
医疗影像数据传输的智能优化方案
2023-02-12 15:13胡佳迎王奕何萍
中国医疗器械杂志 2023年1期
【作 者】 胡佳迎,王奕,何萍
1 复旦大学附属肿瘤医院,上海市,200032
2 上海申康医院发展中心,上海市,200041
0 引言
医疗卫生数据是患者在就医过程中产生的数据。近年来,随着大数据技术和互联网技术在医疗领域的广泛使用,医疗卫生信息化建设进程不断加快,医疗数据的类型和规模也以前所未有的速度迅猛增长。同时,医疗资源稀缺、医疗资源配置不均等医疗供给侧问题日益凸显,以数字技术和人工智能赋能,通过智慧医疗、远程医疗、线上会诊使得患者无论何时何地,均可接受专家会诊,从而缩短救治时间、降低医疗费用。这样的互联网医疗建立了一种医学专家和患者之间的全新服务模式,可以有效解决部分医务人员技术水平偏低、医疗资源短缺、供给配置不充分不平衡等一系列问题[1],缓解医疗供需矛盾,推动医疗行业的供给侧改革。医疗数据的压缩与传输[2-3]是实现远程医疗、线上会诊以及互联网医院的重要所在。然而,这样大规模、大体积的影像数据在传输过程中会出现速度慢、效率低、网络资源占用率高等问题。在已有诊断报告的情况下,如何高效、快速且安全地在不同的平台系统中传输数字医疗影像,成了减少患者等待时间、提高医生诊断效率、推动医院数字化进程需要解决的问题,也是推动全国各医疗机构医疗信息共享、医疗数据互联互通面临的主要困难之一。
现有的医疗影像传输优化方法主要分为两种。一是直接对影像数据进行压缩,传输压缩后的影像数据,最终在终端进行解压、还原,包括有损压缩和无损压缩。这种方法虽然简单方便,且有损压缩方法压缩比很高,不可避免地会在压缩、解压的过程中造成数据损耗,降低图像质量,对医生的诊断造成影响,而无损压缩方法压缩比较低,即压缩后传输速度很难有大的提升。二是将影像分割为子影像数据,分开传输,最终在终端还原,在传输过程中可对子影像数据进行优先级划分,优先传输关键的子影像。例如:
(1)通过模式识别或者基于图像特征的图像处理方法提取出感兴趣区域图像,将其作为第一优先级图像传输,然后将整体压缩[4-5]图像作为第二优先级图像传输,并对第一优先级图像替换显示,最后将原始图像传输。但是由于医疗影像差异性大,根据统计先验来提取感兴趣区域无法做到很好的泛化性能和精准性能。
(2)根据人为设定关键区域或者医生阅读习惯来抽取关键区域依次进行传输的方法。但不同的医生阅读习惯不同,很难做到收集每个医生的阅片习惯并按优先级排序。
(3)将影像数据与患者的电子病历相结合,根据不同位置在病例中出现的词频对其打分来确定传输顺序。该方法虽然结合了患者的历史病例,但是单纯地依靠词频的方法很难保证提取的关键区域是正常还是异常,新出现的异常区域无法检测出来。
为了优化传统的影像传输流程,提高医生工作效率,本研究提出了一种智能的大体积医疗影像传输的优化方法,将医生的诊断报告与计算机影像分析结果相结合,提取出影像关键部位图像并将其优先传输到显示终端,随后根据用户的需求将剩余部分数据进行传输,在显示终端上合并展示。医学影像传输优化方法流程如图1所示,具体为:①应用FlashText算法对诊断报告进行关键词匹配提取,构建病灶、异常或者可疑的描述以及相应的区域位置的关键词对;②利用人工智能影像分割算法3D-UNet将影像数据按照不同的器官、部位等分割为不同的子区域影像;③依据关键词对以及影像分割结果,匹配提取对应的关键区域影像对应的横断位切片子影像数据块,为子影像数据块分配传输优先级分数,按照优先级分数将子区域影像数据推入传输队列依次传输,将输入的三维CT影像通过语义分割为5个不同的子区域:左上肺叶、左下肺叶、右上肺叶、右中肺叶、右下肺叶。本研究提出的方法不受个人偏好、病灶差异性等因素影响,同时具备更好的泛化性能。
