次数均值E,其中E=N×e(其中N是样本总数)。

(4)计算剪枝后错误率e+。
(5)计算减值后误判次数均值E+,其中E+=N×e+。
(6)判断剪枝条件,若E-var>E+,则剪枝该子树;若E-var≤E+,则不剪枝该子树。
上述步骤中的错误率估计如下所示:
(3)
2.6 模型集成
本文将数据集划分之后结合Easy Ensemble技术形成决策树的训练数据集,随后生成多个决策树模型,然后分别计算出各个模型决策树的预测准确率,在3个分区H1=[0,0.4],H2=[0.4,0.6] ,H3=[0.6,1] 分别选择预测准确率最高的模型作为最终形成的决策树模型,其预测准确率分别记为PJi(i=1,2,3)。同时结合之前生成的Logistic回归模型在3个分区H1=[0,0.4],H2=[0.4,0.6] ,H3=[0.6,1]的预测准确率PLi(i=1,2,3),最终比较并选出分别在3个分区上的模型。其集成过程如下:
(1)选择分区Hi(i=1,2,3) ,分别计算两种模型预测准确率。
(2)若PLi>PJi(i=1,2,3),在分区Hi上最终选择Logistic回归模型;若PLi≤PJi(i=1,2,3),在分区Hi上最终选择决策树模型。
(3)重复步骤1,直到i=3。
3 实验结果与分析
如图2所示为3个分区内的两个模型的预测准确率,在H2分区内,决策树和Logistic回归模型的预测准确率相差明显,决策树预测准确率明显高于Logistic回归模型,在H1,H3两个分区内决策树和Logistic回归模型的预测准确率差别不大,最终在3个分区内分别选择H1决策树、H2决策树、Logistic回归模型作为最终的集成模型的判别标准。
由集成模型和实验数据可知,其训练集和测试集的预测准确率如表2所示。

表2 集成模型的预测准确率
由表2可知,集成模型的预测准确率在3个模型中最高,其中训练集预测准确率为91.16%,测试集的预测准确率为88.28%,所有样本的预测准确率为90.34%。由此可知该模型在3个模型中最具有参考意义,对糖尿病的风险预测作用最大。
4 结语
本文立足实际的医疗数据,采用机器学习技术中集成模型来建立糖尿病风险预测模型,改进之处如下:
(1)将机器学习的几种分类算法结合起来应用到糖尿病的风险预测中,采用Logistic回归算法和决策树算法构建集成模型,结合了Logistic回归模型的优点与决策树模型的优点,在一定的程度上解决单分类模型预测结果不稳定的问题。

图2 3个分区内两种模型预测准确率对比
(2)使用集成模型进行实验,通过对医疗数据的处理,最终证明了集成模型拥有较高的分类准确率和稳定性,适合于糖尿病的风险预测。
猜你喜欢
保健医苑(2022年5期)2022-06-10
医学食疗与健康(2021年27期)2021-05-13
成都信息工程大学学报(2021年6期)2021-02-12
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
天津诗人(2017年2期)2017-03-16
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
计算机工程(2014年6期)2014-02-28