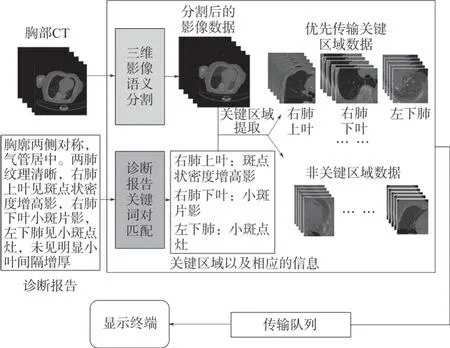
图1 医学影像传输优化方法流程Fig.1 Flowchart of the optimized medical image transmission method
1 数据与方法
1.1 数据的采集与预处理
医联中心每日采集36家上海市市级医院医疗电子数据,包括检验报告、检查报告、检查影像、电子病历等,归集到中心端统一存储与管理。我们基于医联中心的数据,随机抽取了2020ü 2022年的1000例胸部CT断层扫描影像及其对应的诊断报告。CT扫描影像数据的分辨率为0.625~5 mm,原始尺寸约为512像素h 512像素h 层数,以DICOM格式存储。由专业医生标注,标注掩膜分为5个类别:左上肺叶、左下肺叶、右上肺叶、右中肺叶、右下肺叶。诊断报告以.txt文本格式存储。
对于每个获取的三维CT扫描影像数据,保留其中0.5%~99.5%的体素值,并做z-score标准化处理,然后对其三次样条插值,将其缩放为228像素h 228像素h 128像素的三维图像。实验选取所有CT影像数据的70%作为训练集,20%作为验证集,10%作为测试集。
1.2 文本报告关键词提取
医生的诊断报告具有专业性强、专业术语多、数据量大等特点。正则表达式是目前常见的关键词匹配方法,但使用烦琐且其匹配耗时会随着关键词字典数量的增加而呈线性增长。FlashText是一种基于Aho-Corasick算法[6]的关键词匹配算法,该方法不会受到关键词字典数量的影响,更加高效,并广泛应用[7-8]。具体地,FlashText算法首先会根据关键词语料库(本研究中的词库由医生预定义)构建一个前缀树字典。定义start和eot(end of term)节点,其中start节点为前缀树的根节点,eot节点为关键词的结束节点,均用来定义词的边界。每个eot节点都有一条从根节点到它的唯一路径,代表一个单词。FlashText算法构建的前缀树字典结构如图2所示。其中前缀树字典包含了右肺、右肺上叶、右肺下叶、主动脉弓、增厚和增大6个关键词。
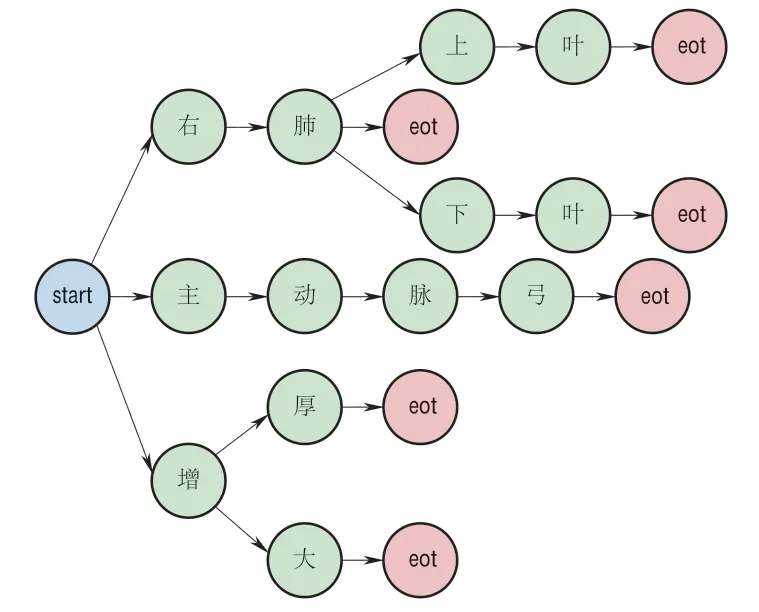
图2 FlashText算法构建的前缀树字典结构Fig.2 Illustration of tree structure built by FlashText algorithm
对于输入的字符串,按字符逐个在前缀树字典中搜索,若当前节点为eot节点且没有相匹配的孩子节点,那么输出该关键词,若当前节点不是eot节点且与当前根节点匹配不上则返回前一个匹配到的eot节点对应的关键词。例如,假设有字符串 右肺下方有阴影”,按照图2所示的前缀树字典,可以匹配到 右肺下 三个关键字,这并不是一个关键词,但回溯到上一个eot节点可以发现,“右肺 是一个关键词,因此输出结果为 右肺”。
1.3 影像分割
U-Net是由RONNEBERGER等[9]在2015年提出的一种encoder-decoder结构的深度卷积神经网络,其跳跃连接层结构使得网络在编码与解码的过程中很好地保留了图像的特征信息,使得其在医疗图像语义分割任务上有出色的表现。对于3D医疗影像,等[10]将2D卷积操作改进成了3D卷积操作,使得网络更好地保留了三维影像的结构信息。3D U-Net同样包含了一个编码器encoder和一个解码器decoder。编码器中包含了四层不同分辨率的卷积网络结构,每一层有两个3h 3h 3卷积,每一个都后接一个Normalization层以及ReLU层,最后连接了一个2h 2h 2的每个方向上步长都为2的最大池化层,用于下采样。相应的解码器每一层包含一个步长为2的2h 2h 2的反卷积层用于上采样,紧跟两个3h 3h 3的卷积层,每一个都后接一个Normalization层以及ReLU层。通过一个跳跃连接层将编码器中相同分辨率的层通过concat操作传递到对应的解码器层中,网络最后由一个1h 1h 1的卷积层构成,其输出通道数为按像素分类后的标签类别数量。我们将编码器和解码器中的Batch Normalization[11]替换为Instance Normalization[12],将ReLU层替换为斜率0.01的Leaky ReLU。3D-UNet模型结构如图3所示。

图3 3D-UNet模型结构Fig.3 3D-UNet model structure
1.4 优先级传输队列
为了与关键影像匹配,根据不同的语义将关键词分为器官、位置、病理特征(异常)以及否定词共四类。构造关键词对,如图4所示。将诊断报告分成不同的词段,对每一个词段,提取出表示病灶、异常的词,过滤掉否定的描述,搜索其最近邻的器官以及位置描述关键词,生成关键词对。图4中加粗的关键词表示器官,斜体表示位置,下划线表示病例特征或者异常描述,高亮表示否定词。

图4 构造关键词对示意Fig.4 Illustration of constructing keyword pairs
对于每一个分割子区域根据医生的需求预定义关注程度分数Ci,1,2,…,K,其中K为子分割区域的总数量。同样的对于每一个程度描述或者病灶描述预设一个表示严重程度的分数Li,,2,…,M,其中M为所有相应描述的关键词总数目。例如 Ca”(癌变)、“出血 腔梗 等关键词分数较高,“可疑 可能 增宽 等描述词汇关键词分数较低。对于每一个分割区域依据对应的关键词对打分,分数Gi的计算方式如式(1)所示,其中N为该影像报告中出现的结构化关键词对的总数量,ni为分割区域i内的关键词对的数量,α、β为常数系数。对于没有与关键词对进行关联的子区域图像,令其关注程度Ci分数为零。

在用户显示终端发送数据请求后,对所请求的影像数据,按照优先级顺序将预处理好的关键区域影像块以及对应的诊断报告词段描述和对应的位置信息依次推入消息传输队列,首先在用户的显示终端按照顺序将关键区域影像在所对应的位置渲染。若关键区域仍不能满足诊断需求,用户可继续请求剩余部分的影像数据。这样减少不必要的影像传输,避免网络资源的浪费。
2 实验结果及分析
实验平台配置如下:CPU为Intel® Xeon®CPU E5-2643 v3 @ 3.40 GHz;显卡为NVIDIA GTh 1080Ti(h 4),显存容量为12 GB;操作系统为18.04.2-Ubuntu,配置了CUDA 11.1和cuDNN 8.0.5;深度学习框架为Pytorch1.9.0。
2.1 关键词提取与影像分割
由于本研究中诊断报告平均长度为317字符,关键词数量较少,因此选择了含有18749条医学关键词条的thuocl medical词库,来对FlashText方法进行有效性分析。实验随机选取了16000个关键词,FlashText和正则表达式(Regex)2种方法在不同数量的关键词字典上的平均运行时间(wall time)的耗时结果如图5所示。图5中横坐标为字典中的关键词个数,纵坐标为平均运行时间。由图5可知,随着字典中的关键词数量的增加,正则表达式运行时间呈线性增长,而FlashText几乎不受影响。因此,本研究选择可扩展性更高的FlashText方法来提取关键词。

图5 FlashText与正则表达式Regex运算时间比较Fig.5 Comparison of computing time between FlashText and Regex
为了分析改进后的3D-UNet分割方法的有效性,在划分好的训练集上通过混合精度方法进行模型训练,使用Kaiming initialization方法[13]对模型的权重和偏差进行初始化,Dice Loss作为损失函数,ADAM为模型的优化器,初始化学习率为0.001,使用分布式训练方法,每块GPU上的Batch Size为2,迭代次数为200。在验证集上进行5-fold交叉验证,选取表现最好的模型作为最终结果。将得到的模型在测试集上进行验证。使用Dice系数、Jaccard系数以及平均对称表面距离(average symmetric surface distance,ASSD)作为评价指标,其定义分别如式(2)~(4)所示,其中X表示预测值,Y表示真实值,S(X)表示X边界上的像素点集合。Dice系数和Jaccard系数是语义分割任务上常用的评价指标,其值越接近1,代表分割结果越接近真实值;ASSD表示分割结果与真实值表面的平均距离,其值越小,代表分割结果越接近真实值。
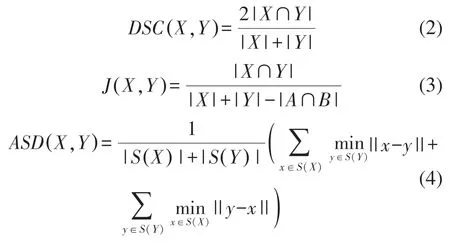
模型分割结果如下:Dice系数为0.974,Jaccard系数为0.958,ASSD达到2.186。模型分割结果的准确率较高,能够满足关键影像区域的分割要求。
2.2 关键影像有效性分析
在收集的1000个数据中,有592个影像数据异常、病灶等相关诊断报告描述,占数据集的59.2%,其余40.8%为正常患者影像。在异常的数据中,通过本方法提取出的关键影像切片平均大小约为原始影像的45.4%,即节省了54.6%的影像传输资源,有效地缩短了影像传输时间,降低了网络资源占用。为了更好地分析本方法在优化医疗影像传输上的有效性,邀请了两名专业的临床医生参与评价。由医生在测试数据集上进行独立阅片,判断所提取的关键区域影像能否满足诊断需求。实验结果显示,对于报告中包含病灶的患者数据,平均94.4%的情况下临床医生只需要浏览关键影像即可满足诊断需求,剩余5.6%未能提取出全部异常以及包含病灶的影像区域,需要医生进一步请求传输剩余影像子区域。
3 结论
针对医疗影像数据体积大、传输占用的网络资源高、传输效率差等问题,本研究提出了一种结合医生诊断报告中的关键性描述与影像关键区域的分步影像传输优化方法。通过3D-UNet将影像分割为子影像数据块,应用FlashText关键词匹配方法分析医生的诊断报告并抽取其中的关键性描述词对,匹配相应的区域的横断位切片子影像数据块,按照用户的需求与其优先级顺序依次传输子影像数据块。实验证明,本方法基于对诊断报告和影像的准确分析,能够优先传输最相关的影像数据块,进而让医生能快速有效地在诊断过程中获取关键区域的影像。实验表明,本方法能够减少约50%的影像传输负担,大幅降低了对于传输设备以及网络资源的要求,对于实现全国各医疗机构医疗信息共享、医疗数据互联互通,有重要的现实意义和经济价值。
猜你喜欢
安徽医学(2022年3期)2022-03-22
数学物理学报(2021年1期)2021-03-29
家庭影院技术(2020年12期)2021-01-18
电子制作(2018年18期)2018-11-14
小太阳画报(2018年3期)2018-05-14
文学港(2018年1期)2018-01-25
当代医药论丛(2017年22期)2017-04-12
家庭影院技术(2017年12期)2017-02-06
腹腔镜外科杂志(2016年9期)2016-06-01
哈尔滨医药(2014年6期)2014-02-27
